tldr
KggleのMarvel vs DCをMarvel or DC??? - Data Every Day #035に沿ってやっていきます。
実行環境はGoogle Colaboratorです。
インポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.preprocessing as sp
from sklearn.model_selection import train_test_split
import sklearn.linear_model as slm
import tensorflow as tf
データのダウンロード
Google Driveをマウントします。
from google.colab import drive
drive.mount('/content/drive')
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
KaggleのAPIクライアントを初期化し、認証します。
認証情報はGoogle Drive内(/content/drive/My Drive/Colab Notebooks/Kaggle)にkaggle.jsonとして置いてあります。
import os
kaggle_path = "/content/drive/My Drive/Colab Notebooks/Kaggle"
os.environ['KAGGLE_CONFIG_DIR'] = kaggle_path
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
Kaggle APIを使ってデータをダウンロードします。
dataset_id = 'leonardopena/marvel-vs-dc'
dataset = api.dataset_list_files(dataset_id)
file_name = dataset.files[0].name
file_path = os.path.join(api.get_default_download_dir(), file_name)
file_path
Warning: Looks like you're using an outdated API Version, please consider updating (server 1.5.10 / client 1.5.9)
'/content/db.csv'
api.dataset_download_file(dataset_id, file_name, force=True, quiet=False)
100%|██████████| 3.70k/3.70k [00:00<00:00, 1.02MB/s]
Downloading db.csv to /content
True
データの読み込み
Padasを使ってダウンロードしてきたCSVファイルを読み込みます。
data = pd.read_csv(file_path, encoding='latin-1')
data
| Unnamed: 0 | Original Title | Company | Rate | Metascore | Minutes | Release | Budget | Opening Weekend USA | Gross USA | Gross Worldwide | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Iron Man | Marvel | 7.9 | 79 | 126 | 2008 | 140000000 | 98618668 | 318604126 | 585366247 |
| 1 | 2 | The Incredible Hulk | Marvel | 6.7 | 61 | 112 | 2008 | 150000000 | 55414050 | 134806913 | 263427551 |
| 2 | 3 | Iron Man 2 | Marvel | 7.0 | 57 | 124 | 2010 | 200000000 | 128122480 | 312433331 | 623933331 |
| 3 | 4 | Thor | Marvel | 7.0 | 57 | 115 | 2011 | 150000000 | 65723338 | 181030624 | 449326618 |
| 4 | 5 | Captain America: The First Avenger | Marvel | 6.9 | 66 | 124 | 2011 | 140000000 | 65058524 | 176654505 | 370569774 |
| 5 | 6 | The Avengers | Marvel | 8.0 | 69 | 143 | 2012 | 220000000 | 207438708 | 623357910 | 1518812988 |
| 6 | 7 | Iron Man Three | Marvel | 7.2 | 62 | 130 | 2013 | 200000000 | 174144585 | 409013994 | 1214811252 |
| 7 | 8 | Thor: The Dark World | Marvel | 6.9 | 54 | 112 | 2013 | 170000000 | 85737841 | 206362140 | 644783140 |
| 8 | 9 | Captain America: The Winter Soldier | Marvel | 7.7 | 70 | 136 | 2014 | 170000000 | 95023721 | 259766572 | 714421503 |
| 9 | 10 | Guardians of the Galaxy | Marvel | 8.0 | 76 | 121 | 2014 | 170000000 | 94320883 | 333176600 | 772776600 |
| 10 | 11 | Avengers: Age of Ultron | Marvel | 7.3 | 66 | 141 | 2015 | 250000000 | 191271109 | 459005868 | 1402805868 |
| 11 | 12 | Ant-Man | Marvel | 7.3 | 64 | 117 | 2015 | 130000000 | 57225526 | 180202163 | 519311965 |
| 12 | 13 | Captain America: Civil War | Marvel | 7.8 | 75 | 147 | 2016 | 250000000 | 179139142 | 408084349 | 1153296293 |
| 13 | 14 | Doctor Strange | Marvel | 7.5 | 72 | 115 | 2016 | 165000000 | 85058311 | 232641920 | 677718395 |
| 14 | 15 | Guardians of the Galaxy Vol. 2 | Marvel | 7.6 | 67 | 136 | 2017 | 200000000 | 146510104 | 389813101 | 863756051 |
| 15 | 16 | Spider-Man: Homecoming | Marvel | 7.4 | 73 | 133 | 2017 | 175000000 | 117027503 | 334201140 | 880166924 |
| 16 | 17 | Thor:Ragnarok | Marvel | 7.9 | 74 | 130 | 2017 | 180000000 | 122744989 | 315058289 | 853977126 |
| 17 | 18 | Black Panther | Marvel | 7.3 | 88 | 134 | 2018 | 200000000 | 202003951 | 700059566 | 1346913161 |
