はじめに
自然言語処理の文書分類タスクでは、分散表現とCNNが相性が良く、論文やまとめサイトも良く見かけます。
KerasのデータセットにもSentiment Analysisで有名な「Movie Reviews」などがあらかじめ用意されており、
文書分類の手法を学ぶことができます。
ある文章のクラス分類について学習します。
今回は、アニメの主人公分類をやってみようと思います。
(既に似たことやっている人、いっぱいいますが・・)
例えば、アニメの主人公を当てるクイズの場合、
「エヴァに乗った少年」→「碇シンジ」、
「バスケットをしている不良少年」→「桜木花道」
「殺人事件によく遭遇する少年」→「江戸川コナン」
こんな風な連想をする方は多いと思います。
これって文章中の単語の特徴とその正解データを学習できれば、
簡単な予測がニューラルネットでも出来るかなって思いました。
1 コーパスの作成
まずは、コーパスを作らないことには始めれません。
アニメに関するデータを手っ取り早く入手するにはWikipediaが一番かと思います。
まずは、Wikipediaの内容をtextにまとめました。
やったことはankaji92さんの手法をほとんど同じなので割愛します。
2 学習データの作成
コーパスから必要な学習データを作ります。
今回、分類するアニメは下記の5つに限定します。
・うずまきナルト
・江戸川コナン
・碇シンジ
・桜木花道
・モンキー・D・ルフィ
有名なアニメの主人公でないと、Wikipediaに情報が少ないので、なるべく有名な主人公を選びました。
今回は、特徴量をその主人公に関する単語、正解を主人公という形式で表現します。
データセットはこんな感じです。
| no | 訓練データ | 正解ラベル |
|---|---|---|
| 1 | 火の国・木ノ葉隠れの里出身の忍者 | 0(うずまきナルト) |
| 2 | 東の高校生探偵 | 1(江戸川コナン) |
| 3 | エヴァンゲリオン初号機のパイロット | 2(碇シンジ) |
| 4 | 赤い髪が特徴 | 3(桜木花道) |
| 5 | 海賊「麦わらの一味」船長 | 4(モンキー・D・ルフィ) |
Wikipediaからデータを作る時、少し工夫をします。
Wikipediaのtxtは、
<doc id="257785" url="https://ja.wikipedia.org/wiki?curid=257785" title="うずまきナルト">
うずまきナルト
うずまきナルトは、岸本斉史作の漫画作品及びそれを原作としたアニメ『NARUTO -ナルト-』の主人公である架空の人物。・・・
</doc>
こんな感じになっています。
一つのtitleは、**<doc>~</doc>までです。
また、titleは「title="XXX"」**から特定できます。
このタグを利用して、txtに目的の主人公が出現したら、
・<doc id ...> 以降の内容は、主人公に関する文章(</doc>まで)
・title→正解ラベル
というルールを作ることで、学習データが作れます。
次に、文章を単語に分割します。
ここでは、形態素解析ツールmecabを利用しました。
また、アニメに関する用語は、新語・固有表現が多いので、「mecab-ipadic-NEologd」を使いました。
「mecab-ipadic-NEologd」の大まかな説明はここに載ってます。
ここまでくると、やっと上のデータセットのような学習データが出来上がります。
3 CNNで学習
今回は自然言語処理の文書分類タスクとしてCNNにより学習します。
こちらで詳しく解説されております。
CNNのテキスト分類に関する論文によると、CNNは局所的な位置の隠れた特徴を抽出することに優れているので、単語の位置や並びが重要となるテキスト分類で高精度が期待できるみたいです。
単語を入力とするCNNのモデルですが、下記が分かりやすいです。
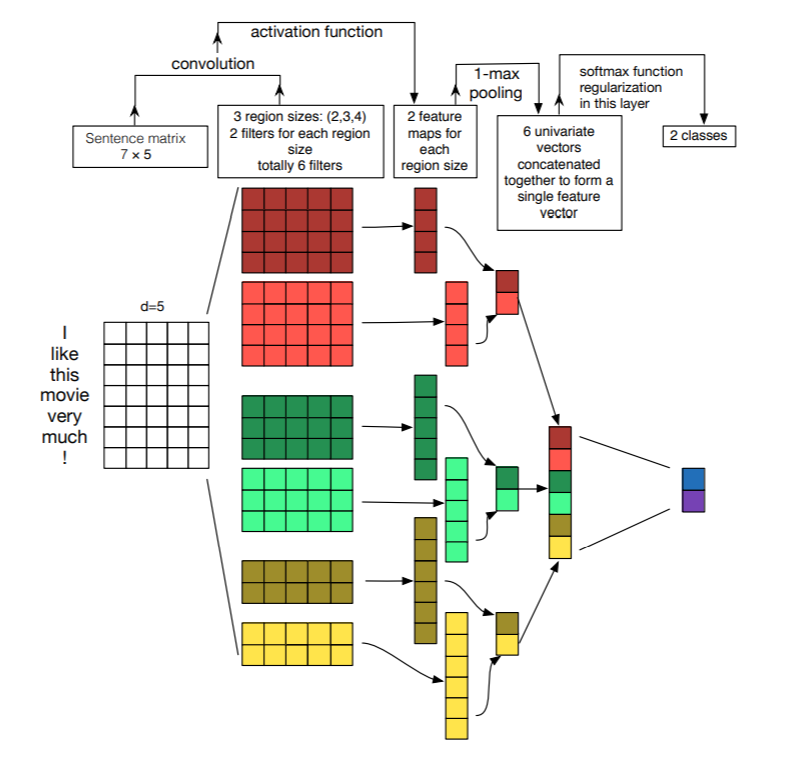
A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification より引用
