1. はじめに
本記事は、ChatGPTを活用してみたいけれど、どうやって使うの?という方向けの、「ChatGPTと始める」シリーズ第3弾として、機械学習アプリの開発に取り組みます!
(「ChatGPTと始める」シリーズ第1弾, 第2弾はこちらです。どちらもたくさんのいいねをありがとうございます。)
今回は「猫の品種判別アプリ」を題材に、ChatGPT-4 にどのように機械学習アプリの開発を手伝ってもらうかについて順を追って説明します。
ChatGPTのおかげで、機械学習に対するハードルが大幅に下がったため、機械学習に挑戦したいと思っていたエンジニアの方々にも、ぜひトライしていただきたいです!
2. アプリの仕様を相談しよう!
2.1. 転移学習について
今回は「猫の品種判別アプリ」を作ってみようと思います。
先に完成品のキャプチャ動画を貼っておきます。
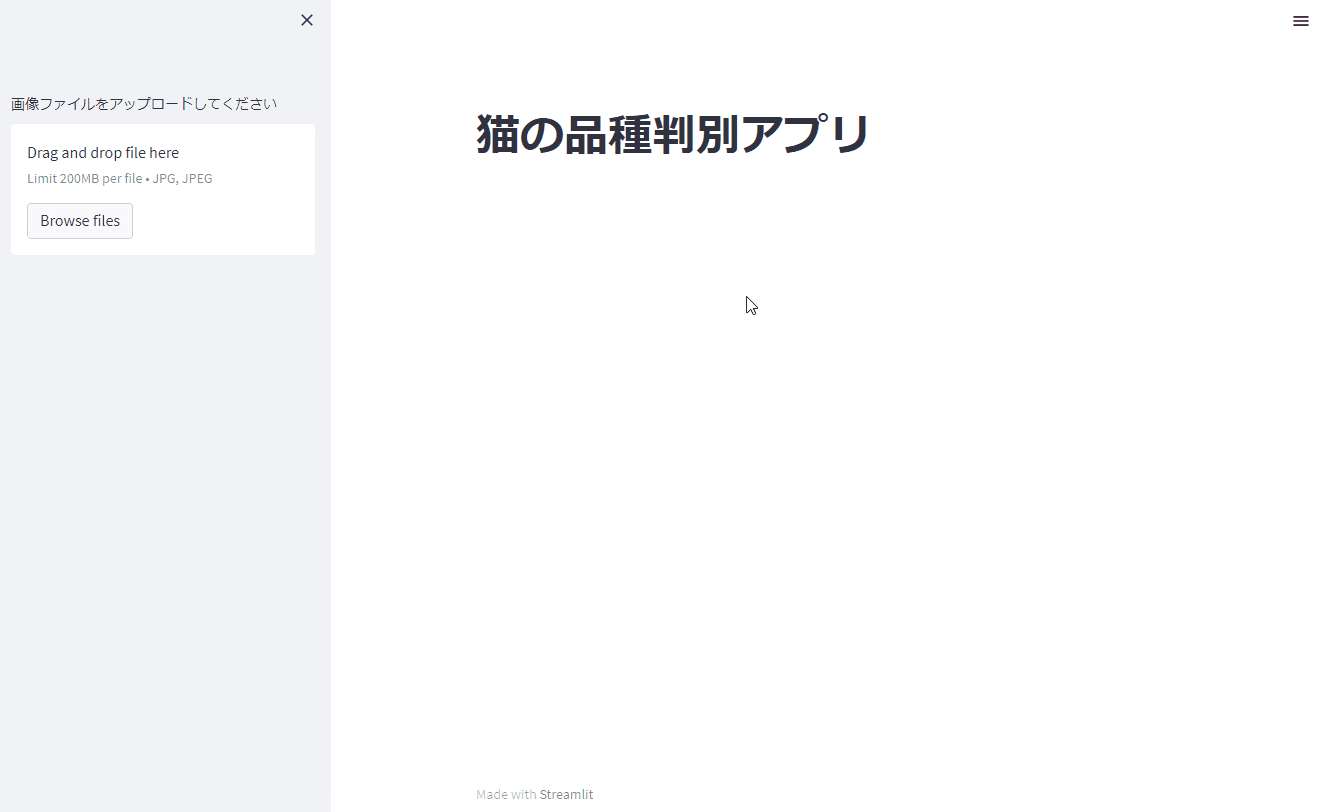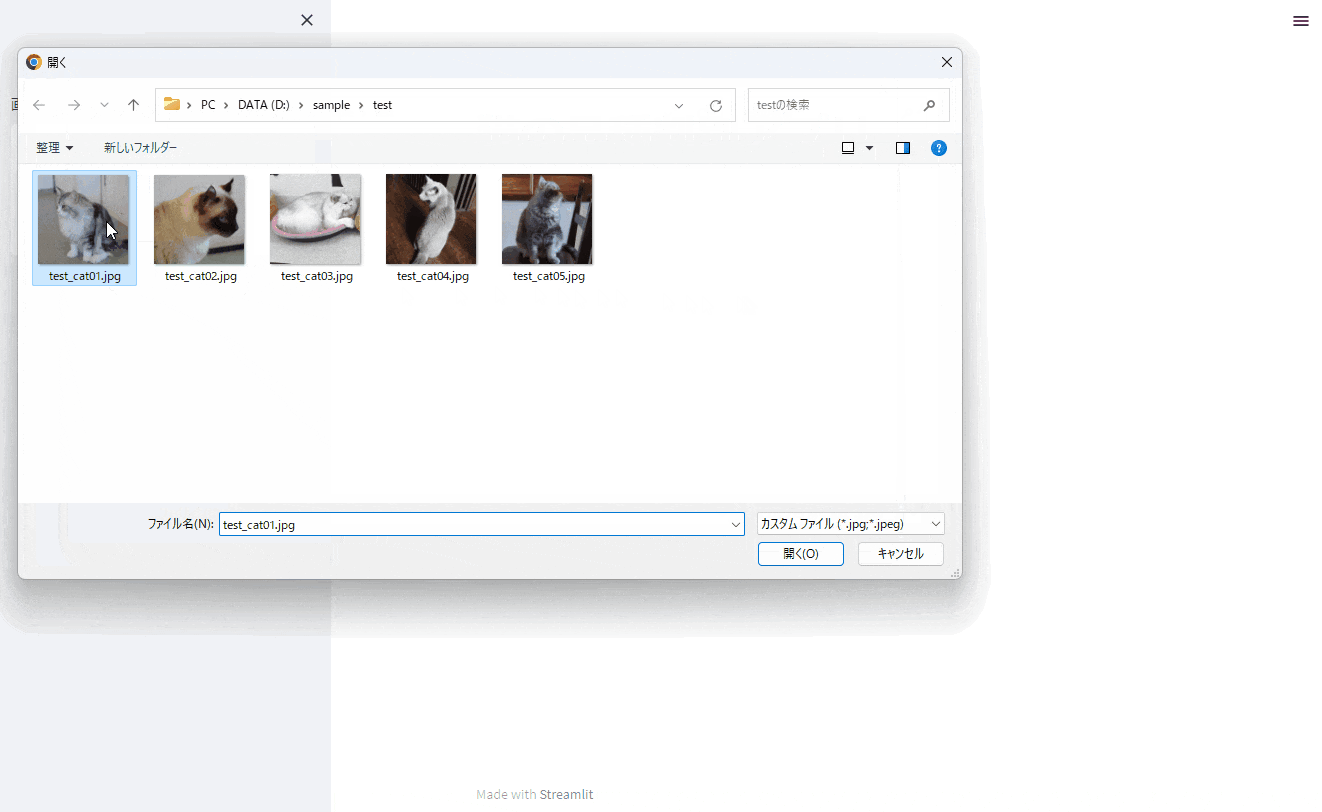