1. はじめに
最近、色々な場所でChatGPTの情報が飛び交っていますが、進化が早すぎて全然追いつけていないです...
そんな中、私が投稿した「ChatGPTにGUI開発を手伝ってもらったら、すごすぎて驚きました」的な内容の初心者向けの記事に、たくさんいいねをいただきました(ありがとうございます)。
初心者向けのものにも需要があるのだろうかと、今回「ChatGPTと始める」シリーズ第2弾として、ChatGPTと協力してPythonでCSVデータの可視化を行いました。
さすがにプロットを書くだけではシンプルすぎるかなとWebアプリ化も実施しましたが、これからChatGPTを活用してみたいと考えているエンジニアの方々に、身近な例として参考になると嬉しいです!
2. matplotlib でプロットしよう!
2.1. 事前準備
以下のライブラリをインストールしてください。
pip install streamlit plotly pandas matplotlib
2.2. 今回やりたいこと
例題として、気象庁( リンク )からダウンロードできる各地の気象データを使用して、以下のようなプロットを作成したいと思います。

大阪の2023年3月の1ヶ月分のデータをダウンロードしたものが以下になります。
ダウンロードした時刻:2023/03/30 19:53:27
,大阪,大阪,大阪,大阪,大阪
年月日,平均気温(℃),最高気温(℃),最低気温(℃),降水量の合計(mm),降水量の合計(mm)
,,,,,
,,,,,現象なし情報
2023/3/1,13.1,18.8,6.1,0.5,0
2023/3/2,8.8,13.2,4.9,1.5,0
2023/3/3,7.7,11.6,5.0,0,1
2023/3/4,9.2,16.5,4.1,0,1
- 1行目が時刻、2行目が空行で、3行目に地区名、4行目がヘッダー, 7行目以降が数値データ。
- 「降水量の合計(mm)」列が2つあり、2つ目(6列目)の補足情報は不要。
と、CSVの構造がちょっと複雑です。
2.3. ChatGPTにプロット化を依頼する
(追記)この記事を書いていたときにはまだ出ていなかった、ChatGPT Code interpreter 機能を使用することで、CSVの読み取り作業が非常に簡単になります。下記の記事に詳細を記載しています。
先ほどの気象データCSVを用いて、イメージしたデザイン通りのプロットをChatGPTに依頼しようと思ったのですが、CSVの形式が少々特殊である(不要な行があったり、空行がある)ため、想定していたよりもChatGPTにファイルを正しく読み込ませるのに苦労しました...
プロンプトは以下の通りです。ベースは、前回記事(「ChatGPTと始める」シリーズ第1弾)から流用しています。

コピペ用全文
以下の条件を満たすPythonコードを生成すること。
前提条件:
1. コードにはコメントを記載すること。
2. Python 3.8を使用すること。
3. main 関数を使用すること。
4. 関数の引数を介して必要な変数を渡すことで、グローバル変数の使用を避けること。
5. 行および列番号は、すべて1から始まるインデックスで指示する。Pythonコードに変換する際には、0から始まるインデックスに変換すること。
6. 行および列番号は、CSVファイル上の行、列番号で指示する。Python 上の行、列番号ではないことに注意すること。
機能条件:
1. 以下の構造を持つ CSVファイル(data.csv) を読み込む。
1-1. ファイルの文字コードはShift-JIS である。
1-2. data.csv の 1, 2, 3, 5, 6行目は不要なデータが入っているので、読み込みを行うデータの中に含まれないようにすること。
1-3. data.csv の4行目をテーブルのヘッダー行として設定する。
1-4. 数値データは、data.csv の7行目以降(7, 8, 9, ...)にある。この数値データが、テーブルの中身となるようにする。
1-5. ヘッダー行のサンプルは以下の通り。
`年月日,平均気温(℃),最高気温(℃),最低気温(℃),降水量の合計(mm),降水量の合計(mm)`
1-6. 降水量の合計(mm)が 5, 6列目にあるが、6列目の情報は不要である。削除すること。
2. 機能条件1.で読み込んだデータを以下の形式でプロットする。
2-1. プロットを2つ縦に並べる。
2-2. 1つ目のプロットは、折れ線グラフとし、横軸は年月日、縦軸は平均気温とする。
2-3. 2つ目のプロットは、棒グラフとし、横軸は年月日、縦軸は降水量の合計とする。
機能条件の1.がCSVの読み込みに関する指示で、2.がプロットに関する指示です。1.の指示の方が長くなりました。
正直、CSVファイルを直接編集してもっとシンプルな形にした方が早かったのですが、その対応はエンジニアとして負けかなと頑張ってしまいました...