| 18 | 19 | Avengers: Infinity War | Marvel | 8.5 | 68 | 149 | 2018 | 321000000 | 257698183 | 678815482 | 2048359754 |
| 19 | 20 | Ant-Man and the Wasp | Marvel | 7.1 | 70 | 118 | 2018 | 162000000 | 75812205 | 216648740 | 622674139 |
| 20 | 21 | Captain Marve | Marvel | 6.9 | 64 | 123 | 2019 | 175000000 | 153433423 | 426829839 | 1128274794 |
| 21 | 22 | Avengers: Endgame | Marvel | 8.5 | 78 | 181 | 2019 | 356000000 | 357115007 | 858373000 | 2797800564 |
| 22 | 23 | Spider-Man: Far from Home | Marvel | 7.6 | 69 | 129 | 2019 | 160000000 | 92579212 | 390532085 | 1131927996 |
| 23 | 24 | Catwoman | DC | 3.3 | 27 | 104 | 2004 | 100000000 | 16728411 | 40202379 | 82102379 |
| 24 | 25 | Batman Begins | DC | 8.2 | 70 | 140 | 2005 | 150000000 | 48745440 | 206852432 | 373413297 |
| 25 | 26 | Superman Returns | DC | 6.0 | 72 | 154 | 2006 | 270000000 | 52535096 | 200081192 | 391081192 |
| 26 | 27 | The Dark Knight | DC | 9.0 | 84 | 152 | 2008 | 185000000 | 158411483 | 535234033 | 1004934033 |
| 27 | 28 | Watchmen | DC | 7.6 | 56 | 162 | 2009 | 130000000 | 55214334 | 107509799 | 185258983 |
| 28 | 29 | Jonah Hex | DC | 4.7 | 33 | 81 | 2010 | 47000000 | 5379365 | 10547117 | 10903312 |
| 29 | 30 | Green Lantern | DC | 5.5 | 39 | 114 | 2011 | 200000000 | 53174303 | 116601172 | 219851172 |
| 30 | 31 | The Dark Knight Rises | DC | 8.4 | 78 | 164 | 2012 | 250000000 | 160887295 | 448139099 | 1081041287 |
| 31 | 32 | Man of Steel | DC | 7.1 | 55 | 143 | 2013 | 225000000 | 116619362 | 291045518 | 668045518 |
| 32 | 33 | Batman v Superman: Dawn of Justice | DC | 6.5 | 44 | 151 | 2016 | 250000000 | 166007347 | 330360194 | 873634919 |
| 33 | 34 | Suicide Squad | DC | 6.0 | 40 | 123 | 2016 | 175000000 | 133682248 | 325100054 | 746846894 |
| 34 | 35 | Wonder Woman | DC | 7.4 | 76 | 141 | 2017 | 149000000 | 103251471 | 412563408 | 821847012 |
| 35 | 36 | Justice League | DC | 6.4 | 45 | 120 | 2017 | 300000000 | 93842239 | 229024295 | 657924295 |
| 36 | 37 | Aquaman | DC | 7.0 | 55 | 143 | 2018 | 160000000 | 67873522 | 335061807 | 1148161807 |
| 37 | 38 | Shazam! | DC | 7.1 | 71 | 132 | 2019 | 100000000 | 53505326 | 140371656 | 364571656 |
| 38 | 39 | Joker | DC | 8.7 | 59 | 122 | 2019 | 55000000 | 96202337 | 333204580 | 1060504580 |
下準備
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 39 entries, 0 to 38
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 39 non-null int64
1 Original Title 39 non-null object
2 Company 39 non-null object
3 Rate 39 non-null float64
4 Metascore 39 non-null int64
5 Minutes 39 non-null object
6 Release 39 non-null int64
7 Budget 39 non-null object
8 Opening Weekend USA 39 non-null int64
9 Gross USA 39 non-null int64
10 Gross Worldwide 39 non-null int64
dtypes: float64(1), int64(6), object(4)
memory usage: 3.5+ KB
不要な列の削除
data = data.drop(['Unnamed: 0', 'Original Title'], axis=1)
エンコード
encoder = sp.LabelEncoder()
data['Company'] = encoder.fit_transform(data['Company'])
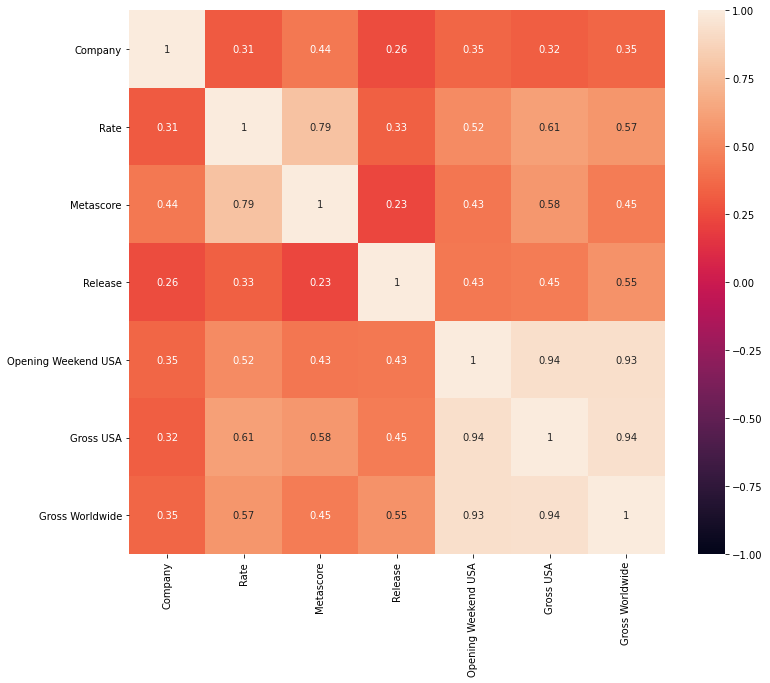
可視化
data['Company'] = encoder.fit_transform(data['Company'])
plt.figure(figsize=(12, 10))
sns.heatmap(data.corr(), annot=True, vmax=1, vmin=-1)
plt.show()
スケーリングとデータの分割
y = data['Company']
X = data.drop('Company', axis=1)
スケーリング
scaler = sp.StandardScaler()
X = scaler.fit_transform(X)
分割
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7)
トレーニング
model = slm.LogisticRegression()
model.fit(X_train, y_train)
model.score(X_test, y_test)
0.8333333333333334
同じモデルで何回かトレーニングしてみましたが、かなり精度に差がありました。
データが少ないからしょうがないかなー