はじめに
Kotlin で Android アプリを作るための基本的なコーディング学習を完了したので、作ろうとしている Android アプリから呼び出す Web API が参照するデータの準備を始めました。
-
Android アプリ開発の学習に利用した書籍
最終的にやりたいこと
ここ最近、毎日のように閲覧している バーチャル YouTuber プロダクション「ホロライブ」などの、動画配信予定を定期的にデータベースに格納し、それを Web API で参照して閲覧する Android アプリを作りたい。
- 動画配信予定を収集するためのプログラムの作成
- 収集した動画配信予定を格納するためのデータベースの作成と収集の自動化
- 格納した動画配信予定を参照するための Web API の作成
- Web API を参照して動画配信予定を閲覧する Android アプリの作成
ホロライブ
ホロライブのライバーの動画配信予定は下記ページで公開されています。
ホロライブプロダクション配信予定スケジュール『ホロジュール』
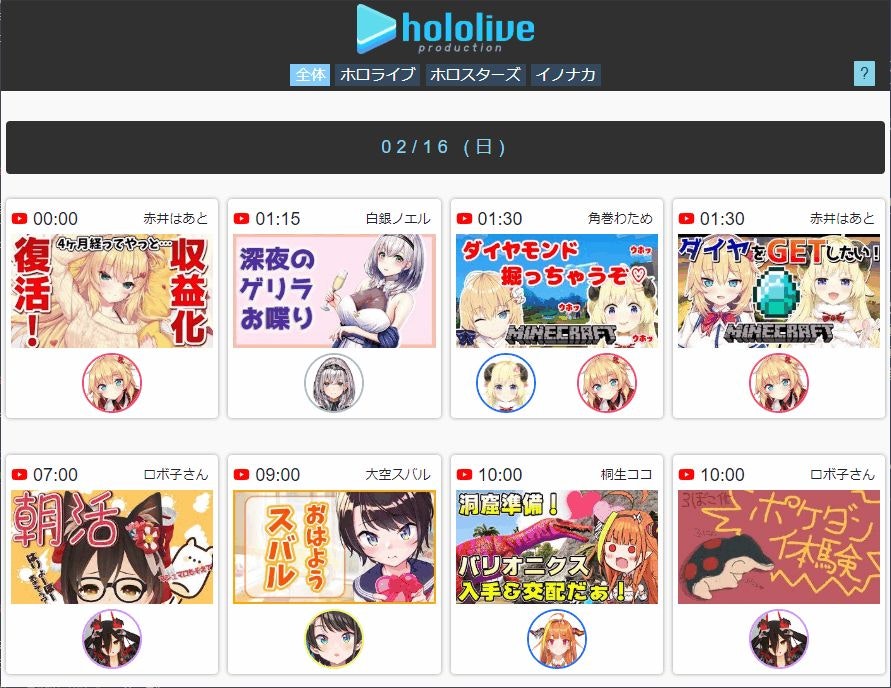
Web スクレイピングだけでなんとかなるでしょ。って思ったら、動画のタイトルや説明はリンク先の YouTube にしか無い。
YouTube は Web スクレイピングが禁止されている。ということで、Web スクレイピングと YouTube Data API を組み合わせることにしました。
やったこと
今回は、やりたいこと 1 の「動画配信予定を収集するためのプログラムの作成」を行いました。
-
開発環境の準備
- プロジェクトディレクトリの作成
- git 初期化
- .gitignore の作成
- Python 仮想環境の構築
- Web スクレイピングのための geckodriver のダウンロード
- YouTube 動画情報を取得するための YouTube Data API v3 の有効化
- .env の作成
- requirements.txt の作成
- requirements.txt を利用して Python のパッケージを一括インストール
-
プログラムの作成
- .env からの設定情報の取得
- プログラム実行時のコマンドライン引数の取得
- ホロライブプロダクション配信予定スケジュール『ホロジュール』の情報を取得
- YouTube から動画の情報を取得
- CSV ファイルの出力
-
プログラムの実行
- lounch.json の作成
- プログラムのデバッグ実行
- 実行結果(出力したCSVファイル)
開発環境の準備
下記構成で環境を用意しました。
- Windows 10 Pro x64 1909
- Python 3.7.6
- Power Shell 6 x64
- Visual Studio Code x64 1.42.1
- Git for Windows x64 2.25.0
プロジェクトディレクトリの作成
> mkdir holoduler
> cd holoduler
git 初期化
> git init
.gitignore の作成
.gitignore ファイルを作成し、除外対象を設定しておきます。
> ni .gitignore
/__pycache__/
/venv/
/geckodriver.log
/geckodriver.exe
.env
Python 仮想環境の構築
Python のバージョンを確認し、仮想環境構築用の virtualenv を導入します。
> python -V
Python 3.7.6
> pip install virtualenv
virtualenv で仮想環境を構築して有効化します。
> virtualenv venv
> activate
(venv) > python -V
Python 3.7.6
Web スクレイピングのための geckodriver のダウンロード
Selenium で Firefox を利用するための geckodriver をダウンロードします。
- geckodriver(geckodriver-v0.26.0-win64.zip)をダウンロードします。
- geckodriver-v0.26.0-win64.zip を解凍し、geckodriver.exe を任意の場所に配置して PATH を通しておきます。
YouTube 動画情報を取得するための YouTube Data API v3 の有効化
Google Developer Console でプロジェクトを作成し、YouTube Data API v3 を有効化します。
- Google Developer Console にログイン
- ダッシュボードでプロジェクトを作成
- ライブラリで YouTube Data API v3 を有効化
- 認証情報で認証情報を作成して APIキー を取得
.env の作成
YouTube Data API v3 の APIキーなどを設定しておくためのファイルを作成します。
(venv) > ni .env
HOLODULE_URL = "ホロジュールのURL"
API_KEY = "YouTube Data API v3 の APIキー"
API_SERVICE_NAME = "youtube"
API_VERSION = "v3"
requirements.txt の作成
もろもろインストールするための requirements.txt を作成します。
(venv) > ni requirements.txt
pylint
beautifulsoup4
requests
