ETLに関して
普段取得しているデータというのはそのままでは分析することが出来ないです。それは取得したデータにはデータフォーマットがばらばらであったり、非構造化データがあったりするからです。そのため、ETLという処理が必要になってきます。ETLとは「Extract」「Transform」「Load」の略になります。簡単にETLの説明するとさまざまな形式のデータを一定の形式に統一して保存する処理のことです。 一般的に、データウェアハウスにデータを保存する際の前処理として行われます。AWSのサービスではGlueがこれに当たります。
Glueに関して
AWSのGlueはデータの抽出や変換、ロードなどを簡単に行える完全マネージド型のサービスになります。サーバーレスであるため、自分たちでインフラ周り管理する必要がないです。Glueは大きく3つの機能に分かれます。「データカタログ」、「サーバーレスエンジン」、「オーケストレーション」です。
データカタログとは…メタデータを管理するリポジトリ機能のこと。このデータカタログを作成する方法は3つあります。「Glueクローラー」「GlueのAPI」「Hive DDL(Athena , EMR , Redshift , spectrum)」です。データソースとしてはAmazon DynamoDB , S3 ,Redshift , RDS などがあります。管理しているメタデータはAmazon Redshift spectrum,Amazon Athena , Amazon EMRに連携することが可能。データカタログはデータのスキーマ情報(データのカラム名やデータ型)を持ち、データベースごとに管理します。データそのものは持っていません。あくまでもデータの情報を持っているという感じです。使い方としてはAthenaで分析する際にデータレイクのS3からデータを持ってきます。その際にS3にあるデータがどのようなデータであるのかが分からないのでGlueクローラーで分析してカタログを作成し、それを参照しながらAthenaはクエリを行う流れになります。データカタログはクローラーで解析したメタデータを管理するっていう感じです。接
Apache hiveメタストアとは…Apache hiveで実データとは別に表の定義だけ格納する仕組みです。実データはHDFSやS3などに保存します。
