データ分析をしてタイタニック号の生存者を予測する
はじめに
この記事ではPythonを用いて、Kaggleのチュートリアルとして有名なTitanicの生存者予測問題をに挑戦していきたいと思います。
Kaggleとは、世界中の機械学習・データサイエンスに携わっている約40万人の方が集まるコミニティーです。企業や政府が競争形式で課題を提示し、賞金と引き換えに最も制度の高い分析モデルを買い取る「Competetion(コンペ)」というクラウドファウンディングのようなものを開催しているのがKaggleの特徴です。
参考記事 - Kaggleとは?機械学習初心者が知っておくべき3つの使い方
簡単に言えば、タイタニック号の乗客情報から船の沈没後にその人が生き残ったのか或いは亡くなってしまったのかを予測していきます。
事前準備
GoogleColabを使っていきます。また、anaconda環境がある人はJupyter Notebookで実行すると良いと思います。
目次
1.タイタニックのデータセットを取得
2.データの前処理
3.トレーニングデータとテストデータに分ける
4.モデルの学習
5.モデルの評価
1.タイタニックのデータセットを取得
from sklearn import datasets
X, y = datasets.fetch_openml(data_id=40945, return_X_y=True, as_frame=True)
sklearnとは統計学、パターン認識、データ解析の技法が豊富に使うことができるライブラリです。
datasets.fetch_openml
でデータのidを指定することで外部のデータセット(Titanicの顧客データ)をとってくることができます。
また、
return_X_y=True
と記述することでdataとtarget(答え)を直接取得できます。つまりXにはこれから予測を行うためのデータ、yにはその人が生き延びることができたか、もしくは死んでしまったかの答えの情報が入っているということです。
as_frame=True
は、データをDataFrame(pandas)で取得するための記述です。これを書かないとDataFrameではなくndarray(numpy)で取得してしまうため、後述して行く内容にある情報の加工ができなくなってしまいます。
そもそも今扱っているTitanicのデータでは配列データは用意されていませんのでエラーが出てきてしまいます。
何が違うのか気になる方は
data=sklearn.datasets.load_iris(return_X_y=True,as_frame=(ここをTrueとFalseにしてみよう!))
data
をColabにコピペして確認してみると違いがわかると思います。(titanicとは違うデータです!)
Xとyにはそれぞれdataとtarget(答え)が入っている
2.データの前処理
これからがデータを扱いやすい(計算しやすい)ようにちょっと加工をしていきます。
X
とだけ打つと加工前のデータを確認できます。(colabやJupyter Notebookでは、コードの最後に変数名を書いておくことでprint関数を使わずに変数の中身を出力することができます。)
1309人の顧客情報をみることができたでしょうか?
たくさん情報があって分かりにくいですから一旦項目をまとめておきます。
-
情報項目
・PassengerId – 乗客識別ユニークID
・Pclass – チケットクラス(1 = 上層クラス(お金持ち)、2 = 中級クラス(一般階級)、3 = 下層クラス(労働階級))
・Name – 乗客の名前
・Sex – 性別(male=男性、female=女性)
・Age – 年齢
・SibSp – タイタニックに同乗している兄弟/配偶者の数
・parch – タイタニックに同乗している親/子供の数
・ticket – チケット番号
・fare – 料金
・cabin – 客室番号