selenium
urllib3
lxml
google-api-python-client
python-dotenv
requirements.txt を利用して Python のパッケージを一括インストール
(venv) > pip install -r .\requirements.txt
この時点でこんな感じになっているはずです。
├ __pycache__
├ .vscode
├ venv
├ .env
├ .gitignore
└ requirements.txt
プログラムの作成
.env からの設定情報の取得
settings.py ファイルを作成します。
(venv) > ni settings.py
python-dotenv を利用して、.env に設定した YouTube Data API v3 の APIキーなどを取得します。
.envファイルからキーと値のペアを読み取り、環境変数に追加します。
12ファクターの原則を使用して、開発中および運用中にアプリの設定を管理するのに最適です。
import os
from os.path import join, dirname
from dotenv import load_dotenv
# .env ファイルを明示的に指定して読み込む
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
# ホロジュールのURL
HOLODULE_URL = os.environ.get("HOLODULE_URL")
# YouTube Data API v3 の APIキー
API_KEY = os.environ.get("API_KEY")
# YouTube Data API v3 の APIサービス名
API_SERVICE_NAME = os.environ.get("API_SERVICE_NAME")
# YouTube Data API v3 の APIバージョン
API_VERSION = os.environ.get("API_VERSION")
プログラム実行時のコマンドライン引数の取得
holoduler.py ファイルを作成します。
(venv) > ni holoduler.py
argparse を利用して、プログラム実行時のコマンドライン引数を取得します。
argparse モジュールは、ユーザーフレンドリなコマンドラインインターフェースの作成を簡単にします。プログラムがどんな引数を必要としているのかを定義すると、argparse が sys.argv からそのオプションを解析する方法を見つけ出します。
argparse モジュールは自動的にヘルプと使用方法メッセージを生成し、ユーザーが不正な引数をプログラムに指定したときにエラーを発生させます。
import os
import argparse
...割愛
def main():
# parser を作る(説明を指定できる)
parser = argparse.ArgumentParser(description="ホロジュールのHTMLをSelenium + BeautifulSoup4 + YouTube Data API で解析してCSV出力")
# コマンドライン引数を設定する(説明を指定できる)
parser.add_argument("filepath", help="出力するCSVファイルのパス")
# コマンドライン引数を解析する
args = parser.parse_args()
# ファイルパスの取得
filepath = args.filepath
# ディレクトリパスの取得と存在確認
dirpath = os.path.dirname(filepath)
print(f"出力ディレクトリパス : {dirpath}")
if os.path.exists(dirpath) == False:
print("エラー : 出力するCSVファイルのディレクトリパスが存在しません。")
return RETURN_FAILURE
# ファイル名の取得
filename = os.path.basename(filepath)
print(f"出力ファイル名 : {filename}")
# URLの取得とアクセス確認(parser から取得)
holodule_url = settings.HOLODULE_URL
print(f"ホロジュールURL : {holodule_url}")
if check_url(holodule_url) == False:
print("エラー : 設定されているURLにアクセスできません。")
return RETURN_FAILURE
# YouTube Data API v3 の API設定(parser から取得)
api_key = settings.API_KEY
api_service_name = settings.API_SERVICE_NAME
api_version = settings.API_VERSION
ホロライブプロダクション配信予定スケジュール『ホロジュール』の情報を取得
Selenium Firefox (geckodriver) で Web ページを取得し、BeaurifulSoup4 で解析します。
主にテスト目的でWebアプリケーションを自動化するためのものですが、
確かにそれだけに限定されません。 退屈なWebベースの管理タスクも自動化できます(また、そうすべきです)。
このプログラムは、WebDriverプロトコルで記述されたHTTP APIを提供して、
FirefoxなどのGeckoブラウザーと通信します。
