はじめに
SIGNATEの第6回AIエッジコンテストに参加しました。
課題の3D物体検出タスクを解くためにPaintPointingというモデルを使用しましたが、今回はこのモデルの計算に必要なセマンティックセグメンテーション部分を動作させました。
SIGNATEから提供されているチュートリアルでは、DeepLabV3によるセマンティクセグメンテーションだったので、これを量子化したモデルをFPGAボードKV260上で動かしてみます。
コンテストの詳細については以下をご覧ください。
前提
この記事は以下のチュートリアルに相当する準備を終えている方向けの内容となっています。
目標
PyTorchから公開されているDeepLabV3を量子化して、KV260上で動作させることを今回の目標にします。
COCOデータセットで学習済みの以下のモデルを使用します。
モデルの量子化スクリプトの実装
DeepLabV3の量子化を行います。
実装したコード
import sys
import argparse
import torch
import torch.nn as nn
from pytorch_nndct.apis import torch_quantizer, dump_xmodel
DIVIDER = '-----------------------------------------'
def create_model(device):
print(f"Using {device} device")
model = torch.hub.load('pytorch/vision:v0.10.0', 'deeplabv3_resnet101', pretrained=True)
model.eval()
model.to(device)
return model
def quantize(build_dir,quant_mode,batchsize):
quant_model = build_dir + '/quant_model'
# use GPU if available
if (torch.cuda.device_count() > 0):
print('You have',torch.cuda.device_count(),'CUDA devices available')
for i in range(torch.cuda.device_count()):
print(' Device',str(i),': ',torch.cuda.get_device_name(i))
print('Selecting device 0..')
device = torch.device('cuda:0')
else:
print('No CUDA devices available..selecting CPU')
device = torch.device('cpu')
# load model
model = create_model(device)
# force to merge BN with CONV for better quantization accuracy
optimize = 1
# override batchsize if in test mode
if (quant_mode=='test'):
batchsize = 1
rand_in = torch.randn([batchsize, 3, 120, 192])
quantizer = torch_quantizer(quant_mode, model, (rand_in), output_dir=quant_model, device=device)
quantized_model = quantizer.quant_model
quantized_model.eval()
with torch.no_grad():
pred = quantized_model(rand_in)
# export config
if (quant_mode=='calib'):
quantizer.export_quant_config()
if (quant_mode=='test'):
quantizer.export_xmodel(deploy_check=False, output_dir=quant_model)
return
def run_main():
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument('-d', '--build_dir', type=str, default='build', help='Path to build folder. Default is build')
ap.add_argument('-q', '--quant_mode', type=str, default='calib', choices=['calib','test'], help='Quantization mode (calib or test). Default is calib')
ap.add_argument('-b', '--batchsize', type=int, default=100, help='Testing batchsize - must be an integer. Default is 100')
args = ap.parse_args()
print('\n'+DIVIDER)
print('PyTorch version : ',torch.__version__)
print(sys.version)
print(DIVIDER)
print(' Command line options:')
print ('--build_dir : ',args.build_dir)
print ('--quant_mode : ',args.quant_mode)
print ('--batchsize : ',args.batchsize)
print(DIVIDER)
quantize(args.build_dir,args.quant_mode,args.batchsize)
return
if __name__ == '__main__':
run_main()
実行方法
$ python -u quantize.py --quant_mode calib
$ python -u quantize.py --quant_mode test
解説
-
rand_in = torch.randn([batchsize, 3, 120, 192])- 量子化のために入力を作成しています
- コンテストに使用する画像は1920x1200x3ですが、KV260のDPUメモリに載るサイズにするために192x120x3のサイズまで落としています
- pytorchのtensorはbatchsize, channel, height, widthなので注意しましょう
- 環境によっては実行中にメモリエラーになることがありますが、cpuで動作させるかbatchsizeを減らすなどで対処できます
- warning
- 以下のように3箇所でwarningが発生しましたが実行上問題はないようです
- bilinearアルゴリズムでupsampleを行う箇所があるようで、DPUによる計算はnearestのアルゴリズムにしか対応していないらしくCPUで計算する必要があります
- 後述しますが、これによりモデルが2つのsubgraphに分かれています
[UNILOG][WARNING] xir::Op{name = DeepLabV3__DeepLabV3_DeepLabHead_classifier__ASPP_0__ASPPPooling_convs__ModuleList_4__20508, type = upsample-fix} has been assigned to CPU: [DPU does not support BILINEAR mode. (only support NEAREST mode)].
[UNILOG][WARNING] xir::Op{name = DeepLabV3__DeepLabV3_20589, type = upsample-fix} has been assigned to CPU: [DPU does not support BILINEAR mode. (only support NEAREST mode)].
[UNILOG][WARNING] xir::Op{name = DeepLabV3__DeepLabV3_20641, type = upsample-fix} has been assigned to CPU: [DPU does not support BILINEAR mode. (only support NEAREST mode)].
