TL;DR
MacOSで使える神ランチャーアプリAlfredで、検索窓からlong 調べたい単語打てばLongman英和辞書(和英辞書)からスクレイピングで意味を引っ張ってきて、ブラウザで開かずとも単語の意味を検索できるようにした。
追記:上位互換
Longman英和

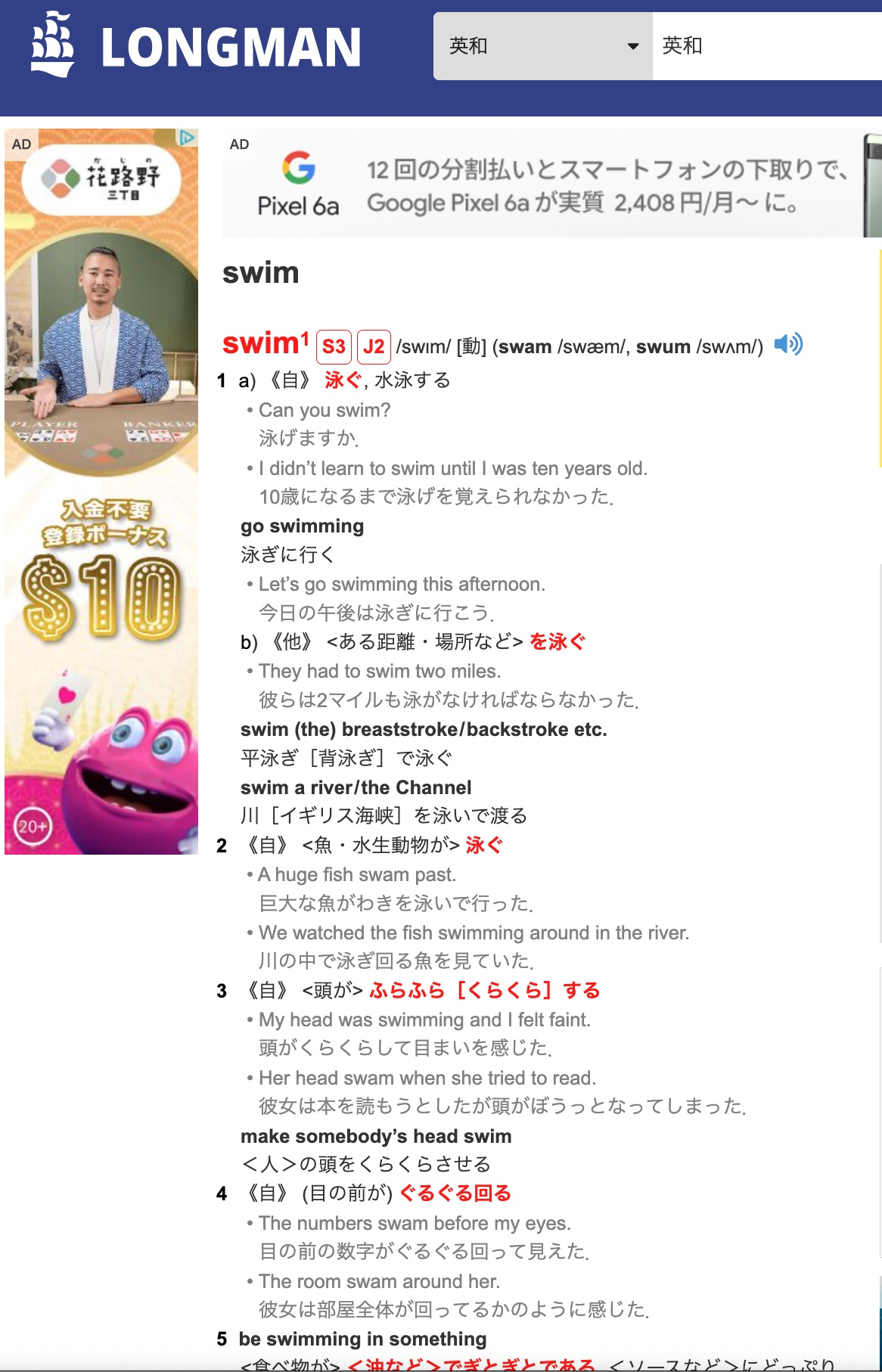
元のサイトはこんな感じ。