お読みの皆さんがプロットしてみたいと思っているCSVが、ヘッダーがちゃんと1行目にあるシンプルなものなら、こんな苦労はせずにサクッと終わると思います。
ChatGPTが作ってくれたコードはこちらになります。

# 必要なモジュールのインポート
import pandas as pd
import matplotlib.pyplot as plt
# CSVファイルを読み込み、不要な行や列を削除する関数
def read_csv_file(file_path):
# Shift-JIS形式でCSVファイルを読み込む
df = pd.read_csv(file_path, encoding='shift-jis', header=None, skiprows=[0, 1, 2, 4, 5])
# ヘッダー行を設定
df.columns = df.iloc[0]
df = df.drop(df.index[0])
# 不要な列を削除
df = df.drop(columns=df.columns[5])
# 必要な列のデータ型を変換
df[df.columns[0]] = pd.to_datetime(df[df.columns[0]])
df[df.columns[1:]] = df[df.columns[1:]].astype(float)
return df
# データをプロットする関数
def plot_data(dataframe):
# プロットの設定
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(10, 10), sharex=True)
# 1つ目のプロット(折れ線グラフ)
ax[0].plot(dataframe[dataframe.columns[0]], dataframe[dataframe.columns[1]], label='平均気温')
ax[0].set_ylabel('平均気温(℃)')
ax[0].legend()
# 2つ目のプロット(棒グラフ)
ax[1].bar(dataframe[dataframe.columns[0]], dataframe[dataframe.columns[4]], label='降水量の合計')
ax[1].set_xlabel('年月日')
ax[1].set_ylabel('降水量の合計(mm)')
ax[1].legend()
# プロットの表示
plt.show()
# main関数
def main():
# CSVファイルの読み込み
data = read_csv_file('data.csv')
# データをプロット
plot_data(data)
# プログラムの実行
if __name__ == '__main__':
main()
指示通りの、美しいコードなのがすごいです。
2.4. エラーに対応する
見た感じ間違っていなかったのですが、実行してみると以下のエラーが発生しました。
Exception has occurred: IndexError
index 4 is out of bounds for axis 0 with size 4
File "D:\APItest\chatgpt\csv_plot\plot01.py", line 34, in plot_data
ax[1].bar(dataframe[dataframe.columns[0]], dataframe[dataframe.columns[4]], label='降水量の合計')
File "D:\APItest\chatgpt\csv_plot\plot01.py", line 48, in main
plot_data(data)
File "D:\APItest\chatgpt\csv_plot\plot01.py", line 52, in <module>
main()
ChatGPTにそのままエラー文を投げてみたのですが、珍しくなかなか解決しなかったので、デバッグコードで該当の箇所を覗いたところ
→ dataframe.head()
0 年月日 平均気温(℃) 最高気温(℃) 最低気温(℃)
1 2023-03-01 13.1 18.8 6.1
2 2023-03-02 8.8 13.2 4.9
3 2023-03-03 7.7 11.6 5.0
4 2023-03-04 9.2 16.5 4.1
5 2023-03-05 9.4 14.8 6.5
5, 6列目にあった「降水量の合計(mm)」が両方とも消えています。
6列目だけを消すように指示していて、下記のようにコードでもそう書いているのになんでだろうとよく見てみると、5, 6列目のヘッダー名がどちらも同じ(どちらも「降水量の合計(mm)」)であるために
df = df.drop(columns=df.columns[5])
この操作で、6列目だけを消しているように見えて、5列目も消してしまったようです。
自分で答えはわかったのですが、ChatGPTにできれば自分で気づいてもらいたい...
ChatGPTに「ここが間違っている」とか「ここのデータはこうなっている」とか色々と遠回しに指摘してもなかなか直らなかったのですが、以下のように聞くだけで、自分で解決方法を発見してくれました。
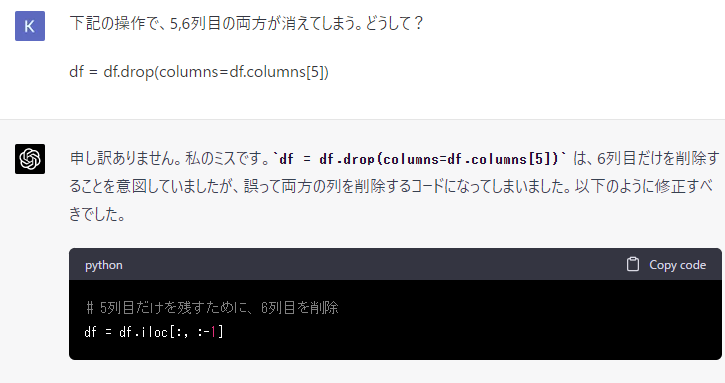
日経の記事 (ChatGPTを賢くする呪文) にあったのですが、「一歩ずつ考えよう」と付け加えると、ChatGPTが賢くなるそうです。直接間違っている箇所を指摘するよりも、「どうして?」と考えることを促した方がよかったのかなと個人的には思っています。
この修正で、以下のようなプロット画像が表示されるようになりました!