・Embarked – 出港地(タイタニックへ乗った港)、(C = Cherbourg、Q = Queenstown、S = Southampton)
・boat – 救命ボート番号
・body – 遺体収容時の識別番号
・home.dest – 自宅または目的地
ではこれからデータを処理します。
流れは以下です。
①欠損値のある項目を洗い出し、その数を知る
②欠損値を補填する
③文字列データを数値化する
①欠損値のある項目を洗い出し、その数を知る
X.isnull()
で各項目、欠損している場合trueそうでない場合false が返ってきます。
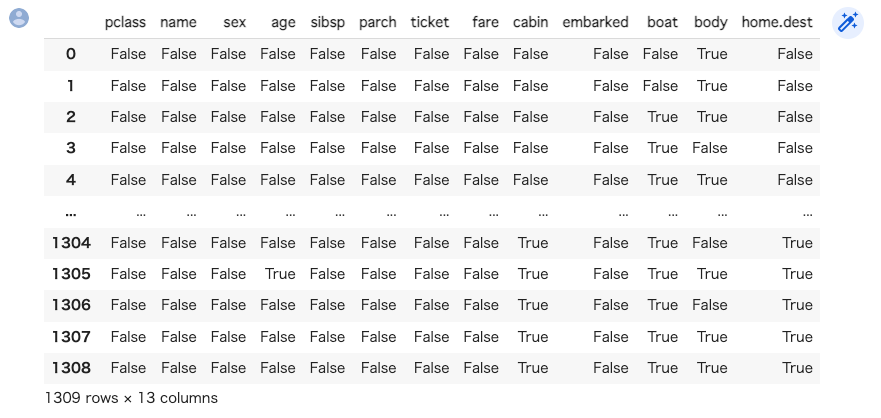
しかしこれではデータが多いためとても見づらいですね。
X.isnull().sum()
を実行します。
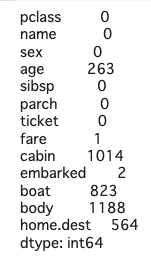
これでどの項目がどのくらい欠損しているのかがわかりました。
データ.isnull().sum() で項目ごとの欠損値の合計がわかる
②欠損値を補填する
age は生存するかどうかに大きく影響してきそうな値です。これは補填する必要があるのでageの中央値で補填します。
またembarkedにも一つ欠損がありますから、1番多い値のSで補填します。
X["age"]=X["age"].fillna((X["age"].median())) #ageを中央値に補填
X["embarked"]=X["embarked"].fillna("S") #embarkedは1番を多いSを補填
X.isnull().sum()
実行結果

ageとembarkedの欠損値が0になりました。
③文字列データを数値化する
データを見ると数値ではなく、maleやfemale、SやCなど文字列の値があります。文字列のデータは解析できないため、数値に変換します。そのためにはまずデータ解析ライブラリPandasを読み込みます。
import pandas as pd
pd.get_dummies()
性別データは男女の二択なので、先頭のデータと同じかそうでないかで0, 1を入れます。
X["sex"] = pd.get_dummies(X["sex"])
X
は引数にデータを取ります。
文字列でカテゴリー分けされたデータを数字の情報にすることで、コンピュータが計算をしやすくするために使います。
実行結果

0と1に変換されていることがわかりますね!
embarkedはC,Q,Sの三択なので、それぞれを分解して、Cであるかそうでないか、Qであるかそうでないか、Sであるかそうでないかという情報を0, 1に変換します。
X = pd.concat([X, pd.get_dummies(X["embarked"])], axis=1)
X
実行結果

pd.concat()
はpd.concat([data_1,data_2,data_3,...,data_n]) という使い方をします。
これで何ができるのかというと、なんとデータを結合することができます。
つまり、Xとpd.get_dummies(X["embarked"]) をつなげているのです。
pd.get_dummies(X["embarked"])
は先程やったように文字列を数字に変換してくれますから、実行結果はC,Q,Sごとに追加されています。
は0なら縦方向の結合、1なら横方向の結合となります。
sexとembarkedのデータを数値にすることができました。 また、今回使用しないデータはここで除外しておきます。
feature_columns =["name", "sibsp", "parch", "ticket", "fare", "cabin","embarked", "boat", "body", "home.dest"]
X = X.drop(columns=feature_columns, axis=1)
実行結果
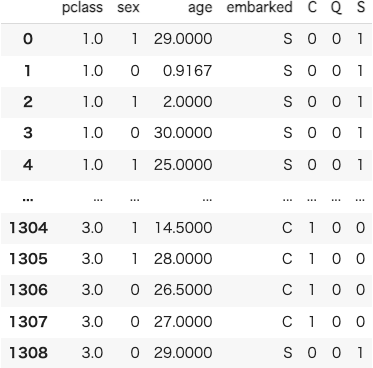
これで今回は使わない情報を除去することができました!