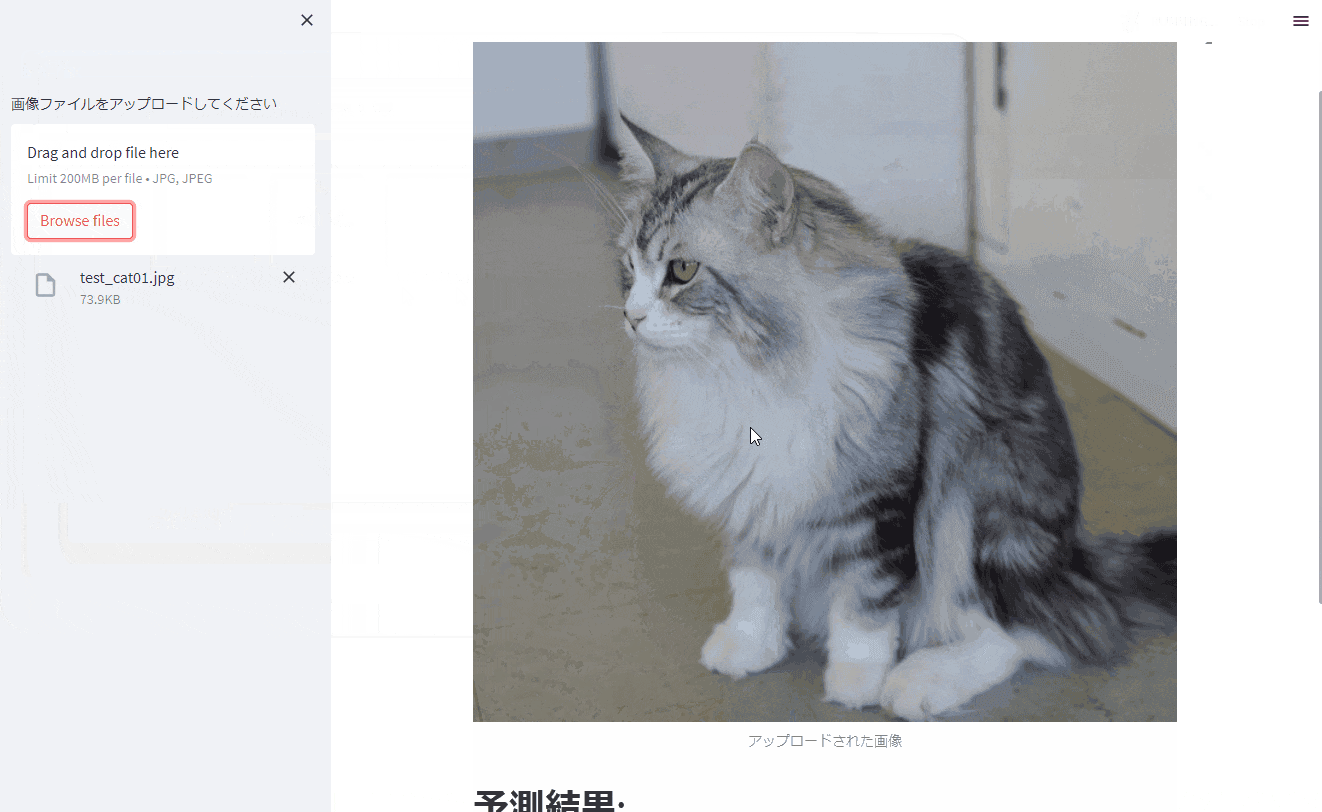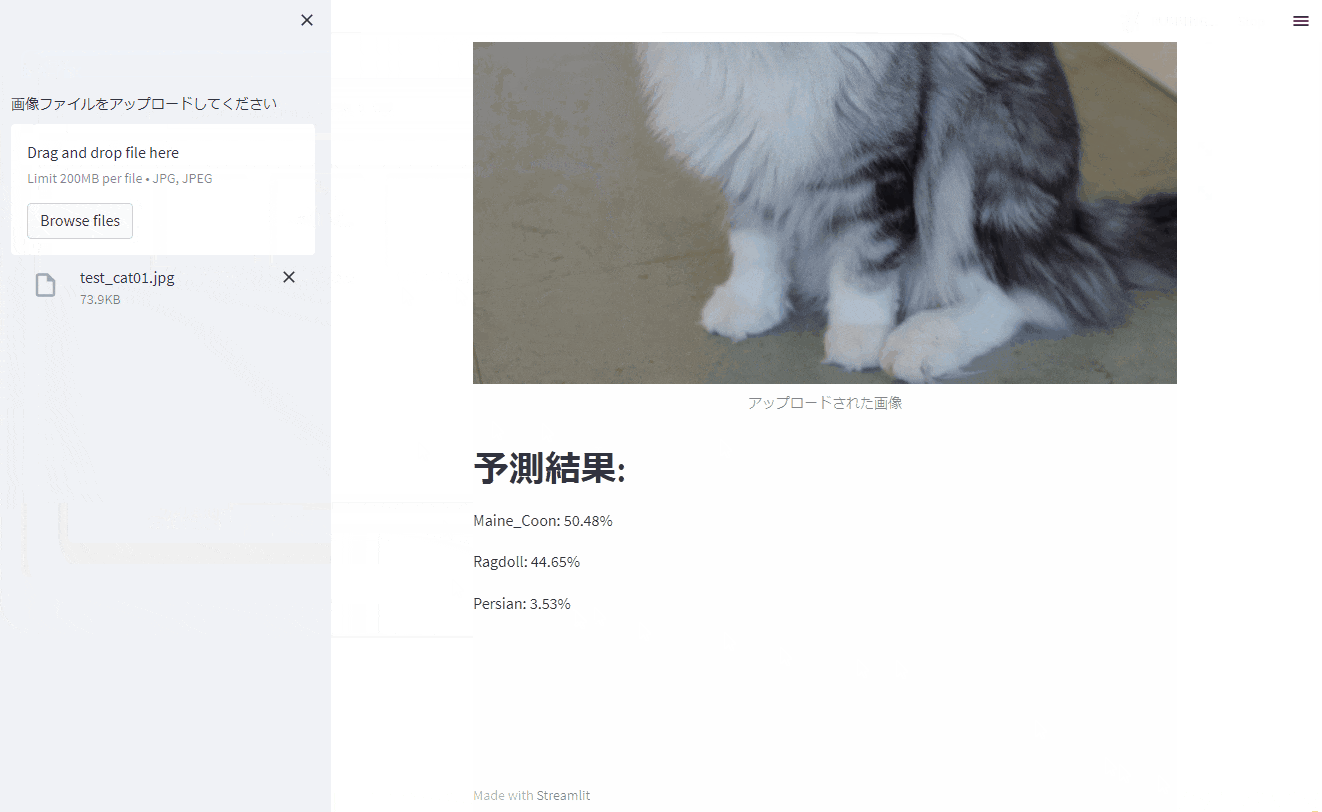
一例として「猫の品種判別アプリ」を使用しますが、Deep Learningの一手法である転移学習を使用すると、様々なものに応用することができます。
皆様には作ってみたいものをイメージしながら読んでいただけばと思います。
補足: 転移学習ってなに?