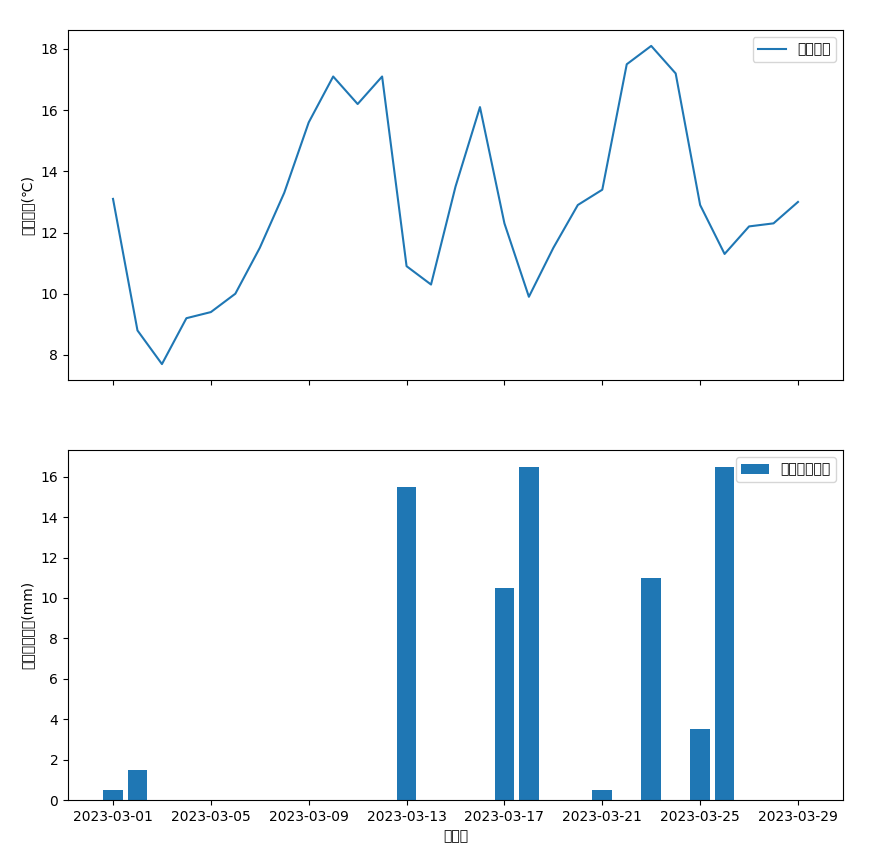
はい、お馴染みの豆腐です。 指示するのを忘れていました。
もちろんマッハで直ります。
コードは折りたたんでいます。
# 必要なモジュールのインポート
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
# CSVファイルを読み込み、不要な行や列を削除する関数
def read_csv_file(file_path):
# Shift-JIS形式でCSVファイルを読み込む
df = pd.read_csv(file_path, encoding='shift-jis', header=None, skiprows=[0, 1, 2, 4, 5])
# ヘッダー行を設定
df.columns = df.iloc[0]
df = df.drop(df.index[0])
# 6列目を削除して、5列目だけを残す
df = df.iloc[:, :-1]
# 必要な列のデータ型を変換
df[df.columns[0]] = pd.to_datetime(df[df.columns[0]])
df[df.columns[1:]] = df[df.columns[1:]].astype(float)
return df
# データをプロットする関数
def plot_data(dataframe):
# 日本語フォントの設定
mpl.rcParams['font.family'] = 'MS Gothic'
# プロットの設定
fig, ax = plt.subplots(nrows=2, ncols=1, figsize=(10, 10), sharex=True)
# 1つ目のプロット(折れ線グラフ)
ax[0].plot(dataframe[dataframe.columns[0]], dataframe[dataframe.columns[1]], label='平均気温')
ax[0].set_ylabel('平均気温(℃)')
ax[0].legend()
# 2つ目のプロット(棒グラフ)
ax[1].bar(dataframe[dataframe.columns[0]], dataframe[dataframe.columns[4]], label='降水量の合計')
ax[1].set_xlabel('年月日')
ax[1].set_ylabel('降水量の合計(mm)')
ax[1].legend()
# プロットの表示
plt.show()
# main関数
def main():
# CSVファイルの読み込み
data = read_csv_file('data.csv')
# データをプロット
plot_data(data)
# プログラムの実行
if __name__ == '__main__':
main()
これで完成しました!

