はじめに、筆者情報
非職業エンジニア
趣味で競技プログラムを始めて5年
2024年後半頃からヒューリスティックコンテストにLLM(ChatGPT/Gemini)を活用
GitHubを自作ライブラリ置き場にはしてるけどGitナニモワカラナイ
ChatGPT×Codexで実現するヒューリスティック競技プログラミングの新スタイル
2025年5月にリリースされたChatGPT版Codexの競技プログラミング(ヒューリスティック)での活用に可能性を感じたので記事にしてみます。リリースされたばかりの機能なので試行錯誤の段階ですがこれまでのChatGPTとは一線を画す使用感で、使い方を工夫すれば強力なパートナーになると感じています。
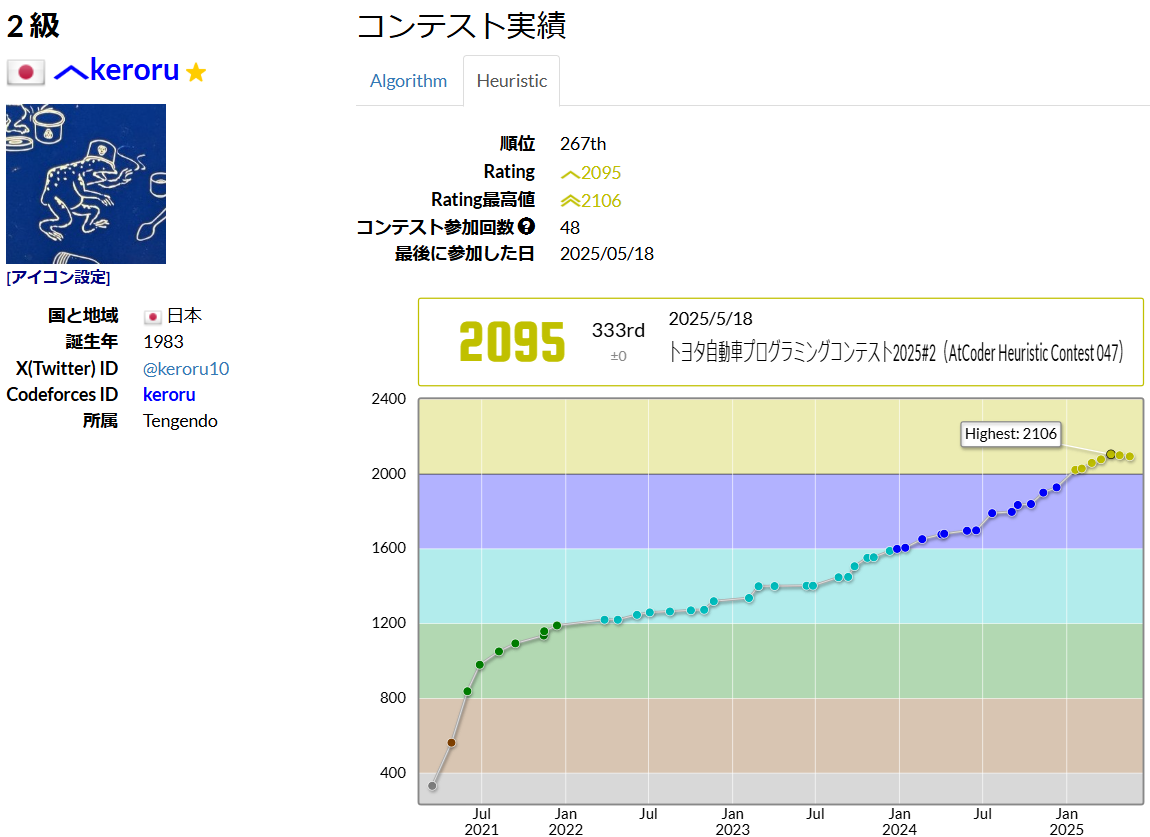
本記事では実際に「トヨタ自動車プログラミングコンテスト2025#2(AtCoder Heuristic Contest 047)」でCodexを使ってみた実例や今後の課題等を紹介していきます。
Codexで出来ること(2025年5月時点 o3調べ)
| 機能 | 詳細 |
|---|---|
| Code / Ask サイドバー | ChatGPT画面からプロンプトを送信し、自動でコード生成・改善タスクを開始。並列実行可能 |
| クラウドSandbox | GitHubリポジトリを自動でクローンし、環境内でテストやベンチマークを実行 |
| セルフヒーリング機能 | テスト失敗時には自動的に修正を繰り返し、テスト通過まで再試行 |
| 多言語サポート | Pythonでプロトタイプを作り、C++やRustへ自動的にコード移植 |
| AGENTS.mdによるカスタマイズ | プロジェクトごとに特化したビルド・テスト方法を定義可能 |
5月21日時点ではProプラン($200/月)にのみ提供されています。月額料金以外の追加料金なしで使い放題で、並列で指示を投げまくれて内部的にはo3がガンガン回っているっぽいので激安では?と思っています。
Codexで戦うヒューリスティックコンテストの流れ
コンテスタント: GitHubリポジトリの作成
(以下の繰り返し)
コンテスタント: コーディング内容をチャットで指示
Codex: 指定したリポジトリをクローン(この後はネット接続はしない)。指示にしたがって問題の解答コードを変更。(実行環境があり、実行しながら編集する)数分~30分後に変更を完了。
コンテスタント: コード差分を確認。プルリクの生成ボタンを押し、マージ、良さそうなら解答として提出する。
コンパイルや実行時のエラーメッセージを読みながらフィードバックループを自分で回してくれるのがすごい所です。今までのチャットベースでのやり取りでありがちだった、生成コードを実行>>コンパイルエラーになってエラーメッセージをチャットに貼って修正(繰り返し)…という虚無の作業が必要ありません。AHC047では基本的にほぼ全てのPRを実際に提出しましたが、全てACを取れて半分くらいの割合でスコアも改善しています。
CodexのAHCでのセットアップ
GitHubリポジトリの用意
フォルダ構成は公式配布ツール通りでいいと思います。
.
