はじめに
データ分析処理のELTにおけるT(データストア内でのデータ変換)の実施をサポートするツールであるdbtを触ってみる。
dbtを使って解決したいこと
- 1SQLファイル内に複数のクエリが記述されているデータ処理を解読しやすくできないか
- 繰り返しクエリを修正しても、データ品質を担保できるか
- データ仕様を誰でも理解できる状態にできないか
やってみた
とりあえず簡単に触ってみたかったので、dbt Cloud(Developerプラン)を利用する。
事前にサンプルデータとして、BigQuery上に購入者データと購入データのテーブルを用意する。
- raw_customers
- id (integer)
- first_name (string)
- last_name (string)
- raw_orders
- id (integer)
- user_id (integer)
- order_date (date)
- status (string)
1SQLファイル内に複数のクエリが記述されているデータ処理を解読しやすくできないか
dbtには、テーブルがどのテーブルから生成されたか、テーブル間の関係図を自動生成してくれる機能がある。
raw_customersテーブルにraw_ordersテーブルを使って、customersテーブルを作成するクエリを書いてみる。
-- /models/customers.sql
with customers as (
select
id as customer_id,
first_name,
last_name
from {{data_set}}.raw_customers
),
orders as (
select
id as order_id,
user_id as customer_id,
order_date,
status
from {{data_set}}.raw_orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
この時のデータリネージは、次のようになる。
同一SQLファイル内にwith句を使って定義すると、テーブルの関係性は分からない。そこで、with句で定義しているテーブルを別モデルとして管理するように、SQLファイルを分けて書いてみる。
-- /models/_customers.sql
select
id as customer_id,
first_name,
last_name
from {{data_set}}.raw_customers
-- /models/_orders.sql
select
id as order_id,
user_id as customer_id,
order_date,
status
from {{data_set}}.raw_orders
別モデルとして切り出したテーブルをref機能を用いて参照する。
-- /models/customers.sql
with customers as (
select * from {{ ref('_customers') }}
),
orders as (
select * from {{ ref('_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
すると、データリネージは次のようになる。
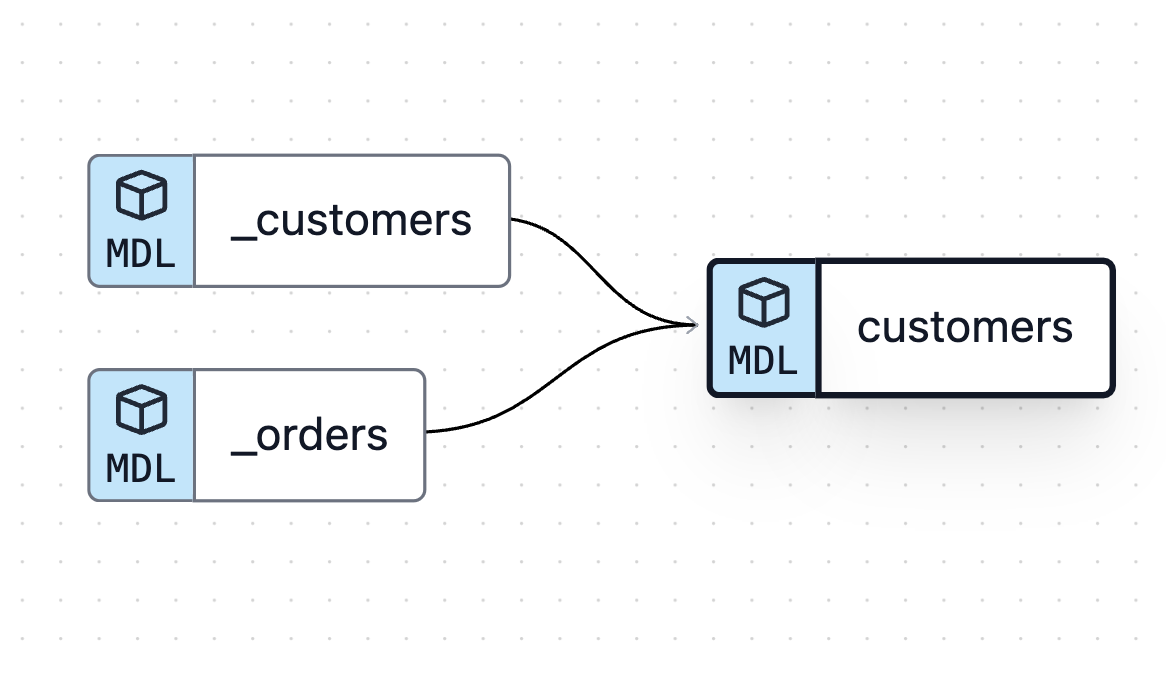
_customersテーブルと_ordersテーブルを参照して、customersテーブルが生成される。このように可視化されることによって、各テーブルの依存関係を把握することができる。
1SQLファイル内に複数のクエリが記述されていて複雑なクエリほど、依存関係を把握するのに苦労する。クエリのリファクタリングが必要ではあるが、dbtのデータリネージを使えば把握しやすくなりそうだ。
繰り返しクエリを修正しても、データ品質を担保できるか
dbtには、各テーブルのデータが期待通りに動作するかテストする機能がある。
yamlファイルに、各テーブルのカラムにテストケースを追記する。
-- /models/schema.yml
version: 2
models:
- name: orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: id
-
unique: 一意の値が入っているか -
not_null: null値が入っていないか -
accepted_values: 指定した値が入っているか -
relationships:customers.customer_idと結合できるか
今回は単一テストを試してみたが、自分で用意したテストクエリを実行して、結果を確認することもできるようだ。テストを通じてデータ仕様を満たしているか確認することができるため、よりクエリの修正をしやすくなりそうだ。
データ仕様を誰でも理解できる状態にできないか
dbtは、各テーブルのドキュメントを共有する仕組みがある。
yamlファイルに、各テーブルやカラムの説明文を追記する。
version: 2
models:
- name: customers
description: One record per customer
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: first_order_date
description: NULL when a customer has not yet placed an order.