概要:
転移学習(Transfer Learning)は、ディープラーニングの一種で、すでに訓練済みのニューラルネットワークモデルを、新しいタスクやデータセットに適用する手法です。この方法では、すでに学習済みのモデルが持つ知識や特徴抽出能力を利用し、新しいタスクのために最適化されたモデルを効率的に作成することができます。転移学習は、学習時間の短縮やデータ不足を解消するために広く利用されています。
メリット:
- 学習時間の短縮: すでに訓練済みのモデルを使用するため、学習にかかる時間が大幅に削減されます。
- データ不足の解消: 転移学習では、元のモデルが持つ知識を利用するため、新しいタスクに必要なデータ量が少なくても、高い性能のモデルを構築できます。
- 汎用性: さまざまなタスクやデータセットに適用できるため、多様な問題解決に役立ちます。
どういったことに使えるのか(産業分野の使用例):
- 画像認識: 転移学習は、医療画像診断、製品不良検出、自動運転システムの画像解析など、画像認識タスクに広く利用されています。
- 自然言語処理: ニュース記事のカテゴリ分類、感情分析、チャットボットなど、文章解析や生成に関するタスクでも転移学習が活用されています。
- 音声認識: 音声アシスタントや音声翻訳システム、音声からの感情認識など、音声データを扱うタスクにも転移学習が使われます。
転移学習は、これらの分野において効率的なモデル構築や高い性能を発揮することができ、初心者にも短時間で高品質な成果を得ることが可能です。
2.2. 仕様について相談する
これまで(記事以外も含めて)さまざまなアプリやプログラムを作成してきたのですが、ChatGPT にいきなりコードを書くのを指示するのはオススメできません。
(特に専門外のものを依頼する場合、仕様が細かく指示できないため、出てくるコードが思った通りの機能ではなかったり、修正を指示するのに苦労することが多いです。)
上司の指示と同じように、一番始めの指示が的確であれば、その後の作業効率がアップします。
なので、まずは自分がどのようなものを作ってもらいたいと思っているのか、ChatGPTと議論してみることをオススメします。
では、ざっくりと仕様を聞いてみます。


イメージはずれていないですが、いくつか不明点があるので聞いてみましょう。
(略)
仕様内容を順番にチェックしながら、最終的に、議論して出来上がった仕様がこちらです。
以下、Qiitaに回答を貼りつけて表示しています。
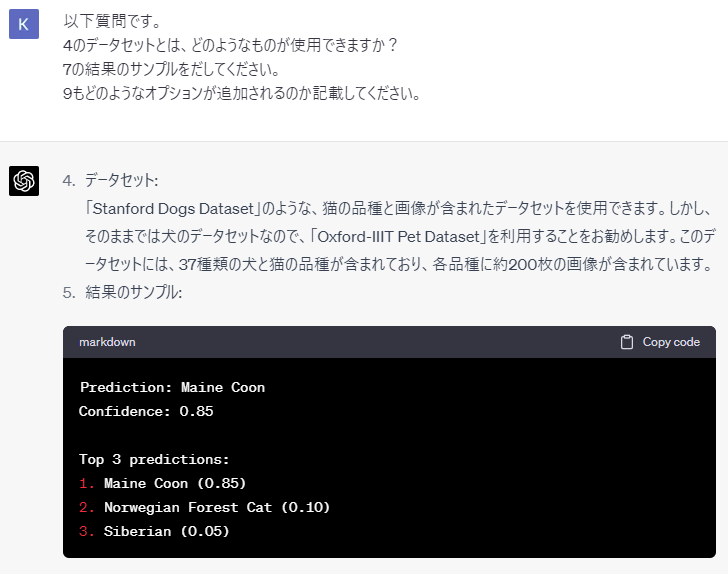
- コマンドライン引数: オプションで画像へのパス、学習済みモデルへのパス、データセットへのパス、上位k個の表示、学習モードを指定できるようにする
- 学習モード: 学習モードが指定された場合、Oxford-IIIT Pet Datasetを用いてResNetモデルを学習させ、学習済みモデルを保存する
- 画像入力: ターミナルから猫の画像ファイルへのパスを入力する
- 画像読み込み: 入力されたパスから画像を読み込む
- 画像前処理: 画像のリサイズや正規化を行う
- 学習済みモデルの読み込み: 予測モード時に、指定されたパスから学習済みResNetモデルを読み込む
- 予測: 学習済みResNetモデルを用いて、読み込んだ画像から猫の品種を予測
- 結果表示: ターミナルに予測された品種とその確率を表示(上位k個)
- エラー処理: 不適切な画像や予測失敗時のエラーメッセージをターミナルに表示
コマンドライン引数のオプション:
-
--mode: 実行モードを指定('train'または'predict') -
--model_path: 学習済みモデルのファイルパスを指定 -
--dataset_path: データセットのフォルダパスを指定(学習モード時に使用) -
--image_path: 分類したい猫の画像ファイルへのパスを指定(予測モード時に使用) -
--top_k: 上位k個の予測結果を表示する(デフォルトは3)
例:
# 学習モード
python cat_breed_classifier.py --mode train --model_path model.pth --dataset_path ./dataset
# 予測モード
python cat_breed_classifier.py --mode predict --model_path model.pth --image_path cat.jpg --top_k 5
