この記事は Kaggle Advent Calendar 2019 の 19 日目の記事です。
どうもこんにちは、kiccho1101と申します!
人生で初めて記事を書きます!よろしくお願いします!
はじめに
今回は、Kaggleの特徴量管理をPostgreSQLでやってみたら思ったよりも捗ったので、紹介したいと思います。
作ったディレクトリはこちら: https://github.com/kiccho1101/datascience-template
↑READMEにはTitanicコンペのデータを使った使用例が書いてあります。
特徴量管理とは?
Kaggleコンペでは、(以前の)僕のように何も考えずにコードを書きまくってると、以下のような問題が発生します。
- 特徴量が何を表してるのかわからない
- notebookがカオス状態に(exp1.ipynb, exp1_tmp.ipynb, exp1_tmp_tmp.ipynbなどが大量に発生)
- 半年後見返したときに、書いた自分でも???となるコードが生成される
これらの問題を解決するために、何らかの方法で特徴量を管理する必要があります。
特徴量管理については、Takanobu Nozawaさんのスライドがとてもわかり易いので、こちらを是非参考にしてもらえれば幸いです。
概要
このディレクトリの特徴をまとめると以下のとおりです。
- データをDockerコンテナ上のPostgreSQLで管理
- SQLとPythonの両方でデータの操作ができる
- Makefileを使って一連の流れ(特徴量生成, 交差検証, 予測)をコマンドラインツール化
- 実験内容をconfigファイルで管理
データをDockerコンテナ上のPostgreSQLで管理
データベースを用いることにより、
