目標
-
以下の項目を CSV ファイルから読み込む
- 検索キーワード
- 取得ページ
- 商品価格の最小値
- 商品価格の最大値
-
eBay にて商品情報を取得する
-
取得した商品情報を元に、以下のファイルを出力する
- CSV ファイル
- 商品名
- 商品状態
- 販売価格
- 送料
- 合計額 (販売価格 + 送料)
- 辞書ファイル
- 商品名に登場した単語の頻出度
- 商品名に登場した単語の品詞分類
- グラフ
- 合計額の度数分布(ヒストグラム)
- CSV ファイル
ソースコード
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.support.ui import WebDriverWait
import csv
import pandas as pd
import datetime
from collections import Counter
import collections
import numpy as np
import matplotlib as mpl
mpl.use('TkAgg') # or whatever other backend that you want
import matplotlib.pyplot as plt
import nltk
import time
import random
import re
# # Input Keywordkoda
# print("Input Keyword:")
# keyword = input().strip().replace(" ","+")
# # Input PageNumber
# print("Input PageNumber")
# page_num = int(input())
# # Input MaxPrice
# print("Input MaxPrice")
# x_max = int(input())
# Open Browser
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('–-disable-dev-shm-usage')
# options.add_argument('--proxy-server="direct://"') # Proxy経由ではなく直接接続する
# options.add_argument('--disable-web-security')
driver = webdriver.Chrome(executable_path="/Users/micksmith/home/work/eBay/Python/chromedriver", chrome_options=options)
names = []
statuses = []
prices = []
shippings = []
amounts = []
displayed_results = 200
Source_file = "/Users/micksmith/home/work/eBay/Python/movie anime.csv"
CSV_file_path = "/Users/micksmith/home/work/eBay/Python/CSV/"
keyword_file_path = "/Users/micksmith/home/work/eBay/Python/Keyword/"
analysis_file_path = "/Users/micksmith/home/work/eBay/Python/Analysis/"
hist_file_path = "/Users/micksmith/home/work/eBay/Python/Hist/"
with open(Source_file, "r") as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
keyword = row[0].strip().replace(" ","+")
page_num = int(row[1])
x_min = int(row[2])
x_max = int(row[3])
#print(page_num)
#print(x_max)
#driver.implicitly_wait(random.randint(10,20))
# number_of_search
url = 'https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw={}&_sacat=0&_ipg={}'.format(keyword, displayed_results)
driver.get(url)
number_of_search = driver.find_element_by_css_selector('#mainContent > div.s-answer-region.s-answer-region-center-top > div > div.clearfix.srp-controls__row-2 > div > div.srp-controls__control.srp-controls__count > h1 > span:nth-child(1)').text
number_of_search = int(re.sub("\\D", "", number_of_search))
if(page_num * displayed_results > number_of_search):
page_num = number_of_search // displayed_results + 1
print("number_of_search:", number_of_search)
print("page_num:", page_num)
time.sleep(3)
print(keyword, page_num, x_max)
for i in range (1,page_num+1):
url = 'https://www.ebay.com/sch/i.html?_from=R40&_nkw={}&_sacat=0&rt=nc&LH_Sold=1&LH_Complete=1&_ipg=200&_pgn={}'.format(keyword, i)
# driver.implicitly_wait(random.randint(1,3))
#driver.implicitly_wait(1)
driver.get(url)
#print("debug")
print("Page_num:", i)
time.sleep(random.randint(1,3))
items = driver.find_elements_by_class_name('s-item__info.clearfix')
for item in items:
# get Name
try:
name = item.find_element_by_class_name('s-item__title').text
name = name.replace("NEW LISTING", "")
names.append(name)
except:
names.append(" ")
print(name)
# #get Status
try:
