大規模言語モデル (Large Language Models; LLM) の登場によって、プロンプトエンジニアリングといった新しい概念が登場しました。
LLM 登場以前から機械学習を学んでいた身としては、プロンプトエンジニアリングの登場は「学問みたいな顔しているけど、結局モデルの癖では??」と中々受け入れられなかったのですが、今ではすっかり市民権を得ています。
さて、そんなプロンプトエンジニアリングの文脈で In-context Learning という単語が登場することがあります。
In-context Learning でググると、「要するに In-context Learning とは Few-shot prompting のこと」というようなページが出てくるのですが、「ML における Learning = パラメータの更新」という意識があると、非常に気持ち悪さを感じます。
そこで、今回はこの "In-context Learning" という言葉について確認していきます。
In-context Learning とは
In-context Learning は、Language Models are Few-shot Learnersという論文内で登場します(たぶん、この論文が言葉としては初出?)。
論文内では明確に In-context Leaning の定義が語られているわけではなく、何度か単語が登場するのでそこから定義は推し量ることができます。論文内では、以下のように説明されています。
During unsupervised pre-training, a language model develops a broad set of skills and pattern recognition abilities. It then uses these abilities at inference time to rapidly adapt to or recognize the desired task. We use the term “in-context learning” to describe the inner loop of this process, which occurs within the forward-pass upon each sequence.
訳すと
教師なし事前学習時、言語モデルの広範なスキルセットとパターン認識能力が発達する。そして、求められるタスクに迅速に適応したり、認識したりするために、これらの能力を推論時に利用される。このプロセスの内部ループを説明するために、“インコンテキスト学習” という用語を我々は使用する。このループは、各シーケンスにおけるフォワードパス中に発生する。
引用部分を図示したものが以下です。
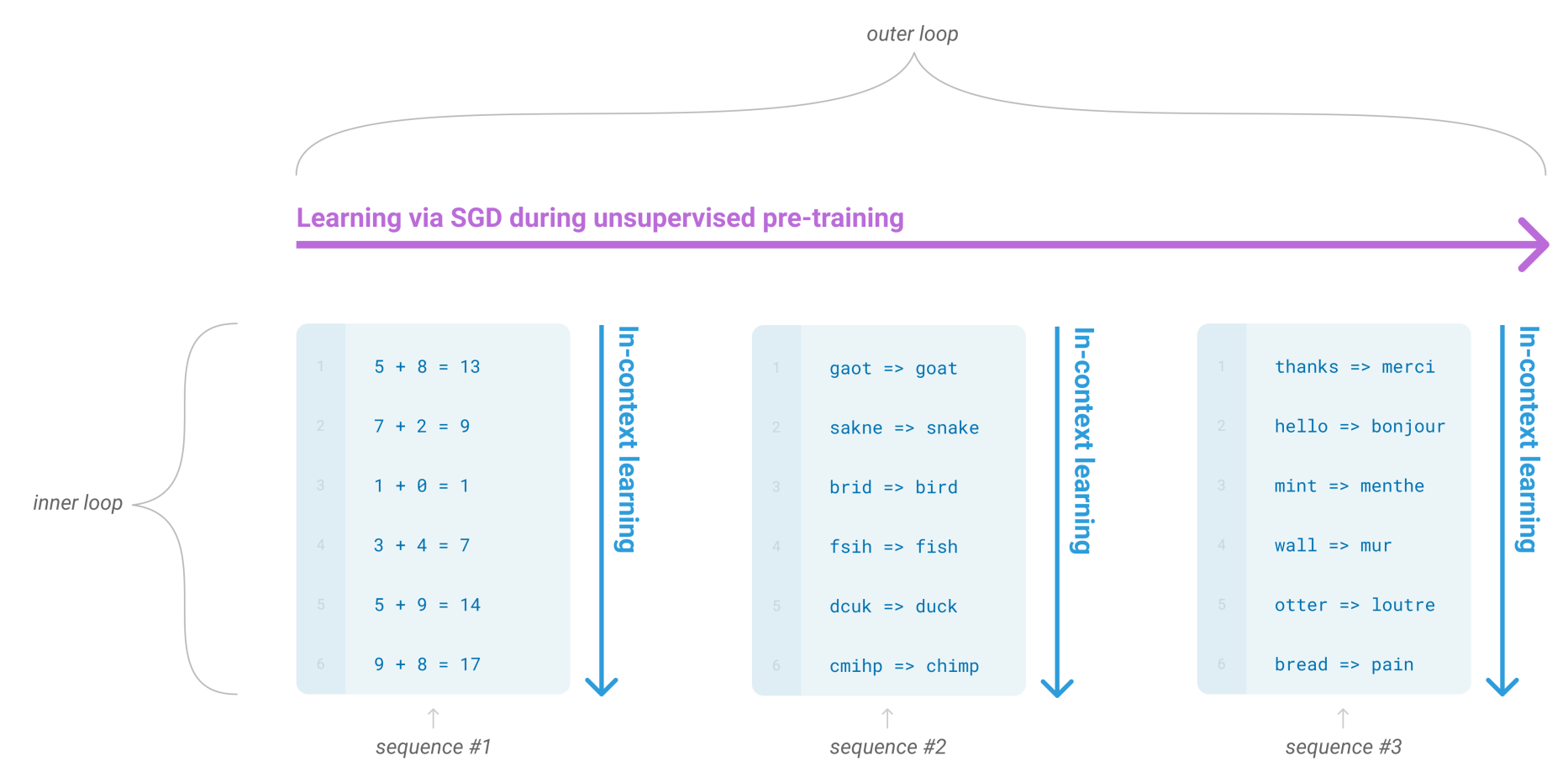
(出典:Language Models are Few-shot Learners)
わかったようなわからないようなという感じですが、Pre-training 時の 1 文章に含まれる「5+8=13, 7+2=9, ..., 9+8=17」のような内部ループを学習することで、規則的な文章からパターンを認識する能力を獲得することこそが In-context Learning と言えそうです。
(これは Pre-training 時の話なので、パラメータの更新が起きており、Learning と言われてもしっくりきます。)
つまり、「In-context Learning = Few-shot prompting」ではなく、「In-context learning によってできるようになることが Few-shot prompting 」ということです。
結論を 3 行で
- "In-context Learning" は、特に大規模な言語モデルにおける学習方法の一つで、モデルが与えられた入力のコンテキストに基づいて新しいタスクを理解し、適応する能力あるいはその能力を学習すること。
- モデルが以前に収集した知識やデータを活用して、特定の例や指示から学び、それに応じて適切な応答を生成することを目的にしている。
- In-context Learning によって Few-shot prompting ができるようになるのであって、狭義の意味では「In-context Learning = Few-shot prompting」は間違い。
というのが、私の中の解釈です。
以上です。皆さんなりの解釈あれば、コメントで教えてください。
ありがとうございました。