Athenaとは
Athena(アテナ)とはAWSのデータ分析サービスであり、S3に格納されたデータに対して、集計やソートなどの分析を実行することができます。分析する際に使用する言語はSQLになり、実行したクエリに対してのみ料金がかかる。
サーバーレスであるため、インフラの管理は不要。S3にはデータだけが置かれているようなものです。そのため、S3に直接Athenaがクエリを行ってもデータの構造が分からないためうまくいきません。そのテーブル構造(メタデータ)を定義するのがGlueカタログです。一つのテーブルにつき一つのGlueカタログを作成します。AthenaはこのGlueカタログを参照しながらクエリを行うといった感じになります。このGlueカタログを作成するサービスの一つとしてGlueクローラーというものがあります。GlueクローラーはS3等においてあるデータ構造を推測して、データカタログに表構造を登録するサービスです。そのためAthenaがS3にあるデータをSQLでクエリを行うには、データカタログの作成が必要であり、データカタログを作成するためにGlueクローラを使用するといった感じです。
ではRDSからS3 にどのようにしてデータを持ってくるのか??それは、RDSのスナップショットからParquet形式でS3にexportすることが出来ます。その際、RDSからスナップショットを作成しS3に保存するときは、KMSという暗号化を行うサービスを使用して暗号化し、S3に保存されることに注意が必要です。そのため、Glueクローラーでデータカタログを作成する際にはKMSで複合する操作が必要になってきます。
Athenaの実装
今回はS3にあるデータをAthenaで分析するのを想定して行っていきます。