- name: _customers
description: This model cleans up customer data
columns:
- name: customer_id
description: Primary key
tests:
- unique
- not_null
- name: _orders
description: This model cleans up order data
columns:
- name: order_id
description: Primary key
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
すると、dbtのGUI上でドキュメントが見られるようになる。
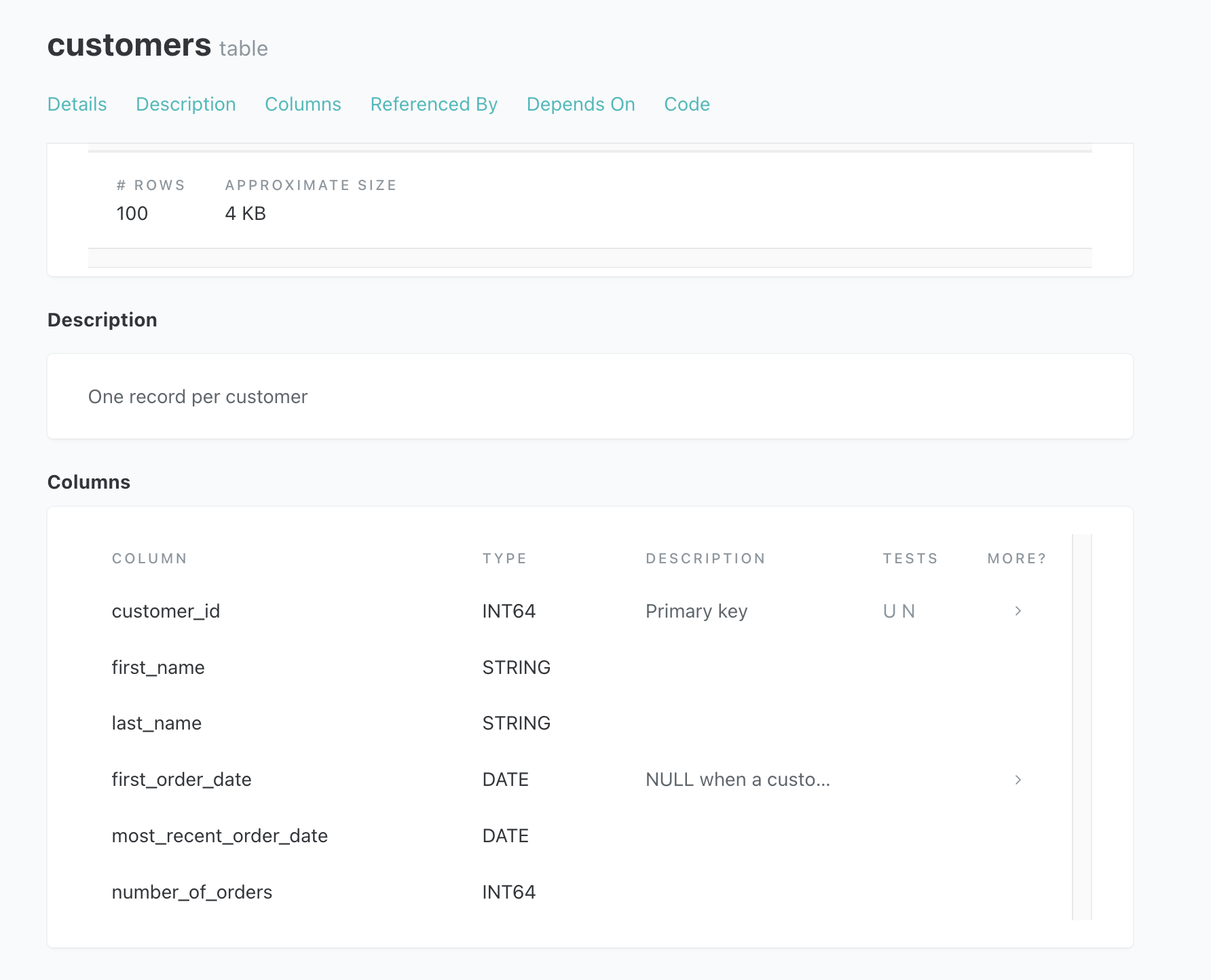
yamlファイルを一から用意すると手間がかかるので、dbtのパッケージcodegenを利用すると便利そうだ。既存テーブルの情報をyamlファイルに自動で生成してくれる。
まとめ
ツール導入によって既存処理や運用フローを見直することで、冒頭で挙げた点を解消することができそうである。dbtには他にも魅力的な機能があるため、引き続きdbtをどう利用するか探っていきたい。