はじめに
こんにちは,keygoroと申します.よろしくお願いします.
今回,Pythonを使用して四則演算に対応するアセンブリ言語プログラムを生成するプログラムを作成しました.完成形ではありませんが,ここにまとめたいと思います.作成するにあたり,植山類さんの低レイヤを知りたい人のためのCコンパイラ作成入門(https://www.sigbus.info/compilerbook) を参考にさせていただきました.
目的
今回の目的は,四則演算に対応するアセンブリ言語プログラムを生成するコンパイラをPythonで作成することである.例えば,30 + (4 − 2) × 5などの式がコンパイルできるようにする.
コンパイラで計算を行う際,計算の優先順位を処理する必要がある.入力として与えられる数式はただの文字列であって,構造化されたデータではない.式を正しく評価するためには,文字の並びを解析して,そこに隠れた構造をうまく導き出す必要がある.そのために,今回は構文解析の最も一般的なアルゴリズムの一つである「再帰下降構文解析法」を用いてコンパイラを作成する.以下で,コンパイラを作成するために重要なトークナイザ,構文解析,スタックマシンについて解説する.
トークナイザ
四則演算の式の最小単位のことをトークンと呼ぶ.例えば,5 + 20 − 4は,5, + ,20, − ,4という5つのトークンで構成されている.四則演算の式(文字列)をトークンの列に分解することを「トークナイズする」という.トークナイズする際には,四則演算に関係ない空白文字は無視する必要がある. 例えば,”5 + 20 − 4”という式も"5, + ,20, − ,4"という5つのトークンに分解されるようにプログラムする必要がある.
今回作成したPythonのプログラムでは,プログラム1で示すクラスにトークンの情報を格納している.kindはトークンの種類,valはトークンが数字だった場合の値,strはそのときのトークン文字列を表している.
例として, 1 * (2 + 3)のとき先頭のトークンは,kind=num,val=1,str=1*(2+3)となる.
# プログラム1 トークンのクラス
class Token:
def __init__(self, kind, val, str):
self.kind = kind
self.str = str
構文解析
四則演算の演算子の優先順位をうまく処理するためには,トークン列に対して構文解析を行う必要がある.コンパイルの行程で構文解析をする機能のことをパーサーと呼ぶ.パーサーはフラットなトークン列を演算子の優先順位を表現可能な木構造で表すことができる. 例えば,1 * (2 + 3)という式は,図1のような木構造で表すことができる.
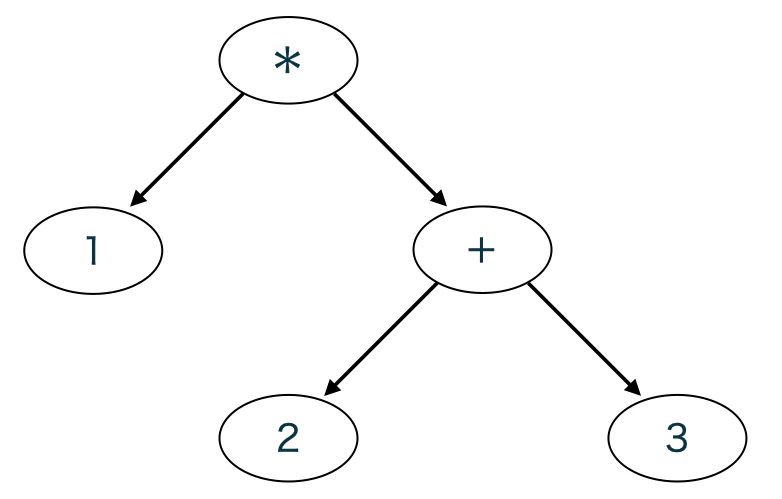
図1 1*(2+3)を表す抽象構文木
トークン列から構文木を生成するには,四則演算の法則を記述する必要がある.法則を記述するためにここでは*EBNF(Extended Backus-Naur Form)*を用いることにする.
EBNFでは,一つ一つの生成規則を$A=\alpha_1,\alpha_2,\dots$という形式で表す.これは記号$A$を$\alpha_1,\alpha_2,\dots$に展開できるという意味である.
$\alpha_1,\alpha_2,\dots$は0個以上の記号の列で,それ以上展開できない記号と,さらに展開される(いずれかの生成規則で左辺に来ている)記号の両方を含むことができる.以下は,EBNFを使って加減算の式の文法を表したものである.
expr = num ("+" num | "-" num)*
ここで,numは数値を表す記号を表している.この式では,まずnumが1つあって,その後に0個以上 の「+とnum,あるいは-とnum」があるものをexprとして定めている.