クローラーとは…Glueのデータカタログにメタデータを作成するプログラムのこと。クローラを使用せずにテーブル定義をAPI経由で登録することも可能。
スキーマの管理…Glueではスキーマをバージョン管理することが可能。
接続方法…S3とDynamoDBに接続する際にはIAMロールでアクセスする。Redshift,RDS,オンプレミスDB,RDB on EC2に接続する際には事前に接続設定を追加して接続を行う。
ジョブとは…ETLの処理単位をジョブという。ジョブは3種類から選択することが可能です。「python shell」「spark」「spark streaming」の3つです。sparkによる並列分散処理なんかが行えたりします。これはS3のデータをデータカタログ経由でデータをとってくると何かと便利だったりします。ジョブはトリガーにて実行のタイミングを定義することができる。ジョブではGlueが自動生成したコード、自身で作成するスクリプト、既存のコードが実行可能。
DPUとは…DPUとはジョブ実行時に割り当てられる処理能力のこと。1DPU = 4vCPU , 16GBメモリ。
DynamicFrameとは…DynamicFrameとはSparkSQL DataFrameと似たGlue特有の抽象化の概念。DynamicFrameはスキーマ不一致を明示的にエンコードするschema on the fly を採用している。複数の型の可能性を残し、あとで決定できるようにするchoice型というのがある。そのため、一つの列に複数のデータ型を持つことが可能です。DynamicFrameとDataFrameではそれぞれ変換することが可能。しかし、pandasのDataFrameとは異なるため注意が必要になります。
ブックマーク機能…ジョブの実行状態を保持する機能であり、定常的にETL処理が必要な場合において有効。
トリガー…ジョブを開始するための定義を設定できる機能。スケジュール(日時、曜日)、ジョブイベント、手動で指定することが可能。
とりあえず実装してみる。
今回はS3 にあるjsonデータを変更してS3 に戻すというETL作業を行っていきたいと思う。
今S3にこのようなデータがあるとします。