Beautiful Soupは、Webページから情報を簡単に収集できるライブラリです。
HTMLまたはXMLパーサーの上にあり、解析ツリーの反復、検索、および変更のためのPythonのイディオムを提供します。
def get_holodule_list(self):
try:
# プロファイルのセットアップ
profile = self.__setup_profile()
# オプションのセットアップ
options = self.__setup_options()
# ドライバの初期化(オプション(ヘッドレスモード)とプロファイルを指定)
self.__driver = webdriver.Firefox(options=options, firefox_profile=profile)
# 指定したドライバに対して最大で10秒間待つように設定する
self.__wait = WebDriverWait(self.__driver, 10)
# ホロジュールの取得
holodule_list = self.__get_holodule()
# YouTube情報の取得
... 割愛
# 生成したリストを返す
return holodule_list
except OSError as err:
print("OS error: {0}".format(err))
except:
print("Unexpected error:", sys.exc_info()[0])
raise
finally:
# ドライバを閉じる
self.__driver.close()
Selenium Firefox (geckodriver) のプロファイルを設定します。
def __setup_profile(self):
# Firefoxプロファイルの設定
profile = webdriver.FirefoxProfile()
# TODO : ファイルのダウンロードを想定していた際の設定を残している
# 0:デスクトップ、1:システム規定フォルダ、2:ユーザ定義フォルダ
profile.set_preference("browser.download.folderList", 2)
# 上記で2を選択したのでファイルのダウンロード場所を指定
profile.set_preference("browser.download.dir", self.__dirpath)
# ダウンロード完了時にダウンロードマネージャウィンドウを表示するかを示す真偽値
profile.set_preference("browser.download.manager.showWhenStarting", False)
# MIMEタイプを設定(これが実態と一致していないとダイアログが表示されてしまう)
profile.set_preference("browser.helperApps.neverAsk.saveToDisk",
"application/octet-stream-dummy")
# その他(参考)
# profile.set_preference("browser.helperApps.alwaysAsk.force", False)
# profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
# profile.set_preference("browser.download.manager.focusWhenStarting", False)
# profile.set_preference("browser.download.manager.useWindow", False)
# profile.set_preference("browser.download.manager.showAlertOnComplete", False)
# profile.set_preference("browser.download.manager.closeWhenDone", False)
return profile
Selenium Firefox (geckodriver) のオプションを設定します。
def __setup_options(self):
# Firefoxオプションの設定
options = Options()
# ヘッドレスモードとする
options.add_argument("--headless")
return options
Selenium Firefox (geckodriver) で Web ページを取得し、BeaurifulSoup4 で解析します。
日時とライバーごとのスケジュールをリストに格納して返却します。
def __get_holodule(self):
# 取得対象の URL に遷移
self.__driver.get(self.__holodule_url)
# <div class="holodule" style="margin-top:10px;">が表示されるまで待機する
self.__wait.until(EC.presence_of_element_located((By.CLASS_NAME, "holodule")))
# ページソースの取得
html = self.__driver.page_source.encode('utf-8')
# ページソースの解析(パーサとして lxml を指定)
soup = BeautifulSoup(html, "lxml")
# タイトルの取得(確認用)
body = soup.find("body")
