背景・目的
とあるテーブルデータで機械学習モデルを構築するにあたって、クラス間での差異を無くしたい変数が出てきたため、その処理を実装しました。
手法
指定区間ごとで、属性毎にアンダーサンプリングしています。
今回は、seabornのtitanic(タイタニック)データを使用して、alive(生存状況)が’yes’の群と、’no’の群の間で、10代毎の年齢での人数を整合させました。
環境
OS:Windows10
conda:4.8.3
python:3.8.3
pandas:0.25.3
matplotlib:3.3.1
seaborn:0.11.0
実装
データ取得
以下の様にして、データを取得します。
load_dataset.py
import seaborn as sns
data = sns.load_dataset("titanic")
補正前データ確認
取得データについて、alive(生存状況)毎の10代毎年齢分布は、以下の通りです。
display_gragh.py
import matplotlib.pyplot as plt
sns.set_style(style='darkgrid')
fig, ax = plt.subplots(1,1, figsize=(4,4))
ax.set_xticks(range(0,100,10))
ax.set_ylim(0,150)
ax.set_ylabel('the number of people')
sns.distplot(data['age'][data['alive']=='yes'], kde=False, rug=False, bins=range(0,100,10),
label='alive', ax=ax)
sns.distplot(data['age'][data['alive']=='no'], kde=False, rug=False, bins=range(0,100,10),
label='dead', ax=ax)
ax.legend()
plt.show()
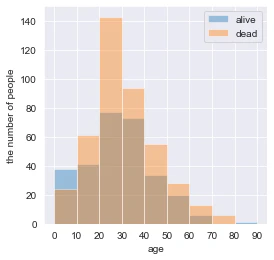
年齢分布整合
データ整合のために以下の関数を作成しました。
import pandas as pd
def adjust_number(data, target_column, attribute, period):
'''
target_column:調整対象のカラム名
attribute :調整対象の属性(この属性間で対象カラムの数を調整)
period :調整する区間幅
'''
##初期区間設定
#下限は、対象データ群の最小値が0以上なら0から、0未満ならその最小値からスタート
lower = 0 if data[target_column].min() >= 0 else data[target_column].min()
#上限は、下限+区間幅-1からスタート
upper = lower+period-1
data_adjusted = pd.DataFrame() #調整後データ格納用
maximum = data[target_column].max() #調整対象データ群の最大値取得
#下限が最大値を超過するまで繰り返し
while lower <= maximum:
#対象区間のデータを抽出
data_in_range = data[(lower<=data.loc[:,target_column]) & (data.loc[:,target_column]<=upper)]
#対象区間にデータが無い、または対象区間にデータが存在しない属性が有れば、次の区間へ
#(アンダーサンプリングのため、いずれかの属性のデータ数が0なら、全て0となる)
if len(data_in_range) == 0 or set(data[attribute]) != set(data_in_range[attribute]):
lower += period
upper += period
continue
else:
#対象区間での属性ごとデータ数取得
counts = data_in_range[attribute].value_counts()
#属性ごとにアンダーサンプリング
sample = pd.DataFrame()
for att in counts.index:
sample = data_in_range[data_in_range[attribute]==att].sample(n=counts.min(), random_state=42)
#対象区間の調整後データを、格納済みの調整後データへ連結
data_adjusted = pd.concat([data_adjusted, sample],axis=0, ignore_index=True)
#次の区間へ
lower += period
upper += period
return data_adjusted
この関数で処理した後(年齢分を整合した後)の10代毎の年齢分布が、以下の通りです。
補正前も再度載せています。
data_adjusted = adjust_number(data, target_column='age', attribute='alive', period=10)
fig, ax = plt.subplots(1,1, figsize=(4,4))
ax.set_xticks(range(0,100,10))
ax.set_ylim(0,150)
ax.set_ylabel('the number of people')
sns.distplot(data_adjusted['age'][data_adjusted['alive']=='yes'], kde=False, rug=False, bins=range(0,100,10),
label='alive', ax=ax)
sns.distplot(data_adjusted['age'][data_adjusted['alive']=='no'], kde=False, rug=False, bins=range(0,100,10),
label='dead', ax=ax)
ax.legend()
plt.show()
▼補正後 ▼補正前


無事補正出来ました。
応用1(区間幅変更)
区間幅を10→5に変更(5歳ごとの人数を整合)しても問題無く動作しました。
data_adjusted = adjust_number(data, target_column='age', attribute='alive', period=5)
▼補正後 ▼補正前


応用2(調整対象変更)
調整対象をfare(料金)に変更しても問題ありません。
data_adjusted = adjust_number(data, target_column='fare', attribute='alive', period=30)
▼補正後 ▼補正前


応用3(対象属性変更)
対象属性をsex(性別)に変更しても問題無しです。
data_adjusted = adjust_number(data, target_column='age', attribute='sex', period=10)
▼補正後 ▼補正前


以上になります。
ご閲覧頂きありがとうございました。