概要
この度、自分だけで使う小規模な書籍自炊システムを作った。
振り返ってみると業務でのシステム開発に通じる要素がちらほらあった。
初心者や未経験者、大学生など、システム開発に関してまだそれほど明るくない方に向けて勘どころをまとめる。
また、顧客向けサービスや社内システム、受託開発、自社開発などを区別せず広い意味でシステム開発を取り上げる。
IT関連の仕事に興味があるががなんとなく実態が掴めない、具体的な業務内容がピンとこない、という方が解像度を上げる助けになれば幸いである。
目次
設計
要件がある程度わかってくると仕様を作ることができる。
今回は前の記事の終わりに書いた要件をそのまま基本仕様として扱う。
- 書籍
- A4(見開きA3)以下
- 縦書き(右綴じ)、横書き(左綴じ)の両方に対応する。
- 日本語と英語
- カラー、モノクロ
- PDF
- 基本的に書籍の仕様をそのままPDFに適用する。
- 書籍の大きさはPDFの大きさと一致しなくてもOK
- 例えばA5の書籍でもA4のPDFを出力可能とする。
- 1ファイルにつき200MB以下を目標とする。
- カラーはカラー、モノクロはモノクロのPDFを出力する。
- ロックや署名は不要
- 注釈や書き込みは必要
- OCRは必要
- 表紙、裏表紙を含める
- スキャン
- 1人で作業できるものとする。
- 基本的にカメラとiPadを有線接続してスキャンする。
- 例外としてスマートフォン単体でもスキャン可能とする。
- 作業環境は100cm*60cm程度の机を使う。
- クラウド(保存と閲覧)
- 自分だけアクセスできればOK、逆に他人はアクセス不可とする。
- windows, mac, iPhone, iPad等でアクセス可能とする。
- 実際にはwebブラウザやスマートフォンのアプリケーションでアクセスする。
- どの端末からでもPDFを更新(注釈や書き込み)可能とする。
- ファイルの履歴管理は不要。
基本設計とその他設計資料
実際の業務ではもう少し詳細なものを基本設計とすることが多い。
例えば要件としては「csvファイルを読み込んでDBに登録する」となっているのを、設計ではcsvの項目やそれに対応するDBの項目を決める必要がある。
また、「csvファイルを読み込んでDBに登録すること」を基本設計として、csvやDBの項目は詳細設計とする場合もある。
このあたりの切り分けはプロジェクトの規模や複雑度によって異なる。
設計工程を進めていくと沢山の資料が出来上がっていくが、人が見渡せる範囲には限界がある。
そのため「資料が増えてきたな、これは整理したほうがいいかも」というタイミングがどこかで発生する。
このときに基本設計と詳細設計、その他必要な設計資料に分けられていくイメージである。
多くのプロジェクトでは基本設計書や詳細設計書、エンティティ定義書などがよくある資料として作成される。
ただし、最初から「このプロジェクトでは基本設計書、詳細設計書、〇〇設計書を作ります」と決めることはほとんどない。
大体がPMやSEが一定のところまで資料を作成して、どこかの打合せで「それではこれを基本設計書ってことにして、〇〇さん詳細設計をお願いします」というように進むことが多い。
技術選定
要件定義の中盤から設計工程にかけて技術選定を行う必要がある。
何を使ってそのシステムを作るかを決めることと考えてもらえば問題ない。
プログラミング言語やデータベース、その他ツールなどを選定する。
今回の書籍自炊システムは比較的特殊なことをやっており、コーディングやDB構築は発生しない。
プロジェクトの作業としてはほとんどがこの技術選定、特にスキャン用アプリケーション探しだった。
今回の仕様には以下のようにモノと仕組みそれぞれの仕様が含まれている。
このうち、技術選定が必要なのは仕組みにあたる部分。
- 書籍(モノ)
- PDF(モノ)
- スキャン(仕組み)
- クラウド(仕組み)
最終的に今回使うものを以下のようにした。
- スキャン(撮影、OCR、PDF出力)
- 必須
- iPhone
- vFlat scan(スキャンアプリケーション)
