tldr
KggleのAGE, GENDER AND ETHNICITY (FACE DATA) CSVをFace Image Classification - Data Every Day #042に沿ってやっていきます。
実行環境はGoogle Colaboratorです。
インポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn.preprocessing as sp
from sklearn.model_selection import train_test_split
import sklearn.linear_model as slm
import tensorflow as tf
データのダウンロード
Google Driveをマウントします。
from google.colab import drive
drive.mount('/content/drive')
Mounted at /content/drive
KaggleのAPIクライアントを初期化し、認証します。
認証情報はGoogle Drive内(/content/drive/My Drive/Colab Notebooks/Kaggle)にkaggle.jsonとして置いてあります。
import os
kaggle_path = "/content/drive/My Drive/Colab Notebooks/Kaggle"
os.environ['KAGGLE_CONFIG_DIR'] = kaggle_path
from kaggle.api.kaggle_api_extended import KaggleApi
api = KaggleApi()
api.authenticate()
Kaggle APIを使ってデータをダウンロードします。
dataset_id = 'nipunarora8/age-gender-and-ethnicity-face-data-csv'
dataset = api.dataset_list_files(dataset_id)
file_name = dataset.files[0].name
file_path = os.path.join(api.get_default_download_dir(), file_name)
file_path
'/content/age_gender.csv'
api.dataset_download_file(dataset_id, file_name, force=True, quiet=False)
8%|▊ | 5.00M/63.2M [00:00<00:01, 30.9MB/s]
Downloading age_gender.csv.zip to /content
100%|██████████| 63.2M/63.2M [00:00<00:00, 83.8MB/s]
True
データの読み込み
Pedumagalhaes/quality-prediction-in-a-mining-processadasを使ってダウンロードしてきたCSVファイルを読み込みます。
data = pd.read_csv(file_path + '.zip')
data
| age | ethnicity | gender | img_name | pixels | |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 0 | 20161219203650636.jpg.chip.jpg | 129 128 128 126 127 130 133 135 139 142 145 14... |
| 1 | 1 | 2 | 0 | 20161219222752047.jpg.chip.jpg | 164 74 111 168 169 171 175 182 184 188 193 199... |
| 2 | 1 | 2 | 0 | 20161219222832191.jpg.chip.jpg | 67 70 71 70 69 67 70 79 90 103 116 132 145 155... |
| 3 | 1 | 2 | 0 | 20161220144911423.jpg.chip.jpg | 193 197 198 200 199 200 202 203 204 205 208 21... |
| 4 | 1 | 2 | 0 | 20161220144914327.jpg.chip.jpg | 202 205 209 210 209 209 210 211 212 214 218 21... |
| ... | ... | ... | ... | ... | ... |
| 23700 | 99 | 0 | 1 | 20170120221920654.jpg.chip.jpg | 127 100 94 81 77 77 74 99 102 98 128 145 160 1... |
| 23701 | 99 | 1 | 1 | 20170120134639935.jpg.chip.jpg | 23 28 32 35 42 47 68 85 98 103 113 117 130 129... |
| 23702 | 99 | 2 | 1 | 20170110182418864.jpg.chip.jpg | 59 50 37 40 34 19 30 101 156 170 177 184 187 1... |
| 23703 | 99 | 2 | 1 | 20170117195405372.jpg.chip.jpg | 45 108 120 156 206 197 140 180 191 199 204 207... |
| 23704 | 99 | 0 | 1 | 20170110182052119.jpg.chip.jpg | 156 161 160 165 170 173 166 177 183 191 187 18... |
23705 rows × 5 columns
下準備
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 23705 entries, 0 to 23704
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 23705 non-null int64
1 ethnicity 23705 non-null int64
2 gender 23705 non-null int64
3 img_name 23705 non-null object
4 pixels 23705 non-null object
dtypes: int64(3), object(2)
memory usage: 926.1+ KB
data = data.drop('img_name', axis=1)
{column: list(data[column].unique()) for column in ['gender', 'ethnicity', 'age']}
{'age': [1,
10,
100,
101,
103,
105,
11,
110,
111,
115,
116,
12,
13,
14,
15,
16,
17,
18,
19,
2,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
3,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
4,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
5,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
6,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69,
7,
70,
71,
72,
73,
74,
75,
76,
77,
78,
79,
8,
80,
81,
82,
83,
84,
85,
86,
87,
88,
89,
9,
90,
91,
92,
93,
95,
96,
99],
'ethnicity': [2, 3, 4, 0, 1],
'gender': [0, 1]}
data['age'] = pd.qcut(data['age'], q=4, labels=[0, 1, 2, 3])
data
| age | ethnicity | gender | pixels | |
|---|---|---|---|---|
| 0 | 0 | 2 | 0 | 129 128 128 126 127 130 133 135 139 142 145 14... |
| 1 | 0 | 2 | 0 | 164 74 111 168 169 171 175 182 184 188 193 199... |
| 2 | 0 | 2 | 0 | 67 70 71 70 69 67 70 79 90 103 116 132 145 155... |
| 3 | 0 | 2 | 0 | 193 197 198 200 199 200 202 203 204 205 208 21... |
| 4 | 0 | 2 | 0 | 202 205 209 210 209 209 210 211 212 214 218 21... |
| ... | ... | ... | ... | ... |
| 23700 | 3 | 0 | 1 | 127 100 94 81 77 77 74 99 102 98 128 145 160 1... |
| 23701 | 3 | 1 | 1 | 23 28 32 35 42 47 68 85 98 103 113 117 130 129... |
| 23702 | 3 | 2 | 1 | 59 50 37 40 34 19 30 101 156 170 177 184 187 1... |