title = body.find("title").text
print(title)
# TODO : ここからはページの構成に合わせて決め打ち = ページの構成が変わったら動かない
# スケジュールの取得
holodule_list = []
date_string = ""
today = datetime.date.today()
tab_pane = soup.find('div', class_="tab-pane show active")
containers = tab_pane.find_all('div', class_="container")
for container in containers:
# 日付のみ取得
div_date = container.find('div', class_="holodule navbar-text")
if div_date is not None:
date_text = div_date.text.strip()
match_date = re.search(r'[0-9]{1,2}/[0-9]{1,2}', date_text)
dates = match_date.group(0).split("/")
month = int(dates[0])
day = int(dates[1])
year = today.year
if month < today.month or ( month == 12 and today.month == 1 ):
year = year - 1
elif month > today.month or ( month == 1 and today.month == 12 ):
year = year + 1
date_string = f"{year}/{month}/{day}"
# print(date_string)
# ライバー毎のスケジュール
thumbnails = container.find_all('a', class_="thumbnail")
if thumbnails is not None:
for thumbnail in thumbnails:
holodule = Holodule()
# YouTube URL
youtube_url = thumbnail.get("href")
if youtube_url is not None:
holodule.url = youtube_url
# print(holodule.url)
# 時刻(先に取得しておいた日付と合体)
div_time = thumbnail.find('div', class_="col-5 col-sm-5 col-md-5 text-left datetime")
if div_time is not None:
time_text = div_time.text.strip()
match_time = re.search(r'[0-9]{1,2}:[0-9]{1,2}', time_text)
times = match_time.group(0).split(":")
hour = int(times[0])
minute = int(times[1])
datetime_string = f"{date_string} {hour}:{minute}"
holodule.datetime = datetime.datetime.strptime(datetime_string, "%Y/%m/%d %H:%M")
# print(holodule.datetime)
# ライバーの名前
div_name = thumbnail.find('div', class_="col text-right name")
if div_name is not None:
holodule.name = div_name.text.strip()
# print(holodule.name)
# リストに追加
holodule_list.append(holodule)
return holodule_list
YouTube から動画の情報を取得
YouTube Data API v3 を利用して動画のURLに含まれるIDから動画の情報を取得します。
YouTube Data API を使うと、YouTube Web サイトで通常実行する機能を、自分の Web サイトやアプリケーションに統合できます。
from apiclient.discovery import build
from apiclient.errors import HttpError
...割愛
# YouTube Data API v3 を利用するための準備
self.__youtube = build(api_service_name, api_version, developerKey=api_key)
取得した日時とライバーごとのスケジュールごとに YouTube の情報を取得します。
...割愛
for holodule in holodule_list:
# TODO : ループして1件ずつ API を呼び出すのは見直すべきかも(クォータ制限に関連)
video_info = self.__get_youtube_video_info(holodule.url)
holodule.title = video_info[0]
# TODO : 説明文が長いので20文字でばっさり切っている
holodule.description = video_info[1][:20]
...割愛