- スキャン品質、作業効率向上のため
- iPad
- デジタル一眼カメラ
- 三脚
- ライト
- 机
- 必須
- クラウド(保存、閲覧)
- 必須
- Googleドライブ
- 閲覧品質、運用効率向上のため
- GoogleWorkspace
- PDF Viewer(閲覧アプリケーション)
- PDF Pro(閲覧アプリケーション)
- 必須
その他の技術選定例
もしもWEBアプリケーションを作る場合は例として次のような技術選定になる。
- フロントエンド
- typescript
- ライブラリ1, ライブラリ2、ほか
- バックエンド
- python
- ライブラリ1, ライブラリ2、ほか
- データベース
- postgresql
- インフラ、ストレージ
- AWS EC2, S3
選定基準
まず、選定基準には仕様を実現できるかどうかが挙げられる。
また、コストや開発/保守運用のしやすさ、その技術に対する開発チームの習熟度、などが挙げられる。
例えば今回はコストを重視して既に自分が持っている機材を優先して採用した。
新しく取り入れた(コストが掛かった)ものはvFlat scanというアプリケーションのみである。
また、保守運用のしやすさという観点で、基本的にiPadとカメラを使ってスキャン作業をするものとした。
というのも、スキャン中やその後のPDF出力など様々な要因で端末が長時間拘束されるのである。
それに対してiPhoneは日常生活で使っているため、電話機能やその他用途のために端末をなるべく空けておきたい。
このような 実際に使ってみたら…… という内容は後のプロトタイピングで触れることにする。
技術選定やプロトタイピングは並行して進むことが多い。
良いシステム
良いシステムとはどんなものか。
売上やコスト削減など金銭的なメリットや、業務効率が上がるなどいろいろな要素があるだろう。
個人的にはユーザーに気に入られてよく使われることも1つの要素だと考えている、先ほど例に挙げた「運用しやすいからiPadとカメラを使うことにした」というのもここに関わってくる。
システム開発の話題からは少しそれるが、金銭的なメリットや業務効率を一番求めているのはそのシステムを導入した側のことがままある。
導入されたユーザー側(作業者やお客さん)は別に売上を上げたい訳では無いし、今の業務効率で特別困っていないこともある。
むしろユーザーが嬉しいのは前よりも使いやすい、便利だと感じるシステムである。
想定通りに使われれば大きなメリットがあるが、そもそも使われないというのは広い意味で失敗したシステムと言えるだろう。
調べ物をするときに……
もし自分が初めて触れる領域の技術を探す場合、どのようにするのがよいか。
ウェブを検索するか、いまならばAIに聞いてみるのもよいだろう。
AIは残念ながら厳密なことを聞くとよく嘘を付くが、自分が何も知らない領域について最初の知識を得るときには役に立つ。
検索にしろ、AIにしろ調べ物を始めるときに非常に大切なことがある、調査対象に関連する言葉を自分が知っていなければいけないのだ。
例えば今回のプロジェクトでいえば自炊やOCRという言葉がよく出てくる。
それぞれの言葉を簡単に説明すると次のようになる。
-
自炊
紙の書籍を何らかの方法で電子書籍としてデータ化すること。 -
OCR
Optical Character Recognitionの略であり、日本語では光学文字認識と訳される。画像上の文字をコンピュータに認識させて文字データ化すること。
ウェブを検索するときに上記のような文章で検索するのは少し難しい。
AIであればもしかするとこちらの意図を汲み取って何か有益な情報を答えてくれるかもしれない。
しかし、やはり自分が最初からその言葉を知っていれば調査効率が段違いなのである。
個人的な調べ方
このような言葉を知っていることに関連して、私がまったく知らないモノや概念に対してよくやる調査の手法は次のようなものだ。
まず、そのときの自分の知識でざっと調査対象を調べる。
このときに検索かAIかは問わない、内容の正確さも良し悪しも問わない。
すると、調べた中に同じ言葉が偏って出てくるのである。