https://www.ldoceonline.com/jp/dictionary/english-japanese/swim
主な意味と例文を引っ張ってきている。見やすいように1文を一行に表示するようにしている。
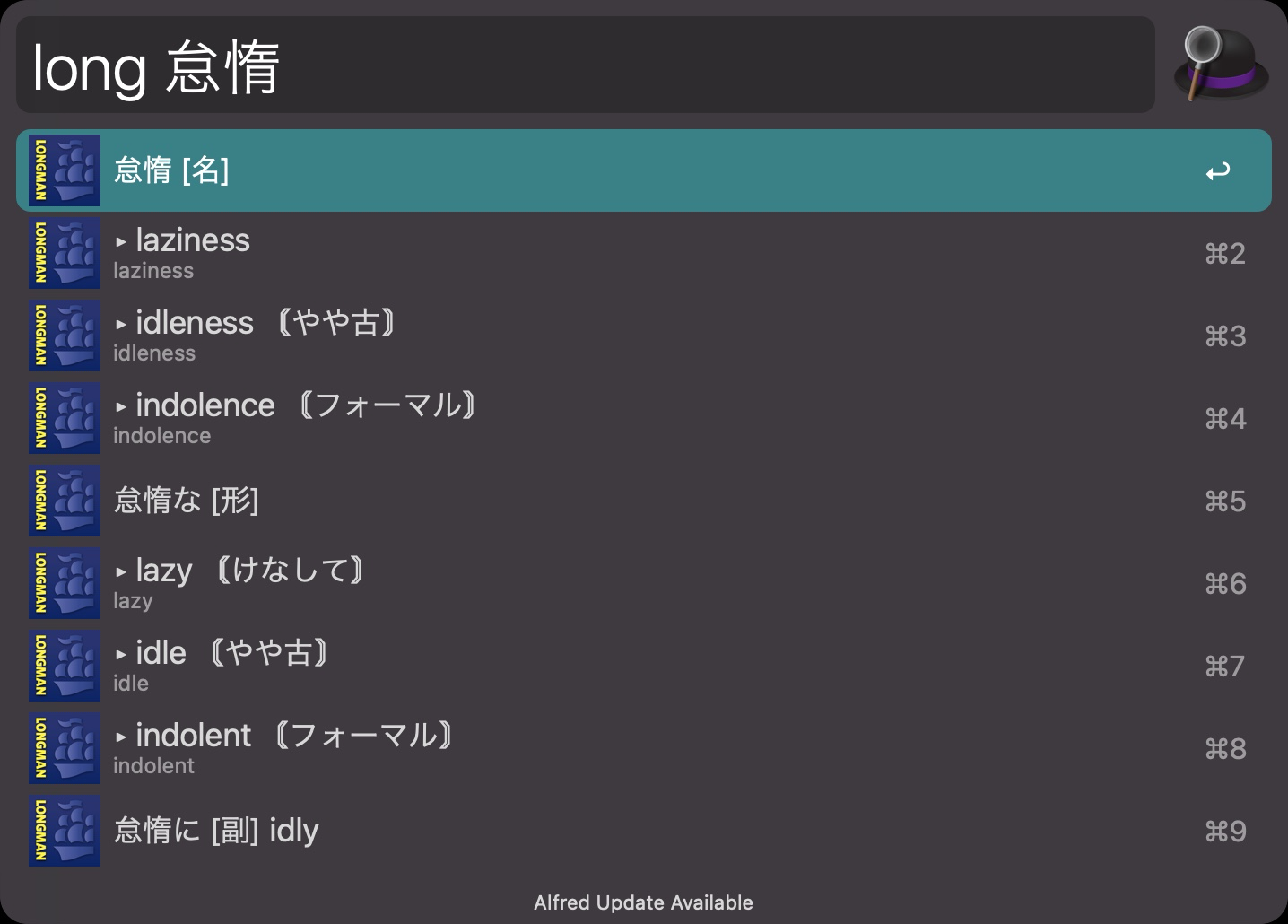
せっかくなので、和英にも対応させた。
Longman和英
Motivation
DeepL、Google翻訳、みらい翻訳などいろいろな翻訳サイトが出てきているが、結局単語の意味を知るには辞書がいちばん!