今S3には一つのCSVファイルが入っています。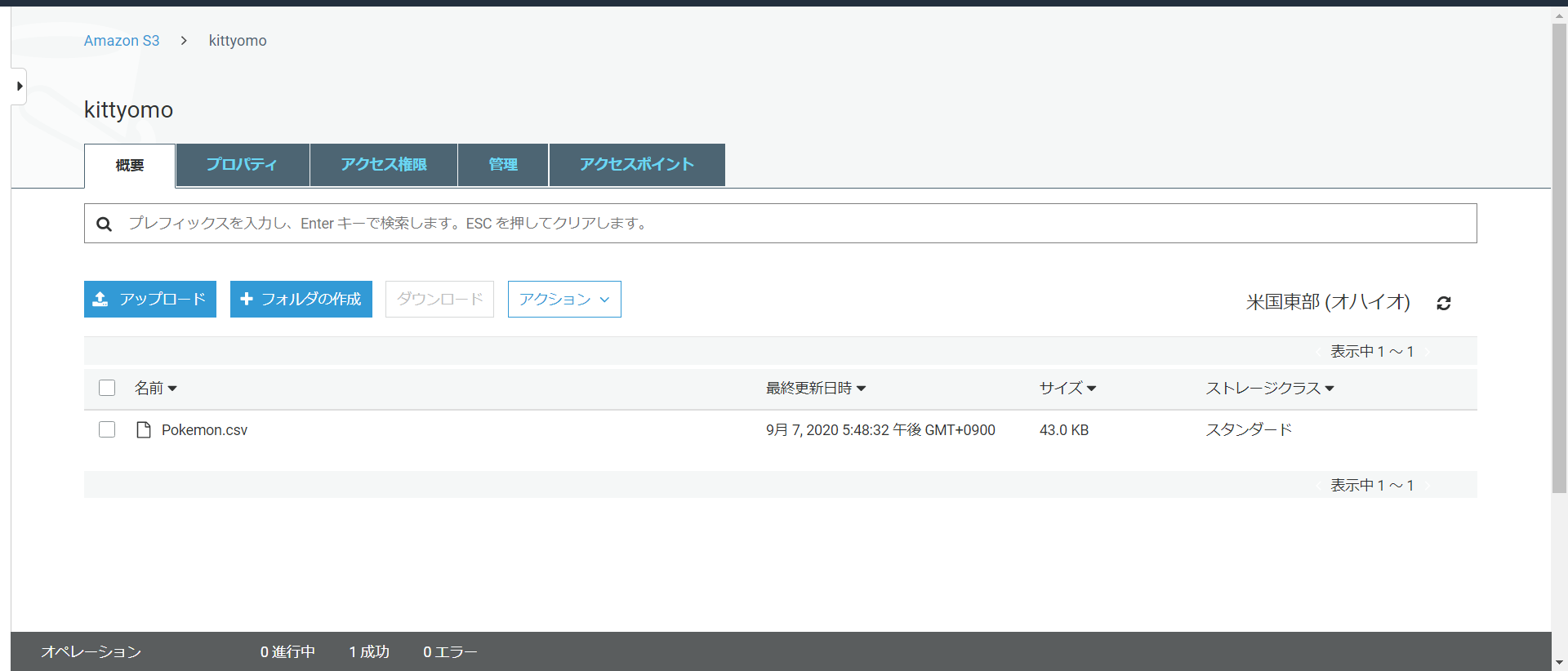
次にGlue クローラーでデータカタログを設定します。
Glueの画面に移動しクローラを選択。その後クローラの追加を押します。
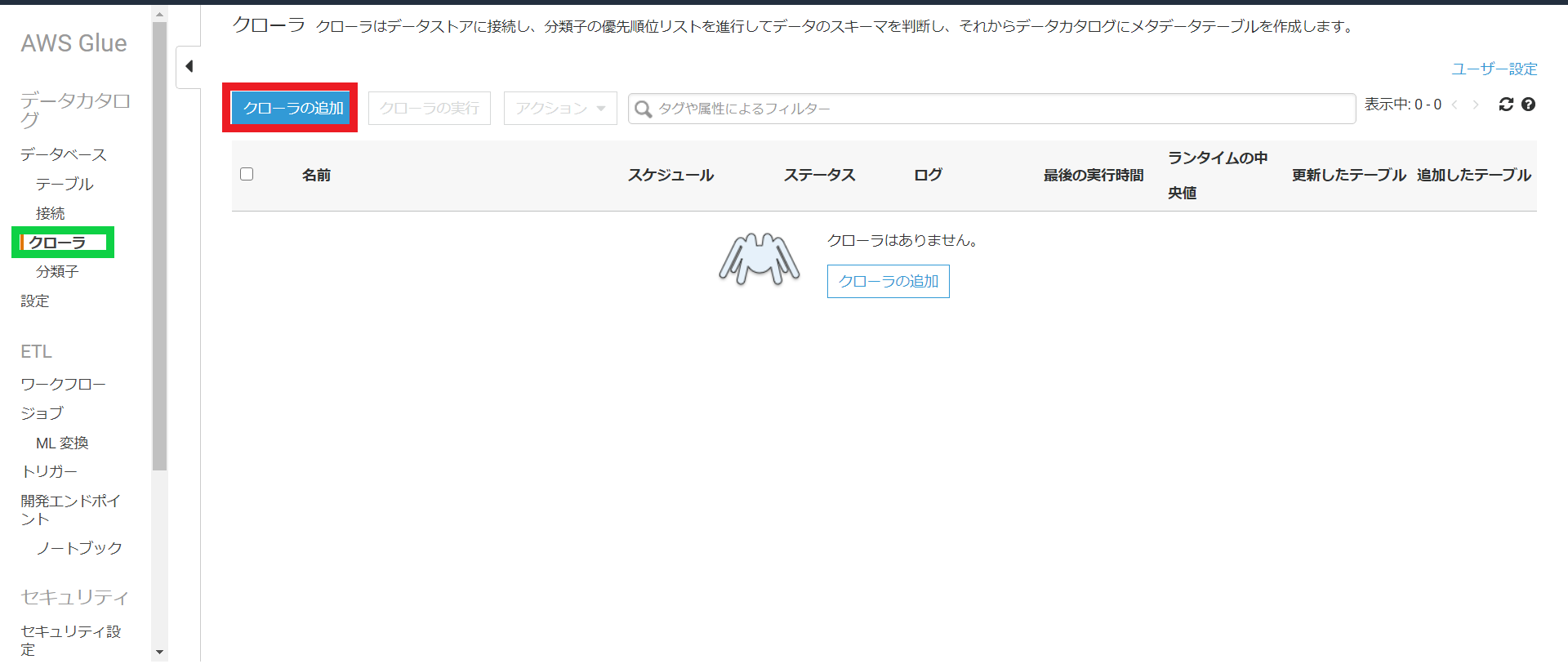
クローラの名前は適当に設定し、source typeはDatastoreを設定します。
クロールするS3のパスを選択するには下図の赤いところを選択すると、自分のAWSアカウントのS3バケットの一覧が表示されるので使用するS3バケットを選択します。
