はじめに
最近スクレイピングに関して学んで実装をして見ました。今回作成したのは「CiNii Articles - 日本の論文をさがす - 国立情報学研究所」でキーワードを入力し、そのキーワードにヒットした論文の「タイトル」「著者」「論文掲載媒体」をすべて取得しCSVに保存するというものです。
スクレイピングの学習を行う上でいい勉強になったので記事にして見ました。スクレイピングの学習をしている方に役立つことを願っています!
コード
以下が自分自身が作成したコードになります。説明に関してはコードと一緒に書いてあるのでそれを見ていただければと思います。また、実際に「CiNii Articles - 日本の論文をさがす - 国立情報学研究所」のサイトに行って、Chromeの検証機能を使用し実際にHTMLの構造を見ながら行うと理解が深まると思います。
今回このコードを「search.py」として保存しました。
import sys
import os
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
def main():
url ='https://ci.nii.ac.jp/search?q={}&count=200'.format(sys.argv[1])
res = requests.get(url)
soup = BeautifulSoup(res.content , "html.parser")
#検索件数を調べる。
#textには'\n検索結果\n\t\n\t0件\n\t'こんな感じのデータが入っている。
search_count_result = soup.find_all("h1" , {"class":"heading"})[0].text
#正規表現を使用して検索件数を取得
pattern = '[0-9]+'
result = re.search(pattern, search_count_result)
#検索結果がない場合はここで関数は終了
search_count = int(result.group())
if search_count == 0:
return print('検索結果はございません。')
print('検索件数は' + str(search_count) + '件です。')
#データを保存するディレクトリの作成。
try:
os.makedirs(sys.argv[1])
print("新しいディレクトリが作成されました。")
except FileExistsError:
print("すでに存在しているディレクトリになります。")
#すべての検索結果を取得する為、forの回数を取得する。
#今回は200件ごとに表示を行うようにしたため200に設定しています。
if search_count // 200 == 0:
times = 1
elif search_count % 200 == 0:
times = search_count // 200
else:
times = search_count // 200 + 1
#著者・タイトル・掲載媒体を一気に取得
title_list = []
author_list = []
media_list = []
#ここで空白文字の削除を行うための処理
