概要
スパースモデリング第14章「画像のノイズ除去」を実装した。
- ウェーブレット縮小
- 重複したパッチベースのDCT縮小
- 重複したパッチベースのDCT学習縮小曲線
- 重複したパッチベースのDCT大域的学習縮小曲線
- 冗長DCT辞書によるOMPノイズ除去
- K-SVD辞書によるOMPノイズ除去
- NL-means
- BM3D
を比較した。
ノートブック
ch14-01.ipynb
ch14-02.ipynb
ch14-03.ipynb
ch14-04.ipynb
ch14-05.ipynb
結果

数字はピーク信号対雑音比(PSNR; peak signal to noise ratio)[db]
K-SVDむっちゃ計算時間かかるわりに、NL-means、BM3Dの方が強くて草はえた。実装がいかんのかもしれんが…
方法
テスト画像
Barbaraにσ=20のガウシアン雑音を追加し、テスト画像とした。各手法でノイズ除去した。

ウェーブレット縮小
ウェーブレット変換して、ハード閾値処理した。
閾値によって性能が変化した。


重複したパッチベースのDCT縮小
画像から8x8のパッチを抽出した。
パッチをDCT変換して、ハード閾値処理した。
パッチの重なりの平均を取った。
閾値によって性能が変化した。


縮小曲線学習
閾値処理は入力値と出力値の関係をあらわす曲線とみなせる。多項式フィッティングにより、ノイズなし、ありのパッチのペアから最適な縮小曲線を学習した。
$$ F_{local}(S) = \Sigma_{k=1}^{M}||p_{k}^{0}-AS\{A^{T}p_{k}\}||^{2}_{2}$$
_S_は閾値処理、$A^{T}$はDCT変換、$p^{0}$はノイズなしのパッチ、M_は訓練データの総数。$F{local}$を最小にするSのパラメータ(多項式の係数)を最小二乗法で求めた。
DCTの各要素ごとに縮小曲線を学習する。パッチの大きさ$6 \times 6$とした。非冗長なDCTを用いたため、DCT後の要素数も$6 \times 6$となる。縮小曲線の本数は36本となる。
縮小曲線学習の訓練データ

lenaの$200 \times 200$の領域からパッチを抽出し、訓練データとした。127引いて128で割って規格化した。
結果
各マスの曲線は、各DCT係数に対する縮小曲線をあらわす。
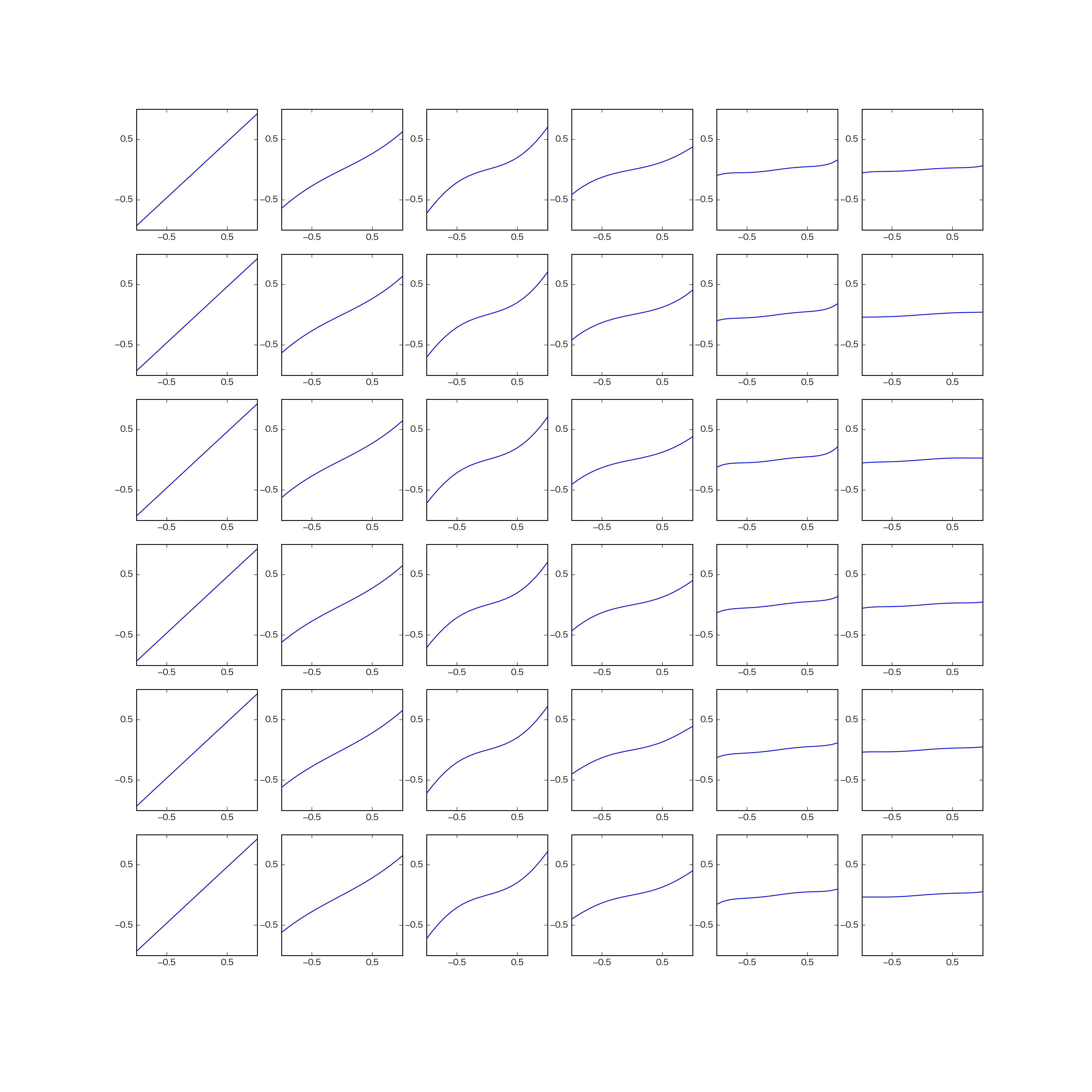