演算子の優先規則もEBNFによって,以下のように記述することができる.
expr = mul ("+" mul | "-" mul)*
mul = num ("*" num | "/" num)*
この規則では,exprが直接num(数字)に展開されず,mulを介してnumに展開されている.mulは乗除算の生成規則を表しているが,図2からもわかるように,この規則によって乗除算が先に実行されるという規則を構文木の中で自然に表現できる.
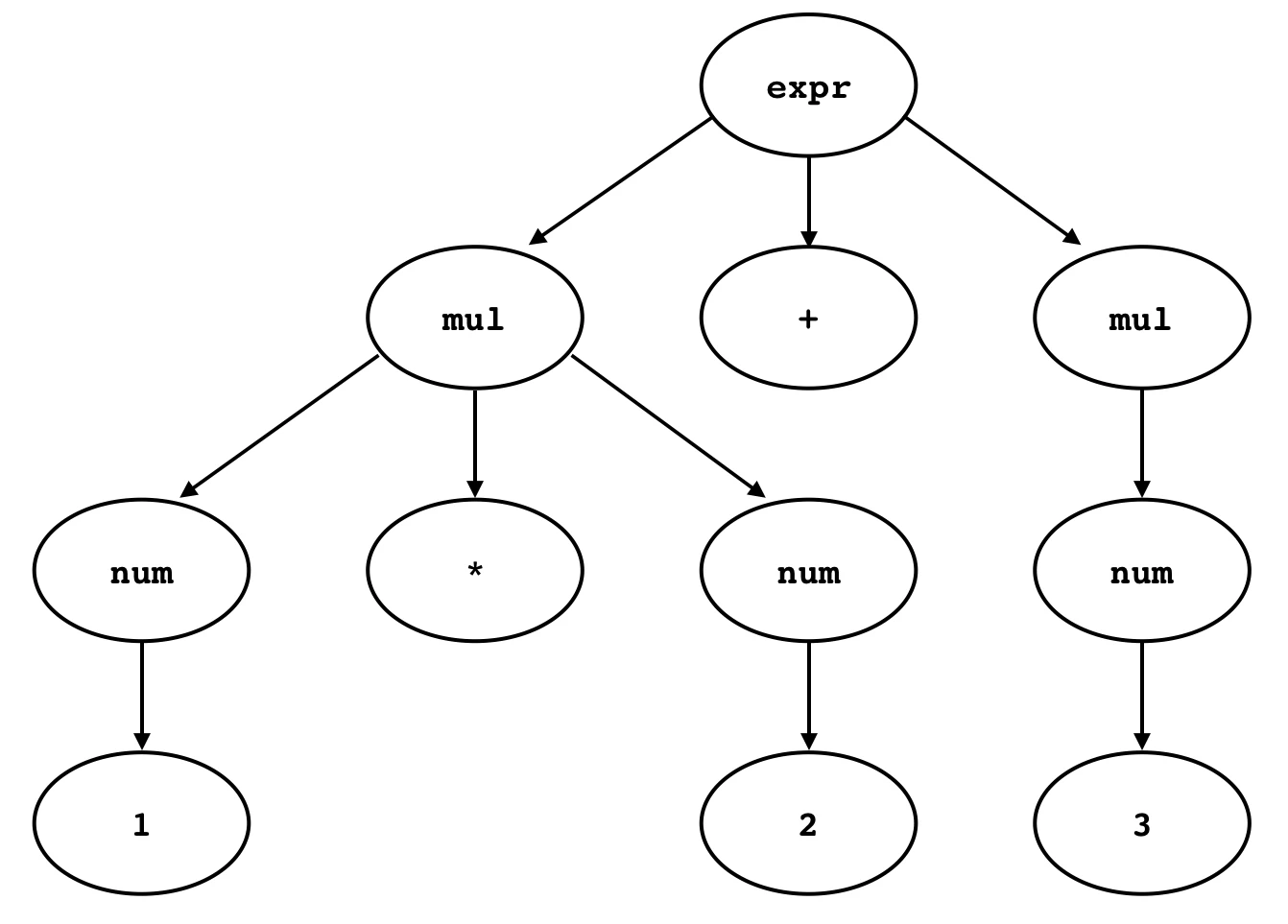
図2 1*2+3を表す具象構文木
ここで,図1のようなシンプルな構文木を抽象構文木,図2のような文法に1対1対応の構文木を具象構文木という.
また,以下のように再帰的に文法記述することにより,カッコの中を優先するという四則演算の規則を記述することができるようになる.
expr = mul ("+" mul | "-" mul)*
mul = primary ("*" primary | "/" primary)*
primary = num | "(" expr ")"
以下のプログラム3は,この文法にしたがって,トークン列から構文木を生成するプログラムの主要部分である.
