機械学習とは
機械学習は、データを利用して学習するプログラミング科学である。
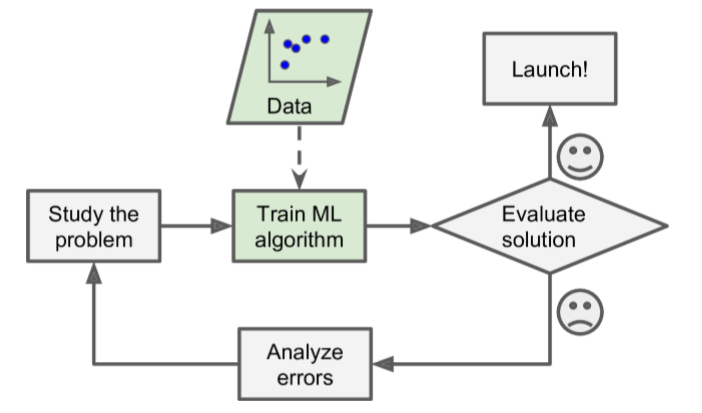
機械学習の流れ
機械学習の種類
1.人の介入有無によって分類###
①教師あり学習####
主なタスク
• 分類
• 回帰
アルゴリズム
• k-Nearest Neighbors
• Linear Regression
• Logistic Regression
• Support Vector Machines (SVMs)
• Decision Trees and Random Forests
• Neural networks
②教師なし学習####
主なタスク
• クラスタリング
• 可視化
• 次元削減
• 異常検知
• 相関ルール学習
アルゴリズム
• Clustering
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
• Anomaly detection and novelty detection
- One-class SVM
- Isolation Forest
• Visualization and dimensionality reduction —Principal Component Analysis (PCA)
- Kernel PCA
- Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
• Association rule learning
- Apriori
- Ecla
③半教師あり学習####
④強化学習####
2.システム稼働中の学習有無によって分類###
①バッチ学習####
• 全量データが必要、時間・計算資源かかる
②オンライン学習####
• 増分データ対応可能、時間・計算資源かからない
3.一般化の手法よって分類###
①Instance-based learning####
例えば、k-Nearest Neighbors
②Model-based learning
例えば、Linear Regression
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# データの準備
country_stats = pd.read_csv("xxx.csv",thousands=',',delimiter='\t',
encoding='latin1', na_values="n/a")
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# データ可視化(非必須)
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# モデルの指定(ここだけ変更すれば、他モデルに切替可能)
model = sklearn.linear_model.LinearRegression()
# モデルの訓練
model.fit(X, y)
# 訓練済みのモデルを利用して、新しい入力値に対して結果を推測する
X_new = [[22587]] # 推測対象の入力値
print(model.predict(X_new)) # 推測値の出力
機械学習のポイント
• アルゴリズム ⇒ 適切
• データ ⇒ 高質で代表的なデータの量が十分であること
データ量が少ない場合、サンプリングノイズが発生する。
データ量が多い場合でも、サンプリング方法が不適切な場合、サンプリングバイアスが発生する。
【原文】
It is crucial to use a training set that is representative of the cases you want to generalize to. This is often harder than it sounds: if the sample is too small, you will have
sampling noise (i.e., nonrepresentative data as a result of chance), but even very large
samples can be nonrepresentative if the sampling method is flawed. This is called
sampling bias
データの品質が低い場合の対処
•インスタンスが極端値の場合の選択肢
- 当インスタンスを採用しない
- 手動で極端値を直す
•インスタンスに特徴属性のデータが記入されない場合の選択肢
- 当属性を採用しない
- 当インスタンスを採用しない
- 当属性にデータを(平均値など)補足する
- 当属性を含む、含まないモデルをそれぞれ訓練する
過学習
モデルが訓練データに対してうまく学習されているが、未知データに対しては適合(汎化)できていない状態である。
【対処】
①訓練データの特徴を減少することで、パラメータが少ない、簡単なモデルを利用する
②訓練データをもっと収集する
③訓練データのノイズを減少する
※正則化
モデルを簡単化して、過学習のリスクを軽減する。
未学習
モデルが訓練データにもテストデータにも適合していない、全然ダメな状態である。
【対処】
①もっとパラメーターが多い、強いモデルを利用する
②特徴エンジニアリング
③モデルの制限を減少する (例えば、正則化のハイパーパラメータを減少する)
ハイパーパラメータ
(モデルのではなく)学習アルゴリズムのパラメーター(事前設定の常数)の一つである。正則化のハイパーパラメータに非常に大きい値を設定した場合、モデルが平坦(傾きが0に近い)になる。学習アルゴリズムがほぼ過学習にならないが、良いソリューションでもない。ハイパーパラメータの最適化は、機械学習システムの構築に重要な部分である。
Hold-out法と交差検証
一般的に、データの80%を訓練データにして、残り20%をテストデータにする。
ただし、データの母数が非常に多い(例えば、1憶件)場合は、1%(10万件)でも十分である。
モデルの選択
データセットに対して一番良いモデルがどれか分からないので、複数のモデルを作って計算してみる必要がある。
ただし、簡単タスクの場合は線形回帰を利用し、複雑の場合はニューラルネットワークを利用することが考えられる。