大域的な縮小曲線学習
$$ F_{global}(S) = ||y_{0} - \frac{1}{n}\Sigma_{k=1}^{M}R_{k}^{T}AS\{A^{T}p_{k}\}||^{2}_{2}$$
を最小にする縮小曲線のパラメータを求める。$R_{k}$はk番目のパッチを画像から抽出するオペレータ。


縮小曲線の傾きがほぼ0だけど一応使えているよう…
DC成分が0になってしまうため、後処理でスケーリングしている。
(実装がおかしいかも…)
冗長DCT辞書によるOMPノイズ除去
画像から8x8のパッチを抽出した。
パッチを冗長DCT変換して、OMPによりスパース符号化した。
パッチの重なりの平均をとった。
ノイズありの画像と重み付き平均をとった。
OMPで求めるスパース表現の非ゼロの要素数$k_0 = 4$とした。OMPの許容誤差$\epsilon = 8^2 \times 20^2 \times 1.15$とした。ノイズありの画像の重み0.5、ノイズ除去した画像の重み1として、重み付き平均をとった。
冗長DCT辞書
$8 \times 8$のパッチを$16 \times 16$の成分に変換する


K-SVD辞書によるOMPノイズ除去
ノイズありの画像からパッチを抽出し、K-SVDにより辞書を求めた。
求めた辞書を用いて、上と同様に処理した。
K-SVD辞書


NL-means
Buadesらの有名なNL-means
辞書学習の観点からは、NL-meansは、画素ごとに異なる辞書を持つ、極端な辞書学習と見ることができる。
関心画素を中心とした探索窓を考える。
探索窓内の各画素を中心としたパッチの集合を辞書と考える。
関心画素を中心としたパッチ(関心パッチ)との二乗誤差にもとづいて、各アトムの係数を求める。
これは関心パッチの密な表現となる。
このような観点から辞書学習、NL-meansをそれぞれ改良できる。

BM3D
Dabovらの有名なBM3D。ガウシアンノイズには最強である。
BM3Dも辞書学習の観点から見られる。
ブロックマッチング(BM; block matching)により探索窓内で関心パッチに類似したパッチを集めスタックして3Dパッチとする。
3Dパッチをスパーシファイ変換(ウェーブレット、DCTなど)し、ハード閾値処理、ウィーナー縮小して、ノイズ除去する(協調フィルタリング)。
構造化辞書学習や、クラスタリングと辞書学習の組み合わせに通ずる。

まとめ
- 計算時間のわりにK-SVD辞書+OMPノイズ除去より、NL-means、BM3Dの方が高性能であった。
- 辞書学習とスパース符号化は、理屈がおもしろい。
- NL-meansの画素ごとのローカルな辞書、BM3Dの協調フィルタリングの考えから、クラスタリングと辞書学習の組み合わせなどが研究されている。
- 計算時間の問題はあるが、辞書学習とスパース符号化に、NL-means、BM3Dのアイデアを応用したものが将来的にはBM3Dを超える?
参考