始めに聞いたものに比べて、仕様が詳細化されました。
3. ChatGPTにコードを生成してもらおう!
3.1. 生成されたコード
つぎに、先ほど得た仕様を使ってChatGPTにコードの生成をお願いします。
以下が依頼文(プロンプト)ですが、このプロンプトのベースは、前の記事(ChatGPTと始めるシリーズ)と同じなので割愛します。

長いので折りたたみますが、ChatGPTから返ってきた初期のコードはこちらになります。
初期に生成してくれたコード
import argparse
import os
import sys
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms
from PIL import Image
# 学習の関数
def train_model(model, criterion, optimizer, scheduler, dataset_path, num_epochs=25):
# データの読み込みと前処理
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets = {x: datasets.ImageFolder(os.path.join(dataset_path, x), data_transforms[x]) for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
for epoch in range(num_epochs):
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
return model
# 画像の読み込みと前処理
def load_image(image_path):
img = Image.open(image_path)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_tensor = preprocess(img)
img_tensor.unsqueeze_(0)
return img_tensor
# 予測の関数
def predict(model, image_path, class_names, top_k=3):
img_tensor = load_image(image_path)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_tensor = img_tensor.to(device)
model.eval()
with torch.no_grad():
outputs = model(img_tensor)
_, preds = torch.topk(outputs, top_k, dim=1)
probabilities = torch.softmax(outputs, dim=1)
top_probabilities, top_indices = torch.topk(probabilities, top_k, dim=1)
return [(class_names[index], float(prob)) for index, prob in zip(top_indices[0], top_probabilities[0])]
def main(args):
if args.mode == 'train':
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(args.class_names))
model_ft = model_ft.to(args.device)
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, args.dataset_path, num_epochs=args.num_epochs)
torch.save(model_ft.state_dict(), args.model_path)
elif args.mode == 'predict':
model_ft = models.resnet18()
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(args.class_names))
model_ft.load_state_dict(torch.load(args.model_path))
model_ft = model_ft.to(args.device)
predictions = predict(model_ft, args.image_path, args.class_names, top_k=args.top_k)
for breed, prob in predictions:
print(f"{breed}: {prob * 100:.2f}%")
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--mode', choices=['train', 'predict'], required=True, help="実行モードを指定('train'または'predict')")
parser.add_argument('--model_path', required=True, help='学習済みモデルのファイルパスを指定')
parser.add_argument('--dataset_path', help='データセットのフォルダパスを指定(学習モード時に使用)')
parser.add_argument('--image_path', help='分類したい猫の画像ファイルへのパスを指定(予測モード時に使用)')
parser.add_argument('--top_k', type=int, default=3, help='上位k個の予測結果を表示する(デフォルトは3)')
args = parser.parse_args()
main(args)
現状の GPT-4 では、上記のような長いコードだと必ず数個はエラーが発生するので、順番にエラーを修正する必要があります。
今回は、以下のような対応を実施しました。
- Oxford-IIIT Pet Dataset から猫のデータセットを作成する部分のコードがなかったため追加。
-
__main__の中のargsの設定が足りず,エラーが出ていたため修正。 - 1.のコードがPytorch用のフォルダ構造に対応したものではなく,読み込みにエラーが発生したため修正。
- コメントの数が少なかったため、追加を依頼。
現状のGPT-4は「Pythonを一切使えなくてもできます!」というほどではないですが、これまでこのレベルは手を出しづらかったエンジニアでも、試してみよう!と思えるくらいハードルが下がったのではないかと思います。
完成したコードはこちらです。
長いので折りたたんでいます
# 画像データとアノテーションデータをダウンロードするためのコマンド
# !wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
# !wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
# 画像データとアノテーションデータを解凍するためのコマンド
# !tar -xvf images.tar.gz
# !tar -xvf annotations.tar.gz
# 必要なライブラリをインポート
import os
import shutil
import random
# 猫のデータセットを作成する関数
def create_cat_dataset(src_dir, dest_dir, train_ratio=0.8):
# 出力ディレクトリが存在しない場合、ディレクトリを作成
if not os.path.exists(dest_dir):
os.makedirs(dest_dir)
os.makedirs(os.path.join(dest_dir, "train"))
os.makedirs(os.path.join(dest_dir, "val"))
# 猫の品種リスト
cat_breeds = ["Abyssinian", "Bengal", "Birman", "Bombay", "British_Shorthair", "Egyptian_Mau", "Maine_Coon", "Persian", "Ragdoll", "Russian_Blue", "Siamese", "Sphynx"]