Expr(), Mul(), Primary()という関数が,ENBFにおけるexpr, mul, primaryに対応している.NewNnode()は,構文木の新しいノードを生成する関数である.Consume()は今参照しているトークンが+, -, *, /などの演算子であるかを判定する関数である.
# プログラム2 構文木を生成するプログラム
def Expr():
node = Mul()#nodeに関数Mul()が入る
while True:#Trueの間繰り返す.
if Consume("+"):#Consumeでstr_opr="+"だったとき
node = New_Node(ND.ADD,node,Mul())#このような新しいノードを作る
elif Consume("-"):#Consumeでstr_opr="-"だったとき
node = New_Node(ND.SUB,node,Mul())#このような新しいノードを作る
else:
return node
def Mul():
node = Primary()#nodeに関数Primary()が入る
while True:#Trueの間繰り返す
if Consume("*"):#Consumeでstr_opr="*"だったとき
node = New_Node(ND.MUL,node,Primary())#このような新しいノードを作る
elif Consume("/"):#Consumeでstr_opr="/"だったとき
node = New_Node(ND.DIV,node,Primary())#このような新しいノードを作る
else:
return node
def Primary():
if Consume("("):#Consumeでstr_opr="("だったとき
node = Expr()#nodeにExpr()が入る
Expect(")")#関数Expectでstr_opr=)
return node
return New_Node_Num(Expect_Number())
スタックマシン
この章では,パーサーが生成した構文木をアセンブリ言語に変換するプログラムについて説明する.説明を簡単にするために,コンピュータとしては,スタックマシンを想定する.スタックマシンに対して変換できれば,それをx86-64用に拡張するのは容易である.スタックマシンは,スタックをデータ保存領域として持っているコンピュータのことである.したがってスタックマシンでは「スタックにプッシュする」と「スタックからポップする」という2つの操作が基本操作となる.プッシュでは,スタックの一番上に新しい要素が積まれ,ポップでは,スタックの一番上から要素が取り除かれる.スタックマシンにおける演算命令は,スタックトップの要素に作用する.例えばスタックマシンのADD命令は,スタックトップから2つ要素をポップしてきて,それらを加算し,その結果をスタックにプッシュする.SUB,MUL,DIV命令は, ADDと同じように,スタックトップの2つの要素を,それらを減算・乗算・除算した1つの要素で置き換える命令ということになる.このように定義したスタックマシンを使うと,次のようなコードで23+45を計算することができる.
// 2*3を計算
PUSH 2
PUSH 3
MUL
// 4*5を計算
PUSH 4
PUSH 5
MUL
// 2*3 + 4*5を計算
ADD
構文木をスタックマシンのコードに変換する方法について説明するために,図3のような加算を表す構文木を考える.
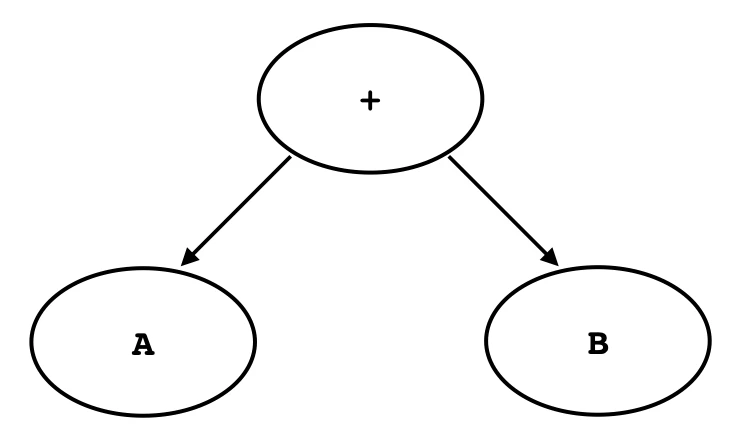
図3 加算を表す構文木
AやBというのは部分木を抽象化して表したもので,実際にはなんらかの型のノードを意味している.この木をコンパイルするときは次のようにすればよい.
- 左の部分木をコンパイルする
- 右の部分木をコンパイルする
- スタックの2つの値を,それらを加算した結果で 置き換えるコードを出力
すなわち,構文木をスタックマシンにコンパイルするときは,再帰的に考えて,木を下りながらアセンブリを出力していくことになる.プログラム3はこの処理を行うPythonのプログラムの主要部である. gen()という関数は再帰処理を行っている.
