Cloudera Managerを使ってセットアップしたData CollectorのGUIからデータフローを作成します。
StreamSetsのドキュメントにあるチュートリアルに従って作ってみます。今回はBasic Tutorialのパイプラインを作ってみましょう。
https://streamsets.com/documentation/datacollector/latest/help/#Tutorial/Tutorial-title.html
テストデータのダウンロード
チュートリアルに従ってディレクトリを作成し、サンプルデータをダウンロードします。
[cloudera@quickstart ~]$ sudo mkdir /streamsets
[cloudera@quickstart ~]$ mkdir -p /streamsets/tutorial/origin
[cloudera@quickstart ~]$ mkdir -p /streamsets/tutorial/destination
[cloudera@quickstart ~]$ mkdir -p /streamsets/tutorial/error
[cloudera@quickstart ~]$ sudo chmod -R 777 /streamsets
[cloudera@quickstart ~]$ cd /streamsets/tutorial/origin/
[cloudera@quickstart origin]$ wget https://www.streamsets.com/documentation/datacollector/sample_data/tutorial/nyc_taxi_data.csv
--2016-07-20 01:56:40-- https://www.streamsets.com/documentation/datacollector/sample_data/tutorial/nyc_taxi_data.csv
Resolving www.streamsets.com... 162.242.235.205
Connecting to www.streamsets.com|162.242.235.205|:443... connected.
HTTP request sent, awaiting response... 301 Moved Permanently
Location: https://streamsets.com/documentation/datacollector/sample_data/tutorial/nyc_taxi_data.csv [following]
--2016-07-20 01:56:41-- https://streamsets.com/documentation/datacollector/sample_data/tutorial/nyc_taxi_data.csv
Resolving streamsets.com... 162.242.235.205
Connecting to streamsets.com|162.242.235.205|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1054132 (1.0M) [text/csv]
Saving to: “nyc_taxi_data.csv”
100%[======================================>] 1,054,132 828K/s in 1.2s
2016-07-20 01:56:43 (828 KB/s) - “nyc_taxi_data.csv” saved [1054132/1054132]
[cloudera@quickstart origin]$
基本チュートリアル
チュートリアルに従って進めていきます。
パイプラインの作成とパイプラインのプロパティの定義
まずはGUIからパイプラインを作成してみます。Data Collector の Web UIから「Create New Pipeline」をクリックします。
パイプラインの名前は Tutorial1 としてみました。

「Save」を押して保存すると、空のキャンバスが表示されます。

キャンバスの説明はドキュメントに書かれています。
https://streamsets.com/documentation/datacollector/latest/help/#Pipeline_Configuration/DataCollectorWindow-Config.html
Directory Origin を設定する
パイプラインの「入り口」に相当するのがOriginです。今回はダウンロードしたサンプルのCSVファイルがあるディレクトリをOriginにします。ドロップダウンメニューの「Select Origin」 -> 「Directory」を選択するか、右側のStage LibraryからDirectory Originを選びます。
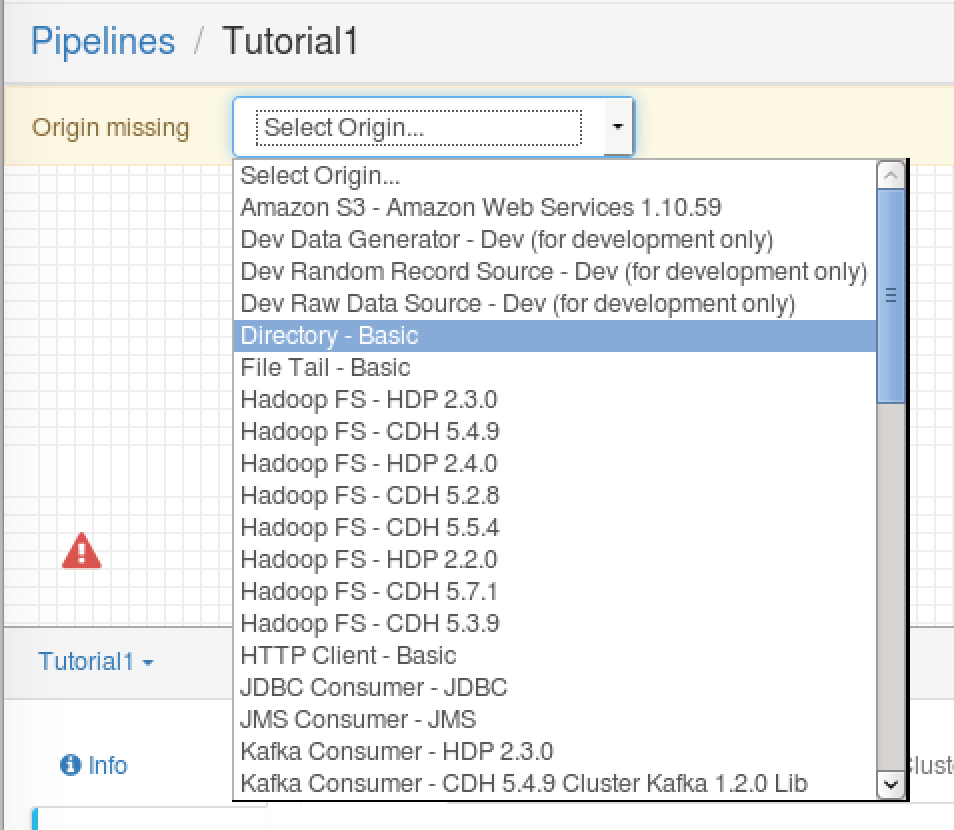