├── in :入力ファイル
├── out :出力ファイル
└── src :公式テスター
以下、配布ツール以外のファイル
AGENTS.md : これをリポジトリに置くとこの内容に従ってCodexが動いてくれます。
task.html : 問題ページのhtmlソースを置いています。
next_action.txt : Codexでは最初の指示でしか対話ができないので、実装時の考察を受け取ったりQ&Aをしたりするためのファイルがあるといいかなと思っています。
Codexの挙動をコントロールするAGENTS.mdが一番重要だと思っていて、継続的にいじっている最中ですが今はこんな感じです。これを改善していけばパフォーマンスが上がるのではと期待しています。
# このリポジトリについて
- このリポジトリは競技プログラミングのヒューリスティックな問題を解くためのものである。
- 問題はtask.htmlに記載されている。
## タスク実行時の注意
- タスク実行中に気付いたこと、さらなる改善の可能性などがあれば next_Action.txt に追記すること。
- タスク等の不明点についての質問がある場合もこのファイルに追記して伝えること。ユーザーからの解答もこのファイルを通して与えられる。
## テスト方法
入力ファイルは下記のような名前で0000~0099まで与えられることが多い
./in/0001.txt
下記の例のように実行して、テストケース0000~0014の15件の合計スコアをベンチマークとせよ。改善せよというタスクの場合はこのスコアをKPIとする。スコアが大小どちらがよいかは問題を読んで判断すること。
./a.out < $input_file > $output_file 2> $err_file
入出力は下記の形式で行う
- 入力ファイル ./in/0000.txt
- 出力ファイル ./out/out_0000.txt
- エラー出力ファイル ./err/err_0000.txt
テストをbashで自動化したものがあるのでこれを使ってテストすること。
./run_all_par_sh.sh
タスク完了時に、テスト結果の15ケースのスコアの合計をSummaryに明記すること。
# コーディング規約・実装のヒント
- 指示の無い限り言語はC++20で実装する
- TL、焼きなましの開始温度、最終温度などのモデルパラメータはグローバル変数として、定義はコードの先頭部分に置く事。
- なるべく差分更新でスコアを計算できるようなデータの持ち方を考える
## 出力形式
### 標準出力
標準出力への形式はtask.htmlに記載の出力の形式を遵守すること
### エラー出力
次の項目がある場合は個の順にエラー出力へ出力すること
- 最終ベストスコア
- モデルパラメータ(パラメータチューニングのため)
- 焼きなましのループ回数
- 時間経過ごとのベストスコア(0.1secごと)
## 焼きなましの実装方法
- 状態のコピーをするよりも、遷移で状態を変更してしまって、受理されなかったら元に戻すようにするとコピーコストがかからない
- 時間計測は毎回行わない
- 乱数を返す関数は焼きなましループの外で定義しておく