YouTube 動画のURLからIDを取得し、YouTube Data API v3 を利用してタイトルなどを取得します。
動画を指定して情報を取得するため、search() ではなく videos() を利用しています。
def __get_youtube_video_info(self, youtube_url):
# YouTube の URL から ID を取得
match_video = re.search(r'^[^v]+v=(.{11}).*', youtube_url)
video_id = match_video.group(1)
# YouTube はスクレイピングを禁止しているので YouTube Data API (v3) で情報を取得
search_response = self.__youtube.videos().list(
# 結果として snippet のみを取得
part="snippet",
# 検索条件は id
id=video_id,
# 1件のみ取得
maxResults=1
).execute()
# 検索結果から情報を取得
for search_result in search_response.get("items", []):
# タイトル
title = search_result["snippet"]["title"]
# 説明
description = search_result["snippet"]["description"]
# タイトルと説明を返却
return (title, description)
return ("","")
参考:search() を利用する場合(こちらのほうがクォータ使用量が多い感じ)
search_response = self.__youtube.search().list(
# 検索条件
q="検索条件を指定",
# 結果として id と snippet を取得
part="id,snippet",
# 対象を video 限定とする
type="video",
# 1件のみ取得
maxResults=1
).execute()
CSV ファイルの出力
取得した日時とライバーごとのスケジュールをCSVファイルとして出力します。
import csv
...割愛
try:
# ホロジュールの取得
hddl = HoloduleDownloader(holodule_url, dirpath, api_key, api_service_name, api_version)
hdlist = hddl.get_holodule_list()
# CSV出力(BOM付きUTF-8)
with open(filepath, "w", newline="", encoding="utf_8_sig") as csvfile:
csvwriter = csv.writer(csvfile, delimiter=",")
csvwriter.writerow(["日時", "名前", "タイトル", "URL", "抜粋説明"])
for hd in hdlist:
csvwriter.writerow([hd.datetime, hd.name, hd.title, hd.url, hd.description])
return RETURN_SUCCESS
except:
info = sys.exc_info()
print(info[1])
return RETURN_FAILURE
GitHub に登録
GitHub にリポジトリを作成して登録しておきます。
> git status
> git add .
> git commit -m "first commit."
> git remote add origin https://github.com/********/********.git
> git push -u origin master
プログラムの実行
lounch.json の作成
Visual Studio Code で launch.json を作成して出力ファイルパスを設定しておきます。
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"args": ["c:\\temp\\holodule.csv"]
}
]
}
プログラムのデバッグ実行
Visual Studio Code でデバッグ実行します。
コマンドラインから実行する場合は、下記のように実行します。
(venv) > python .\holoduler.py c:\temp\holoduler.csv
実行結果(出力したCSVファイル)
下記のような CSV ファイルが出力されました。
2020-02-13 21:00:00,兎田ぺこら,【ARK】本当にバレンタインイベント開始!!全力で楽しむぺこ!!【ホロライブ/兎田ぺこら】,https://www.youtube.com/watch?v=RZzGMtDhlvw,"みてないよね・・・?🐰ぺこらとのお約束"
2020-02-13 23:00:00,さくらみこ,#18【ぽんこつArk | ラグナロク】バレンタインイベント中💓ピンクな恐竜と衣装が欲しい!【ホロライブ/さくらみこ】,https://www.youtube.com/watch?v=jntHBtYEwsQ,#みこなま で感想をツイートしてくれると
2020-02-14 23:00:00,大空スバル,【#大空家】バレンタイン仕様の地獄です【地獄】,https://www.youtube.com/watch?v=Muy7B9S4bDc,====================
...
