この記事はAWSアドベントカレンダー21日目の記事です。担当はkeroxpでお送りします。
弊社(ロイロ)で開発中のECSへの堅牢なデプロイツールの紹介をしようと思います。
概要
弊社はもともと、AWS EC2でメインのWebサービスを運用していたのですが、今年の中頃から本格的にDockerへの移行を始めました。EC2からDockerへの移行も相当に大変だったんですが、それはなんとかうまく行ってさぁAWSにデプロイだ!というところで大変なつまづきを経験し、その解決策を模索し始めました。
この記事はAWSでECSに「堅牢に」Dockerコンテナをデプロイしたい開発者向けの記事です。
Kubernetesを使ってる人たちには需要無だと思います。
ECSへのデプロイの問題点
AWSを使っている場合、コンテナベースのアプリケーションをデプロイする先としてECSを選択するのは自然な流れだと思います。しかし、ECSへのコンテナのデプロイは控えめに言って安全ではありません。
ECSでWebアプリケーションを運用する場合、Serviceを作成することになりますが。Serviceに対するデプロイは、Serviceを構成するタスクを新しいタスク定義(≒Dockerイメージ)で作成されたタスクで置き換えることで実行されます。
これはいわゆるローリングアップデートというタイプのデプロイで、新旧タスクを順番に置き換えてくれるのでダウンタイムも出ない(はず)なので一見便利に思えます。
しかしECSのこのナイーブなデプロイ方法は、様々な問題を抱えています。中でも壊れたタスクを配置してしまった場合、サービスが落ちる可能性があるという点が一番問題です。
この部分の説明が難しいというか、何を持って「壊れている」かがECSの複雑なシステムによってとにかくわかりにくく、サービスが「壊れている」状態もECSは明示的に示してくれないんですよね。なので、ECS導入初期は「知らないうちに落ちてた」ことが多発しました。**もちろん、開発やステージング環境の話ですヨ。**そこで躓いたのでcageの開発を決意したというわけです。
壊れたものをデプロイしたのだからサービスが落ちるのは当然なのですが、そもそもローカルで動いていてCIも通っているのだからデプロイできないわけがないと考えるのが普通です。
デプロイという作業が、デプロイ職人が二人体制で目を皿にしながら行う月に一度の一大行事というような世界観ならいざしらず、せっかくアプリケーションがコンテナという堅牢な箱を手に入れたのだから、デプロイのサイクルもはやめていきたい。でもデプロイはできるだけ安全に行いたい。
そういった動機からECSへのデプロイツールを自作することを決めました。
つい最近CodeDeploy経由でのECSへのB/Gデプロイメントが発表され、実際に使ってみましたが、実用に足るがまだ癖があると感じました。今からでしたらそちらを検討してみてもいいかもしれません。(ちなみにCodeDeployがやっているTargetGroupを2つ用意してB/Gデプロイするという手法はcageの開発初期に実装していたのですが、動いているECSサービスのTargetGroupを変えることはできず、複数のTargetGroupも割り当てられないので断念したという経緯があります。どうやら謎の特権的な振る舞いをしているようです)
とはいえcageを開発し始めたのは今年(2018年)の8月ころで、その当時はこの機能はなく、CodePipelineからのデプロイもサービス更新するだけだったので、僕たちの用途には合いませんでした。弊社は別のCIサービスを使っているので、その利便性の点でもそちらのサービスから直接堅牢なデプロイを実行できる必要があったのです。
ECSへのデプロイはfragileすぎます。デプロイに相当するアクションが、service-updateでタスク定義を更新することしかないということが一番の問題点で、それはデプロイに相当しているだけで、サービス開発者が思い描くデプロイではないのです。
本来「安全な」デプロイとはアプリケーションによって異なるはずで、ローリングアップデートできるから「安全」なわけはないと思います。ECSはそういった開発側の柔軟なデプロイ方針を適用できないため、「望ましい状態」を定義ファイルで宣言して結局そういう状態にならずにただ止まるということが多々起きます。ECSにはロールバックの機能もないですし。