などのデータベースビューアーでデータを見れます。これがすごくいい。
pandasでやるよりも、EDAが格段にしやすいです。
Makefileによるコマンドラインツール化
特徴量生成
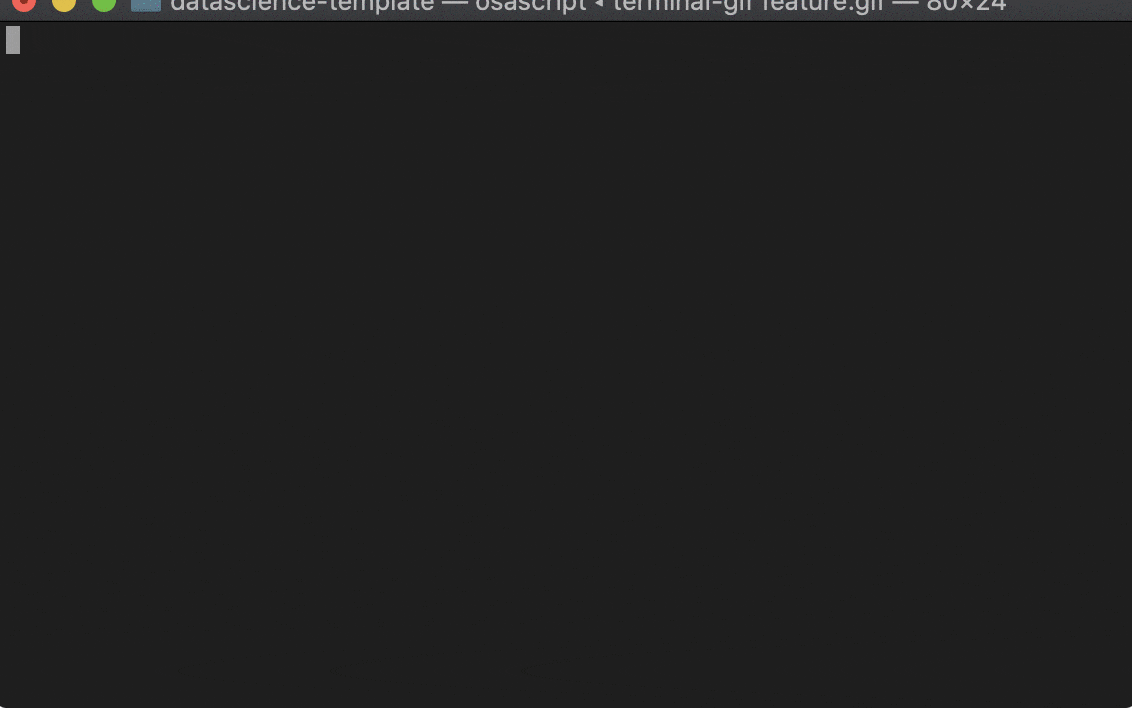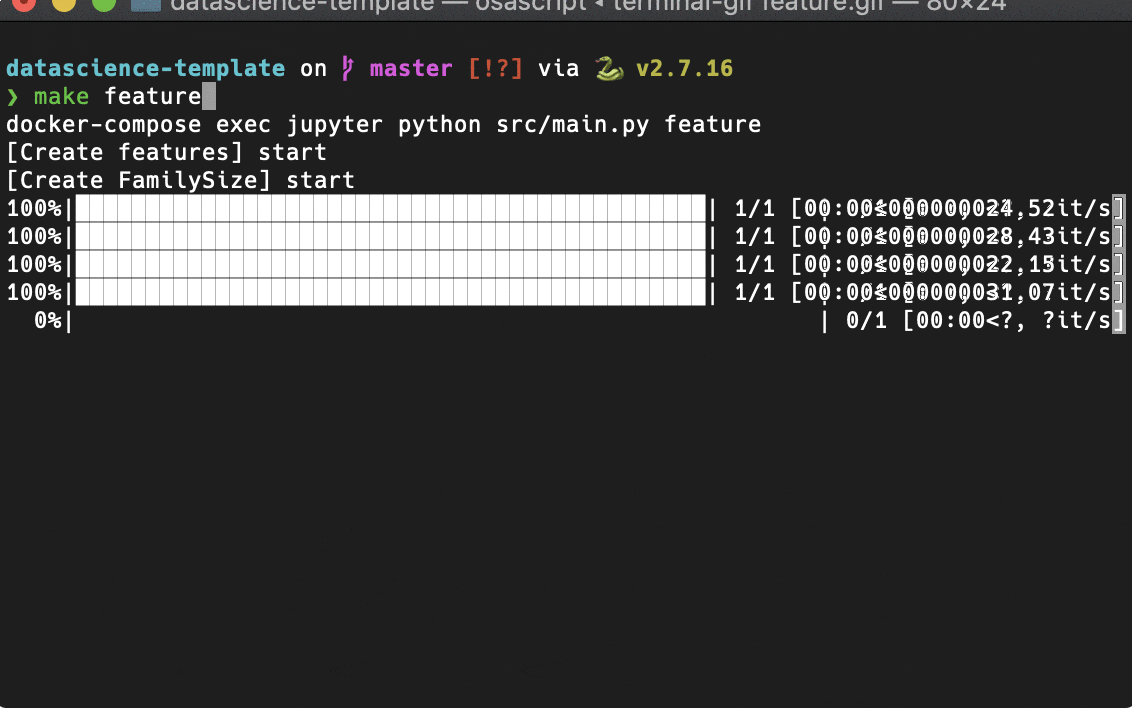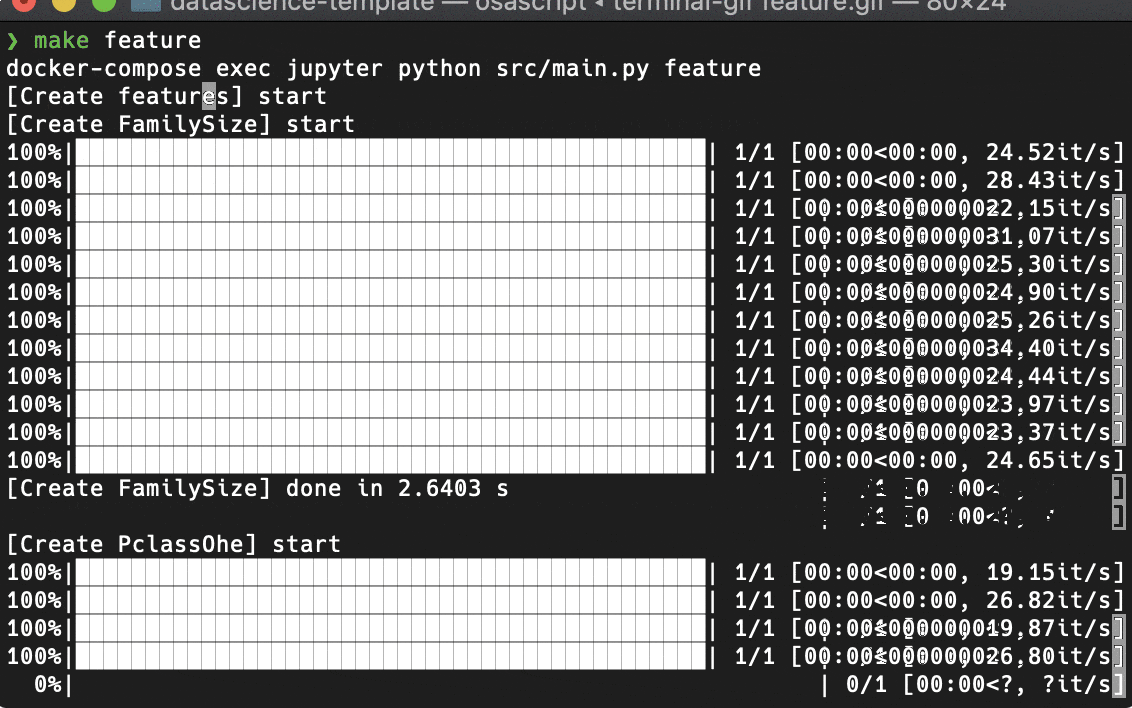