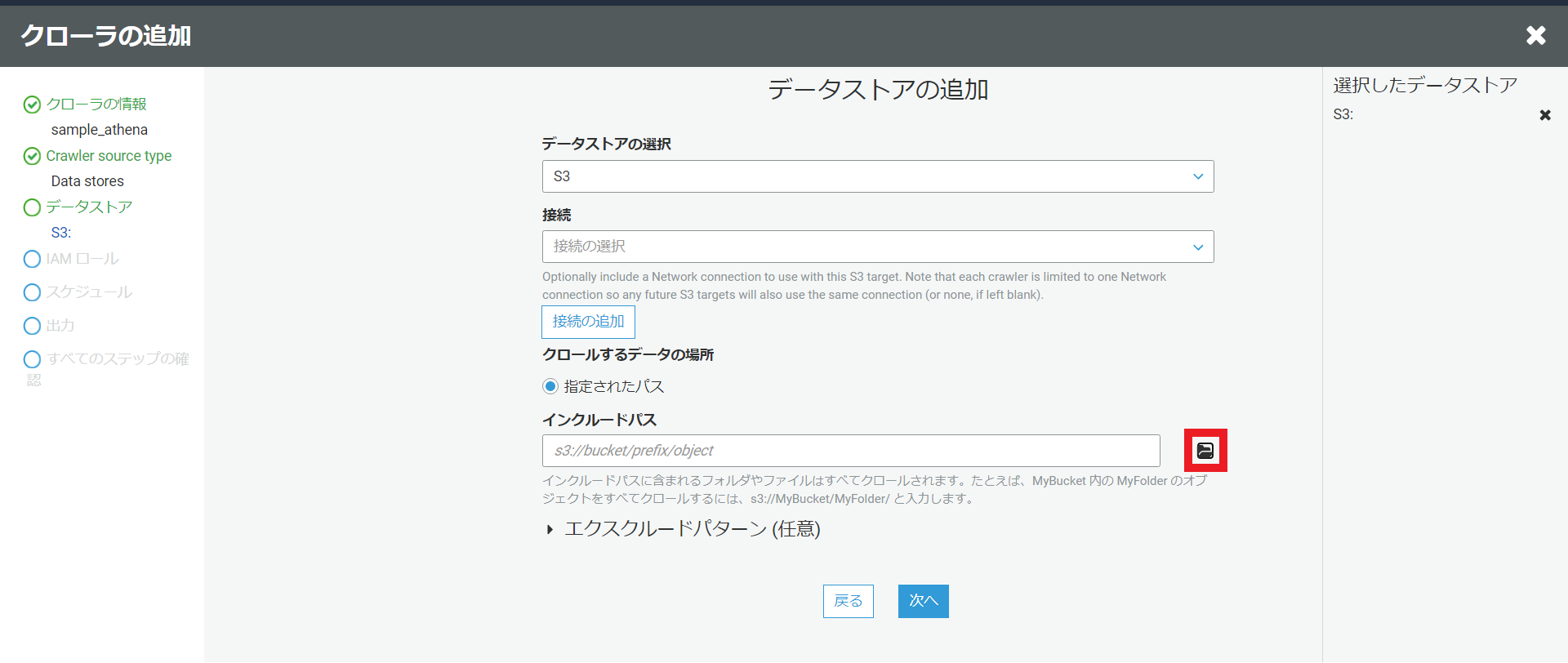
別のデータストアの追加は今回は必要ないため、いいえを選択します。
Glueクローラー用のIAMを選択。今回は新しく作成しました。
Glueクローラのスケジュールは今回一回のみでよいのでオンデマンドで実行を選択します。Glueクローラーは定期的に実行することも可能であるので定期的に実行したいときは頻度に応じて設定を行います。