escape = str.maketrans({"\n":'',"\t":''})
for time in range(times):
#urlを取得
count = 1 + 200 * time
#search?q={}ここに検索したいキーワードが入ります。
#count=200&start={} 200ごとにカウントし、何番目から表示するかを入力しています。
url ='https://ci.nii.ac.jp/search?q={}&count=200&start={}'.format(sys.argv[1], count)
print(url)
res = requests.get(url)
soup = BeautifulSoup(res.content , "html.parser")
for paper in soup.find_all("dl", {"class":"paper_class"}):#1つの論文ごとにループを回す。
#タイトルの取得
title_list.append(paper.a.text.translate(escape))
#著者の取得
author_list.append(paper.find('p' , {'class':"item_subData item_authordata"}).text.translate(escape))
#掲載媒体の取得
media_list.append(paper.find('p' , {'class':"item_extraData item_journaldata"}).text.translate(escape))
#データフレームにしてCSVで保存する。
jurnal = pd.DataFrame({"Title":title_list , "Author":author_list , "Media":media_list})
#文字化けを防ぐためにエンコーディングを行っている。
jurnal.to_csv(str(sys.argv[1] + '/' + str(sys.argv[1]) + '.csv'),encoding='utf_8_sig')
print('ファイルを作成しました。')
print(jurnal.head())
if __name__ == '__main__':
# モジュールを直接実行した時だけ、実行したいコード
main()
実装してみた。
実際に作成したものを実装してみました。
まずターミナルに以下のように打ち込みます。
今回は機械学習を検索のキーワードとして入力しました。
機械学習というところに自分自身が検索したいキーワードを入力する形になります。
python search.py 機械学習
上手くいくと以下のようになります。
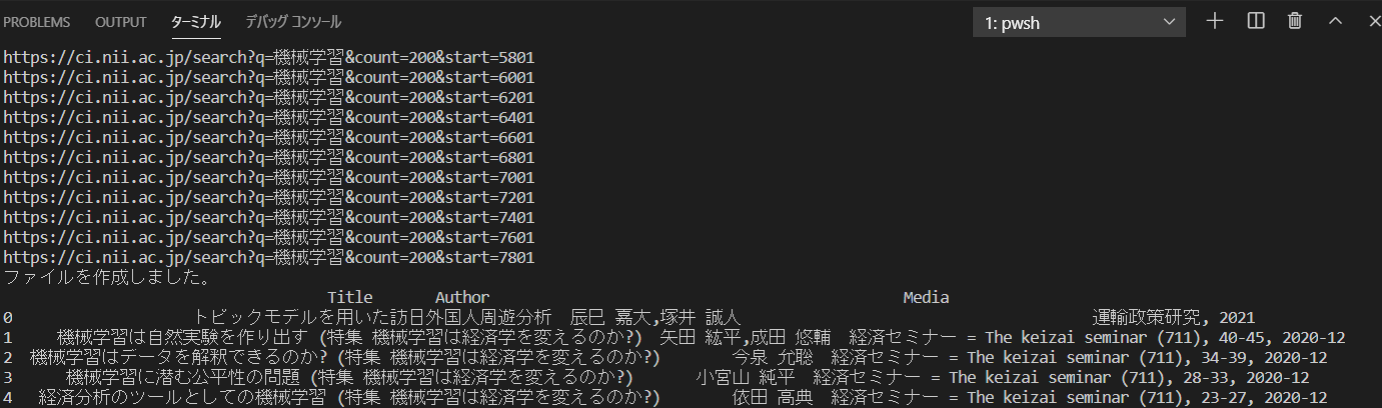
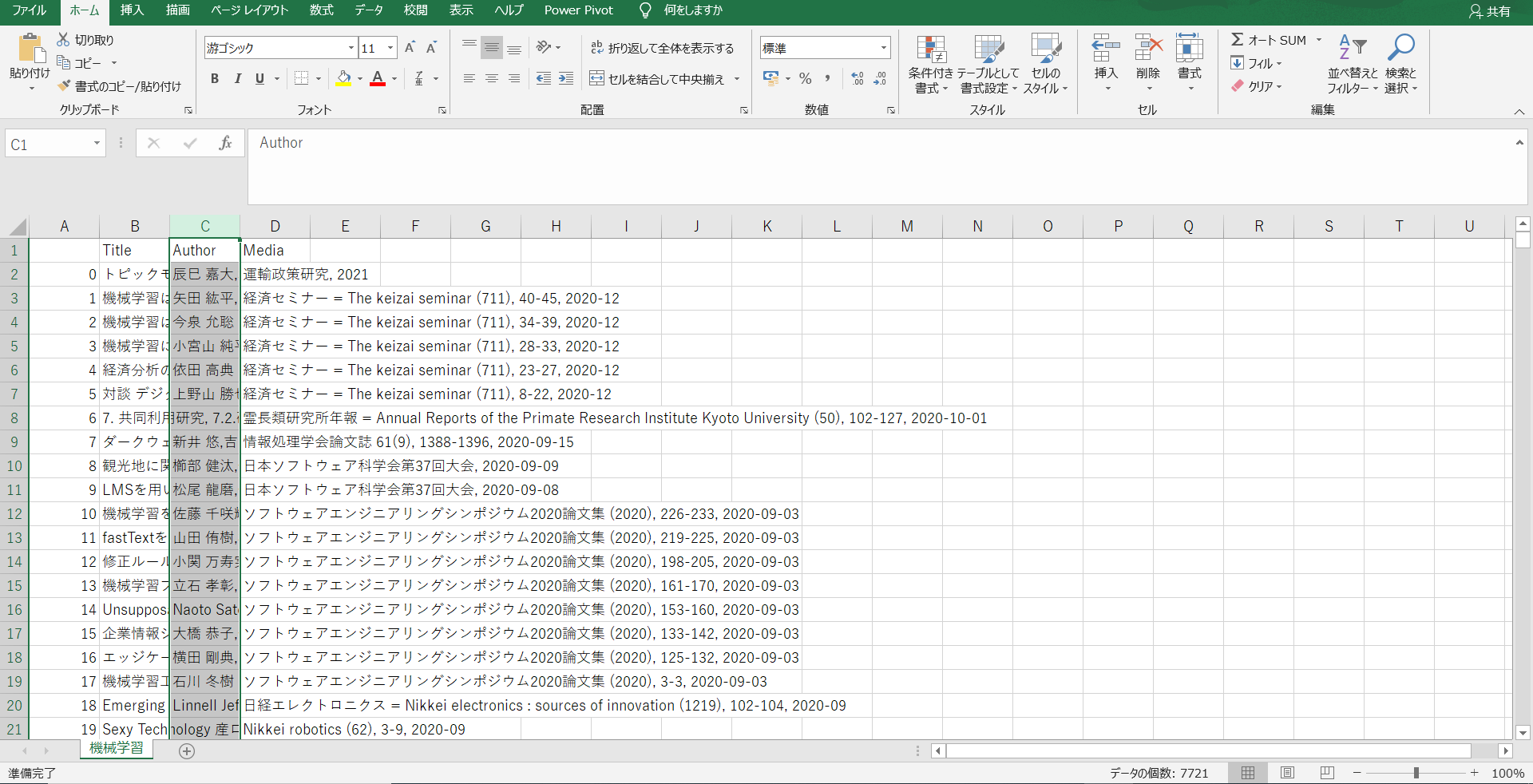
CSVの中身はこのような形になります。
最後に
いかがだったでしょうか?
私自身スクレイピングの学習をしたのは三日前ぐらいですが、コードは汚いものの実装するだけであれば比較的簡単に行うことが出来ました。
まだまだ、勉強することもあると思うので引き続き頑張りたいと思います。