status = item.find_element_by_class_name('SECONDARY_INFO').text
statuses.append(status)
except:
statuses.append(" ")
# #get Price
try:
price = item.find_element_by_class_name('s-item__price').text
if( 'to' in price):
price = price.replace(price, '0')
#print(price)
price = int(re.sub("\\D", "", price))
prices.append(price)
except:
prices.append(" ")
print(price)
# #get ShippingCost
try:
shipping = item.find_element_by_class_name('s-item__logisticsCost').text
shipping = int(re.sub("\\D", "", shipping))
# shipping = int(shipping)
shippings.append(shipping)
except:
shipping = 0
shippings.append(shipping)
print(shipping)
amounts.append(price + shipping)
#print(amount)
#print(len(names))
# TitleExtraction
title = names
titles = ' '.join(title)
keyword = keyword.replace("+"," ")
#print(mojiretsu)
counter = collections.Counter(titles.split())
d = counter.most_common(200)
date = datetime.datetime.today().strftime("%Y%m%d")
keyword_file_name = keyword_file_path +keyword + "_" + str(page_num) + "_" + date + ".txt"
with open(keyword_file_name, 'w') as f:
for key, value in d:
f.write('{0} {1}\n'.format(key, value))
# MorphologicalAnalysis
morph = nltk.word_tokenize(titles)
pos = nltk.pos_tag(morph)
entitles = nltk.chunk.ne_chunk(pos)
analysis_file_name = analysis_file_path + keyword + "_" + str(number_of_search) + "_" + date + ".txt"
#print(type(entitles))
with open(analysis_file_name, mode="w") as f:
f.write(str(entitles))
df = pd.DataFrame()
df['name'] = names
df['status'] = statuses
df['price'] = prices
df['shippingcost'] = shippings
df['amount'] = amounts
date = datetime.datetime.today().strftime("%Y%m%d")
csv_file_name = CSV_file_path + keyword + "_" + str(number_of_search) + "_" + date + ".csv"
df.to_csv(csv_file_name)
y_min = 0 # MinimumFrequency
y_max = number_of_search # MaximumFrequency
interval = (x_max - x_min) // 20 # Interval
bin_num = (x_max - x_min) // interval # bins
# Hists
# plt.xlim(x_min, x_max)
# plt.ylim(y_min, y_max)
plt.title(keyword + "_" + str(number_of_search) + "_" + date)
plt.xlabel("Price")
plt.ylabel("Frequency")
plt.xticks(np.arange(x_min, x_max, interval), rotation = 90)
plt.hist(prices, range=(x_min, x_max), bins = bin_num)
plt.savefig(hist_file_path + keyword + "_" + str(number_of_search) + "_" + date + ".png")
#plt.show()
driver.quit()
結果
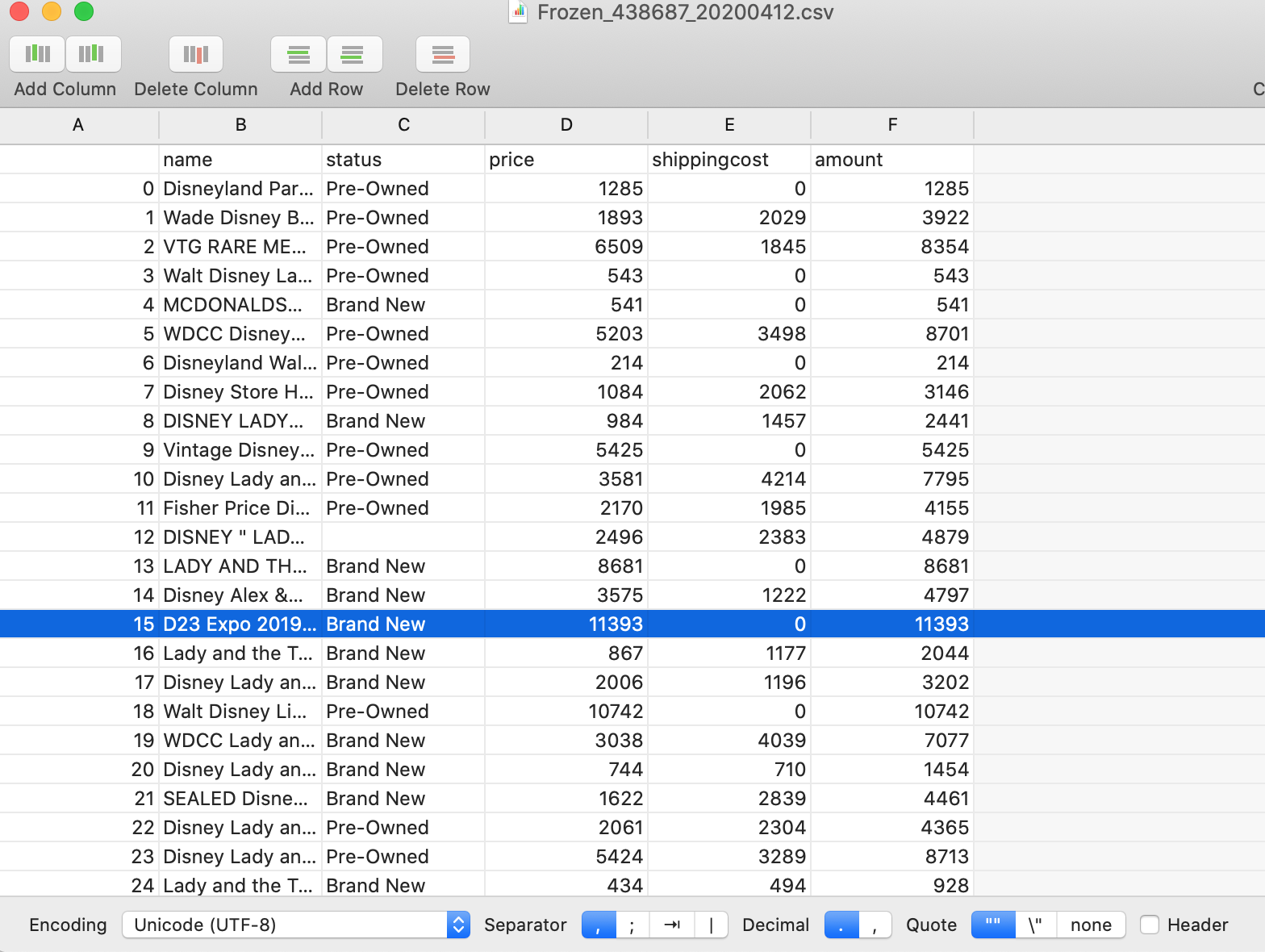



分析
- 以下のエラーメッセージが頻発する
Traceback (most recent call last):
File "/Users/UserName/home/work/eBay/Python/eBay_Scraping.py", line 89, in <module>
driver.get(url)
File "/Users/UserName/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/selenium/webdriver/remote/webdriver.py", line 333, in get
self.execute(Command.GET, {'url': url})
File "/Users/UserName/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/selenium/webdriver/remote/webdriver.py", line 321, in execute
self.error_handler.check_response(response)
File "/Users/UserName/.pyenv/versions/anaconda3-4.2.0/lib/python3.5/site-packages/selenium/webdriver/remote/errorhandler.py", line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.InvalidSessionIdException: Message: invalid session id
- 原因として、以下のことが考えられる
- 同一セッションID で連続してアクセスすると、サーバ上でブロックされる
- 対処法について検討中