# 品種ごとの画像ファイルを格納する辞書を初期化
cat_files = {breed: [] for breed in cat_breeds}
# 各画像ファイルを品種ごとに分類
for f in os.listdir(src_dir):
for breed in cat_breeds:
if f.endswith(".jpg") and f.startswith(breed):
cat_files[breed].append(f)
break
# 各品種の画像ファイルをシャッフル
for breed in cat_breeds:
random.shuffle(cat_files[breed])
# 訓練用と検証用のディレクトリを作成
train_breed_dir = os.path.join(dest_dir, "train", breed)
val_breed_dir = os.path.join(dest_dir, "val", breed)
os.makedirs(train_breed_dir)
os.makedirs(val_breed_dir)
# 訓練用と検証用にデータを分割
split_idx = int(len(cat_files[breed]) * train_ratio)
train_files = cat_files[breed][:split_idx]
val_files = cat_files[breed][split_idx:]
# 画像ファイルを訓練用と検証用のディレクトリにコピー
for f in train_files:
shutil.copy(os.path.join(src_dir, f), os.path.join(train_breed_dir, f))
for f in val_files:
shutil.copy(os.path.join(src_dir, f), os.path.join(val_breed_dir, f))
# 入力ディレクトリと出力ディレクトリのパスを指定
src_dir = "images"
dest_dir = "cat_dataset"
# 猫のデータセットを作成
create_cat_dataset(src_dir, dest_dir)
import argparse
import os
import sys
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms
from PIL import Image
# 学習の関数
def train_model(model, criterion, optimizer, scheduler, dataset_path, num_epochs=25):
# データの読み込みと前処理
# 画像のリサイズ、クロップ、正規化などを行う
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224), # ランダムなリサイズとクロップ
transforms.RandomHorizontalFlip(), # ランダムな水平反転
transforms.ToTensor(), # テンソルへの変換
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 正規化
]),
'val': transforms.Compose([
transforms.Resize(256), # リサイズ
transforms.CenterCrop(224), # 中心をクロップ
transforms.ToTensor(), # テンソルへの変換
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 正規化
]),
}
# 画像データセットの読み込み
image_datasets = {x: datasets.ImageFolder(os.path.join(dataset_path, x), data_transforms[x]) for x in ['train', 'val']}
# データローダーの作成
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=4) for x in ['train', 'val']}
# データセットのサイズを取得
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
# クラス名を取得
class_names = image_datasets['train'].classes
# GPUが利用可能な場合はGPUを使用し、そうでない場合はCPUを使用する
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 各エポックを処理
for epoch in range(num_epochs):
# 学習フェーズと検証フェーズを処理
for phase in ['train', 'val']:
# 学習モードか検証モードを設定
if phase == 'train':
model.train()
else:
model.eval()
# 損失と正解数を初期化
running_loss = 0.0
running_corrects = 0
# 各バッチを処理
for inputs, labels in dataloaders[phase]:
# 入力データとラベルをデバイスに転送します。
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# 順伝搬(学習時のみ勾配計算を有効に)
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 逆伝搬と最適化(学習時のみ)
if phase == 'train':
loss.backward()
optimizer.step()
# 統計情報を更新
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
# 学習時には学習率スケジューラを更新
if phase == 'train':
scheduler.step()
# エポックの損失と正解率を計算
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
# 損失と正解率を表示
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# 学習済みモデルを返す
return model
# 画像の読み込みと前処理
def load_image(image_path):
img = Image.open(image_path)
preprocess = transforms.Compose([
transforms.Resize(256), # リサイズ
transforms.CenterCrop(224), # 中心をクロップ
transforms.ToTensor(), # テンソルへの変換
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 正規化
])
img_tensor = preprocess(img)
img_tensor.unsqueeze_(0)
return img_tensor
# 予測の関数
def predict(model, image_path, class_names, top_k=3):
img_tensor = load_image(image_path)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_tensor = img_tensor.to(device)
model.eval()
with torch.no_grad():
outputs = model(img_tensor)
_, preds = torch.topk(outputs, top_k, dim=1)
probabilities = torch.softmax(outputs, dim=1)
top_probabilities, top_indices = torch.topk(probabilities, top_k, dim=1)
return [(class_names[index], float(prob)) for index, prob in zip(top_indices[0], top_probabilities[0])]