キャンバスに Directory Originが配置されました。アイコンをクリックし、下の画面からFilesタブをクリックし、次のパラメータを指定します。
- Data Format: Delimited
- Files Directory: /streamsets/tutorial/origin
- Read Order: Last Modified Timestamp
- File Name Pattern: taxi.csv
- First File to Process: 空のまま
Data FormatにDelimitedを指定するとDelimitedタブで詳細設定ができます。今回は以下のパラメータを指定します。
- File Type: Default CSV
- Header Line: With Header Line (CSVの先頭行にヘッダ行があるので)
- Root Field Type: List-Map
データのプレビュー
Originで登録したデータをプレビューしてみましょう。データが正しいかどうかをGUIから「見る」ことができるのは便利ですね。
チュートリアルによれば、この状態でPreviewアイコンをクリックできるようですが、手元の環境ではうまくいきませんでした。左側の❗️をクリックしてエラーを解決します。今回はCREATION_009というエラーが表示されています。

エラーデータの扱いを指定しなければならないようなので、まずは無視することにしました。
- Error Record: Discard (Libary Basic)
今度はPreviewアイコンがクリックできるようになっているので、クリックしてプレビューしましょう。


出力結果は以下のようになりました。CSVファイルの各列をリスト形式で表示しています。

テーブル形式でも表示できます!これ、CSVファイルをエディタなどで見る必要ないですし、ヘッダ行も表示してくれていますし、便利ですねぇ....

今回のチュートリアルでは、支払いタイプ(/payment_type)とクレジットカード情報(/credit_card)列を利用するようです。終わったら Close Preview アイコンをクリックします。

Stream Selector でデータの経路を作る
「Select Processor to Connect」->「Stream Selector」を選択します。

Stream Selector の General タブで、Required Fields テキストボックスを指定します。

今回は支払いの種類がないレコードをdiscardしたいので、以下の設定を行います。
- Required Fields: /payment_type
Conditionタブで条件を指定します。
条件により経路が変わります。今回は条件を満たしたデータ(支払いの種類がクレジットカード)が出力ストリーム(1)に流れていくことになります。満たさなかったデータは(2)に流れます。条件の指定の構文を覚える必要はありますが、自動補完が良くできているので、割とサクサク入力できる印象です。
- ${record:value('/payment_type')=='CRD'}

2系統の出力があることがわかりますね。
Jythonを使用してクレジットカードの種類を取得する
ストリーム中のクレジットカード情報のデータを扱うため、Jythonのスクリプトを使用します。「Select processor to connect」からJython Evaluator processorを追加します。

