はじめに
今回はGoogleの画像検索の機能を使用して「広瀬すず」さんの画像をスクレイピングしてみました。自分自身で画像処理を行う際にある程度画像データが必要になってくると思います。画像を取得する手段の一つとしてこの記事を参考にしていただければと思います。
実装
今回はGoogleの画像検索から画像を取得する際にスクロールして取得しなければならないといったことがありました。スクロールするにはBeautifulSoupでは行うことが出来ないためseleniumを使用します。
まずはもろもろインポートします。
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
import requests
import base64
import os
import re
import shutil
seleniumを使用するときはchromedriverが必要になります。ChromeDriver - WebDriver for Chromeで取得してください。
# これでGoogleを開く
driver = webdriver.Chrome("C:\\Users\\chromedriver")#ドライバーがあるパスを指定します。
driver.get("https://www.google.com/")
sleep(2)
検索バーの場所を指定します。この際、seleniumで開いたChromeを検証機能を使用して場所を特定してください。私はもともとダウンロードしてあるChromeで検証を行い、それを元に行っていたためエラーが起きてしまいました。その結果エラーの原因が分かるまでに1時間ぐらいかかってしまいました。。。。。。
search_bar = driver.find_element_by_name("q")
# 検索バーにキーワードを入れる
search_bar.send_keys("広瀬すず")