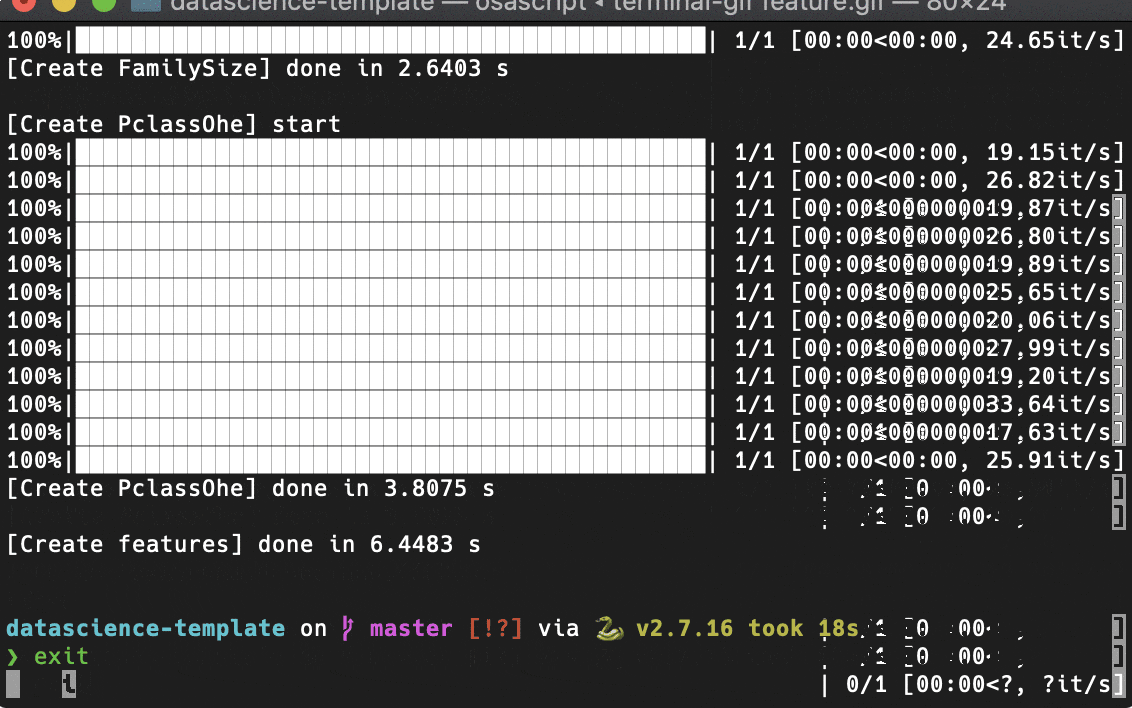
交差検証 (Cross Validation)
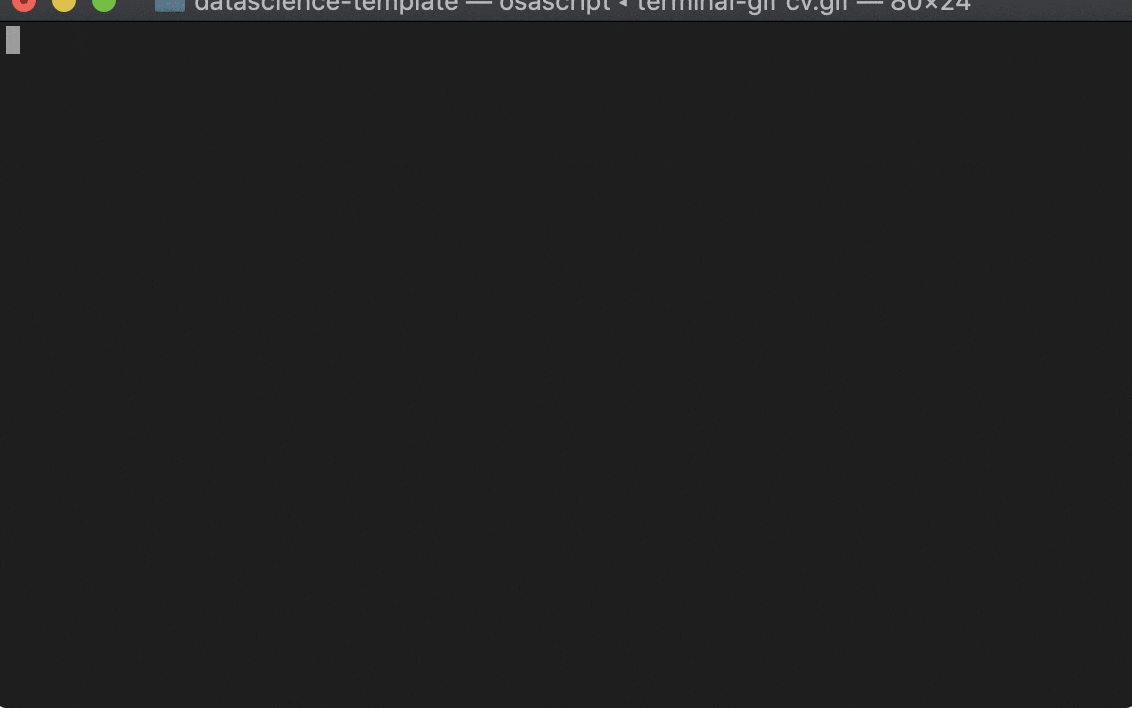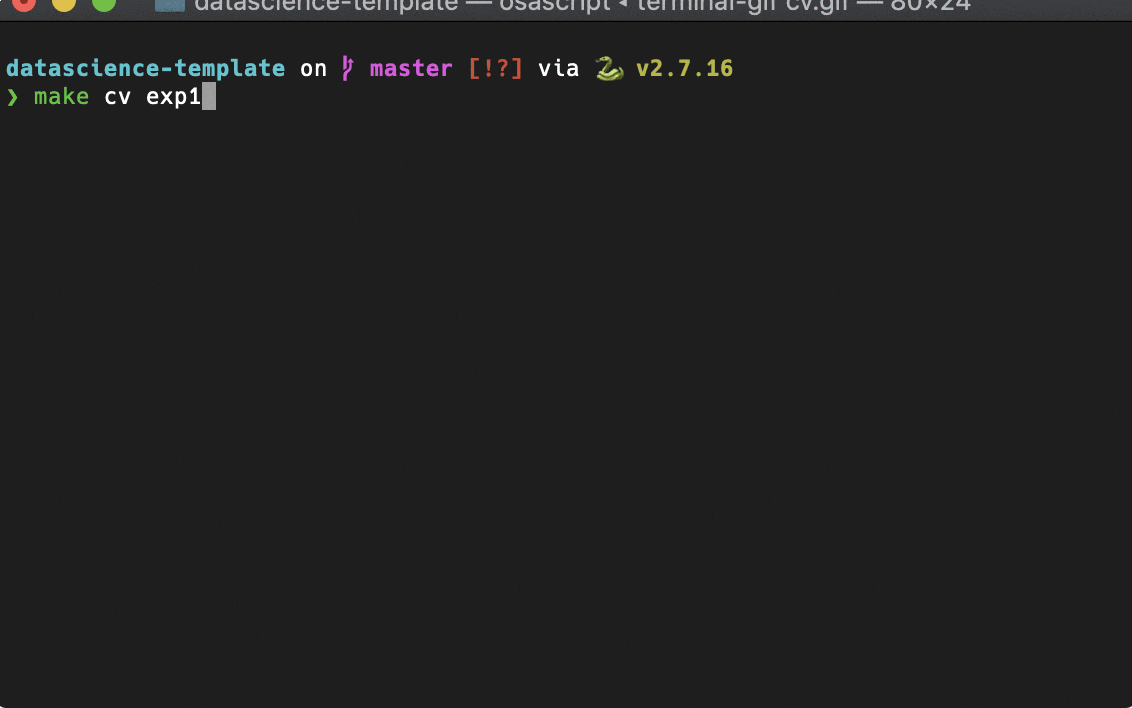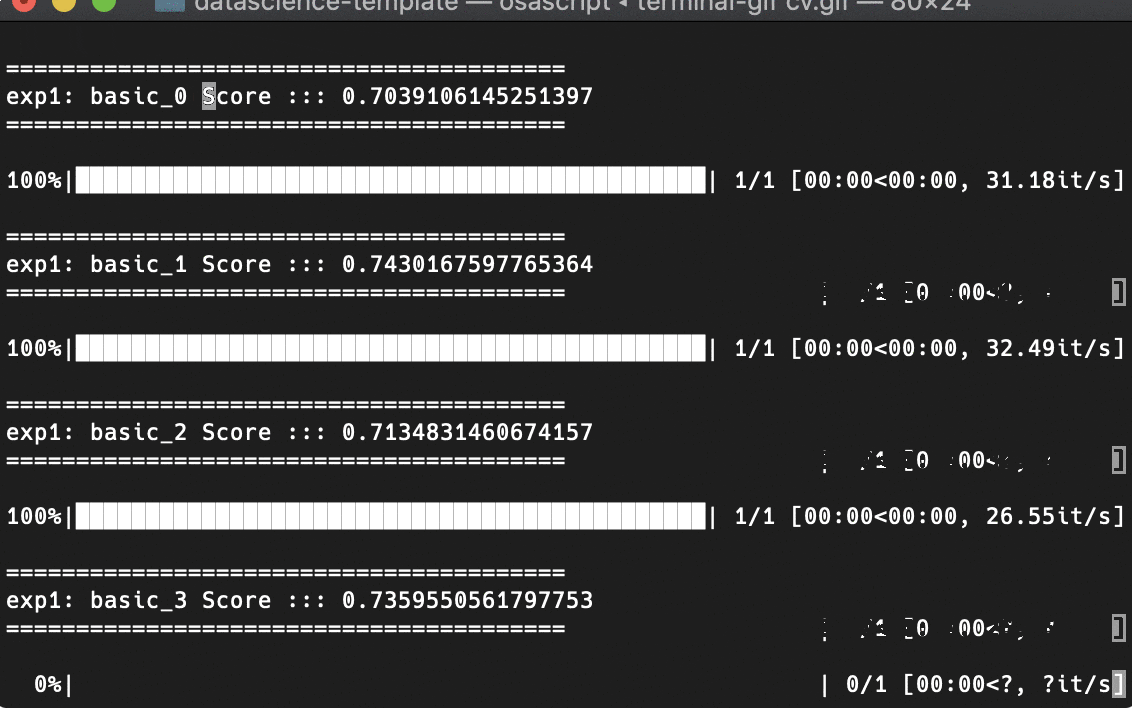