続いでJythonタブのスクリプトテキストボックスに、チュートリアルのJythonスクリプトを貼り付けます。

クレジットカード番号をマスクする
セキュリティ上、クレジットカード番号をそのまま利用するのは避けたいものです。Data Collectorにはマスクの機能もあるのでデータフローでカード番号をマスクします。先ほどと同様の手順で、キャンバスにField Maskerを追加します。以下のプロパティを指定し、正規表現を使ってマスクします。
- Mask Type: Regular Expression
- Regular Expression: (.*)([0-9]{4})
- Groups to Show: 2

Destination に書き込む
パイプラインの結果の出力先を指定します。チュートリアルではローカルファイルシステムになっていますが、せっかくのCloudera Manager管理しているHDFSがあるわけですから今回はHDFSを指定しようかと思ったのですが、Kerberos化していたの後日試すことにしました。「Select Destination to Connect」から「Hadoop FS - CDH5.7.1」を選択します。

Hadoop FS Propertyは、暫定的に書き込み先を file:///にします。
- Hadoop FS URI: file:///
- HDFS user: cloudera

Output Filesタブで以下のプロパティを指定します。
- Data Format: Delimited
- File Prefix: _out
- Directory Template: /streamsets/tutorial/destination
- Data Timezone: JST
Delimitedタブで以下のプロパティを設定します。
- Header Line: With Header Line
Expression Evaluatorで対応するフィールドを追加する
先ほどのJython Evaluatorではクレジットカード情報のデータを処理し、クレジットカードの種類を追加しています。ここでデータをプレビューしてみましょう。先ほどと同じように「Preview」をクリックし、Jython Evaluatorをクリックします。
入力データと出力データが表示されます。期待通り(?)、出力にはcredit_card_typeのデータが含まれていますね!

クレジットカード支払いでなかった場合も考慮する必要があるので、Stream Selectorのdefaultの出力に「Expression Evaluator」を追加します。

Expressionタブのプロパティを以下のように指定します。
- Output Field: n/a
- Header attributeは削除
終わったら、Expression EvaluatorとHadoop FSをつなぎます。