search_bar.submit()
sleep(2)
上手くいくと検索バーに広瀬すずと打ち込まれ検索を行います。
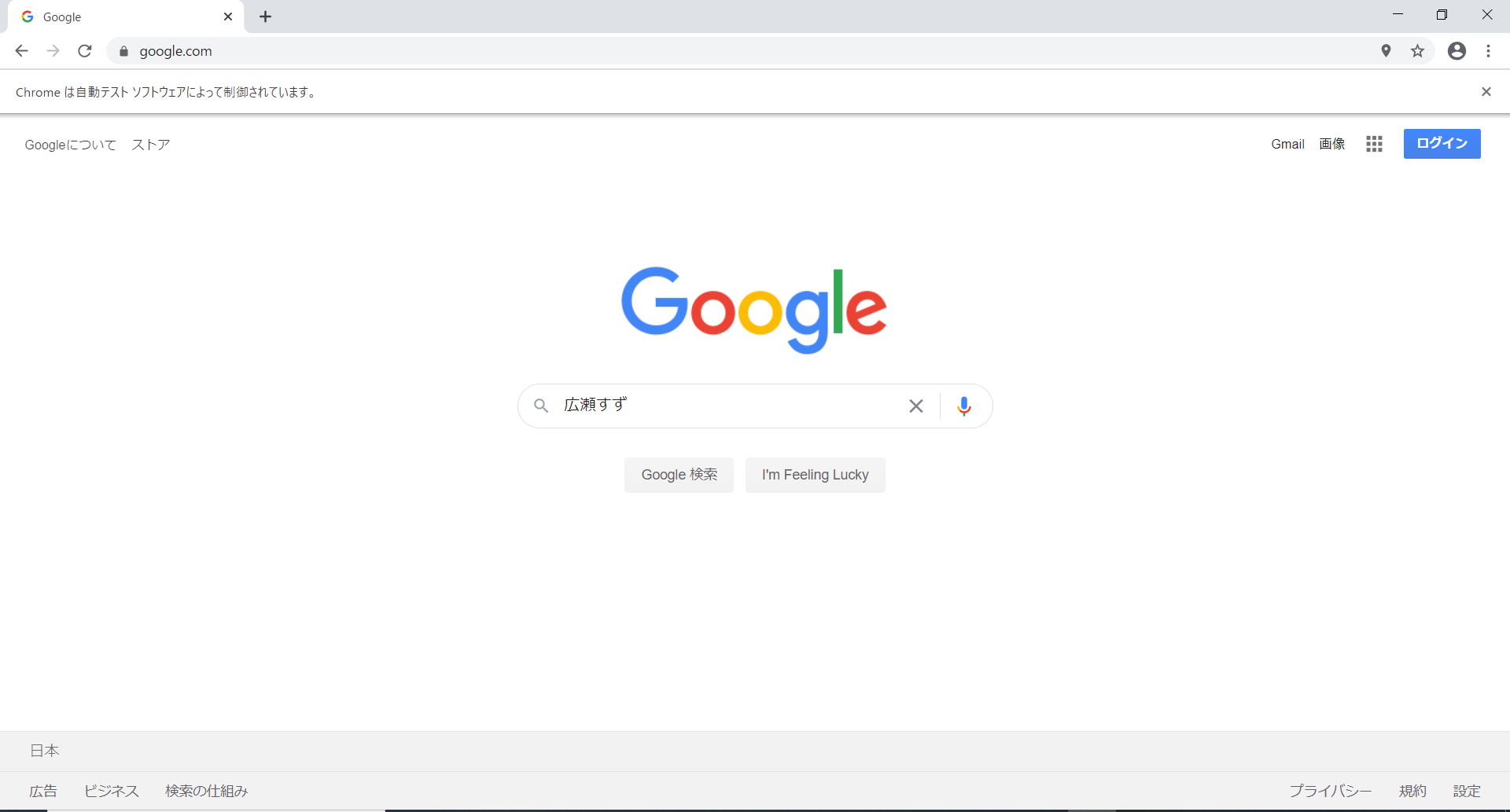
続いて画像一覧へ移動します。
# 画像画面に移動
img_btn = driver.find_element_by_xpath('//a[@class="q qs"]')
img_btn.click()
以下のような画像一覧に移動するのでここにある画像を取得していきたいと思います。
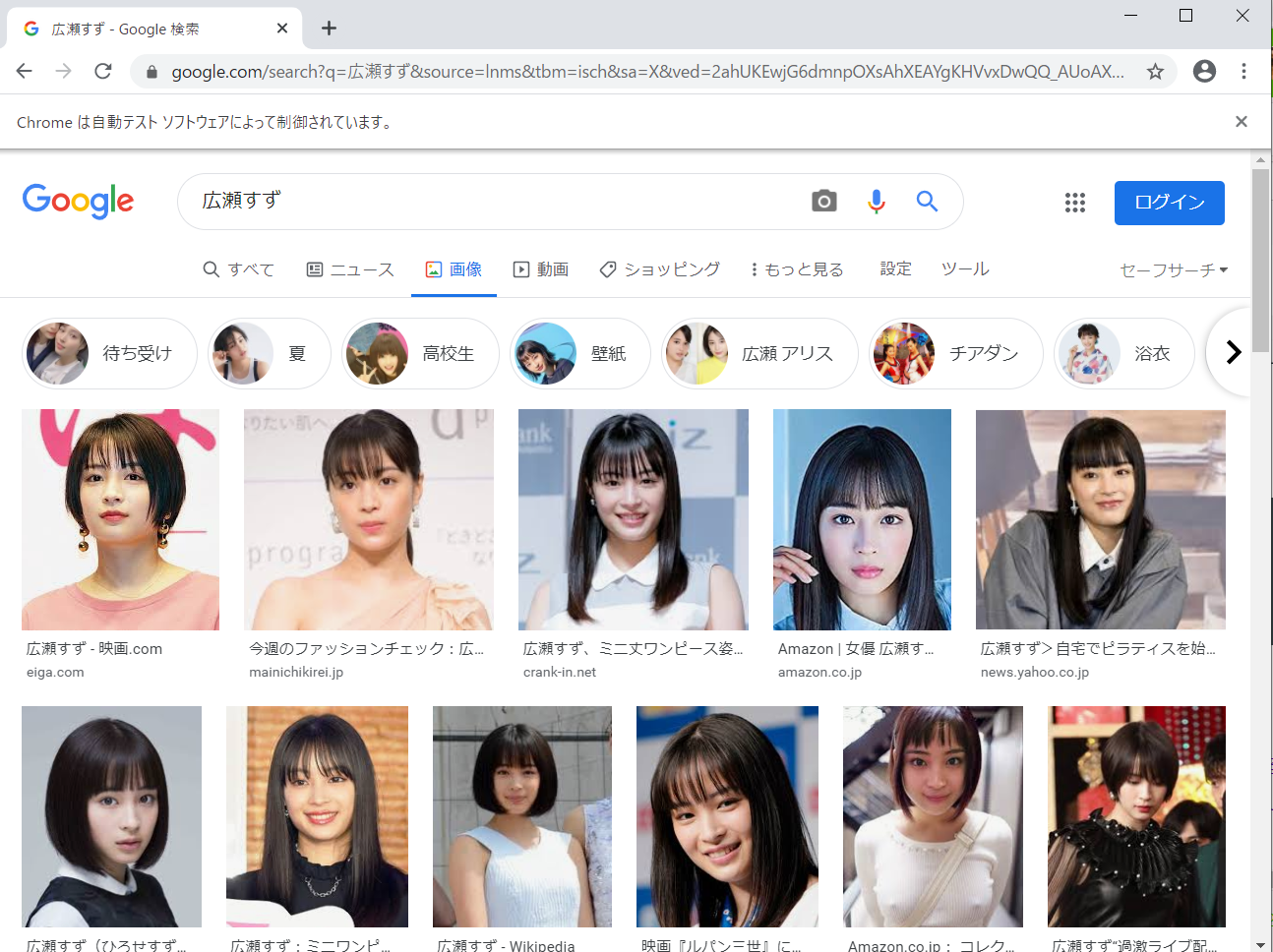
まずは画像のURLを取得していきます。今回、画像のURLを取得するときにBeautifulSoupを使用しimgタグを見つけ、そこから取得を行っています。
画像のURLはimgタグのdata-srcに格納されていることがほとんどでしたが、たまにdata-srcがないものがあったりするのでその時はsrcから取得を行っています。
# 画面のスクロールを行う。
try:
#この中には画像URLが重複している。
all_images = []
#スクロールする回数は5回
for i in range(5):
#ここで画面をスクロールしている。
driver.execute_script("window.scrollTo(0,document.body.scrollHeight);")
#ここでBeautifulSoupに読み込んでいる。
soup = BeautifulSoup(driver.page_source , "html.parser")
#all_imagesに画像URLをappendする
for image in soup.find_all("img"):
try:
url = image.get("data-src")
if url is None:
url = image.get("src")
if url is not None:
all_images.append(url)
except:
print("画像URL取得時にエラーが起きました。")
print()
sleep(2)
except Exception:
print("画面スクロール中にエラーが発生しました。")
error_flag = True
そしてコードの中にもコメントしてある通り、all_imagesの中に画像URLが格納されているのですがここにはURLが重複しています。そのため重複しているものを除去して一意になるようにしていきます。
all_images = list(dict.fromkeys(all_images))
このURLにはhttpsのURLとは別にbase64形式にデータが変更されているものがありました。そのためダウンロードするためには2パターンの方法で行う必要があります。①HTTPからダウンロード②base64からダウンロードです。それぞれのパターンに対応するように今回は関数を作成しました。
# httpのurlで渡された画像を保存していく。
def img_url_download(url , file_path):
response = requests.get(url , stream = True)
#ファイルに保存する、
with open(file_path , 'wb') as file:
shutil.copyfileobj(response.raw , file)
# base64のものを保存していく関数
# urlには"data:image/jpeg;base64,"を取り除いたものを入れます。
def base64_download(url , file_path):
img = base64.b64decode(url.encode())
with open(file_path , "wb") as f:
f.write(img)
