概要
csvファイルが時期毎や属性毎に分かれていたりする場合があり、それらのファイルを一行で読み込めるようにするべく、実装しました。
目的の機能は以下の通りです。
・フォルダ内のcsvファイルを全て読み込む。
・指定の文字を含むcsvファイルのみ対象とすることも出来るようにする。
・下位ディレクトリも含められるようにする。
実行環境
・Windows10 64bit
・Python 3.8.3
・pandas 0.25.3
・seaborn 0.11.0
実装
1.データ準備
irisデータ(150件)を4分割して、csvファイルとして保存(Eドライブ直下の"main"フォルダ)。また、"main"フォルダ内の”sub”フォルダにも同じファイルを保存。
import seaborn as sns
data = sns.load_dataset('iris')
import os
os.makedirs(r'E:\main', exist_ok=True)
for i in range(4):
st = int(0 if i==0 else (len(data)/4)*i)
en = int((len(data)/4)*(i+1))
data.iloc[st:en].to_csv(r'E:\main\iris{}.csv'.format(i), encoding='cp932', index=False)
os.makedirs(r'E:\main\sub', exist_ok=True)
for i in range(4):
st = int(0 if i==0 else (len(data)/4)*i)
en = int((len(data)/4)*(i+1))
data.iloc[st:en].to_csv(r'E:\main\sub\iris{}.csv'.format(i+4), encoding='cp932', index=False)
2.csvファイル読み込み
結果としては、以下の関数にて実装しました。
import glob
import pandas as pd
def read_csv(path, encode, sub_check=False, target_name=None):
#フォルダ内全てのcsvファイルのパスをlistで取得
#sub_check=Trueならサブフォルダまで対象
target_files = glob.glob(path+r'\**\*.csv', recursive=True) if sub_check else glob.glob(path+r'\*.csv')
#結合後のファイル格納用
merged_file = pd.DataFrame()
#対象のcsvファイルを全て結合
for filepath in target_files:
#ファイル名に指定の文字を含まなければ対象外とする
filename = filepath.split('\\')[-1]
if target_name!=None and target_name not in filename: continue
#一つのcsvファイルを読み込み
input_file = pd.read_csv(filepath, encoding=encode, sep=",", engine='python')
#一つのcsvファイルを今までに読み込んだcsvファイルへ結合
merged_file = pd.concat([merged_file, input_file], axis=0)
#結合後のDataFrameのindexをリセット
merged_file = merged_file.reset_index(drop=True)
return merged_file
動作確認
1.一つのフォルダ内のcsvファイル読み込み
一つのフォルダ内のcsvファイル(150件)を全て読み込めました。

2.一つのフォルダ内のcsvファイルで指定ファイルのみ読み込み
target_nameに"1"を指定すると、名前に”1”を含むcsvファイル(38件)を読み込めました。

3.下位ディレクトリも含めてファイル読み込み
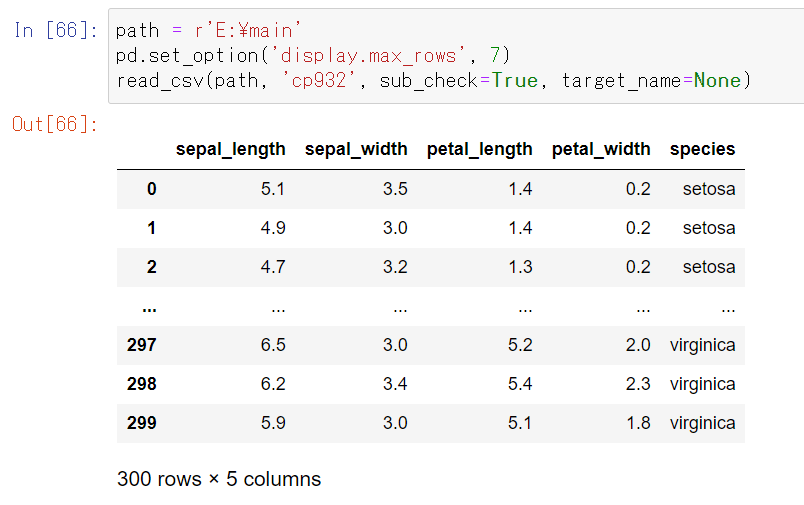
sub_check=Trueとすれば、下位ディレクトリの"sub"フォルダも含めて、csvファイル(300件)を全て読み込めました。
以上、閲覧頂きありがとうございました。