データルールとアラートの作成
さて、いよいよ最後です。Stream SelectorからJython Evaluatorの間の線をクリックしてルールを追加します。今回はクレジットカードデータがない(エラー)の場合のルールを追加をしています。
Data Ruleのプロパティ
- Label: Missing Card Numbers
- Condition: ${recod:value("/credit_card")==""}
- Sampling Percentage: 35
- Alert text: At least 10 missing credit card numbers!
- Threshold Value: 10
パイプラインを実行する
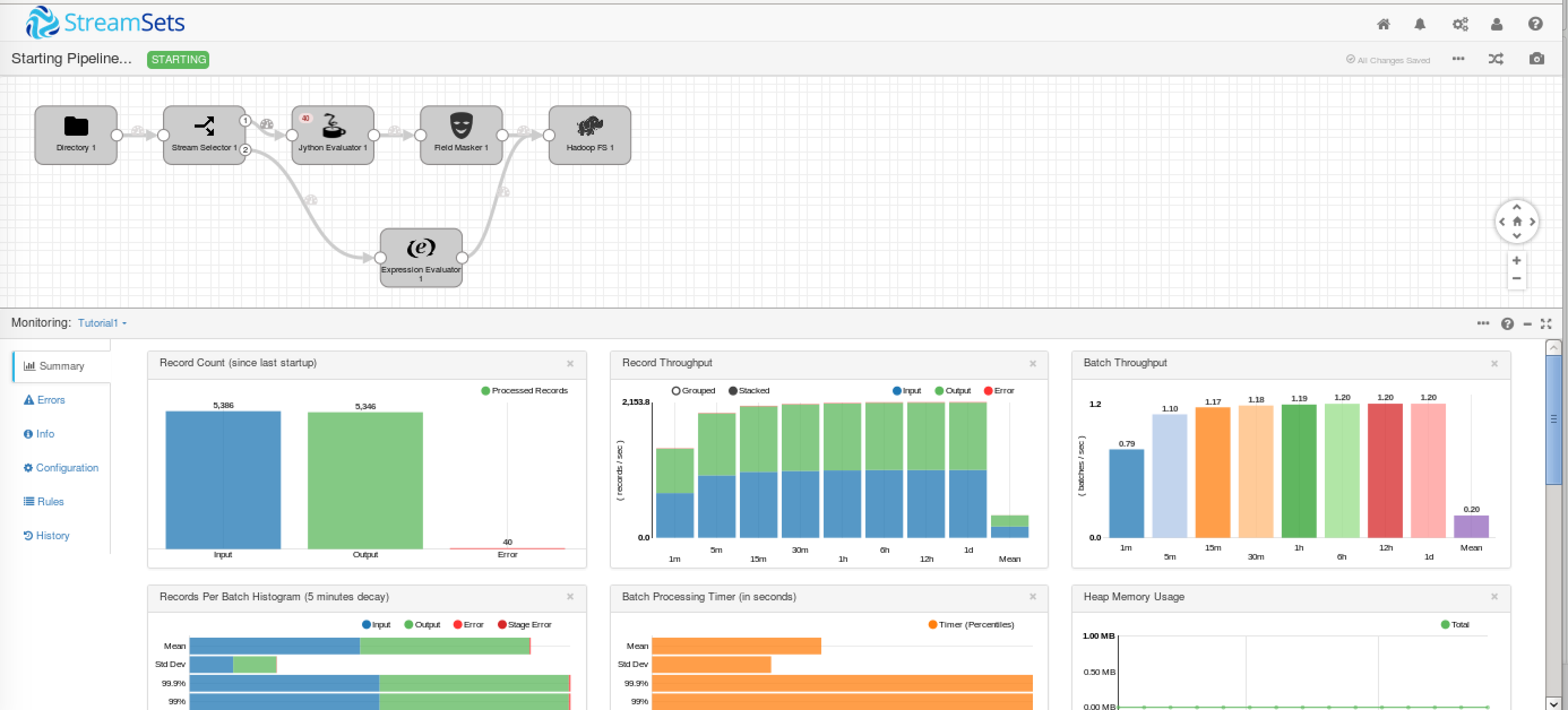
いよいよ実行です。▶︎のアイコンをクリックして実行します。