関数を定義したら最後に画像をフォルダに保存していきます。
# 画像データをファイルにぶち込んでいく!!
# ファイルのパス
path = r"C:\Users\suzu_img_files"#画像を保存するフォルダのパスを指定してください
# base64は最初に"data:image/jpeg;base64,"があるので取り除くようにする。
base64_string = "data:image/jpeg;base64,"
for index , image_url in enumerate(all_images):
filename = "suzu_" + str(index) + ".jpg"
file_path = os.path.join(path , filename)
#if文ではbase64かそうでないかで分岐しています。
if len(re.findall(base64_string , image_url)) > 0:
url = url.replace(base64_string , "")#接頭辞をurlからなくしている。
base64_download(url , file_path)
else:
img_url_download(image_url , file_path)
上手くいくと以下のように画像が保存されます。
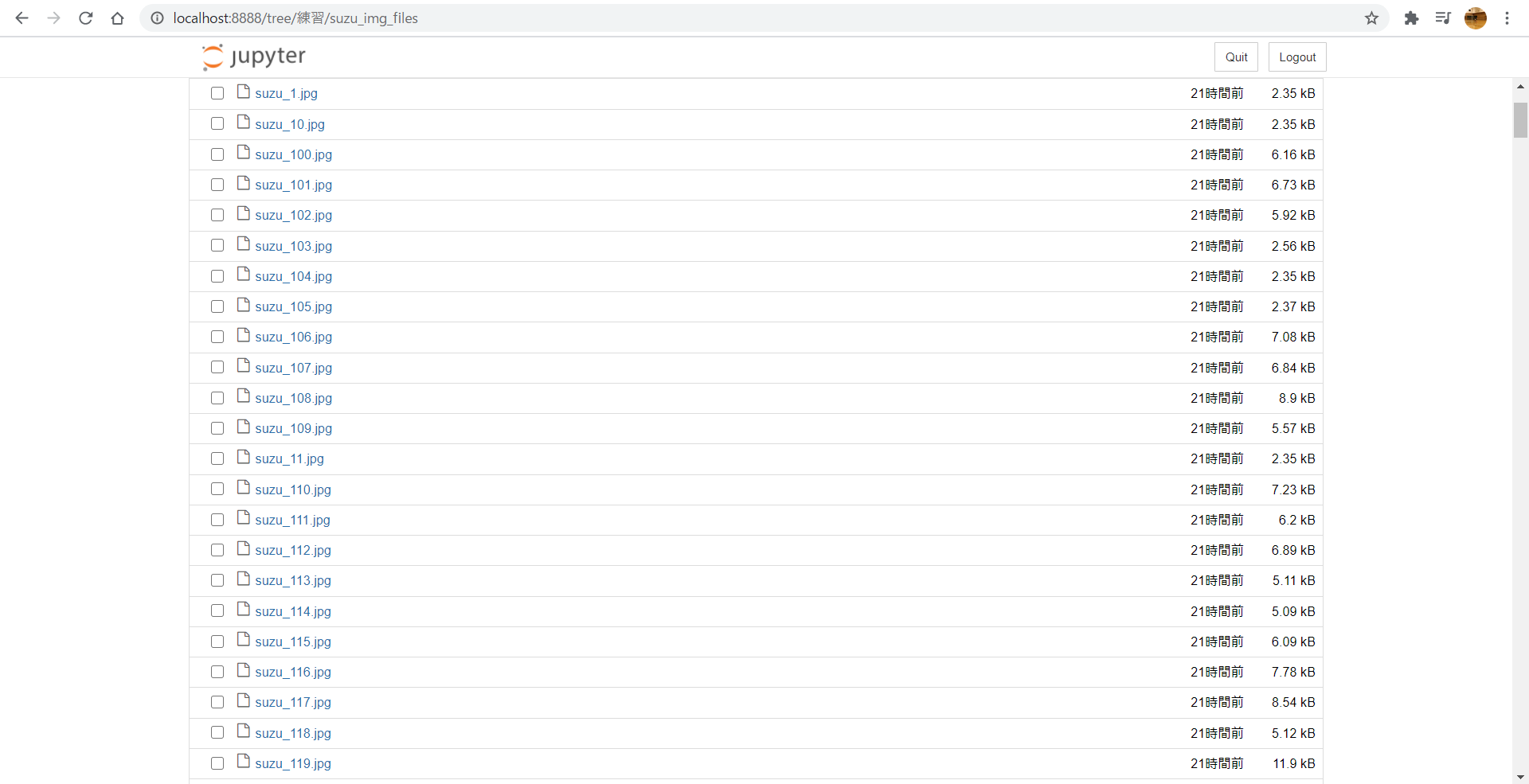
まとめ
いかがだったでしょうか?seleniumを使用する事でスクレイピングの幅も広がるのではないでしょうか?今回は「広瀬すず」さんでしたが自分が好きな人物や動物・建物等でスクレイピングを行うのもいいと思います!
また今回はseleniumの練習もかねて実装を行ったためGoogleの検索画面からの実装でしたが、ただ画像を取得したいだけであれば最初のURLを広瀬すずさんの画像一覧のURLにして実装するほうが速いですね、、、
<参考資料>
【Python入門】橋本環奈の画像をスクレイピング。Pythonのできることの例: 画像をダウンロード。Progateが終わってから行う演習 | Pythonでデータ分析。BeautifulSoup
ChromeDriver - WebDriver for Chrome
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)