ということで、ウェブ上の辞書を使いたい。Weblioや英辞郎が有名だけどどれが良いの?と思っていたところ、Atsu英語さんがLongman英和最強!って言っていたので、ロングマンを使うことにした。
Source
# coding: utf-8
import requests
from bs4 import BeautifulSoup
import sys
import json
import sys
import re
def main(spell):
if onlyAlphabet(spell):
spell=spell.lower()
url = "https://www.ldoceonline.com/jp/dictionary/english-japanese/" + spell
else:
url = "https://www.ldoceonline.com/jp/dictionary/japanese-english/" + spell
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:92.0) Gecko/20100101 Firefox/92.0"
}
source = requests.get(url, headers=headers)
data = BeautifulSoup(source.content, "html.parser")
explanation_list = []
if data.select(".lejEntry"):#英和
if data.select(".Translation"):
for i in range(len(data.select(".Translation"))):
if data.select(".Translation")[i].select(".BOXTRAN.TRAN"):
continue
if data.select(".Translation")[i].select(".PRETRANCOM") or data.select(".Translation")[i].select(".COLL"):#丸括弧#とんがりかっこ
explanation_list.append(data.select(".Translation")[i].get_text())
continue
tmp=""
if data.select(".Translation")[i].select(".TRAN"):
for j in range(len(data.select(".Translation")[i].select(".TRAN"))):
tmp+=data.select(".Translation")[i].select(".TRAN")[j].get_text()
if tmp:
explanation_list.append(tmp)
if data.select(".ljeEntry"):#和英
if data.select(".Subentry"):
for i in range(len(data.select(".Subentry"))):
t = ""
if i == 0:
t+=data.select(".HWD")[0].get_text()
t+=data.select(".Subentry")[i].get_text()
explanation_list.append(t)
tao = explanation_list
result = ""
for idx, txt in enumerate(tao):
if idx < len(tao)-1:
tmp = tao[idx]
result += tmp.strip()+", "
else:
tmp = tao[idx]
result += tmp.strip()
result1 = []
for txt in tao:
result1.append(txt.strip())
if len(explanation_list) == 0:
return "(error) this word is not found"
return result1
def onlyAlphabet(text):
re_roman = re.compile(r'^[a-zA-Z\.]+$') #a-z:小文字、A-Z:大文字
return re_roman.fullmatch(text)
def onlyJa(text):
re_ja = re.compile(r'^[\u4E00-\u9FFF|\u3040-\u309F|\u30A0-\u30FF]{1,10}[\u4E00-\u9FFF|\u3040-\u309F|\u30A0-\u30FF]{1,10}$')
return re_ja.fullmatch(text)
if __name__ == '__main__':
spell = ' '.join(sys.argv[1:])
out = main(spell)
obj = []
if out == "(error) this word is not found":
tao = {
'title': "error",
'subtitle': "(error) This word is not found",
'arg': "error"
}
obj.append(tao)
else:
for idx,i in enumerate(out):
if onlyAlphabet(spell):
ken = i.split("• ")
else:
ken = i.split("‣")
if len(ken) > 1:
for idx,k in enumerate(ken):
if onlyAlphabet(spell):
if idx == 0:
tao = {
'title': ken[0],
'arg': k
}
else:
u=k.split(" ")
reibun_j=""
reibun_e=""
for i in u:
if onlyAlphabet(i):
reibun_e+=i
reibun_e+=" "
else:
reibun_j+=i
tao = {
'title': " ‣ "+reibun_e,
'subtitle': " "+reibun_j,
'arg': k
}
obj.append(tao)
else:
if " → See English-Japanese Dictionary" in k:
k=k.split(" → See English-Japanese Dictionary")[0]
if idx == 0:
tao = {
'title': ken[0],
}
else:
tao = {
'title': "‣ "+k[2:],
'subtitle': k[2:].split(" 〘")[0],
'arg': k[2:].split(" 〘")[0]
}
obj.append(tao)
else:
tao = {
'title': ken[0],
'arg': ken[0]
}
obj.append(tao)
jso = {'items': obj}
sys.stdout.write(json.dumps(jso, ensure_ascii=False))
How to install
最後に
Alfred最高!
https://www.alfredapp.com/ ←公式から買いましょう、57ドルです!(どんどん値上げしている?)
https://qiita.com/jackchuka/items/ccd3f66f6dd00481b98b