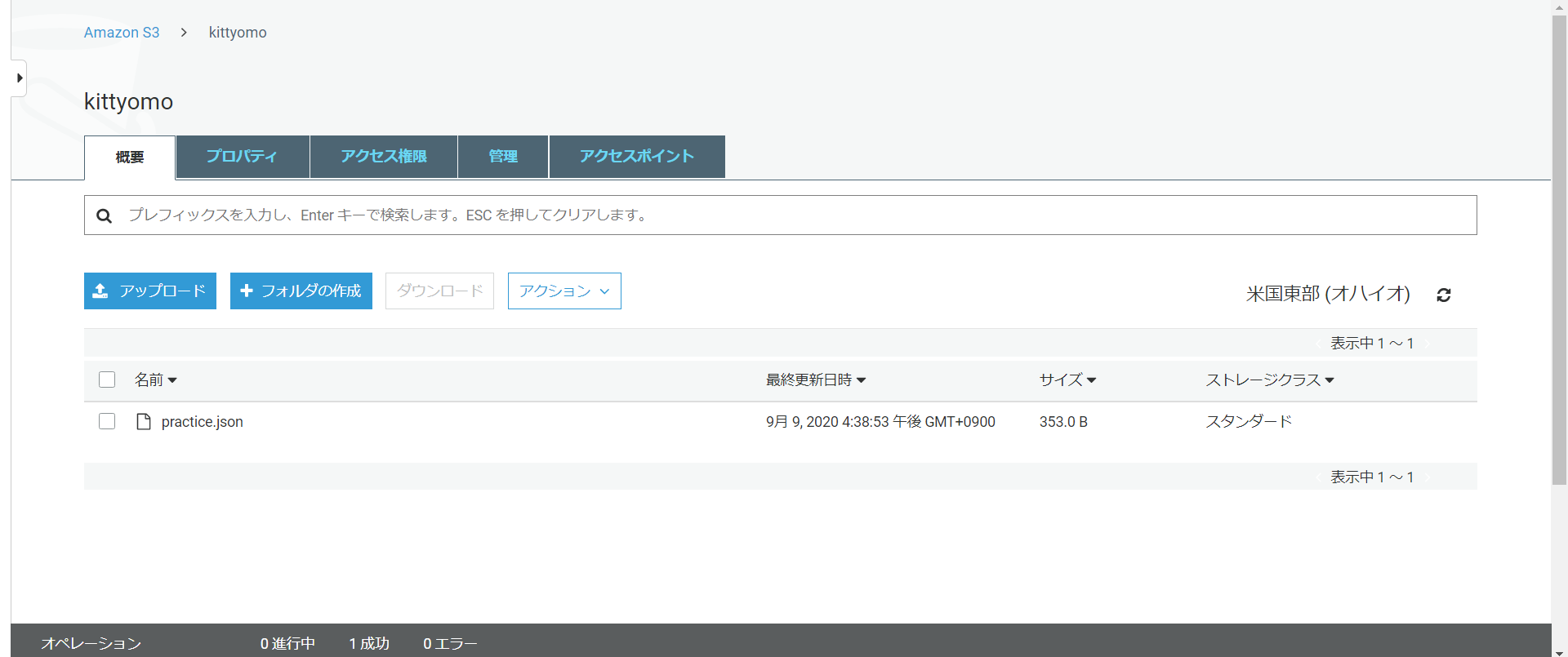
データの中身はこんな感じになっています。
[{
"user": "太郎",
"age": "23",
"gender": "男"
},
{
"user": "次郎",
"age": "18",
"gender": "男"
…………
今回はageのデータ型を変更して、"user"を"name"に変更していきたいとをもいます。
まず初めにGlueのクローラーを使用してテーブルを作成します。
AWSのGlueの画面でクローラを選択します。次にクローラの追加を選択します。
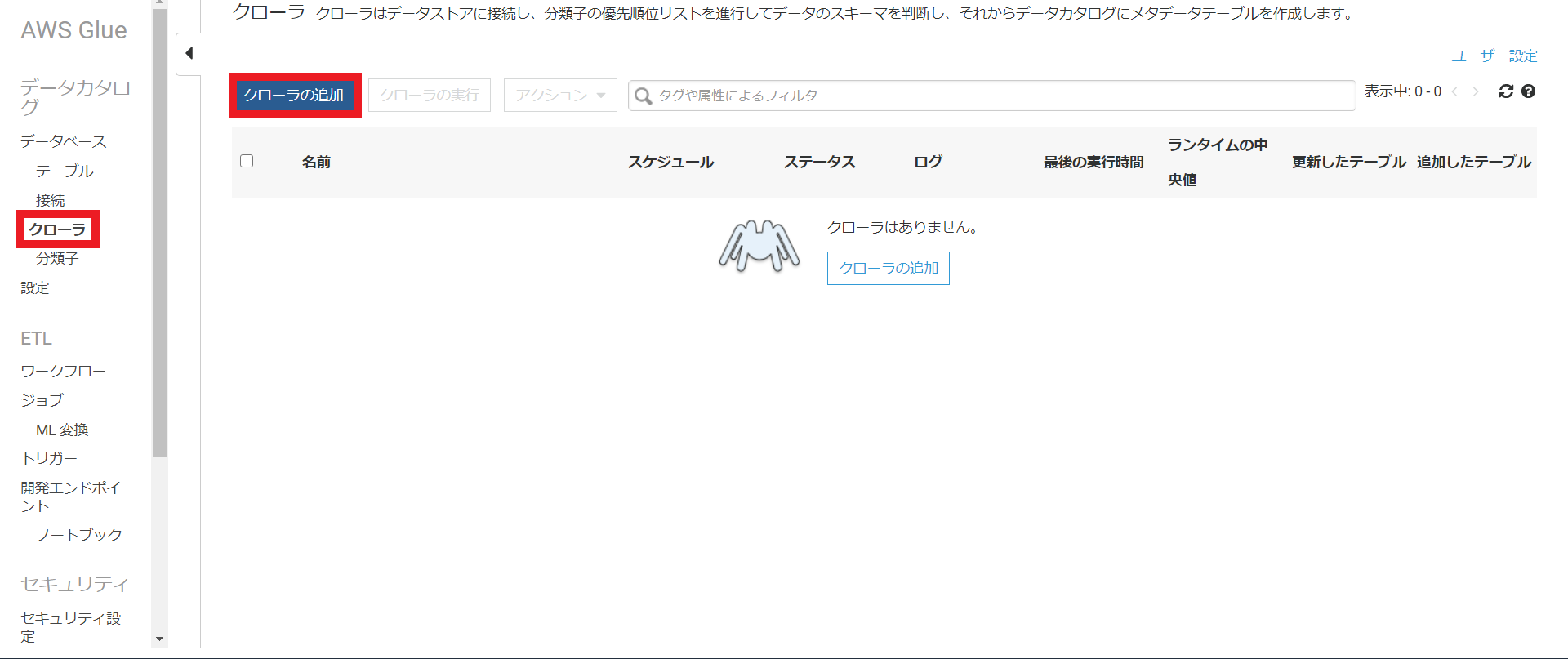
クローラの名前は適当に入力します。
Specify crawler source typeはData Storesを選択。
データストアの追加でどこからデータを取得するのか設定します。
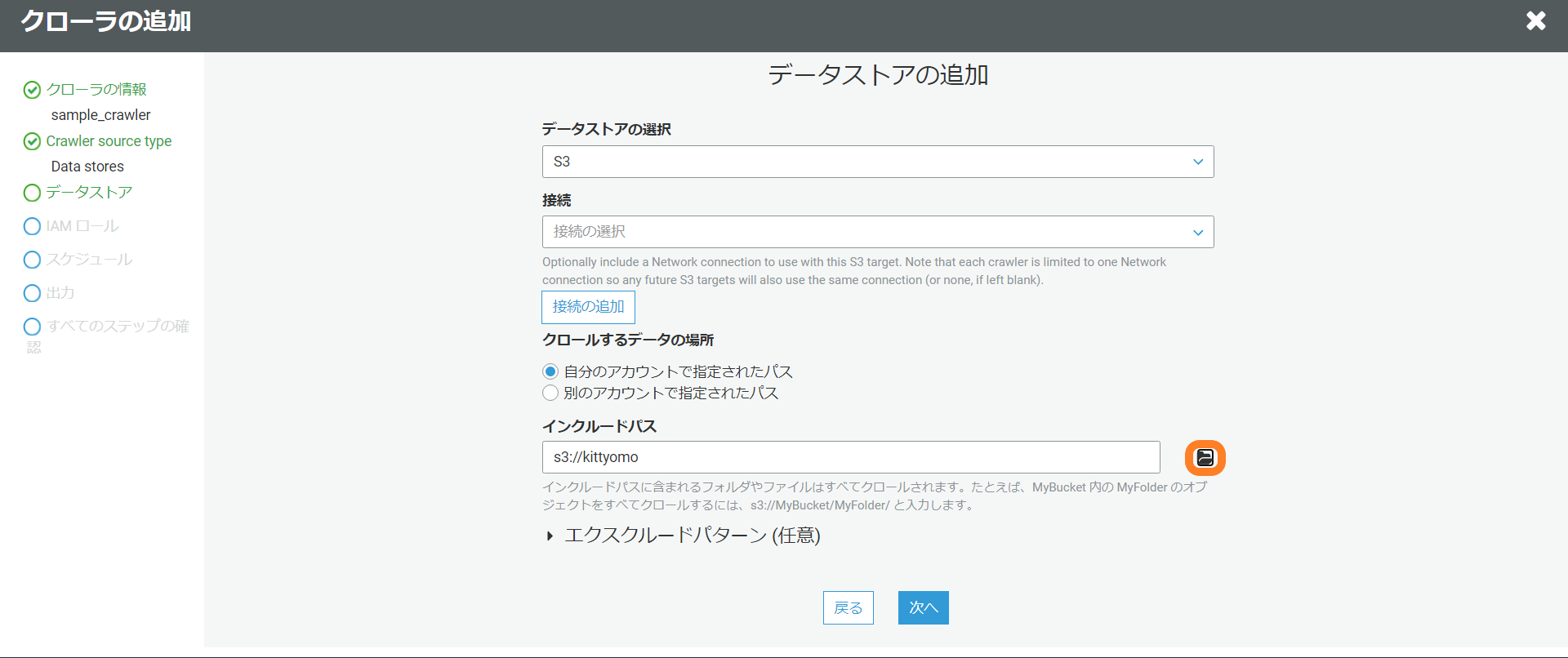
別のデータストアの追加はしないのでいいえを選択。
IAM ロールの選択は・IAM ロールを作成するを選択、名前は適当に入力。