テーブル定義情報を取得したいデータベースの情報を入力します。今回は新しくデータベースを追加します。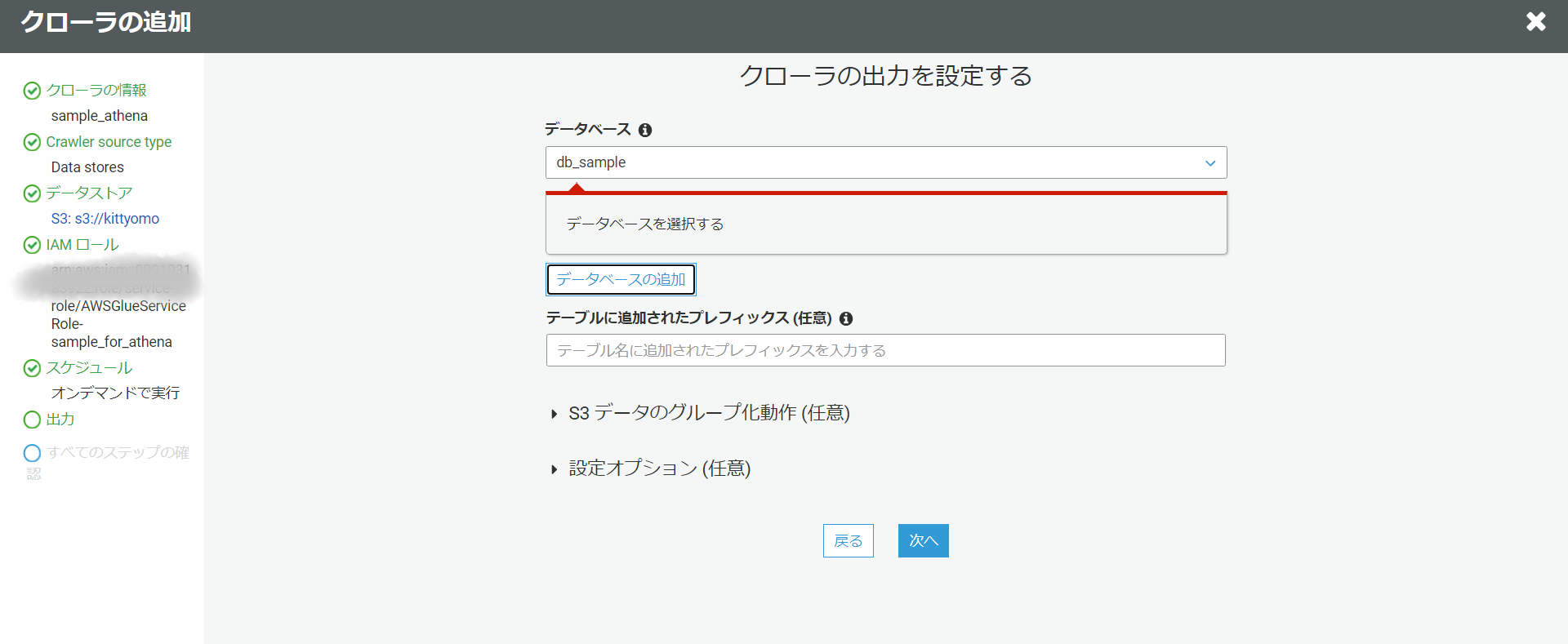
内容を確認し大丈夫であれば完了を押します。
そしたら今作成したクローラを選択し、クローラの実行を押します。
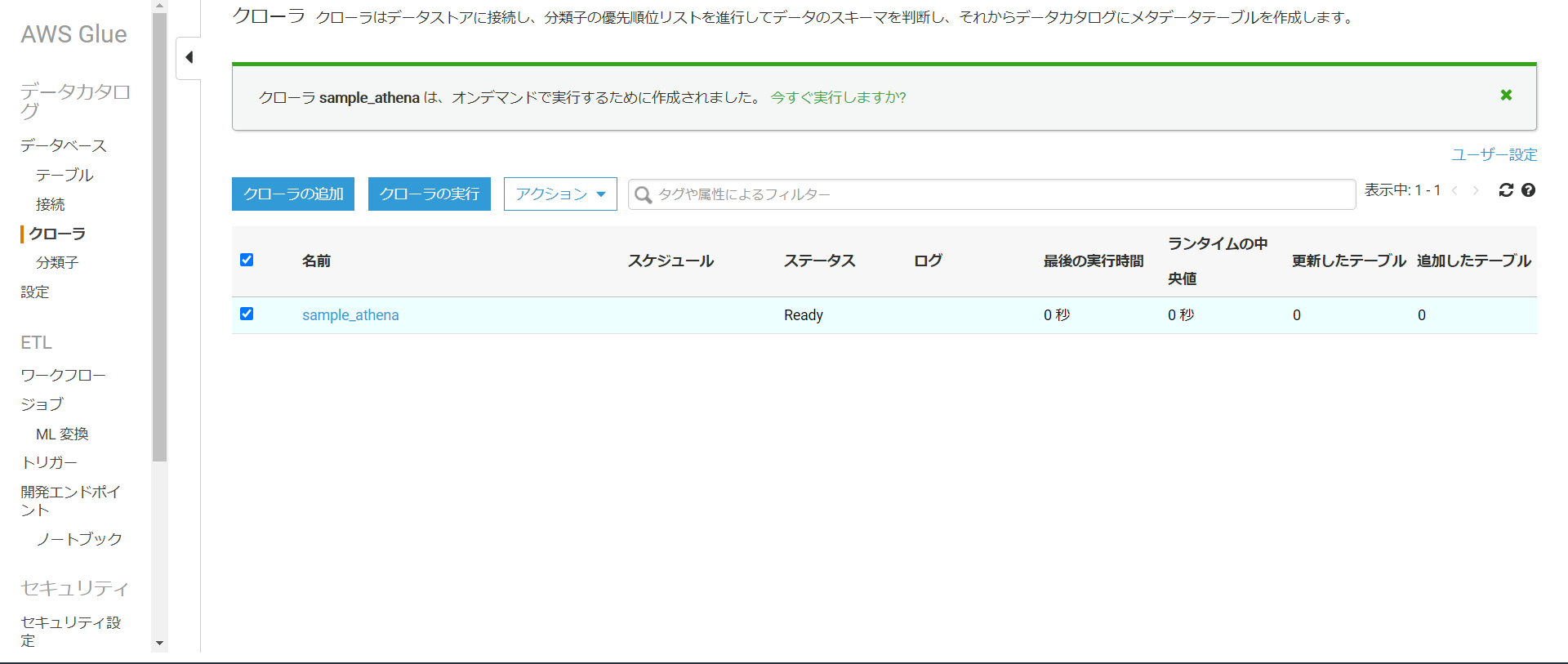
実行が終わるとテーブルでカタログが作成されていることが分かります。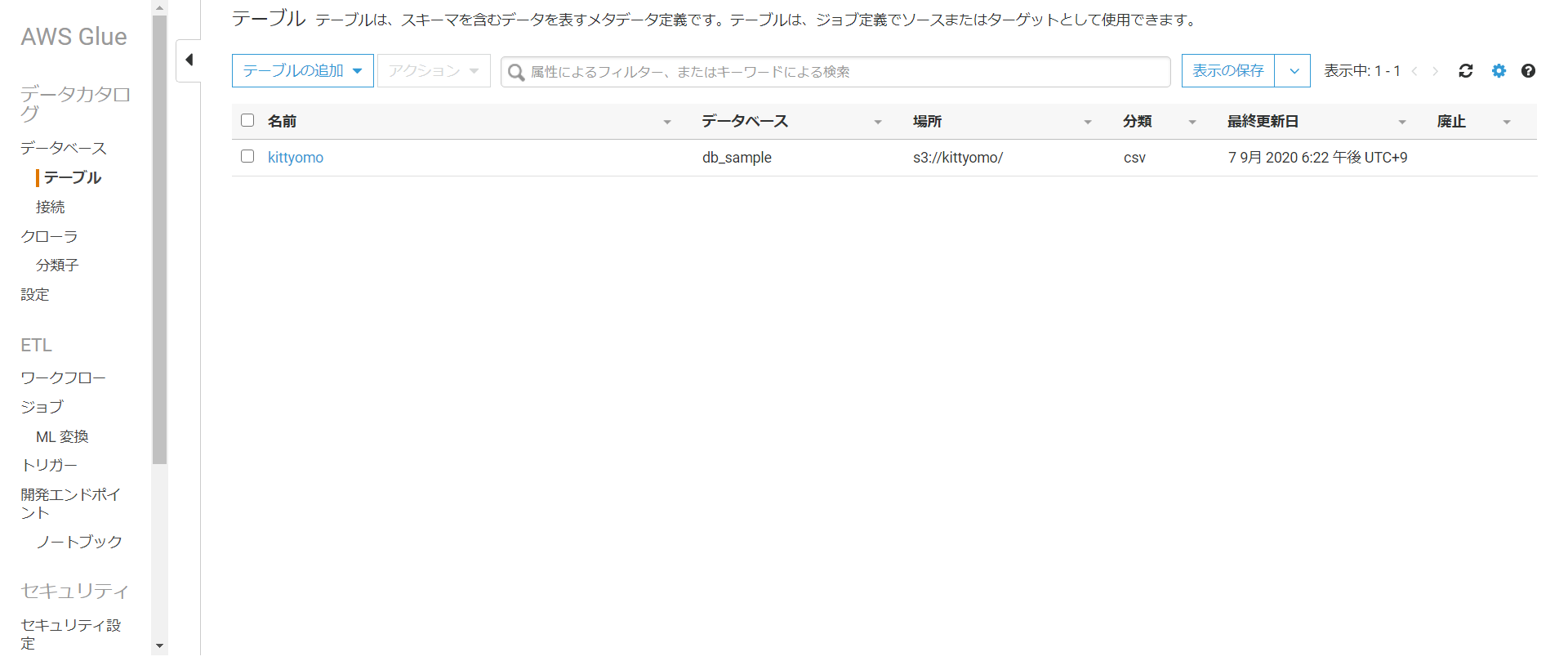