canarycageの紹介
canarycage(a.k.a cage)は、そういった問題を解決し、ECSへの継続的なデプロイを恐れないためのデプロイツールです。cageを開発する前、僕たちはいくつかのECSへのデプロイツールを調べ、そのどれにも満足できませんでした。AWS公式のecs-cliも、僕たちが求める堅牢さは持っていませんでした。結局自分たちでaws-cilを使ったシェルスクリプトを書いていたのですが、だんだん長大になっていき、シェルスクリプトの限界を突破してしまったのでGoで書き直しました。
僕がcageを開発する上で打ち上げた方針はただ一つ、
デプロイ中に「何か」が壊れていても、現存の動いているサービスに影響を与えない
ことでした。
何ヶ月かのECS運用で僕たちはECSのサービスが壊れるパターンを見つけました。
それは、
- サービス定義に誤りがある
- タスク定義に誤りがある
- タスクが配置されるVPCの設定に誤りがある
- クラスターにタスクを配置できない
- タスクのコンテナの起動が成功しない
- タスクは起動しているが、何らかの原因でALBのヘルスチェックが規定の時間以内に通らない
のようなものでした。いずれもアプリケーションのコードの振る舞いは何も壊れておらず、ECS環境でしか検証できない設定の誤りによるものがほとんどでした。誤ったサービスやタスクの定義をメインサービスに適用してしまったせいでサービスが壊れるのは、理不尽に思える時間でした。
cageは、こういった設定ミスをできる限りメインサービスに適用させないために設計されています。
cageの使い方
go製のCLIなので、goで入れることができます。2018/12/21現在の最新版は、2.1.0です。(※1.x.x系は振る舞いが全く違うので使わないでください)
$ go get -u github.com/loilo-inc/canarycage/cli/cage
バイナリはGithubからダウンロードできます。
$ curl -oL https://github.com/loilo-inc/canarycage/releases/download/${VERSION}/canarycage_${OS}_${ARCH}.zip
$ unzip canarycage_linux_amd64.zip
$ chmod +x cage
$ mv cage /usr/local/bin/cage
cageには今の所2つのコマンドしかありません。それがupとrolloutです。
コマンドの使い方を紹介する前に、cageに必要なファイルを説明します。
service.jsonとtask-definition.json
cageはデプロイメントの記述に二種類のjsonファイルを使用します。それがservice.jsonとtask-definition.jsonの2つのファイルで、それぞれECSサービスの作成、タスク定義の登録に使用します。これらを「デプロイファイル」と呼んでいます。
service.jsonはメインサービスの作成、後述するカナリアサービスの作成に使うサービス定義ファイルです。この内容は、サービス定義パラメータに記述のあるJSONフォーマットになります。
aws ecs create-service --generate-cli-skeletonで生成されるフォーマットと同じものである必要があります。
task-definition.jsonは同様にタスク定義パラメータのJSONフォーマットになります。aws ecs register-task-definition --generate-cli-skeletonのアウトプットですね。
ディレクトリ構成
上記2つのファイルは、一つのサービスにつき同じディレクトリに置いてある必要があります。最もナイーブなディレクトリ構成は、次のようなものになるかと思われます。
cage up
upはその名の通り「サービスを作成する」コマンドです。aws ecs create-serviceに相当し、ほぼ同じ挙動をします。
上記のようなディレクトリ構成にした場合、最もシンプルなupコマンドの使い方は以下のようになります。