クレジットカードのエラーは40件のようです。

出力されたファイルも見てみましょう。クレジットカード番号はマスクされ、最後の列にカードの種類が出力されています。
[cloudera@quickstart origin]$ head /streamsets/tutorial/destination/_tmp__out
F6F7D02179BE915B23EF2DB57836442D,088879B44B80CC9ED43724776C539370,VTS,CRD,12,0.5,0.5,1.75,0,14.75,1,2013-01-13 04:36asdf,2013-01-13 04:46asdf,5,600,3.12,-73.996933,40.720055,-73.993546,40.693043,xxxxxxxxxxxx2922,Visa
BE386D8524FCD16B3727DCF0A32D9B25,4EB96EC9F3A42794DEE233EC8A2616CE,VTS,CRD,12,0.5,0.5,3.12,0,16.12,1,2013-01-13 04:37:00,2013-01-13 04:48:00,2,660,3.39,-74.000313,40.730068,-73.987373,40.768406,xxxxxxxxxxxx0902,MasterCard
E9FF471F36A91031FE5B6D6228674089,72E0B04464AD6513F6A613AABB04E701,VTS,CRD,5.5,0.5,0.5,1.2,0,7.7,1,2013-01-13 04:41:00,2013-01-13 04:45:00,1,240,1.16,-73.997292,40.720982,-74.000443,40.732376,xxxxxxxxxxxx9608,Visa
A5D125F5550BE7822FC6EE156E37733A,08DB3F9FCF01530D6F7E70EB88C3AE5B,VTS,CRD,11,0.5,0.5,2,0,14,1,2013-01-13 04:37:00,2013-01-13 04:47:00,5,600,2.91,-73.966843,40.756741,-73.987885,40.722713,xxxxxxxxxxxx7252,Visa
EE1513D432B07F7E0B5E2ED1EF629086,F31D261881520931062C011366E56A04,VTS,CRD,18,0.5,0.5,3.7,0,22.7,1,2013-01-13 04:30:00,2013-01-13 04:44:00,6,840,5.21,-74.005455,40.740772,-73.967354,40.798096,xxxxxxxxxxx7913,AMEX
まとめ
正直に言ってかなり使い易いと思います。HDFS、HBase、Kafka等、様々なエコシステムへのパイプラインを作成できるので、一度試してみてはいかがでしょうか?
おまけ
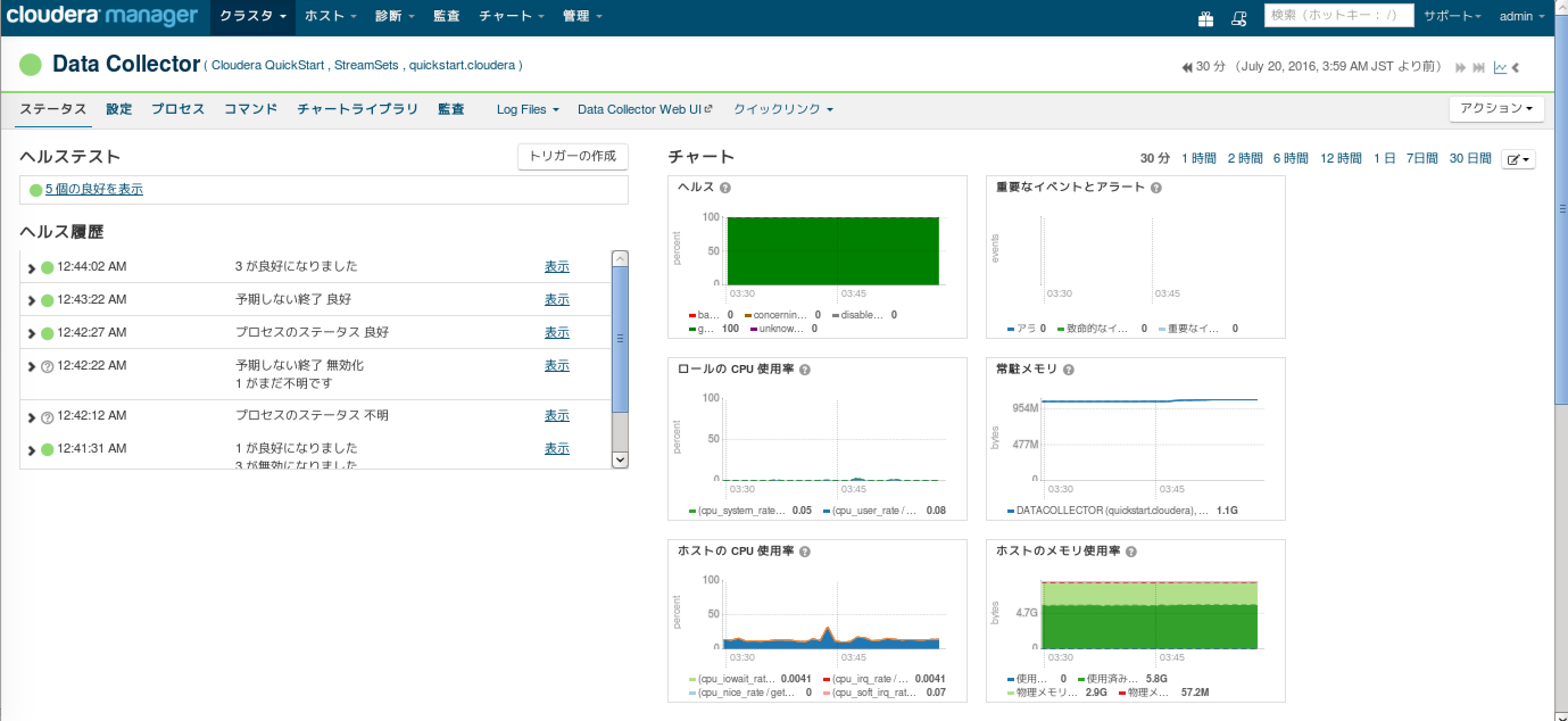
Cloudera ManagerでData Collectorのモニタリング