ソースコード
ファイル構成
├ __pycache__
├ .vscode
│ ├ launch.json
| └ settings.json
├ venv
├ .env
├ .gitignore
├ holoduler.py
├ requirements.txt
└ settings.py
settings.py
import os
from os.path import join, dirname
from dotenv import load_dotenv
# .env ファイルを明示的に指定して読み込む
dotenv_path = join(dirname(__file__), '.env')
load_dotenv(dotenv_path)
# ホロジュールのURL
HOLODULE_URL = os.environ.get("HOLODULE_URL")
# YouTube Data API v3 の APIキー
API_KEY = os.environ.get("API_KEY")
# YouTube Data API v3 の APIサービス名
API_SERVICE_NAME = os.environ.get("API_SERVICE_NAME")
# YouTube Data API v3 の APIバージョン
API_VERSION = os.environ.get("API_VERSION")
holoduler.py
"""
【ホロライブ】ホロジュールと YouTube の動画情報を取得してCSV出力する
YouTube Data API v3 のクォータが標準のままだと、制限の上限にすぐに到達してエラーとなる
1. 事前に geckodriver をダウンロードして配置し PATH を設定しておく
geckodriver https://github.com/mozilla/geckodriver/releases
2. Google の YouTube Data API v3 を有効化して API キーを取得しておく
Google Developer Console https://console.developers.google.com/?hl=JA
3. .envファイルを作成し、URLやAPIキーを設定しておく
参考 : .env.sample
4. requirements.txt を利用して Python のパッケージを一括インストールしておく
参考 : requirements.txt
"""
import sys
import os
import re
import csv
import time
import datetime
import argparse
import urllib.request
import settings
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from apiclient.discovery import build
from apiclient.errors import HttpError
RETURN_SUCCESS = 0
RETURN_FAILURE = -1
class Holodule:
# 日時
datetime = None
# 名前
name = ""
# タイトル(YouTubeから取得)
title = ""
# URL
url = ""
# 説明(YouTubeから取得)
description = ""
class HoloduleDownloader:
def __init__(self, holodule_url, dirpath, api_key, api_service_name, api_version):
self.__driver = None
self.__wait = None
self.__holodule_url = holodule_url
self.__dirpath = dirpath
# YouTube Data API v3 を利用するための準備
self.__youtube = build(api_service_name, api_version, developerKey=api_key)
def __setup_profile(self):
# Firefoxプロファイルの設定
profile = webdriver.FirefoxProfile()
# TODO : ファイルのダウンロードを想定していた際の設定を残している
# 0:デスクトップ、1:システム規定フォルダ、2:ユーザ定義フォルダ
profile.set_preference("browser.download.folderList", 2)
# 上記で2を選択したのでファイルのダウンロード場所を指定
profile.set_preference("browser.download.dir", self.__dirpath)
# ダウンロード完了時にダウンロードマネージャウィンドウを表示するかを示す真偽値
profile.set_preference("browser.download.manager.showWhenStarting", False)
# MIMEタイプを設定(これが実態と一致していないとダイアログが表示されてしまう)
profile.set_preference("browser.helperApps.neverAsk.saveToDisk",
"application/octet-stream-dummy")
# その他(参考)
# profile.set_preference("browser.helperApps.alwaysAsk.force", False)
# profile.set_preference("browser.download.manager.alertOnEXEOpen", False)
# profile.set_preference("browser.download.manager.focusWhenStarting", False)
# profile.set_preference("browser.download.manager.useWindow", False)
# profile.set_preference("browser.download.manager.showAlertOnComplete", False)
# profile.set_preference("browser.download.manager.closeWhenDone", False)
return profile
def __setup_options(self):
# Firefoxオプションの設定
options = Options()