$ cage up .deploy/
upコマンドは第一引数にデプロイファイルのディレクトリパスをとり、そのタスク定義を登録し、それを用いてサービスを作成します。すでにサービスが存在する場合は必要ありませんが、後述のrolloutと同じデプロイファイルを使うということで、ない場合にシュッと作れるように用意されました。
cage rollout
rolloutは、cageのメイン機能で既存のサービスを「できるだけ安全に」ロールアウトさせるコマンドです。使い方はup同様で、
$ cage rollout .deploy/
のようにデプロイファイルがあるディレクトリパスを引数に渡すだけです。
rolloutは以下のステップでサービス更新の前にサービス定義、タスク定義、Dockerイメージの健全性を検証します。
-
task-definition.jsonで新タスク定義を登録する
- cageでは、デプロイのたびに新しいタスク定義を登録し直すことを推奨しています
- 大抵の場合はタスク定義のDockerイメージのタグの記述だけを変更することになるでしょうが、イメージタグが異なるタスク定義は異なるものとして管理するべきです
-
service.jsonと新タスク定義でカナリアサービスを作成する - サービス定義、タスク定義、Dockerイメージが壊れていないか検証するために、メインサービスと同じクラスターに「カナリアサービス」を作成します
- カナリアサービスは、基本的にロールアウト対象となる本サービスと同じリソースを使用し、同じTargetGroupに登録されます
- この時点で、
web-serverというサービスがある場合は、web-server-canaryというサービスを新規作成します - カナリアサービスが安定するまで待つ
- この段階で、サービス定義、タスク定義、Dockerイメージの不備がふるい落とされます
- カナリアサービスが安定して起動しない場合は、ロールアウト失敗になりますが、メインサービスのリソースを何も変更しません
- カナリアサービスのタスクがALBのTarget Groupに登録され、healthyと認定されているか確認する
- タスクがRUNNINGになりサービスが安定しても、タスクがALBから健全だと判定されるとは限りません
- それどころか、ALBのヘルスチェックに失敗したタスクはTargetGroupから外されるどころか、ECSからも消されます
- cageはカナリアサービスのタスクがTargetGroupに登録され、ALBからhealthyと認定されるまでを監視して検証します
- 何らかの原因でヘルスチェックが通らないタスクを配置してしまった場合でも、メインサービスに影響を与えないようになっています
- メインサービスのタスク定義を新タスク定義に更新して、サービスが安定するまで待つ
- メインサービスを新タスク定義で更新し、ECSの機能でタスクのローリングアップデートを行います
- ちなみに最近リリースされたCodeDeployのECS Blue/Green Deploymentには対応していません
- カナリアサービスを削除する
- 検証に使用したカナリアサービスを削除します
- これでロールアウトが完了したメインサービスだけが残ります
cageのベタープラクティス
cageを使う上で、弊社で行っているいくつかのベタープラクティスを紹介します。
デプロイファイルをGitで管理する
デプロイファイルは、cageの実行時に正しいものが存在すればいいのですがCI/CD的な用途のためにGitでサービスのリポジトリに入れて管理することをおすすめします。Gitリポジトリに入れて管理することで、開発チームで正しいデプロイメントの記述が一つに定まり、誰がupやrolloutを実行しても同じ結果を得ることができるようになります。
しかしAWSのリソースの記述は人類には難しすぎるので、インフラの変更をデプロイファイルに反映するのが大変かもしれません。
デプロイファイルをterraformで生成する
言い遅れましたが、弊社ではAWSのリソース管理を基本的に95%くらいまではterraformで管理しています。サービスで使うリソースはほぼ全てterraformで管理しているので、当然ECSに関連するリソースもterraformに記録されています。