クローラのスケジュールを設定は特に時間とか指定しないのでオンデマンドで実行を選択。
クローラの出力を設定では今回はデータベースの追加で新しくデータベースを作成しました。
これで内容を確認して大丈夫であれば完了になります。
完了するとクローラの画面で作成されているのが確認できるので実行します。
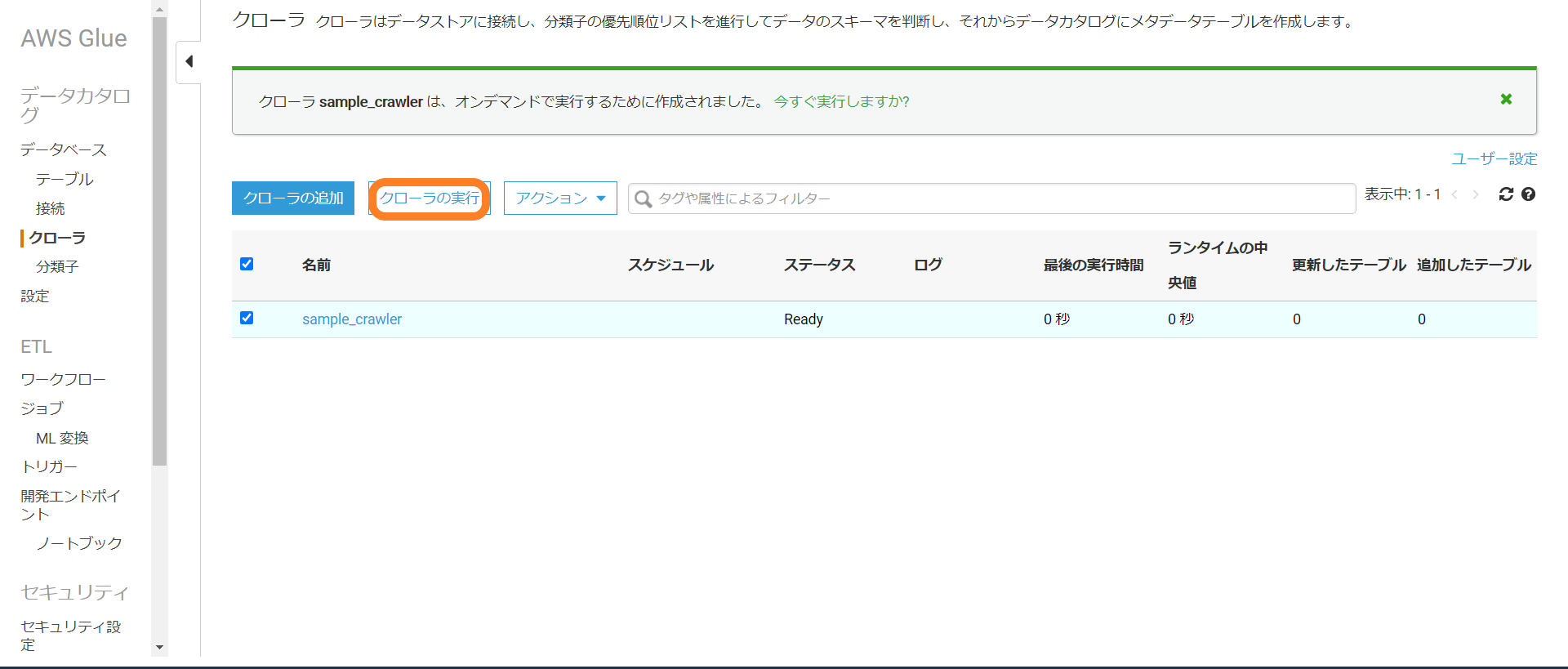
実行が完了するとテーブルにスキーマが登録されているのが確認できます。
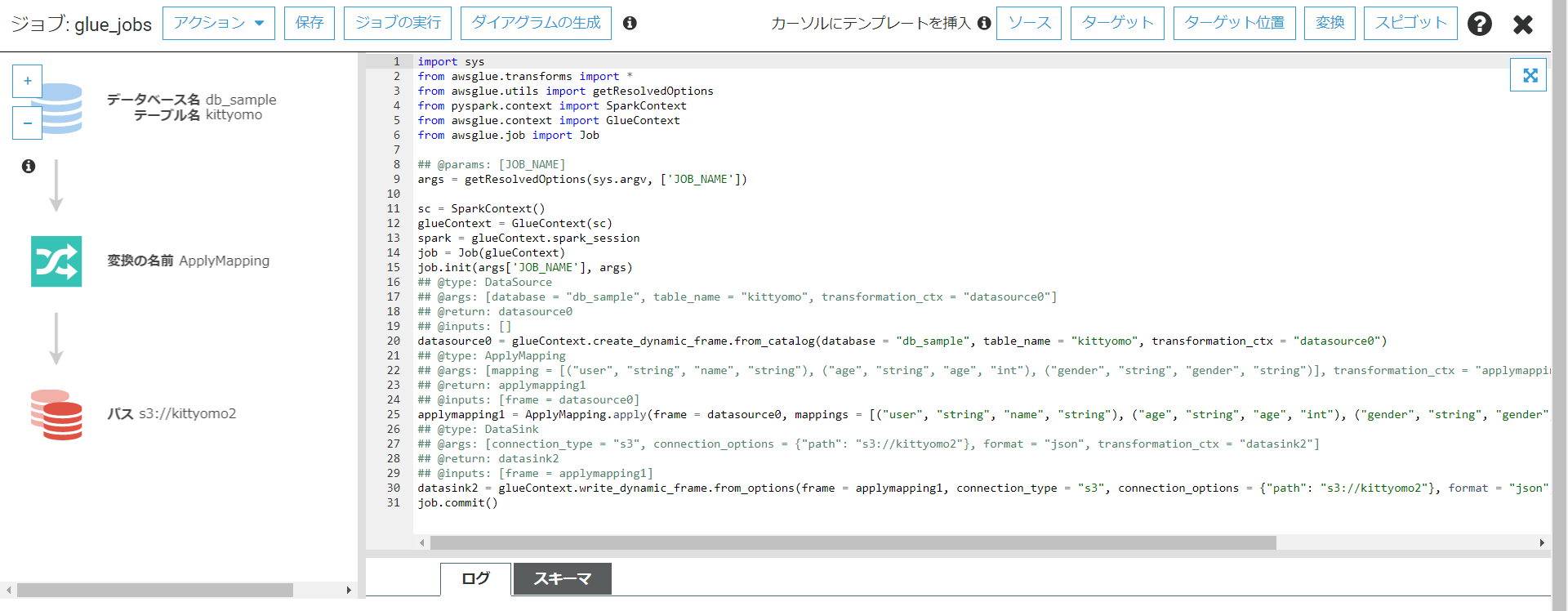
次にジョブの作成を行います。
Glueが自動生成してくれるスクリプトを利用します。
データソースは先ほど作成したものを使用します。
今回はageのデータ型を変更して、"user"を"name"に変更していくのが目的だったのでポチポチしながら行っていきます。マッピングも簡単に行うことが出来ました。
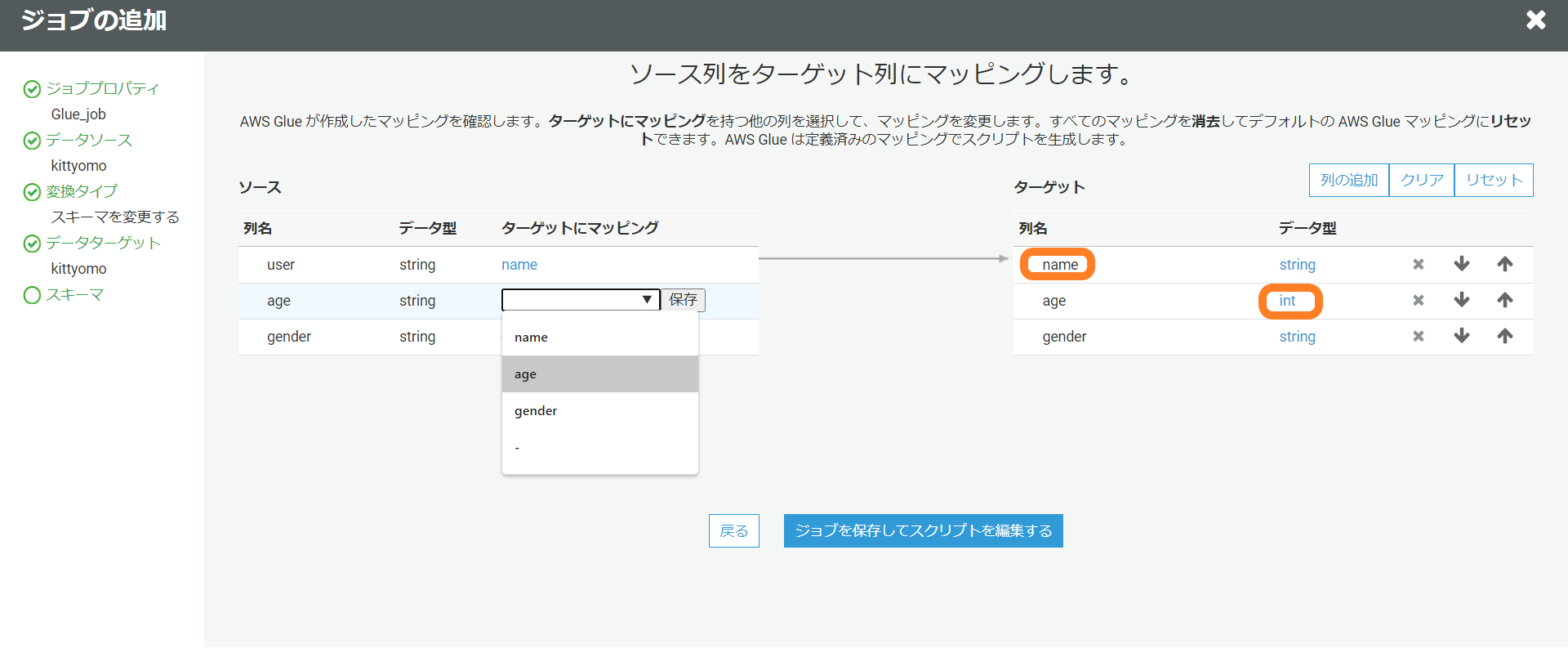
そうするとGlue JObスクリプトが自動生成されます。
ジョブの実行をします。