### 焼きなましの方針のヒント
- 遷移には逆遷移を含めた方がよい
- 一部を大きく破壊して貪欲に再構築する遷移が有効なことがある
- 一定時間スコア改善がない場合は初期解からスタートしなおす(kick)が有効なことがある
- 1点だけの変更ではスコアに直接影響しない、複数の条件が集まって始めてスコアが上がるような設定になっている場合は複数の条件をまとめて導入する遷移が有効なことがある
## ビームサーチの実装方法
TBD
## 評価関数の設計
- 得点Pが大きいものを特に重視したい場合、P >> P^x (x>1) のような変換が有効なことがある
### 高速化TIPS:
- BFS: 探索済リストの初期化を毎回行わず、各BFS開始前にbfscntを適度にインクリメントしてvisitedまたは距離0としてあつかう
- 乱数生成は `std::mt19937` をグローバルに保持し、毎回初期化しない
- スコア計算や評価値は差分更新を徹底して O(1) で求められる形を目指す
- 探索で使う配列は使い回し、キャッシュの局所性を意識する
ヒューリスティックコンテストでCodex活用の利点
高速かつ並列なイテレーション
- 解法のプロトタイプ生成を自動化
- アイデアをすぐに試行錯誤できる
- 試しに出力作成>>ヴィジュアライザで確認>>改善案の考察 というループを高速で回せる
テストの自動化
- 実際に入力ケースを実行してスコアを出すところまでやってくれるのでコードが確実に動く
- 手動デバッグの手間を大幅削減
- スコアが改善されたかどうかも確認可能
結果と課題
結果
(2025/8/26追記)
AHC052でCodex only参戦で本番11位を達成しました。
この間にGPT-5がリリースされたり(CodexもGPT-5になっている??)、GPT-5に改善プロンプトを生成させるという手法を導入したり、というのが効いたのかもしれません。
自分だけでは絶対に取れなかったであろう順位です。
(追記ここまで)
残念ながらAHC047では筆者と問題の相性が悪かったようで、333位/1030人中という散々な結果ではありました。今回の敗因は自分で考えすぎたことだと思っています。焼きなましが当たり方針だったのに、文字列のうまい埋め込みでいけるのではないかと思ってしまい、時間を浪費してしまいました。
なお、旅行中でスマホコーディング参加だったAHC046の復習では1~2時間で60位以内のスコアまで到達できました。次回の短期コンテストでは本番で2桁順位にいきたいですね。(そういえばGitHubの準備さえできてしまえばスマホで指示出しして提出まで簡単にできるのでスマホ参加でも本格的に上位を狙える??)
今後の課題
- テストケースを回してスコアを出すように
AGENTS.mdに書いてはいるが、毎回スコアを出してくれるわけではない。この辺うまくコントロールしたり、テストプロセスも洗練させたい。 - 公式テスター、ヴィジュアライザも活用してフィードバックループを上手く回したい。o3はマルチモーダルなのでヴィジュアライザ画像からも考察ができるはず?
- 提出も自動化したいが、AtCoderは最近CLOUDFLARE認証を導入したので難しいかも。