これでAthenaを実行する環境が整ったのでAthenaのマネジメントコンソール画面に移動します。
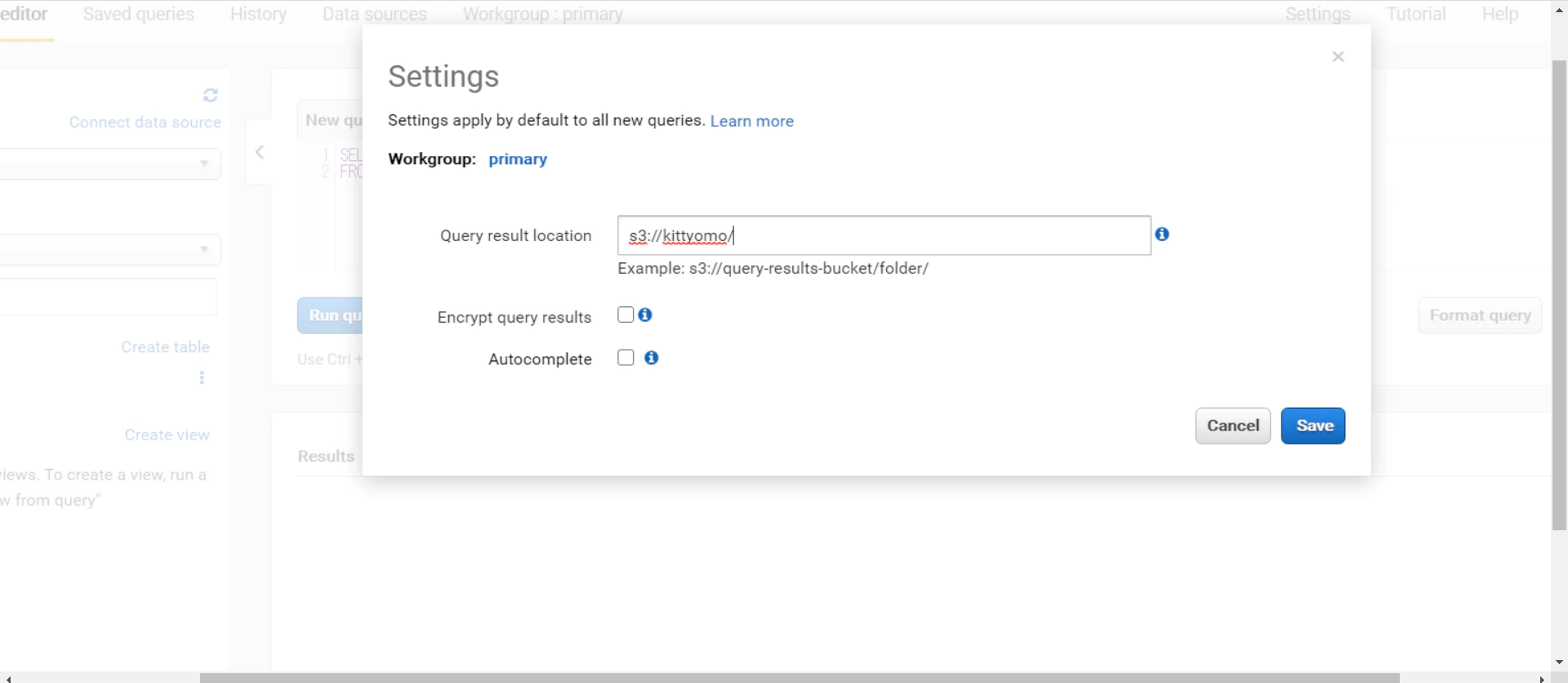
まずはsettingで結果の保存場所を指定します。
クエリを行うときはpreview tableを使用すると簡単なクエリが発行されます。
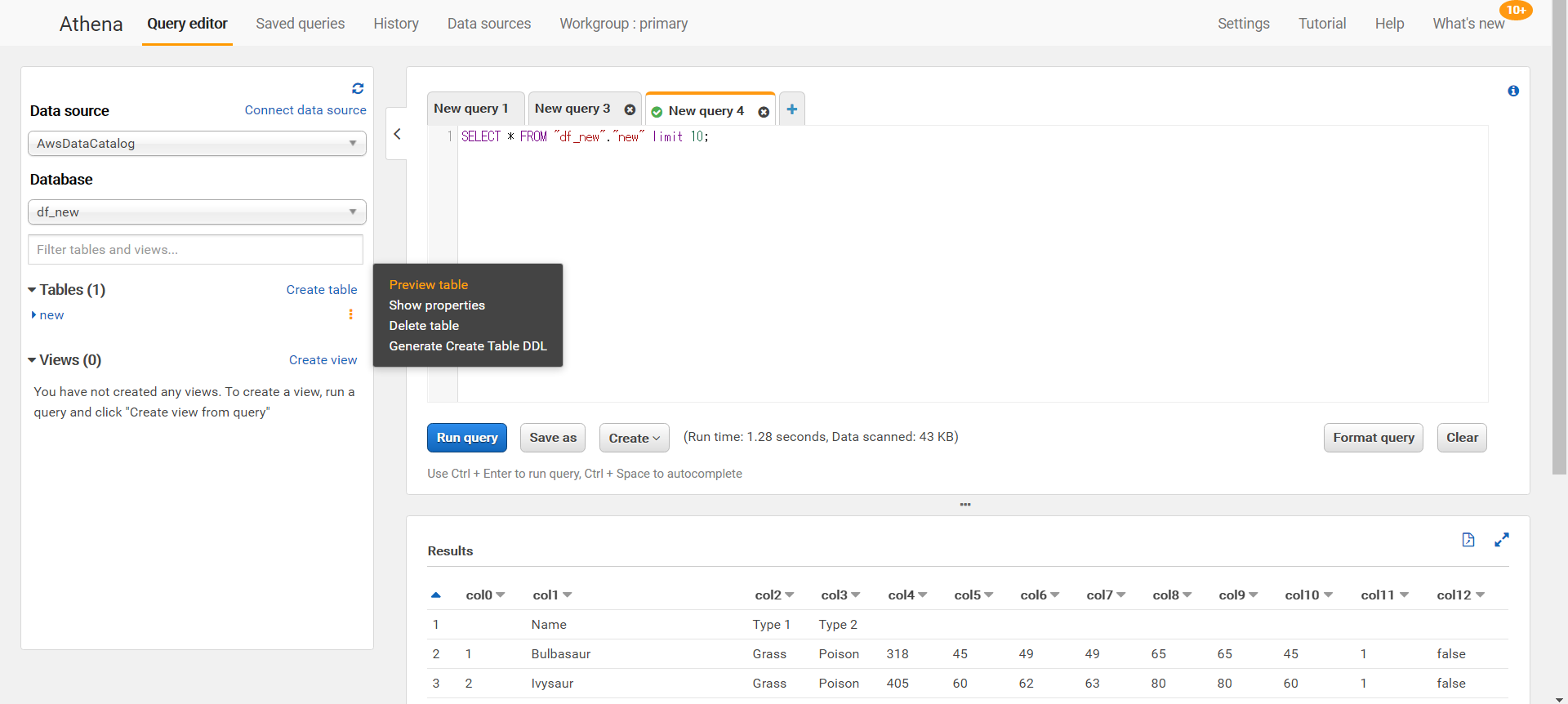
またこのクエリの実行結果は先ほど設定した保存先のS3の場所に保存されます。
<参考させていただいたサイト>
Amazon Athenaによるデータ分析入門