3. Plotly 化する
matplotlib を使ったプロットコードが完成したので、今度は使用するライブラリを Plotly に変換してもらいます。
# 必要なモジュールのインポート
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
# CSVファイルを読み込み、不要な行や列を削除する関数
def read_csv_file(file_path):
# Shift-JIS形式でCSVファイルを読み込む
df = pd.read_csv(file_path, encoding='shift-jis', header=None, skiprows=[0, 1, 2, 4, 5])
# ヘッダー行を設定
df.columns = df.iloc[0]
df = df.drop(df.index[0])
# 6列目を削除して、5列目だけを残す
df = df.iloc[:, :-1]
# 必要な列のデータ型を変換
df[df.columns[0]] = pd.to_datetime(df[df.columns[0]])
df[df.columns[1:]] = df[df.columns[1:]].astype(float)
return df
# データをプロットする関数
def plot_data(dataframe):
# サブプロットの設定
fig = make_subplots(rows=2, cols=1, shared_xaxes=True, vertical_spacing=0.1)
# 1つ目のプロット(折れ線グラフ)
fig.add_trace(go.Scatter(x=dataframe[dataframe.columns[0]], y=dataframe[dataframe.columns[1]], mode='lines', name='平均気温'), row=1, col=1)
# 2つ目のプロット(棒グラフ)
fig.add_trace(go.Bar(x=dataframe[dataframe.columns[0]], y=dataframe[dataframe.columns[4]], name='降水量の合計'), row=2, col=1)
# プロットの軸ラベルの設定
fig.update_xaxes(title_text='年月日', row=2, col=1)
fig.update_yaxes(title_text='平均気温(℃)', row=1, col=1)
fig.update_yaxes(title_text='降水量の合計(mm)', row=2, col=1)
# プロットの表示
fig.show()
# main関数
def main():
# CSVファイルの読み込み
data = read_csv_file('data.csv')
# データをプロット
plot_data(data)
# プログラムの実行
if __name__ == '__main__':
main()
こちらは脅威の1発エラーなしで、以下のような Plotly 版に変換することができました。
Plotly を使ってできた画像を HTML に埋め込むことで、こんな感じに、ブラウザ上でプロットをぐりぐりできます。
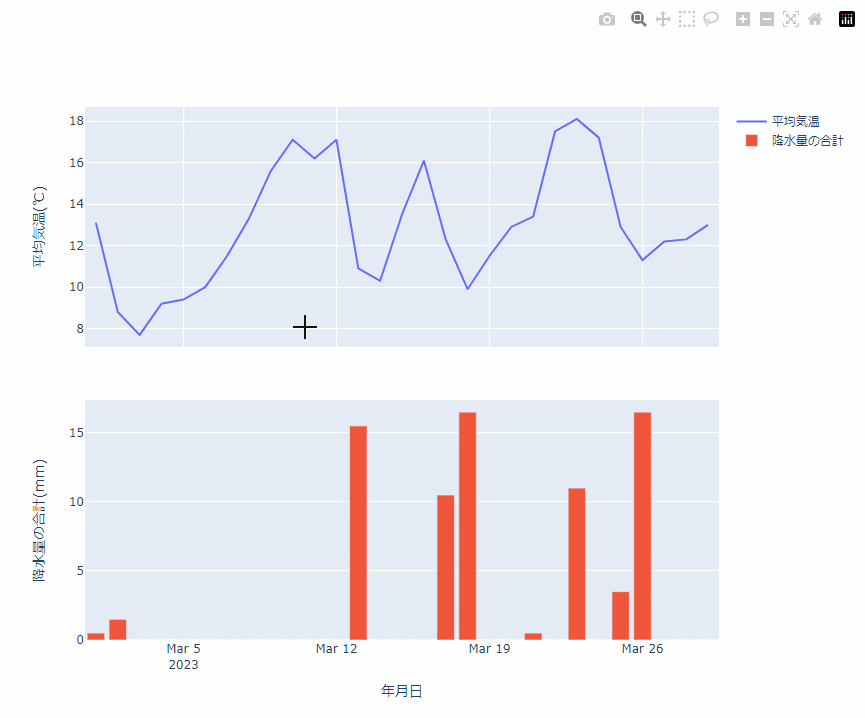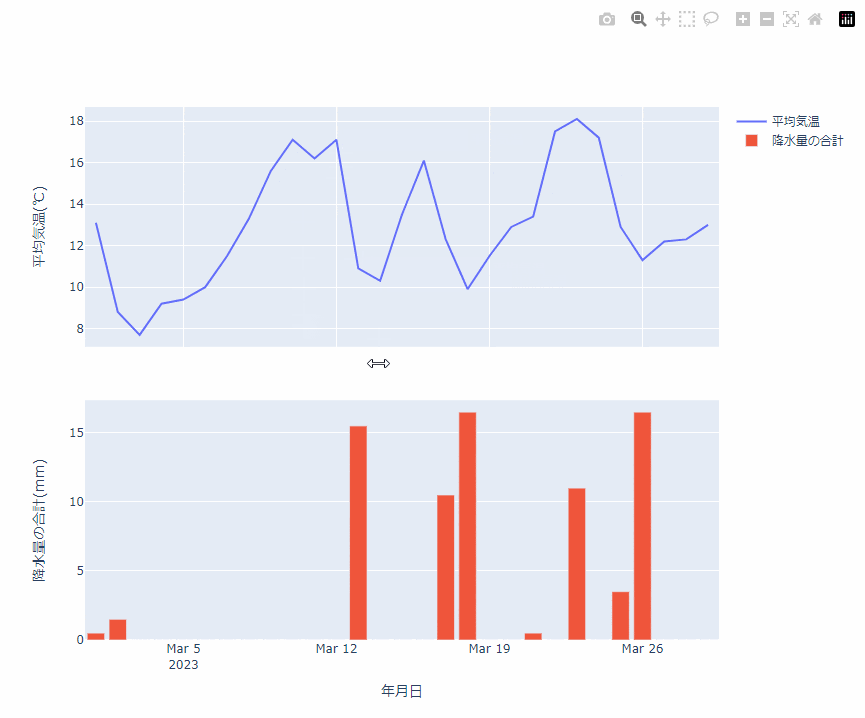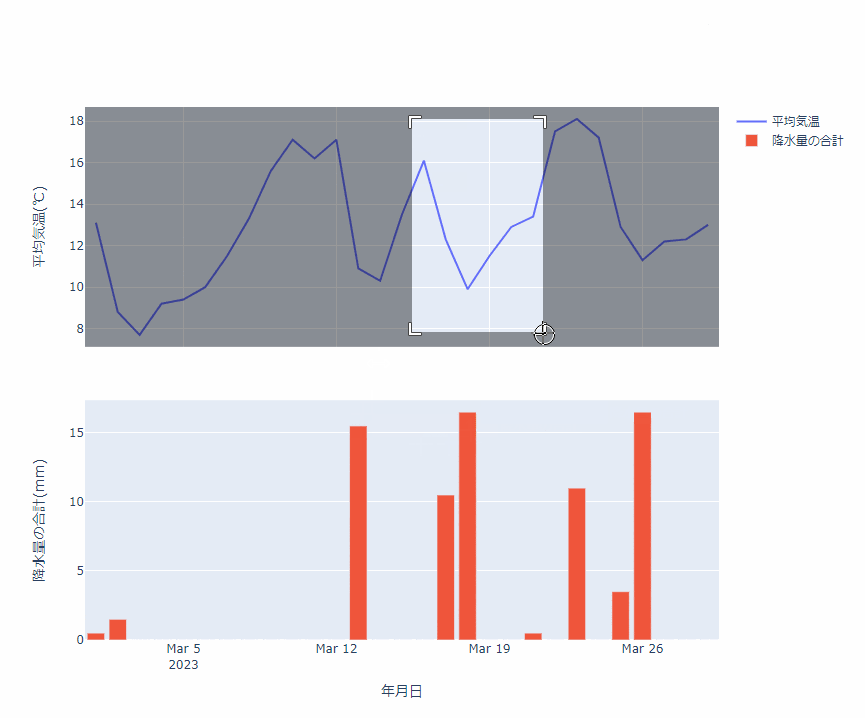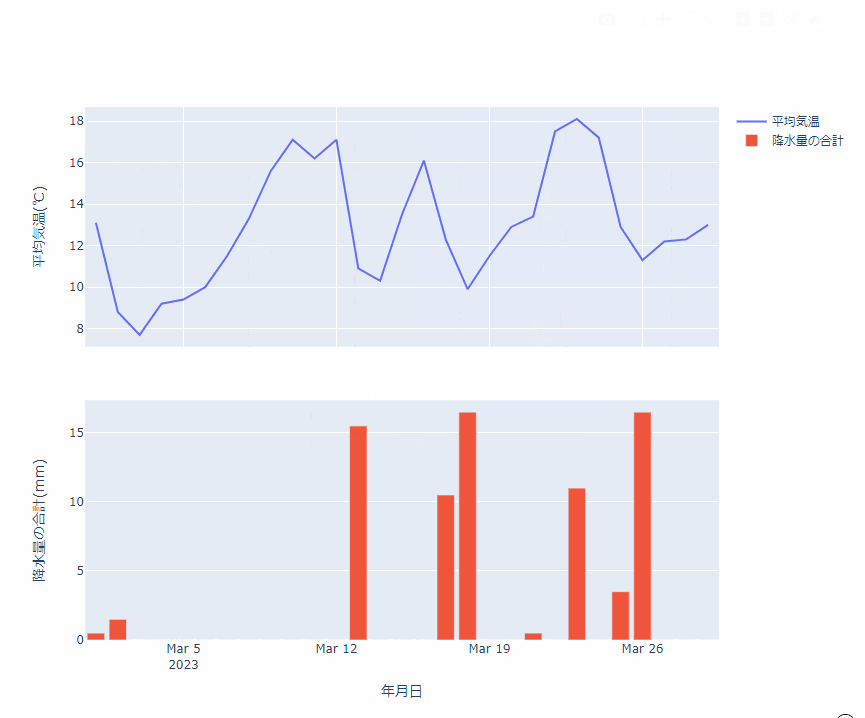
これまで matplotlibで書いたプロットを、あとから Plotly にすればよかったと後悔することが何回かあったのですが、変換に関してはほんと一瞬ですね。
4. Streamlit で Webアプリ化する