(ひょっとするとこの時点でそれらの言葉が自分の知識と関連することが分かるかもしれない)
次にそれらの言葉を調査ワードに混ぜ込んで検索やAIを使う。
これらを繰り返していくと、あるタイミングで自分が最初に調べたかったものに辿り着く場合が多い。
慣れてくると全く知らないことでも(なんとなくあの辺の領域に答えがありそうだなあ)と勘が効いてくる。
勝手ながら、エンジニアの仕事の半分以上は調べ物をしている印象がある。
言葉をよく知っていたり調べ物が上手い人がいたら、それだけである意味エンジニアに向いていると言える。
プロトタイピング
設計や技術選定の最中に、使い勝手や本当にその設計で動作するのかを確認したいことがある。
そのためにちょっとしたコーディングをしたりサンプルを作ったりすることをプロトタイピングという。
今回の書籍自炊システムでは次のように段階的にプロトタイピングを進めた。
- スキャン
- 手持ちでiPhoneを持って書籍をスキャンする。
- 三脚にiPhoneをつけて書籍をスキャンする。
- 三脚にカメラをつけてiPhoneに画像転送しながらスキャンする。
- 三脚にカメラをつけてiPadに画像転送しながらスキャンする。
- 閲覧
- windowsでGoogleドライブに接続してPDFを閲覧する。
- windowsでAdobeAcrobatを使ってPDFを閲覧する。
- macでGoogleドライブに接続してPDFを閲覧する。
- macで標準PDFビュワーを使ってPDFを閲覧する。
- macで
PDF Viewer(閲覧アプリケーション)を使ってPDFを閲覧する。 - iPadでGoogleドライブに接続してPDFを閲覧する。
- iPadで
PDF Viewer(閲覧アプリケーション)を使ってPDFを閲覧する。
結果としては次の2つを基本の運用と想定して設計を進めた。
- スキャン4. 三脚にカメラをつけてiPadに画像転送しながらスキャンする。
- 閲覧5. macで
PDF Viewer(閲覧アプリケーション)を使ってPDFを閲覧する。
一般的にこのときに作成されたものをプロトタイプやサンプル、試作品と呼ぶ。
開発チームだけで気になる点を確認する場合もあれば、プロトタイプをユーザーに見せて反応をもらう場合もある。
実際の流れ
今回のプロジェクトを振り返って、業務でのシステム開発に置き換えるなら最初は「スキャン2. 三脚にiPhoneをつけて書籍をスキャンする。」をプロトタイプとしてユーザーに見せてレビューを貰うだろう。
閲覧に関しては手段だけ整えてユーザーが好きなように確認してもらう。
以下はスキャンのプロトタイプについて実際にやったことや出てきた課題である。
1. 手持ちでiPhoneを持って書籍をスキャンする。
スキャン1はどちらかというと開発チーム向けのプロトタイプである。
vFlat scanで実際に「スキャン → OCR → PDF出力」が出来るかを確認するだけのもので、ユーザーに見せられる段階ではない。
2. 三脚にiPhoneをつけて書籍をスキャンする。
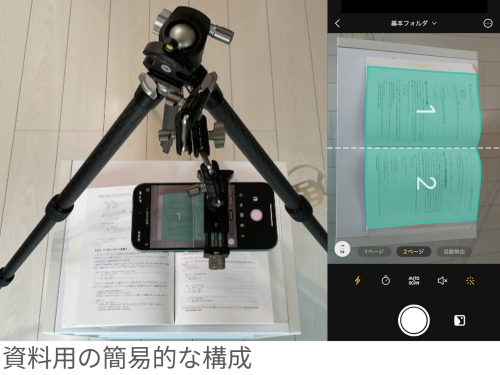
スキャン2の段階で、いわゆるそれっぽいプロトタイプになってくる。
三脚で固定しているためスキャン品質が均一でPDFの品質も確認しやすい、運用イメージを掴むには十分と判断できる。
スキャン1では書籍を2-3ページだけスキャンしたのに対して、スキャン2では100ページほどスキャンしてユーザー目線でPDFを確認した。
この段階のプロトタイプで分かったのは要件はすべて達成していて運用自体は十分可能であるということだ。
しかし、PDFの品質に若干問題があった。文字の大きさや背景色によって同じページの中で鮮明度に差があったのだ。
言ってみれば、要件は達成しているが、ユーザーが期待していた品質には足りていないという状態である。
3. 三脚にカメラをつけてiPhoneに画像転送しながらスキャンする。

スキャン品質を向上するためにiPhoneではなく、デジタル一眼カメラを使うことにした。
