はじめに
D言語を使ってコンピュータ将棋プレイヤを作りました → "D将棋"として第3回将棋電王トーナメントに参加してきました。
大会の参加結果
1位!(予選リーグ1回戦終了時点です、画像は http://live.nicovideo.jp/watch/lv232964965 より)
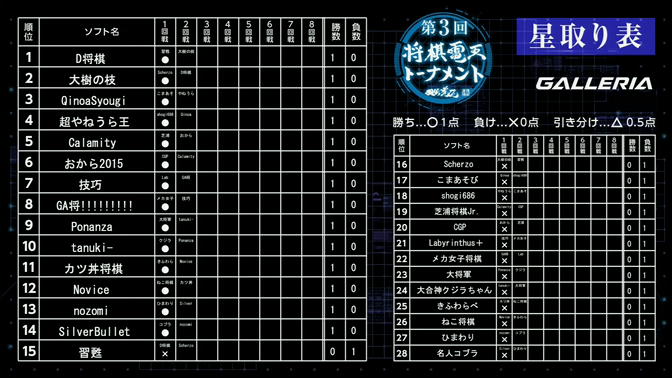
実際は予選リーグ12位で決勝トーナメントまで進出することができました(決勝トーナメントは1回戦敗退)
以下はD言語っぽい部分の解説
実行速度と気に入っている機能の紹介
実行速度について
決して遅くはないです
指し手の生成と盤面の更新のサンプルコードを公開しています
https://github.com/kfule/shogi.d/tree/sample
LDCを入れてbuild.shを実行すると実行バイナリ(d_shogi)ができます
実行画面(色付けたり日本語使ってたりなので、うまく表示されなければごめんなさい。。)
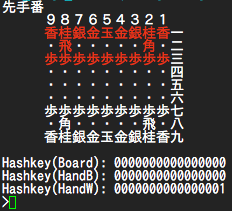
サンプルコードの各種テストの実行結果
MBA (mid 2013, i5 4250U 1.3-2.6GHz 1コア)での実行結果
| テスト\コンパイラ | DMD(2.069.2) | LDC(0.16) |
|---|---|---|
| test1 (手生成と盤面更新) | 1.2M 局面/秒 | 2.6M 局面/秒 |
| test2 (test1+終局からundo) | 0.99M 局面/秒 | 2.3M 局面/秒 |
| test3 (初期局面の手生成) | 3.7M 回/秒 | 11M 回/秒 |
| test4 (「指し手生成祭り」) | 1.2M 回/秒 | 4.0M 回/秒 |
test1, test2の(LDCの)結果から、(テストが間違ってなければ)ゲーム木探索でも1コア100万局面/秒を見込める実行速度が出ていると考えられます。実際、電王トーナメント時のcore-i7 6700K環境の4スレッド並列探索では、合法手数の少ない序盤局面&軽めの2駒関係の評価関数という条件ですが400万局面/秒出ていました。
(C/C++で実装された他プログラムと比較しても負けてない速度は出ていると思います![要出典])
ビットボードの演算子の一括オーバーロード
ビットボード:1マスを1ビットで表現→将棋では81ビット以上必要(、なので構造体でビット演算を定義したい、できればSSEを使いたい)
D言語では演算子をopBinary(2項演算), opUnary(単項演算), opOpAssign(代入演算)などでまとめてオーバーロードでき、コードがすっきりします。
またオーバーロード定義でulong2型を用いることで各種演算でSSE命令まで使ってくれたりします。(a & ~bのような演算では、最適化されてnotand命令も使ってくれるようです)
///ビットボード
struct Bitboard {
union {
ulong[2] b; //コンパイル時変数の初期化周りのバグの回避のためにulong[2]を先に定義している
ulong2 a;
};
///コンストラクタ
this(in Bitboard bb) @nogc { this = bb; }
/// ditto
this(in ulong2 b) @nogc { a = b; }
/// ditto
this(in ulong b0, in ulong b1) @nogc { b = [ b0, b1 ]; }
//演算子
Bitboard opBinary(string op)(const Bitboard bb) @nogc const { return mixin("Bitboard(a" ~op ~"bb.a)"); }
Bitboard opUnary(string op)() @nogc const if (op == "~") { return Bitboard(~a); }
//複合代入
ref Bitboard opOpAssign(string op)(const Bitboard bb) @nogc if (op != "=") {
a = opBinary !op(bb).a;
return this;
}
bool opCast(T)() const if (is(T == bool)&&vendor == Vendor.llvm) { return !__builtin_ia32_ptestz128(a, a); }
bool opCast(T)() const if (is(T == bool)&&vendor != Vendor.llvm) { return cast(bool)(b[0] | b[1]); }
...