ここからさらに、自分が使うだけではなく、同じチームや職場の人に使ってもらうために、Webアプリ化を行います。
PythonでのWebアプリ化のためのツールはいくつかあるのですが、今回は HTMLやJavascript の知識が不要な Streamlit を使用しました。
ついでに、Webアプリとして使いやすくするために、CSVファイルをアップロードするためのウィジェットの設置もお願いします。
# 必要なモジュールのインポート
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import streamlit as st
# CSVファイルを読み込み、不要な行や列を削除する関数
def read_csv_file(file_path):
df = pd.read_csv(file_path, encoding='shift-jis', header=None, skiprows=[0, 1, 2, 4, 5])
df.columns = df.iloc[0]
df = df.drop(df.index[0])
df = df.iloc[:, :-1]
df[df.columns[0]] = pd.to_datetime(df[df.columns[0]])
df[df.columns[1:]] = df[df.columns[1:]].astype(float)
return df
# データをプロットする関数
def plot_data(dataframe):
fig = make_subplots(rows=2, cols=1, shared_xaxes=True, vertical_spacing=0.1)
fig.add_trace(go.Scatter(x=dataframe[dataframe.columns[0]], y=dataframe[dataframe.columns[1]], mode='lines', name='平均気温'), row=1, col=1)
fig.add_trace(go.Bar(x=dataframe[dataframe.columns[0]], y=dataframe[dataframe.columns[4]], name='降水量の合計'), row=2, col=1)
fig.update_xaxes(title_text='年月日', row=2, col=1)
fig.update_yaxes(title_text='平均気温(℃)', row=1, col=1)
fig.update_yaxes(title_text='降水量の合計(mm)', row=2, col=1)
return fig
# Streamlitアプリの作成
st.set_page_config(page_title="CSVファイルプロット", layout="wide")
st.title("CSVファイルプロット")
# サイドバーにCSVファイルアップロードウィジェットを追加
uploaded_file = st.sidebar.file_uploader("CSVファイルをアップロードしてください", type=["csv"])
# CSVファイルがアップロードされたら処理を実行
if uploaded_file is not None:
data = read_csv_file(uploaded_file)
fig = plot_data(data)
st.plotly_chart(fig)
else:
st.warning("CSVファイルをアップロードしてください。")
これも、エラー出ずの一発出力でした。
実行するときは以下のコマンドになります。ローカルからアクセスするときは,ブラウザの http://localhost:8501 を開いてください。