あとはチュートリアル通りKV260で動作するモデルへの変換を行うだけです。
出来たら.xmodelファイルをKV260側に転送します。
$ vai_c_xir --xmodel ${BUILD}/quant_model/DeepLabV3_int.xmodel --arch $ARCH --net_name CNN_${TARGET} --output_dir ${BUILD}/compiled_model
量子化モデルの構造
変換済みの.xmodelを https://netron.app/ にアップロードすることでモデルの構造を詳細に確認することが出来ます。
実際に出来たモデルは2つのsubgraphとなっていました。
いずれの箇所もbilinearが必要となった箇所でモデルが分割されています。
入出力は以下のようになっていました。
- subgraph1
- 入力:[1, 120, 192, 3]
- 出力
- [1, 1, 1, 256]
subgraph2への入力になる。
[1, 15, 24, 256]へとbilinear resizeした後に入力する。 - [1, 15, 24, 21]
学習時に必要となる出力で、推論時には必要ない。 - [1, 15, 24, 2048]
subgraph2への入力になる。
こちらはresize無しでそのまま入力する。
- [1, 1, 1, 256]
- subgraph2
- 入力
- [1, 15, 24, 256]
subgraph1からの出力を入力する。 - [1, 15, 24, 2048]
subgraph1からの出力を入力する。
- [1, 15, 24, 256]
- 出力:[1, 15, 24, 21]
これも[1, 120, 192, 3]へとbilinear resizeを行い、それ以降で使用する。
- 入力
この情報を考慮して次のpythonスクリプトを実装していきます。
実行用pythonスクリプトの実装
KV260上での実行用pythonスクリプトを実装してセマンティックセグメンテーションを実行します。
画像1枚のみを推論します。
実装したコード
from ctypes import *
from typing import List
import cv2
import numpy as np
import vart
import os
import pathlib
import xir
import threading
import time
import sys
import argparse
_divider = '-------------------------------'
def resize(array, out_shape):
_, h, w, c = array.shape
_, oh, ow, _= out_shape
resized_array= np.empty(out_shape, np.float32)
for i in range(c):
resized_array[:, :, :, i] = cv2.resize(array[0, :, :, i], (ow, oh))
return resized_array
def preprocess_fn(image_path, fix_scale):
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (192,120))
image = image.astype(np.float32)
image /= 255.
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
for c in range(3):
image[..., c] = (image[..., c] - mean[c]) / std[c]
image *= fix_scale
image = image.astype(np.int8)
return image
def get_child_subgraph_dpu(graph: "Graph") -> List["Subgraph"]:
assert graph is not None, "'graph' should not be None."
root_subgraph = graph.get_root_subgraph()
assert (root_subgraph is not None), "Failed to get root subgraph of input Graph object."
if root_subgraph.is_leaf:
return []
child_subgraphs = root_subgraph.toposort_child_subgraph()
assert child_subgraphs is not None and len(child_subgraphs) > 0
return [
cs
for cs in child_subgraphs
if cs.has_attr("device") and cs.get_attr("device").upper() == "DPU"
]
def app(image_dir, threads, model):
listimage = os.listdir(image_dir)[:1]
runTotal = len(listimage)
g = xir.Graph.deserialize(model)
subgraphs = get_child_subgraph_dpu(g)
''' model0 '''
subgraph0 = vart.Runner.create_runner(subgraphs[0], "run")
model0_input_tensors = subgraph0.get_input_tensors()
model0_output_tensors = subgraph0.get_output_tensors()
# in/out shape
model0_input_ndim = tuple(model0_input_tensors[0].dims)
model0_output0_ndim = tuple(model0_output_tensors[0].dims)
model0_output1_ndim = tuple(model0_output_tensors[1].dims)
model0_output2_ndim = tuple(model0_output_tensors[2].dims)
# input scaling
model0_input_fixpos = model0_input_tensors[0].get_attr("fix_point")
model0_input_scale = 2**model0_input_fixpos
# output scaling
model0_output0_fixpos = model0_output_tensors[0].get_attr("fix_point")
model0_output0_scale = 1 / (2**model0_output0_fixpos)
model0_output2_fixpos = model0_output_tensors[2].get_attr("fix_point")
model0_output2_scale = 1 / (2**model0_output2_fixpos)
''' model1 '''
subgraph1 = vart.Runner.create_runner(subgraphs[1], "run")
model1_input_tensors = subgraph1.get_input_tensors()
model1_output_tensors = subgraph1.get_output_tensors()
# in/out shape
model1_input0_ndim = tuple(model1_input_tensors[0].dims)
model1_input1_ndim = tuple(model1_input_tensors[1].dims)