service.jsonやtask-definition.jsonの中に、どうしても生のAWSのリソースを記述しないといけない場合は、terraform outputでデプロイファイルを生成するという手法をおすすめします。
なぜなら、セキュリティグループやサブネットのIDは人類には覚えることは不可能なので、常にリソース的に正しいデプロイファイルを維持するために、terraformでインフラに変更を加えるたびに自動的に生成しています。
とはいえ殆どの項目を変えることがないので、必須というわけでもないです。
ただ、正しいリソース情報をGitファイルで管理するのはとても便利です。コンソールにいってコピペする手間が減ります。
terraformにこういった記述をしておいて、
output "service-1/service.json" {
value = <<-EOS
{
"cluster": "${aws_ecs_cluster.service.name}",
"serviceName": "web-service",
"taskDefinition": "dummy",
"loadBalancers": [
{
"targetGroupArn": "${aws_alb_target_group.service.arn}",
"containerName": "web-service",
"containerPort": 80
}
],
"desiredCount": 2,
"launchType": "FARGATE",
"deploymentConfiguration": {
"maximumPercent": 200,
"minimumHealthyPercent": 100
},
"networkConfiguration": {
"awsvpcConfiguration": {
"subnets": [
"${aws_subnet.subnet_a.id}",
"${aws_subnet.subnet_b.id}",
"${aws_subnet.subnet_c.id}"
],
"securityGroups": [
"${aws_security_group.sg-1.id}",
"${aws_security_group.sg-2.id}"
],
"assignPublicIp": "DISABLED"
}
},
"healthCheckGracePeriodSeconds": 60
}
EOS
}
}
terraformコマンドでファイルを更新
$ terraform output service-1/service.json > .deploy/service.json
やはり少し面倒なんですが、確実さはあるかと。
monorepoでデプロイファイルを管理する
弊社では試験的にマイクロサービスとmonorepoの運用をやっていて(まだ勝敗は不明)、cageのデプロイファイルもそれに合わせた構成で管理しています。リリースステージがdevelopment,stging,prductionの3つあるので、それ掛けるマイクロサービスの数のソースコードとデプロイファイルが一つのリポジトリで管理されています。画像にするとこんな感じ。
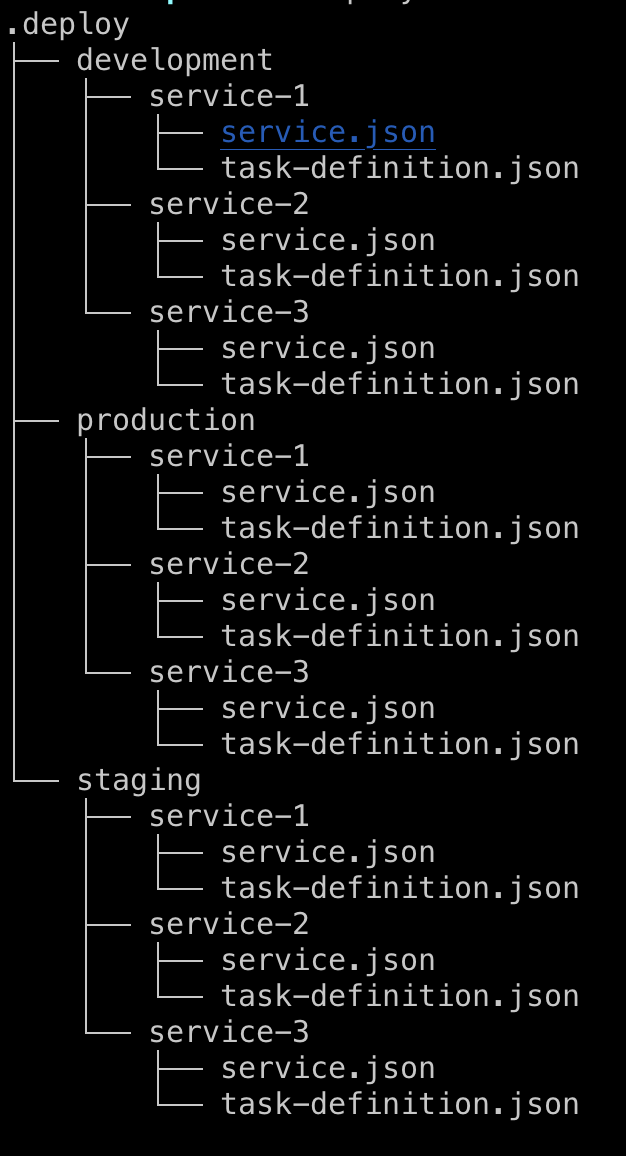
実際はもっと多いですが、これが正しいのかまだ分かってないです。特にCI系のサービスがmonorepoに厳しく、うまく運用できてるとはいい難いです。例えばPullRequestはservice-1の変更だけど、developにマージしたときそれがわからないので全部デプロイしちゃうとか。
そういう事情も相まってデプロイに安心感をもとめたという理由がありますが。
デプロイファイルに環境変数を注入する
リポジトリでデプロイファイルを管理する場合、どうしても手動デプロイやCD(Continual Delivery)段階まで分からない要素が存在します。
いちばん身近な例が、タスク定義ファイルのimageの項目です。
imageの項目はCDするDockerイメージのタグを指定しなければいけませんが、例えば「masterブランチのCIを通った場合のみECRにプッシュしてCDしたい」という場合、CDするためのタグはコードをpushした段階ではわかりません。