# プログラム3 スタックマシンへコンパイルするプログラム
def gen(node):
if node.kind == ND.NUM:#nodeの種類が数字のとき
print(" push ",node.val)#nodeの値をpushする
return
gen(node.lhs)#左辺
gen(node.rhs)#右辺
print(" pop rdi")
print(" pop rax")
if node.kind == ND.ADD:#nodeの種類がADDだった場合
print(" add rax, rdi")
elif node.kind == ND.SUB:#nodeの種類がSUBだった場合
print(" sub rax, rdi")
elif node.kind == ND.MUL:#nodeの種類がMULだった場合
print(" imul rax, rdi")
elif node.kind == ND.DIV:#nodeの種類がDIVだった場合
print(" cqo")
print(" idiv rdi")
else:
print("error")#どれにも当てはまらなかったらerror
print(" push rax")
プログラム
以下に,作成した四則演算コンパイラのプログラムをまとめて示す.
新しいトークンを作る関数,入力した数式をトークナイズする関数を定義
# 新しいトークンを作る関数,入力した数式をトークナイズする関数を定義
from enum import Enum
class TK(Enum): #列挙型
RESERVED = 0#記号なら0
NUM = 1#整数なら1
EOF = 2#入力の終わりなら2を出力
class Token:
def __init__(self, kind, val, str):#トークンの種類、数値、トークン文字列の場所
self.kind = kind #アトリビュートを追加 (kind,val,str)に対応
self.val = val
self.str = str
token = []#apendで追加していくリスト
oprlist=["+","-","*","/","(",")"]#演算子のリスト
def StrtoL(str):
str2=""
flg=0
for i in range(len(str)):#strの長さ分繰り返す
if oprlist.count(str[i]):#oprlistにある演算子に当てはまったらflg1としてbreak
flg=1
break
else:
str2+=str[i] #演算子ではないとき数字がstr2に加わる
if flg==1:
return int(str2),str[i:]#flg==1だったらこれを出力.int(str2)でstr2の文字列を数値に変換.str[i+1:]はstr[i]以降の数字を表示する
else:
return int(str2),0
def NewToken(kind,str):#tokenをつくってtoken[]に追加する
a=Token(kind,0,str)#numは「低レイヤ〜」で追加していないので0としている。
token.append(a)#tokenに追加
return a#aを返す
def Tokenize(p_str):#入力をトークナイズする関数
while True:#Trueの間繰り返す
if p_str[0].isspace():#先頭が空白なのかチェック
p_str=p_str[1:]#p_strの1文字目以降としてcontinue
continue
if p_str[0] in oprlist:#p_strの1文字目がoprlistと一致したら(p_oprの1文字目が記号だったら)
NewToken(TK.RESERVED,p_str)#kindをTK.RESERVED、strをp_strとして新しいトークンを作成
if len(p_str) >1:#p_strの長さが1以上として終端を決めている
p_str=p_str[1:]#p_strの1文字目以降としてcontinue
continue
else:
break#p_strの長さが1より小さければbreak
if p_str[0].isdigit():#p_strの1文字目が数字かどうかチェック
b = NewToken(TK.NUM,p_str)#kindをTK.NUM、strをp_strとして新しいトークンを作成
num,p_str=StrtoL(p_str)
b.val=num#valにnumを入れている
#p_str=n_str
if p_str==0:#p_str=0かチェック
break#p_str=0だったらbreak
else:#p_str=0でなかったら「トークナイズできません」と表示
continue
print("トークナイズできません")
NewToken(TK.EOF,0)
str1=input("数式:")
print(str1)
# str1 = "1*(2+2)"
Tokenize(str1)#入力str1についてトークナイズ
for i in token:
print("kind:",i.kind,"val:",i.val,"str:",i.str)
# 1*(2+2)と入力した場合の出力
数式:1+(2*2)
1+(2*2)
kind: TK.NUM val: 1 str: 1+(2*2)
kind: TK.RESERVED val: 0 str: +(2*2)
kind: TK.RESERVED val: 0 str: (2*2)
kind: TK.NUM val: 2 str: 2*2)
kind: TK.RESERVED val: 0 str: *2)
kind: TK.NUM val: 2 str: 2)
kind: TK.RESERVED val: 0 str: )
kind: TK.EOF val: 0 str: 0
EBNFによる四則演算の記述に対応した構文木を生成するための関数
from enum import Enum
cur_pos=0
def Consume(str_opr):#C言語でコンパイラを作成した場合のconsumeに対応
global token
global cur_pos
if token[cur_pos].kind!=TK.RESERVED or token[cur_pos].str[0]!=str_opr:#トークンの種類が記号ではない、または文字列の1文字目がstr_oprではないとき、falseを返す
return False
cur_pos+=1