model1_output_ndim = tuple(model1_output_tensors[0].dims)
# input scaling
model1_input0_fixpos = model1_input_tensors[0].get_attr("fix_point")
model1_input0_scale = 2**model1_input0_fixpos
model1_input1_fixpos = model1_input_tensors[1].get_attr("fix_point")
model1_input1_scale = 2**model1_input1_fixpos
# output scaling
model1_output_fixpos = model1_output_tensors[0].get_attr("fix_point")
model1_output_scale = 1 / (2**model1_output_fixpos)
''' preprocess images '''
print (_divider)
print('Pre-processing')
img = []
runTotal = 1
for i in range(runTotal):
path = os.path.join(image_dir,listimage[i])
img.append(preprocess_fn(path, model0_input_scale))
img = img[0]
''' model0 inference '''
print('### model0 inference ###')
# prepare in/out tensors
model0_output = []
for out_tensor in model0_output_tensors:
model0_output.append(np.empty(tuple(out_tensor.dims), dtype=np.int8, order='C'))
job_id = subgraph0.execute_async([img], model0_output)
print('job_id:', job_id)
# wait inference
subgraph0.wait(job_id)
# postprocess
model0_output0, _, model0_output2 = model0_output
model0_output0 = model0_output0.astype(np.float32)
model0_output0 = model0_output0 * model0_output0_scale
model0_output0 = model0_output0.reshape(model0_output0_ndim)
model0_output2 = model0_output2.astype(np.float32)
model0_output2 = model0_output2 * model0_output2_scale
model0_output2 = model0_output2.reshape(model0_output2_ndim)
# upsample
resize_shape = (1, 15, 24, 256)
model0_output0 = resize(model0_output0, resize_shape)
''' model1 inference '''
print('### model1 inference ###')
# preprocess
model0_output0 *= model1_input0_scale
model0_output2 *= model1_input1_scale
model0_output0 = model0_output0.astype(np.int8)
model0_output2 = model0_output2.astype(np.int8)
# prepare out tensors
model1_output = []
model1_output.append(np.empty(tuple(model1_output_tensors[0].dims), dtype=np.int8, order='C'))
job_id = subgraph1.execute_async([model0_output0, model0_output2], model1_output)
# wait inference
subgraph1.wait(job_id)
# postprocess
model1_output = model1_output[0].astype(np.float32)
model1_output = model1_output * model1_output_scale
model1_output = resize(model1_output, (1, 120, 192, 21))
model1_output = model1_output.argmax(axis=-1)
return
def main():
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument('-d', '--image_dir', type=str, default='images', help='Path to folder of images. Default is images')
ap.add_argument('-t', '--threads', type=int, default=1, help='Number of threads. Default is 1')
ap.add_argument('-m', '--model', type=str, default='CNN_zcu102.xmodel', help='Path of xmodel. Default is CNN_zcu102.xmodel')
args = ap.parse_args()
print ('Command line options:')
print (' --image_dir : ', args.image_dir)
print (' --threads : ', args.threads)
print (' --model : ', args.model)
app(args.image_dir,args.threads,args.model)
if __name__ == '__main__':
main()
解説
- 「量子化モデルの構造」でまとめた通りに1つ目のモデルの出力を2つ目のモデルの入力の適切な箇所に入力します
-
def resize(array, out_shape):- 4d numpy配列をbilinear resizeするために独自のresize関数を実装しています
- numpy.resize()を使用すると意図した順でresizeされなかったためcv2.resize()を使用して無理やりresizeしていますが、もっと上手いやり方があるかと思います
推論
以下の犬の画像を入力して出力を可視化してみます。

可視化結果
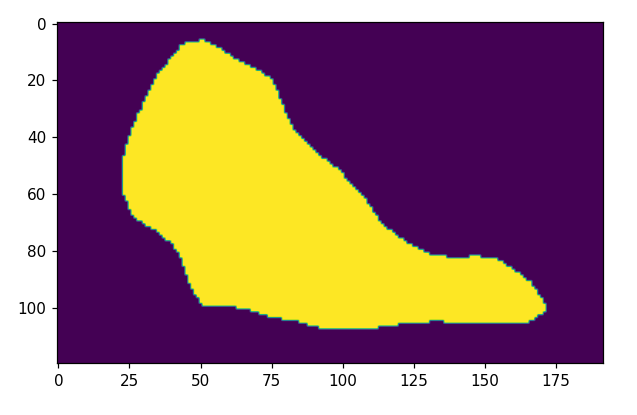
セグメンテーションはそれなりに上手く行っているようですが、黄色い箇所は8の値となっており「犬」ではなく「猫」の判定結果になってしまいました。
DeepLabV3は少なくとも224x224x3の入力サイズを期待しているようなので、これが判定結果と関係しているのかもしれません。
実行速度
モデルに画像を入力してから最終的な出力が得られるまでの時間を計測してみました。
time: 0.20s
大きめなモデルの割に高速に動作しています。
ボトルネックとなっている箇所を特定してresize部分のアルゴリズムの最適化や、使用するスレッド数を増やすことによってまだ高速化の余地がありそうです。
おわりに
FGPAボードを触るのも量子化モデルを動かすのも初めてでしたが、学習済みDeepLabV3を量子化して、DeepLabV3を動作させることが出来ました。
次はpointpainting全体を動作できるように実装してみたいと思います。