y=y.astype(int)
と書くことで答えのデータを数値データ変換しておきましょう。
pd.get_dummies() で文字列を数字に変換することができる
pd.concat([data_1,data_2,data_3,...,data_n]) でデータを結合することができる
3.トレーニングデータとテストデータに分ける
教師あり学習をするので、トレーニングデータ(学習用データ)とテストデータ(検証用データ)に分けます。 学習用データはモデルを学習させ、検証用データはモデルの精度を測るために使用します。 今回は全データの30%を検証用のデータとしてみましょう。
from sklearn.model_selection import train_test_split
seed=0
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=seed)
from sklearn.model_selection import train_test_split
scikit-learnのtrain_test_split()関数を使います。この関数はNumpy配列ndarrayやリスト、DataFrameなどを分けることが可能で、機械学習においてデータを学習用とテスト用に分割して検証を行う際に用います。
train_test_split(X, y, test_size=0.3, random_state=seed)
まずtrain_test_split() の使い方を説明します。
これは引数のデータが1つだった場合は2つの分けられたデータを返します。そのため、2つの変数に代入する必要があります。
例えば、天気のデータをtrainとtestに分けるとすると
train_weather,test_weather = train_test_split(weather_data)
のようになりますね。
しかし今はXとyの2つのデータをtrain_test_split()に渡しているため、当然返ってくる値も4つになりますからtrain_X, test_X, train_y, test_y という4つの変数を用意する必要があるわけです。
test_size=0.3, random_state=seed
前者はテストデータを全データの30%とすることを意味し、後者は乱数シードを固定することを意味しています。どのように分割されるかによって結果が異なってしまうため、乱数シードを固定して常に同じように分割されるようにする必要があるのです。
4. モデルの学習
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(train_X, train_y)
今までの処理でデータは揃いました。
これから何をするのかと言うと、決定木を使ってモデルを構築していきます。
決定木とは
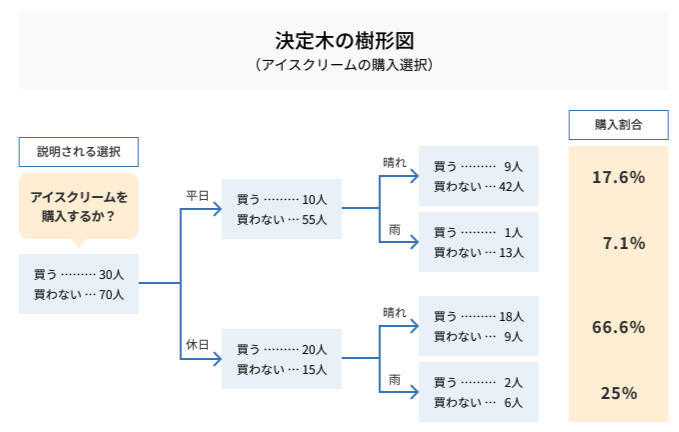
みたいな感じです。
これをPythonは便利なライブラリが
tree_model.fit(train_X, train_y)
と書くだけでが全部やってくれます。
5.モデルの評価
import sklearn.metrics as metrics
pred_X = tree_model.predict(test_X)
metrics.accuracy_score(test_y, pred_X)
pred_X = tree_model.predict(test_X)
predict() は引数にデータを取り、その引数に対して予測値(ここで言うと生存したか否か)を戻り値として返します。
metrics.accuracy_score(test_y, pred_X)
accuracy_score() は第一引数と第二引数と比べた時の正答率を出力してくれます。
ここで言うと、test_yと言う答えとpred_Xと言う予測値を比べて正答率を出しています。
上のコードを実行したら正答率が表示されたでしょうか?
今回使ったコード全文(途中でエラーが出たら一旦これを貼り付けて実行してみてください。)
from sklearn import datasets
X, y = datasets.fetch_openml(data_id=40945, return_X_y=True, as_frame=True)
X["age"]=X["age"].fillna((X["age"].median())) #ageを中央値に補填
X["embarked"]=X["embarked"].fillna("S") #embarkedは1番を多いSを補填
import pandas as pd
X["sex"] = pd.get_dummies(X["sex"])
X = pd.concat([X, pd.get_dummies(X["embarked"])], axis=1)
feature_columns =["name", "sibsp", "parch", "ticket", "fare", "cabin", "embarked","boat", "body", "home.dest"]
X = X.drop(columns=feature_columns, axis=1)
from sklearn.model_selection import train_test_split
seed=0
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.3, random_state=seed)
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier()
tree_model.fit(train_X, train_y)
import sklearn.metrics as metrics
pred_X = tree_model.predict(test_X)
metrics.accuracy_score(test_y, pred_X)
終わりに
今回はPythonを使ってデータ分析の初歩的なものを扱いました。
このほかにもTitanic生存者予測問題にはいろいろな手法によるアプローチがあります。中には正解率100%なんて猛者もいます!
Titanicのほかにもチュートリアルの問題はあるので自分の好きな問題にチャレンジしてみるのもいいと思います。
皆さんがデータ分析へ興味を持ってくれる第一歩になれば嬉しいです。