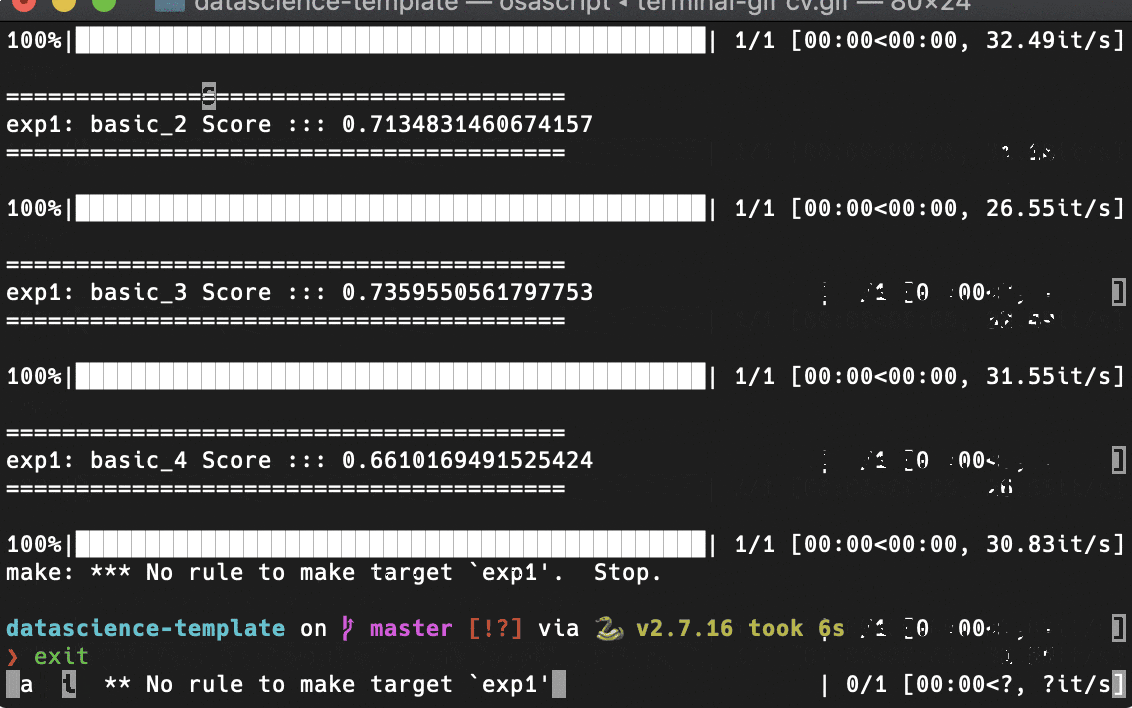
予測
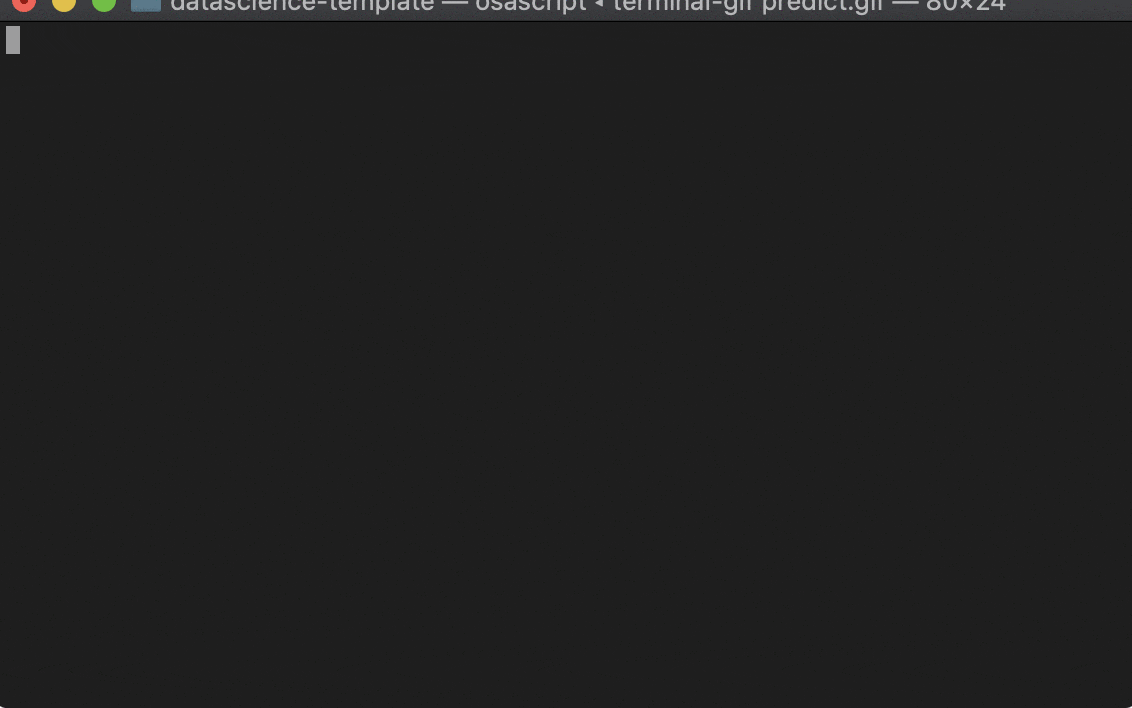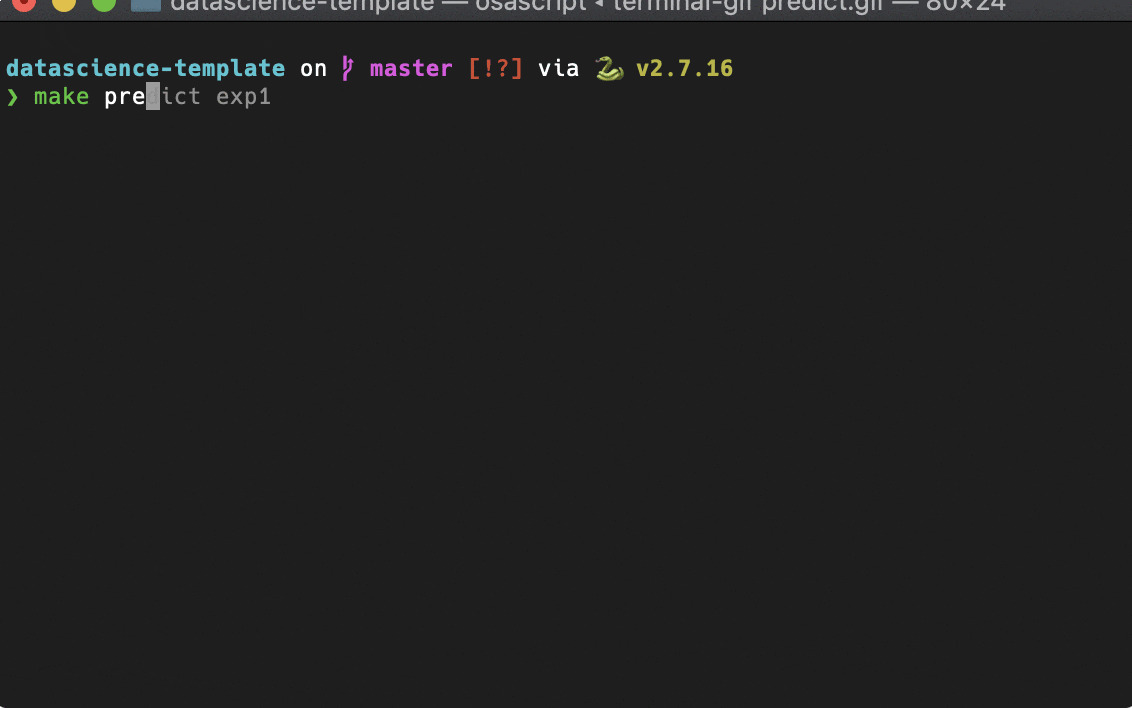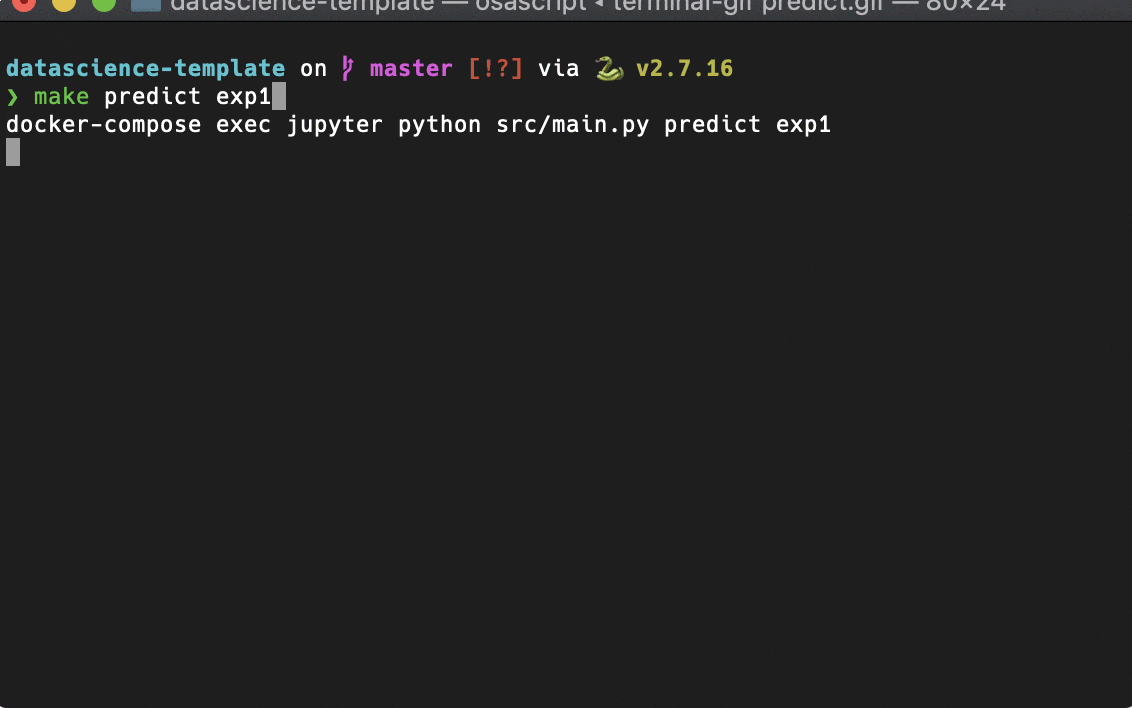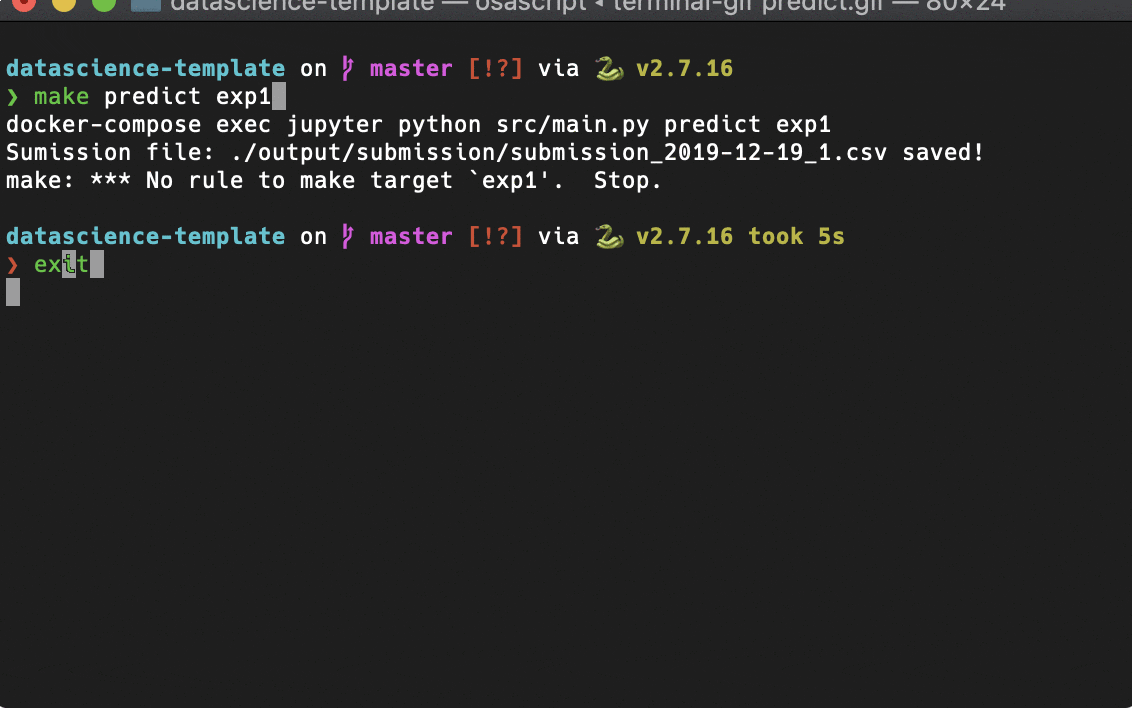
こんな感じで、よくやる操作はmakeコマンドで実行できるようにしました。
コードを書く量がただ減っただけなのですがかなり快適にコーディングできます。
まとめ
今回は、コードがメインになるので、記事のなかではサラッと説明するだけにとどめました。
「面白そう」と思った方は、是非是非Cloneして使ってみてください!!
最後に
プルリク&フォーク歓迎です!!!どなたでも気軽にお願いします!!!