幸運なことに個人的に写真趣味があったため既に良いカメラを持っていたのと、vFlat scanがiPhoneの写真ライブラリからのインポートに対応していた。
カメラで撮影した写真をiPhoneの写真ライブラリに保存して、これをvFlat scanにインポートしてやればよい。
プログラミング的な例え話をすると、その言語の標準機能では不足する要素があったので外部ライブラリを導入したという感じである。
実際のスキャン品質を比較すると以下のようになる。

vFlat scanは普通は端末の標準カメラを使うが、この場合は画角や明るさ、解像度など撮影に関わるパラメータに制限がある。
それに対してデジタル一眼カメラを使えばカメラ側の設定で様々な撮影に対応できるため非常に使いやすいことが分かった。
実際のプログラミングでも問題を解決するために機能や役割を分割するのは1つの手である。
今回はカメラに撮影、vFlat scanに補正やOCRなどを任せている。
このプロトタイプで見つかった課題が次の3つである。
- 画像ファイルの大容量化による処理速度の低下(トレードオフ)
- スキャン作業中に端末が長時間拘束される
- カメラで撮影された画像が横向きのため
vFlat scanでも横向きにインポートされる
このうち1, 2はより性能の高いiPadを採用することで解決した(スキャン4)。
また、3はiOS等に搭載されているショートカットでスクリプトを組んで画像を自動回転することにした、これに関しては次の実装の記事で触れることにする。
トレードオフ
選択肢が複数あるとき、Aには良い点と悪い点がある、Bにも良い点と悪い点がある、どちらかを選ぶのは難しいという状態。
どの選択肢を選んでもベストではないし、すべての条件を満たすのは難しいことを指す言葉。
例えば製品の品質を上げればコストが掛かる、コストを下げれば品質が下がるような状態をトレードオフという。
今回でいえばスキャン品質を上げれば処理速度が下がる、処理速度を上げるにはスキャン品質を下げなければいけないという状態を指す。
システム開発ではこのようなトレードオフの状態がよく発生する。
このような状態を解決するために選択肢ごとのサンプルを作ってユーザーに判断を仰ぐこともよく行われる。
設計の要点
業務でのシステム開発ではこのようなやり取りが非常に重要である。
要件定義を受けて開発チームが設計や技術選定、プロトタイピングを進める。
一定の段階でユーザーからレビューを貰えば方向性が正しいことを確認できたり、求められているものがより鮮明に見えてくる。
開発チームがその設計で問題ないと思っていても、ユーザーから思いがけない指摘が入ることはよくあることだ。
今回もスキャン2のプロトタイプではユーザー目線で、スキャン3のプロトタイプでは開発目線で課題を見つけることができた。
プロトタイピングでちょっとした実装は進んでいるが、まだまだ修正可能な状態である。
本格的な実装が進んでいくと小さな修正でも困難なことがある。
要件定義ではユーザーがやりたいことを明確化して、設計工程ではお互いの認識が正しいか目に見える形で確認する。
中でもサンプルやプロトタイプにはとても大きな役割がある。
今回は実際の作業イメージを作って課題を確認した。
他のシステムでも入出力ファイルのサンプルや、画面があるシステムであれば簡単なクリック動作などを再現したプロトタイプが考えられる。
これらのやり取りから作られる〇〇設計書をもって次の実装工程に進んでいくこととなる。
まとめ
今回の記事では設計工程、特に技術選定やプロトタイピングについて詳しく取り上げた。
設計という割には設計書に関する説明が少なくなってしまったが、設計書の書き方はプロジェクトによってかなり異なってくる。
そのため実際の書き方はそのプロジェクトの既存資料や、手に入るのであれば他プロジェクトの資料を参考にするのがよいだろう。
ただし、設計の本質として「これから作るものを目に見える形(設計書やサンプル)でユーザーと開発チームが確認する」というのは変わらない。
次の記事では実装工程として、コーディングなどいわゆるプログラミング的な部分について取り上げることにする。