# ヘッドレスモードとする
options.add_argument("--headless")
return options
def __get_holodule(self):
# 取得対象の URL に遷移
self.__driver.get(self.__holodule_url)
# <div class="holodule" style="margin-top:10px;">が表示されるまで待機する
self.__wait.until(EC.presence_of_element_located((By.CLASS_NAME, "holodule")))
# ページソースの取得
html = self.__driver.page_source.encode('utf-8')
# ページソースの解析(パーサとして lxml を指定)
soup = BeautifulSoup(html, "lxml")
# タイトルの取得(確認用)
body = soup.find("body")
title = body.find("title").text
print(title)
# TODO : ここからはページの構成に合わせて決め打ち = ページの構成が変わったら動かない
# スケジュールの取得
holodule_list = []
date_string = ""
today = datetime.date.today()
tab_pane = soup.find('div', class_="tab-pane show active")
containers = tab_pane.find_all('div', class_="container")
for container in containers:
# 日付のみ取得
div_date = container.find('div', class_="holodule navbar-text")
if div_date is not None:
date_text = div_date.text.strip()
match_date = re.search(r'[0-9]{1,2}/[0-9]{1,2}', date_text)
dates = match_date.group(0).split("/")
month = int(dates[0])
day = int(dates[1])
year = today.year
if month < today.month or ( month == 12 and today.month == 1 ):
year = year - 1
elif month > today.month or ( month == 1 and today.month == 12 ):
year = year + 1
date_string = f"{year}/{month}/{day}"
# print(date_string)
# ライバー毎のスケジュール
thumbnails = container.find_all('a', class_="thumbnail")
if thumbnails is not None:
for thumbnail in thumbnails:
holodule = Holodule()
# YouTube URL
youtube_url = thumbnail.get("href")
if youtube_url is not None:
holodule.url = youtube_url
# print(holodule.url)
# 時刻(先に取得しておいた日付と合体)
div_time = thumbnail.find('div', class_="col-5 col-sm-5 col-md-5 text-left datetime")
if div_time is not None:
time_text = div_time.text.strip()
match_time = re.search(r'[0-9]{1,2}:[0-9]{1,2}', time_text)
times = match_time.group(0).split(":")
hour = int(times[0])
minute = int(times[1])
datetime_string = f"{date_string} {hour}:{minute}"
holodule.datetime = datetime.datetime.strptime(datetime_string, "%Y/%m/%d %H:%M")
# print(holodule.datetime)
# ライバーの名前
div_name = thumbnail.find('div', class_="col text-right name")
if div_name is not None:
holodule.name = div_name.text.strip()
# print(holodule.name)
# リストに追加
holodule_list.append(holodule)
return holodule_list
def __get_youtube_video_info(self, youtube_url):
# YouTube の URL から ID を取得
match_video = re.search(r'^[^v]+v=(.{11}).*', youtube_url)
video_id = match_video.group(1)
# YouTube はスクレイピングを禁止しているので YouTube Data API (v3) で情報を取得
search_response = self.__youtube.videos().list(
# 結果として snippet のみを取得
part="snippet",
# 検索条件は id
id=video_id,
# 1件のみ取得
maxResults=1
).execute()
# 検索結果から情報を取得
for search_result in search_response.get("items", []):
# タイトル
title = search_result["snippet"]["title"]
# 説明
description = search_result["snippet"]["description"]
# タイトルと説明を返却
return (title, description)
return ("","")
def get_holodule_list(self):
try:
# プロファイルのセットアップ
profile = self.__setup_profile()