そういった場合は、シェルスクリプトの環境変数リテラルをtask-definition.jsonとservice.jsonに記述しておくことが便利です。(※「$VAR」のような記法は使えません。${VAR}だけになります。)
"image": "123456789.dkr.ecr.ap-northeast-1.amazonaws.com/web-server:${IMAGE_TAG}"
cageはコマンドを実行する際、task-definition.jsonとservice-definition.jsonに記述された環境変数リテラルを自動的に自身の環境変数で置き換えて登録します。
弊社はCircleCIを使っていますが、CI上ではこういったスクリプトが実行されています。
... CI
# コミットをtagにしてECRにpush
$(aws ecr get-login --no-include-email --region ap-northeast-1)
ECR_URI=123456789.dkr.ecr.ap-northeast-1.amazonaws.com
docker tag ${IMAGE} ${ECR_URI}/web-server:${CIRCLE_SHA1}
docker push ${ECR_URI}/web-server:${CIRCLE_SHA1}
docker tag ${IMAGE} ${ECR_URI}/web-server:latest
docker push ${ECR_URI}/web-server:latest
# cageでデプロイ
IMAGE_TAG=${CIRCLE_SHA1} cage deploy .deploy/
まとめとAWSでのコンテナのこれからポエム
ECSへのデプロイツールについて紹介しましたが、本来こういうツールは必要ないはずで、堅牢なデプロイはECSに統合されているべきだと思っています。
ECSは、現在コンテナのデプロイスタック(タスクを配置)としてのみ設計されている印象で、実際にWebサービスをコンテナでデプロイすることを第一に設計できていないように思えます。ECSは下記のようにタスクをWebサービスとして成り立たせるために周辺の別サービスと連携させていますが、あまりいい設計には思えません。正直言って使いづらいです。
- クラスター: EC2
- ネットワーク: VPC
- ロードバランサー: ALB
- デプロイ: CodeDeploy
- スケーリング: Application AutoScaling
これはEC2でWebアプリケーションを動かすのとほとんど大差ない構成です。開発中、コンテナの良さとは…という問いを繰り返ししていました。「もうEC2でDocker動かせばよくね?」的な。
控えめに言って、現在のAWSのクラウド関連のサービスは、VPCとインスタンス時代の設計に引っ張れれすぎてコンテナファーストになっていないと感じています。
現在のWebアプリケーションの開発者にとって、王様はDockerコンテナであり、ロードバランサーやVPCネットワークはコンテナだけをサポートするために作られていてほしいというのが本音です。Kubernetesはまさにコンテナファーストの思想で設計されているように思います。実際Kubernetes on GKEも移行先として検討中です。
それにしてもDockerイメージをビルドしてrunするのはめちゃくちゃ簡単なのにそれをどこかへデプロイするのはなんでこんなに楽にならないんですかね? VPS時代にSSHでgit pullして再起動していた時代のほうがわかりやすかった。個人的に作ってるアプリとかはNowにデプロイしてますが、AWSにもこういうのがほしい。ElasticBeanstalk?知らない子ですね…
別件ですが、Goいいですね。CLI書くのにおすすめだと思います。
お客様の中にDocker神もしくはKubernetes神がいらっしゃいましたら弊社にきて僕の仕事をなくしてください。僕の仕事はTypeScriptでExpressとReactを書くことなんです。よろしくお願いいたします。
それでは失礼します!