モデルの構築は下記のとおりです。(よくあるCNNのモデルです。)
# set parameters:
batch_size = 16
embedding_dims = 128
filters = 64
kernel_size = 3
hidden_dims = 250
epochs = 10
num_classes = 5
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1,
output_dim=embedding_dims,
input_length=maxlen))
model.add(Conv1D(filters,
kernel_size,
padding='same',
activation='relu',
strides=1))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(hidden_dims))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print model.summary()
callbacks = [CSVLogger("CNN_history.csv")]
model.fit(data, label,
batch_size=batch_size,
epochs=epochs,
callbacks=callbacks)
4 学習結果
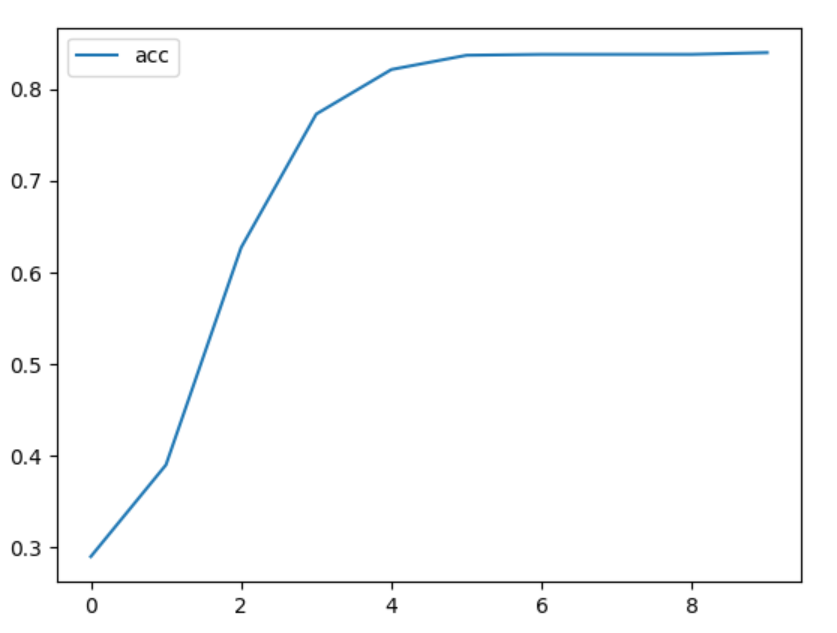
良い感じで学習できました。
loss,accともに5回目あたりで飽和しています。
※今回は学習データのみで過学習については考慮していません。。

5 予測
最後に適当な文章をモデルに与えて、妥当な分類が出来るか確認します。
| no | 文章 | うずまきナルト | 江戸川コナン | 碇シンジ | 桜木花道 | モンキー・D・ルフィ |
|---|---|---|---|---|---|---|
| 1 | 殺人事件に遭遇する探偵少年 | 0.00466 | 0.98292 | 0.00008 | 0.00005 | 0.0123 |
| 2 | バスケットをする不良少年 | 0.01071 | 0.01105 | 0.15661 | 0.68089 | 0.14074 |
| 3 | 苦悩や葛藤 | 0.39589 | 0.11653 | 0.3701 | 0.0441 | 0.07338 |
| 4 | 友達 | 0.15838 | 0.22617 | 0.15373 | 0.11756 | 0.34417 |
| 5 | 成長 | 0.18589 | 0.19391 | 0.23258 | 0.21027 | 0.17734 |
良い感じですね。
1,2は特定の主人公(アニメ)を指す文章にしました。
なので、確率も高い値となっています。
3,4,5は抽象的な文章にしました。
「うずまきナルト」・「碇シンジ」は苦悩・葛藤していますね。
逆に「桜木花道」は苦悩・葛藤とは遠い人物ですね。
(実際は作中で何回は悩んでいるとは思いますが・・)
やっぱり「友達」に関する確率が最も高いのは、「ルフィ」ですね。
友情や仲間の絆が描かれている作品なので納得です。
意外と「コナン」の値も高いです。
これは、「少年探偵団」のおかげかと思います。
最後に「成長」という単語に関してです。
どの作品も「成長」に関する要素はあると思いますが、「碇シンジ」が最も高い確率となりました。
エヴァンゲリオンを通して、彼は成長していったので納得です。
こんな感じで割と納得のいく分類をしてくれました。
さいごに
今回は、Wikipediaを使って文章がどのアニメの主人公っぽいかを分類しました。
コーパスはWikipedia内のアニメに関するものだけでなので、あまり汎用的ではありません。
また、汎化性能なども一切考慮していないので、めちゃ過学習の状態だと思います。
それでも、CNNによるテキスト分類の勉強には良かったと思います。
あと、今回のソースは、以下にまとめました。
https://github.com/kento1109/repo/tree/master/source/toy/anime