return True#それ以外のときはtrue
def Expect(str_opr):#C言語でコンパイラを作成した場合のexpectに対応
global token
global cur_pos
if token[cur_pos].kind!=TK.RESERVED or token[cur_pos].str[0]!=str_opr:#トークンの種類が記号ではない、または文字列の1文字目が+,-ではないとき
print(str_opr,"ではありません")#+ではありません、-ではありません をプリント
cur_pos+=1
def Expect_Number():#C言語でコンパイラを作成した場合のexpect_numberに対応
global token
global cur_pos
if token[cur_pos].kind!=TK.NUM:#トークンの種類が数字ではない時、
print("数ではありません")#数ではありません。をプリント
val = token[cur_pos].val
cur_pos+=1
return val#数字を出力
def At_EOF():#C言語でコンパイラを作成した場合のat_eofに対応
global token
global cur_pos
return token[cur_pos].kind==TK.EOF#トークンの種類がEOF
class ND(Enum): #列挙型.抽象構文木でのノードの種類
ADD = 0#+
SUB = 1#-
MUL = 2#*
DIV = 3#/
NUM = 4#整数
class Node:#抽象構文木のノードの型
def __init__(self):
self.kind = None#ノードの型.何も入っていない場合はNone
self.val = None#ノードの値.kindがND_NUMの場合そのときの値を表示
self.lhs = None#左辺
self.rhs = None#右辺
def New_Node(kind,lhs,rhs):#新しいノードを作る関数
node = Node()#classNodeが入っている
node.kind = kind#ノードの型
node.lhs = lhs#左辺
node.rhs = rhs#右辺
return node
def New_Node_Num(val):
node = Node()
node.kind = ND.NUM#nodeの種類が数字
node.val = val#そのときの値
return node
def Expr():
node = Mul()#nodeに関数Mul()が入る
while True:#Trueの間繰り返す.
if Consume("+"):#Consumeでstr_opr="+"だったとき
node = New_Node(ND.ADD,node,Mul())#このような新しいノードを作る
elif Consume("-"):#Consumeでstr_opr="-"だったとき
node = New_Node(ND.SUB,node,Mul())#このような新しいノードを作る
else:
return node
def Mul():
node = Primary()#nodeに関数Primary()が入る
while True:#Trueの間繰り返す
if Consume("*"):#Consumeでstr_opr="*"だったとき
node = New_Node(ND.MUL,node,Primary())#このような新しいノードを作る
elif Consume("/"):#Consumeでstr_opr="/"だったとき
node = New_Node(ND.DIV,node,Primary())#このような新しいノードを作る
else:
return node
def Primary():
if Consume("("):#Consumeでstr_opr="("だったとき
node = Expr()#nodeにExpr()が入る
Expect(")")#関数Expectでstr_opr=)
return node
return New_Node_Num(Expect_Number())
node = Expr()
スタックマシンへコンパイルするプログラム
def gen(node):
if node.kind == ND.NUM:#nodeの種類が数字のとき
print(" push ",node.val)#nodeの値をpushする
return
gen(node.lhs)#左辺
gen(node.rhs)#右辺
print(" pop rdi")
print(" pop rax")
if node.kind == ND.ADD:#nodeの種類がADDだった場合
print(" add rax, rdi")
elif node.kind == ND.SUB:#nodeの種類がSUBだった場合
print(" sub rax, rdi")
elif node.kind == ND.MUL:#nodeの種類がMULだった場合
print(" imul rax, rdi")
elif node.kind == ND.DIV:#nodeの種類がDIVだった場合
print(" cqo")
print(" idiv rdi")
else:
print("error")#どれにも当てはまらなかったらerror
print(" push rax")
アセンブリプログラムを出力
print(".intel_syntax noprefix")
print(".globl main")
print("main:");
gen(node)
print(" pop rax")
print(" ret")
# 出力
.intel_syntax noprefix
.globl main
main:
push 1
push 2
push 2
pop rdi
pop rax
imul rax, rdi
push rax
pop rdi
pop rax
add rax, rdi
push rax
pop rax
ret
まとめ
四則演算に対応するアセンブリ言語プログラムを生成するコンパイラをPythonで作成した.今後としては,コンパイラを改良し現在扱うことのできない−3などの単項式の演算や,比較演算子を扱えるようにすることを考えている.
参考文献
1] 植山 類:低レイヤを知りたい人のためのCコンパイラ作成入門,https://www.sigbus.info/ compilerbook#,2020.