# オプションのセットアップ
options = self.__setup_options()
# ドライバの初期化(オプション(ヘッドレスモード)とプロファイルを指定)
self.__driver = webdriver.Firefox(options=options, firefox_profile=profile)
# 指定したドライバに対して最大で10秒間待つように設定する
self.__wait = WebDriverWait(self.__driver, 10)
# ホロジュールの取得
holodule_list = self.__get_holodule()
# YouTube情報の取得
for holodule in holodule_list:
# TODO : ループして1件ずつ API を呼び出すのは見直すべきかも(クォータ制限に関連)
video_info = self.__get_youtube_video_info(holodule.url)
holodule.title = video_info[0]
# TODO : 説明文が長いので20文字でばっさり切っている
holodule.description = video_info[1][:20]
# 生成したリストを返す
return holodule_list
except OSError as err:
print("OS error: {0}".format(err))
except:
print("Unexpected error:", sys.exc_info()[0])
raise
finally:
# ドライバを閉じる
self.__driver.close()
def check_url(url):
try:
# 指定したURLにアクセスできるかをチェック
with urllib.request.urlopen(url) as response:
return True
except urllib.request.HTTPError:
return False
def main():
# parser を作る(説明を指定できる)
parser = argparse.ArgumentParser(description="ホロジュールのHTMLをSelenium + BeautifulSoup4 + YouTube Data API で解析してCSV出力")
# コマンドライン引数を設定する(説明を指定できる)
parser.add_argument("filepath", help="出力するCSVファイルのパス")
# コマンドライン引数を解析する
args = parser.parse_args()
# ファイルパスの取得
filepath = args.filepath
# ディレクトリパスの取得と存在確認
dirpath = os.path.dirname(filepath)
print(f"出力ディレクトリパス : {dirpath}")
if os.path.exists(dirpath) == False:
print("エラー : 出力するCSVファイルのディレクトリパスが存在しません。")
return RETURN_FAILURE
# ファイル名の取得
filename = os.path.basename(filepath)
print(f"出力ファイル名 : {filename}")
# URLの取得とアクセス確認(parser から取得)
holodule_url = settings.HOLODULE_URL
print(f"ホロジュールURL : {holodule_url}")
if check_url(holodule_url) == False:
print("エラー : 設定されているURLにアクセスできません。")
return RETURN_FAILURE
# YouTube Data API v3 の API設定(parser から取得)
api_key = settings.API_KEY
api_service_name = settings.API_SERVICE_NAME
api_version = settings.API_VERSION
try:
# ホロジュールの取得
hddl = HoloduleDownloader(holodule_url, dirpath, api_key, api_service_name, api_version)
hdlist = hddl.get_holodule_list()
# CSV出力(BOM付きUTF-8)
with open(filepath, "w", newline="", encoding="utf_8_sig") as csvfile:
csvwriter = csv.writer(csvfile, delimiter=",")
csvwriter.writerow(["日時", "名前", "タイトル", "URL", "抜粋説明"])
for hd in hdlist:
csvwriter.writerow([hd.datetime, hd.name, hd.title, hd.url, hd.description])
return RETURN_SUCCESS
except:
info = sys.exc_info()
print(info[1])
return RETURN_FAILURE
if __name__ == "__main__":
sys.exit(main())
おわりに
やりたいこと 1 の「動画公開スケジュールを収集するためのプログラムの作成」を実現することができましたが、いくつか直したいことや課題があります。
-
Selenium Firefox は不要
- 結果としてページを取得して解析しただけなので、Selenium Firefox を利用する必要はなかったかもしれない。
- response = urllib.request.urlopen() と response.read() でいけると思う。
-
YouTube の既定のクォータが厳しい
- YouTube Data API v3 で動画の情報を取得すると、既定の上限である 10,000 / day はすぐに使い切ってしまう。(search() の使用量が凄まじかったので videos() に変更した)
- videos() を50回ほど実行すると、使用量が150ぐらい増加しているみたい。
-
次の実現に向けて
- やりたいこと 2 の「収集した動画配信予定を格納するためのデータベースの作成と収集の自動化」を実現する場合、どこに配置してどのように実現するかは未定
- Azure Functions (python) + Azure Cosmos DB (Mongo API) をやってみたい。