}
文字列mixinによる手番、駒毎のコードの自動生成
コンパイル時までに生成したstringをD言語のコードとして解釈してくれるので手番毎、駒毎に実行する似たような処理をまとめて書くことができます。コードがすっきりします。
下記では打つ手の生成処理を、手番をYY、駒をXXに集約して記述しています。
二歩の除外処理など特定の駒に特化した処理もstatic if文内で記述可能です。
Move* genDropsBaseYY(in Shogiban pos, Move* mlist, Bitboard target) @nogc {
target.b[1] &= 0xFFFF800000000000UL; //冗長部分を取り除く
mixin(q{
if (pos._mochigomaYY.isXX) {
static if ("XX" == "FU") {
ulong b2FU = pos._bbYYFU.b[0] | (pos._bbYYFU.b[1] >> 1);
foreach (i;[4, 2, 1]) { b2FU |= (b2FU << (9 * i)) | (b2FU >> (9 * i)); }
foreach (to; (target.b[0] & MASK_LEGAL_YYFU.b[0] & ~b2FU).BitwiseRange !ulong)
*(mlist++) = Move(komaType.YYXX, to);
foreach (to; (target.b[1] & MASK_LEGAL_YYFU.b[1] & ~(b2FU << 1)).BitwiseRange !(ulong, 17))
*(mlist++) = Move(komaType.YYXX, to);
}
static if ("XX".startsWith("KY", "KE")) {
foreach (to; (target.b[0] & MASK_LEGAL_YYXX.b[0]).BitwiseRange !ulong) { *(mlist++) = Move(komaType.YYXX, to); }
foreach (to; (target.b[1] & MASK_LEGAL_YYXX.b[1]).BitwiseRange !(ulong, 17)) { *(mlist++) = Move(komaType.YYXX, to); }
}
static if ("XX".startsWith("GI", "KI", "KA", "HI")) {
foreach (to; target.b[0].BitwiseRange !ulong) { *(mlist++) = Move(komaType.YYXX, to); }
foreach (to; target.b[1].BitwiseRange !(ulong, 17)) { *(mlist++) = Move(komaType.YYXX, to); }
}
}
}.generateReplace("XX", [ "FU", "KY", "KE", "GI", "KI", "KA", "HI" ]));
return mlist;
}
その他、実行速度を上げるためにやっていること
LDCを使う
上の表からもわかる通り公式のコンパイラ(DMD)より速いです
またAVX(BMI)の組み込み関数も利用できます
コードを単一ファイルに事前に結合する
あまり行儀は良くない気がしますがLDCの最適化が最大限かかるようです
(適切なモジュール設計ができていないだけ?)
(他に良い方法があれば教えて下さい)
その他
サンプルには含まれていない部分についてですが、、
- GUIによる盤面表示をSDL(Derelict)で、通信部をstd.socketstream(今はもうDeprecatedですが..)を使うことで、GUI、通信部を含めた全てをD言語で書くことができました。GUI/通信部を自前で用意できたことで、対局サーバから送られてくる正確な消費時間を取得でき、思考時間の制御に役立ちました。
- 局面の探索はマルチスレッドで実行しています(YBWC)。できるだけGCが走らないように探索を書ければしっかりCPUを使い切ってくれます。
- 指し手のスコア関数の特徴を文字列mixinを利用することで、「学習用の特徴抽出関数と探索時に利用するスコア計算関数の記述の共通化」、「重み配列の各特徴のoffset値のコンパイル時計算」が可能になりました。特徴の完全な出し入れが1箇所1行の変更で可能になり試行錯誤するのに役立ちました。(最終的には指し手のスコア関数を用いることで一致率は局面更新なしで約37%まで達しました)
まとめ
D言語でコンピュータ将棋プレイヤを作りました。
D言語はコンピュータゲームプレイヤを作るのに現実的な実行速度を備えながら、書きやすくて楽しい言語です!
よかったらD言語でコンピュータゲームプレイヤをつくってみませんか?