# メイン関数
def main(args, class_names, device, num_epochs):
if args.mode == 'train':
# 学習モード
# モデルの読み込み
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
model_ft = model_ft.to(device)
# 損失関数と最適化アルゴリズムの定義
criterion = nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# 学習率スケジューラの定義
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
# モデルの学習
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler, args.dataset_path, num_epochs=num_epochs)
# 学習済みモデルの保存
torch.save(model_ft.state_dict(), args.model_path)
elif args.mode == 'predict':
# 予測モード
# モデルの読み込み
model_ft = models.resnet18()
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
# 学習済みモデルのパラメータをロード
# model_ft.load_state_dict(torch.load(args.model_path))
model_ft.load_state_dict(torch.load(args.model_path, map_location=torch.device('cpu')))
model_ft = model_ft.to(device)
# 画像に対して予測を実行
predictions = predict(model_ft, args.image_path, class_names, top_k=args.top_k)
# 予測結果を表示
for breed, prob in predictions:
print(f"{breed}: {prob * 100:.2f}%")
if __name__ == '__main__':
# クラス名の定義
class_names = ['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair',
'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue',
'Siamese', 'Sphynx']
# デバイスの設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# エポック数の設定
num_epochs = 25
# コマンドライン引数のパーサーの定義
parser = argparse.ArgumentParser()
parser.add_argument('--mode', choices=['train', 'predict'], required=True, help="実行モードを指定('train'または'predict')")
parser.add_argument('--model_path', required=True, help='学習済みモデルのファイルパスを指定')
parser.add_argument('--dataset_path', help='データセットのフォルダパスを指定(学習モード時に使用)')
parser.add_argument('--image_path', help='分類したい猫の画像ファイルへのパスを指定(予測モード時に使用)')
parser.add_argument('--top_k', type=int, default=3, help='上位k個の予測結果を表示する(デフォルトは3)')
# コマンドライン引数の解析
args = parser.parse_args()
# メイン関数の実行
main(args, class_names, device, num_epochs)
(一部のコードに重複があるなど)直した方がいいなと思う部分は多少あるものの、手を一切加えずに、このレベルのコードを出力されるのはやはり驚愕です。
3.2. 学習モードの結果を、ChatGPTに相談してみよう!
得られたコードを使って、学習モードを実行します。
$ python cat_breed_classifier.py --mode train --model_path ./model.pth --dataset_path ./cat_dataset
これを実行すると,以下のように各ステップごとの結果が表示されます。
train Loss: 1.5605 Acc: 0.4818
val Loss: 0.5512 Acc: 0.8083
train Loss: 1.2769 Acc: 0.5875
val Loss: 0.4720 Acc: 0.8333
train Loss: 1.1678 Acc: 0.6182
val Loss: 0.5661 Acc: 0.8396
train Loss: 1.0494 Acc: 0.6620
val Loss: 0.4801 Acc: 0.8396
train Loss: 0.9613 Acc: 0.6880
val Loss: 0.5338 Acc: 0.8417
train Loss: 0.9556 Acc: 0.6984
val Loss: 0.4702 Acc: 0.8708
train Loss: 0.9503 Acc: 0.7021
val Loss: 0.4089 Acc: 0.8750
train Loss: 0.6625 Acc: 0.7823
val Loss: 0.3189 Acc: 0.8792
train Loss: 0.6123 Acc: 0.7995
val Loss: 0.2966 Acc: 0.9062
train Loss: 0.6303 Acc: 0.7995
val Loss: 0.2666 Acc: 0.9250
train Loss: 0.5896 Acc: 0.8125
val Loss: 0.2604 Acc: 0.9104
train Loss: 0.6021 Acc: 0.8104
val Loss: 0.2568 Acc: 0.9125
train Loss: 0.5702 Acc: 0.8172
val Loss: 0.2397 Acc: 0.9187
train Loss: 0.5928 Acc: 0.8047
val Loss: 0.2429 Acc: 0.9104
train Loss: 0.5169 Acc: 0.8307
val Loss: 0.2423 Acc: 0.9250
train Loss: 0.5027 Acc: 0.8370
val Loss: 0.2595 Acc: 0.9271
train Loss: 0.5453 Acc: 0.8182
val Loss: 0.2441 Acc: 0.9229
train Loss: 0.5727 Acc: 0.8172
val Loss: 0.2394 Acc: 0.9229
train Loss: 0.5586 Acc: 0.8219
val Loss: 0.2413 Acc: 0.9146
train Loss: 0.5214 Acc: 0.8339
val Loss: 0.2359 Acc: 0.9229
train Loss: 0.5324 Acc: 0.8219
val Loss: 0.2503 Acc: 0.9229
train Loss: 0.5347 Acc: 0.8250
val Loss: 0.2357 Acc: 0.9146
train Loss: 0.5860 Acc: 0.8042
val Loss: 0.2382 Acc: 0.9208
train Loss: 0.4820 Acc: 0.8516
val Loss: 0.2455 Acc: 0.9271
train Loss: 0.4977 Acc: 0.8401
val Loss: 0.2559 Acc: 0.9125
これは良い結果なのでしょうか?