$ streamlit run app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://(自分のPCのIP):8501
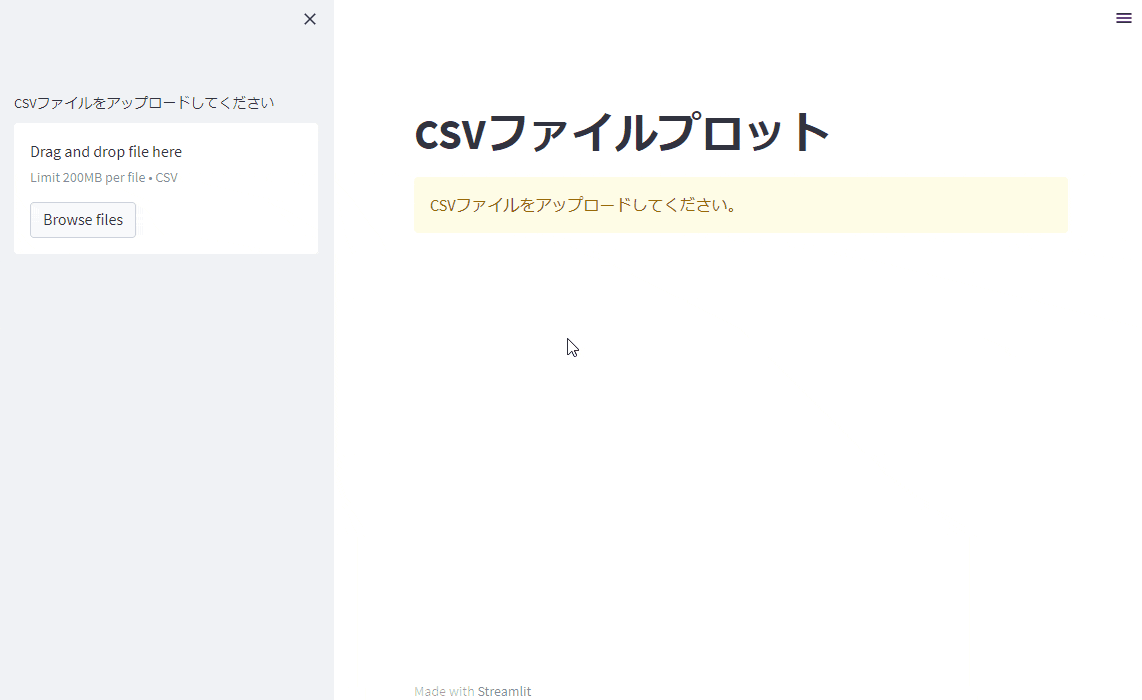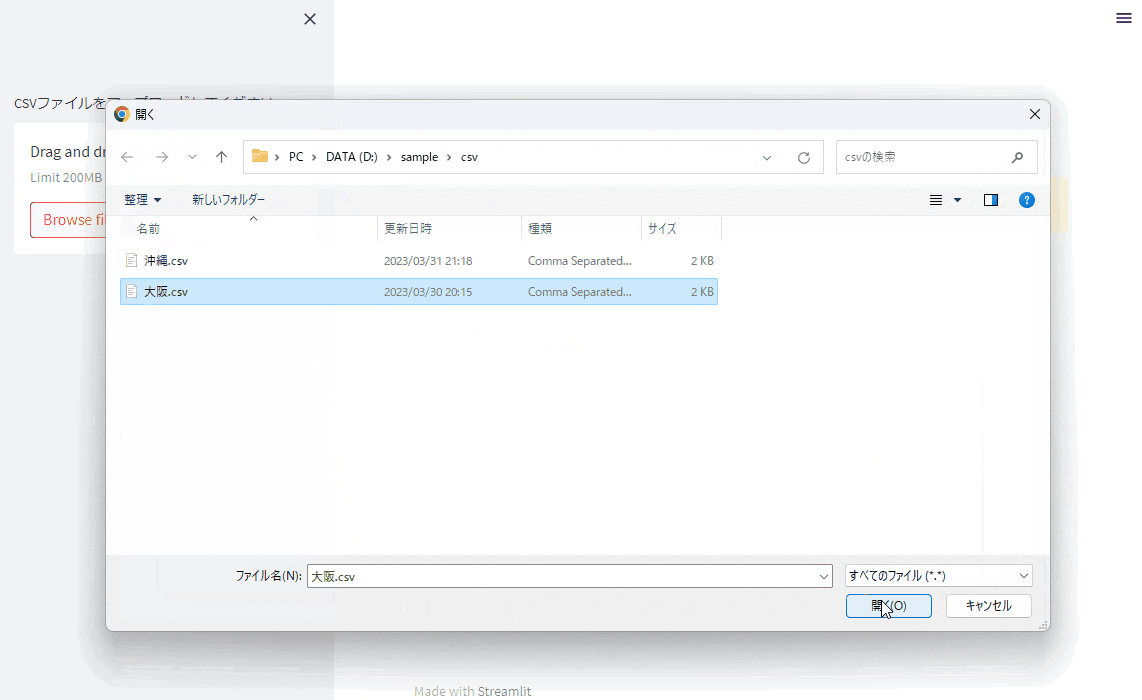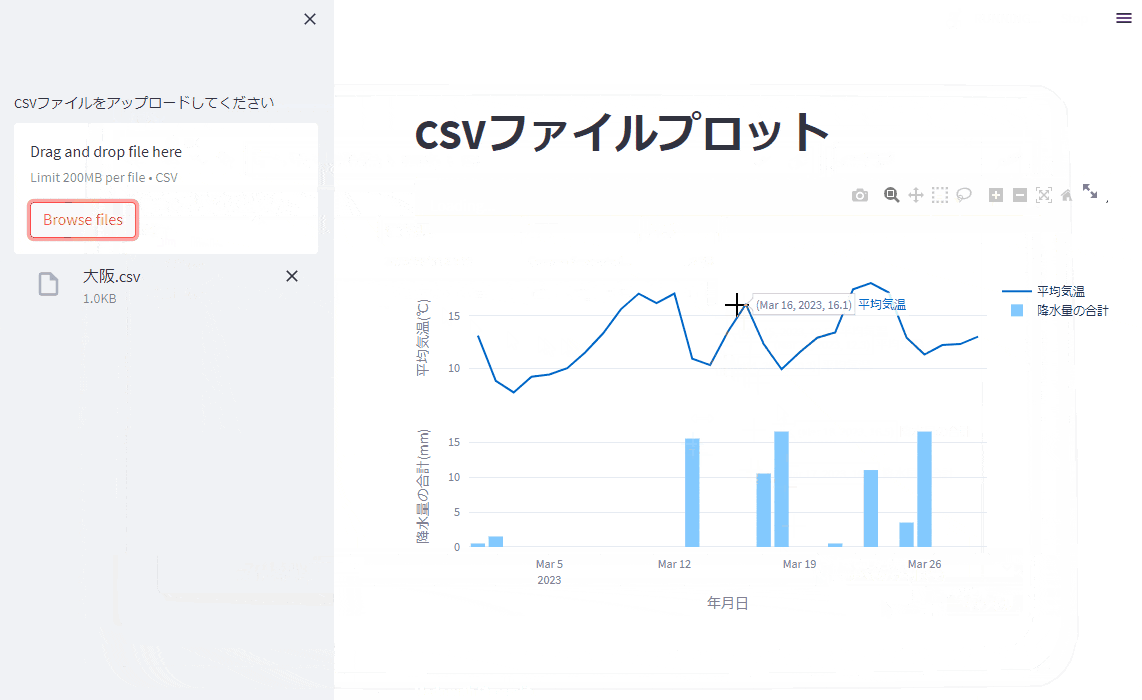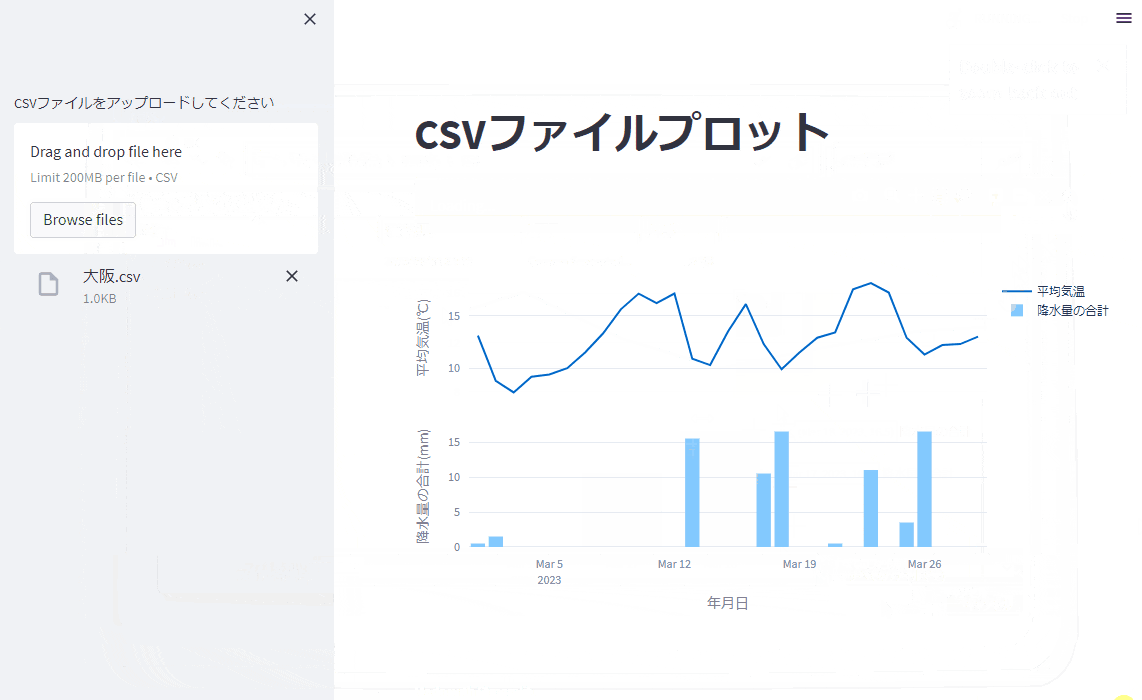
ちゃんと指示通りに、ファイルのアップロードボタンが追加されていて、アップロードしたファイルからプロットされるようになりました!
(プロットがちょっと小さいですが、まぁ指示すればすぐに直るので、いいでしょう。)
今回 前半あたりのpandasでCSVデータを読み込むところが一番苦戦しました。
ChatGPTにも苦手なことがあるのかとむしろ驚いたのですが、それ以外は、いつも通りの爆速でした。
5. おわりに
「仕事がなくなっちゃう」と頭を抱えることはもうあまりなくなって、ChatGPTとこれから協力していく時代が来るんだ!と、最近はChatGPTにどうお願いすれば何をしてくれるのか、その反応を見るのがすごく楽しいです。
ただ立ち止まって振り返ると、のんびりと、プログラムの本を抱えながら、Google先生と相談してエラー文とにらめっこする、あの時間はもう戻ってこないんだなと、
しみじみと感じながら時代の移り変わりを楽しんでいます。
いつも記事が長くなってしまい、反省はしているのですが、どこかが誰かのヒントになるかもしれないと思って全部書きたくなってしまい...すみません。お役に立てば幸いです。
6. 関連記事
本記事の続編です。Code interpreter 機能を使うことで、CSVの読み取りコードの生成が爆速でできるようになりました。
「ChatGPTと始める」シリーズ第3弾はこちらです。
第4弾はこちら