機械学習を専門的にやっていない場合、この結果をどう評価すればいいのかよくわからず悩むのですが、このような場合も、ChatGPTに相談してみましょう。


注意点として、ChatGPTは基本的に「いい人」のように振る舞うので、一生懸命コードを書いたあとであれば、私を応援しようとポジティブ寄りに答えることがあります。
変なバイアスがかかっている可能性があるため、反対の意見も聞いておきます。

(回答が長いので以降省略)
2人の(仮想の)データサイエンティストの意見を参考に、今回はデモ用なので、これ以上の性能は不要と思います。
ただし、指摘にあったように、データセットのばらつきや、猫の品種ごとに性能に違いがある可能性があるため、(仕事で使うなら)もう少し探ったほうがよさそうです。
このように、作業していて「これはなんでだろう」と悩むけれど、機械学習の専門家に直接聞くのははばかられるような、ちょっとした質問を ChatGPT にばんばんと聞くことができます!
もちろん上記のGPTが出した評価内容については、現状は専門家に勝てるレベルではないです。あくまで参考程度に、自分も考えてみることが大切だと思います。
3.2. 推論モードで結果確認
以下の猫の画像について、推論を実行してみました。

$ python cat_breed_classifier.py --mode predict --model_path ./model.pth --image_path ./images/test_cat.jpg --top_k 3
Russian_Blue: 99.08%
British_Shorthair: 0.77%
Ragdoll: 0.11%
ちゃんと正しく判定できていますね。
4. Webアプリ化をお願いする
ここから、サクッとWebアプリ化を実施します。今回も気軽に作れるPythonのWebアプリ化用ライブラリとして、Streamlit を使ったアプリ化をお願いしました。
コードは折りたたんでいます。
import streamlit as st
import torch
import torch.nn as nn
from torchvision import models, transforms
from PIL import Image
import os
def load_image(image_bytes):
img = Image.open(image_bytes)
preprocess = transforms.Compose([
transforms.Resize(256), # リサイズ
transforms.CenterCrop(224), # 中心をクロップ
transforms.ToTensor(), # テンソルへの変換
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 正規化
])
img_tensor = preprocess(img)
img_tensor.unsqueeze_(0)
return img_tensor
def predict(model, img_tensor, class_names, top_k=3):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_tensor = img_tensor.to(device)
model.eval()
with torch.no_grad():
outputs = model(img_tensor)
_, preds = torch.topk(outputs, top_k, dim=1)
probabilities = torch.softmax(outputs, dim=1)
top_probabilities, top_indices = torch.topk(probabilities, top_k, dim=1)
return [(class_names[index], float(prob)) for index, prob in zip(top_indices[0], top_probabilities[0])]
# クラス名の定義
class_names = ['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair',
'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue',
'Siamese', 'Sphynx']
model_path = './model.pth'
# モデルの読み込み
model_ft = models.resnet18()
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
# 学習済みモデルのパラメータをロード
model_ft.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))
model_ft.eval()
# Streamlitアプリの構築
st.title('猫の品種判別アプリ')
uploaded_file = st.sidebar.file_uploader("画像ファイルをアップロードしてください", type=['jpg', 'jpeg'])
if uploaded_file is not None:
image = Image.open(uploaded_file)
st.image(image, caption='アップロードされた画像', use_column_width=True)
img_tensor = load_image(uploaded_file)
predictions = predict(model_ft, img_tensor, class_names, top_k=3)
st.header('予測結果:')
for breed, prob in predictions:
st.write(f"{breed}: {prob * 100:.2f}%")
欲を言えば、(メンテナンス性の観点から)主要な機能は先に作ったコードから import するようにしてほしかったですが、(一発で動いたし)まぁいいでしょう。聞き方が原因な気もします。
以下のコマンドで実行し、
$ streamlit run app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://(自分のPCのIP):8501
http://localhost:8501 からwebアプリにアクセスすることができます。
望みの機能を持ったアプリが完成しました!
5. まとめ
今回、ChatGPTに機械学習アプリの仕様の相談するところから、動かした結果の評価の判断、アプリ化まで一連のプロセスを紹介しました。
みなさんも、ぜひ自分の仕事や趣味にぜひ応用してみてください!
関連記事
第4弾はこちら