| 23703 | 3 | 2 | 1 | 45 108 120 156 206 197 140 180 191 199 204 207... |
| 23704 | 3 | 0 | 1 | 156 161 160 165 170 173 166 177 183 191 187 18... |
23705 rows × 4 columns
画像のサイズを計算します。
length = len(data['pixels'][0].split(' '))
np.sqrt(length)
48.0
num_pixels = 2304
img_height = 48
img_width = 48
target_columns = ['age', 'ethnicity', 'gender']
y = data[target_columns]
X = data.drop(target_columns, axis=1)
intのリストに変換
X = pd.Series(X['pixels'])
X = X.apply(lambda x: x.split(' '))
X = X.apply(lambda x: np.array(list(map(lambda z: np.int(z), x))))
画像データなので書く値を2Dにする
X = np.stack(np.array(X), axis=0)
X.shape
(23705, 2304)
X = np.reshape(X, (-1, 48, 48))
X.shape
(23705, 48, 48)
可視化
plt.figure(figsize=(10, 10))
for index, image in enumerate(np.random.randint(0, 1000, 9)):
plt.subplot(3, 3, index + 1)
plt.imshow(X[image])
plt.axis('off')
plt.show()

トレーニング
y_gender = np.array(y['gender'])
y_age = np.array(y['age'])
y_ethnicity = np.array(y['ethnicity'])
def build_model(num_classes, activation='softmax', loss='sparse_categorical_crossentropy'):
model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 1)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes, activation=activation),
])
model.summary()
model.compile(
optimizer='adam',
loss=loss,
metrics=['accuracy'],
)
return model
X_gender_train, X_gender_test, y_gender_train, y_gender_test = train_test_split(X, y_gender, train_size=0.7)
X_age_train, X_age_test, y_age_train, y_age_test = train_test_split(X, y_age, train_size=0.7)
X_ethnicity_train, X_ethnicity_test, y_ethnicity_train, y_ethnicity_test = train_test_split(X, y_ethnicity, train_size=0.7)
batch_size = 64
epochs = 20
gender_model = build_model(1, activation='sigmoid', loss='binary_crossentropy')
gender_history = gender_model.fit(
X_gender_train,
y_gender_train,
validation_split=0.2,
batch_size=batch_size,
epochs=epochs,
callbacks=[tf.keras.callbacks.ReduceLROnPlateau()],
verbose=0
)
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_2 (Rescaling) (None, 48, 48, 1) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 48, 48, 16) 160
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 24, 24, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 12, 12, 64) 18496
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_4 (Dense) (None, 128) 295040
_________________________________________________________________
dense_5 (Dense) (None, 1) 129
=================================================================
Total params: 318,465
Trainable params: 318,465
Non-trainable params: 0
_________________________________________________________________
def plot_show(history):
plt.figure(figsize=(14, 10))
epochs_range = range(1, epochs+1)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
plot_show(gender_history)
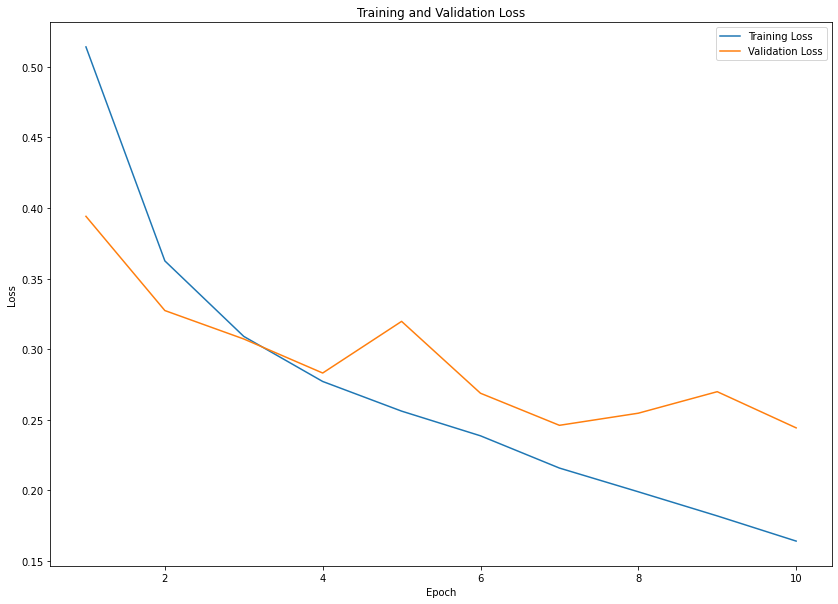
gender_acc = gender_model.evaluate(X_gender_test, y_gender_test)[1]
223/223 [==============================] - 1s 3ms/step - loss: 0.1873 - accuracy: 0.9515
age_model = build_model(4, activation='softmax', loss='sparse_categorical_crossentropy')
age_history = age_model.fit(
X_age_train,
y_age_train,
validation_split=0.2,
batch_size=batch_size,
epochs=epochs,
callbacks=[tf.keras.callbacks.ReduceLROnPlateau()],
verbose=0
)
plot_show(gender_history)
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_11 (Rescaling) (None, 48, 48, 1) 0
_________________________________________________________________
conv2d_33 (Conv2D) (None, 48, 48, 16) 160
_________________________________________________________________
max_pooling2d_33 (MaxPooling (None, 24, 24, 16) 0
_________________________________________________________________
conv2d_34 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d_34 (MaxPooling (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_35 (Conv2D) (None, 12, 12, 64) 18496
_________________________________________________________________
max_pooling2d_35 (MaxPooling (None, 6, 6, 64) 0
_________________________________________________________________
flatten_11 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_22 (Dense) (None, 128) 295040
_________________________________________________________________
dense_23 (Dense) (None, 4) 516
=================================================================
Total params: 318,852
Trainable params: 318,852
Non-trainable params: 0
_________________________________________________________________
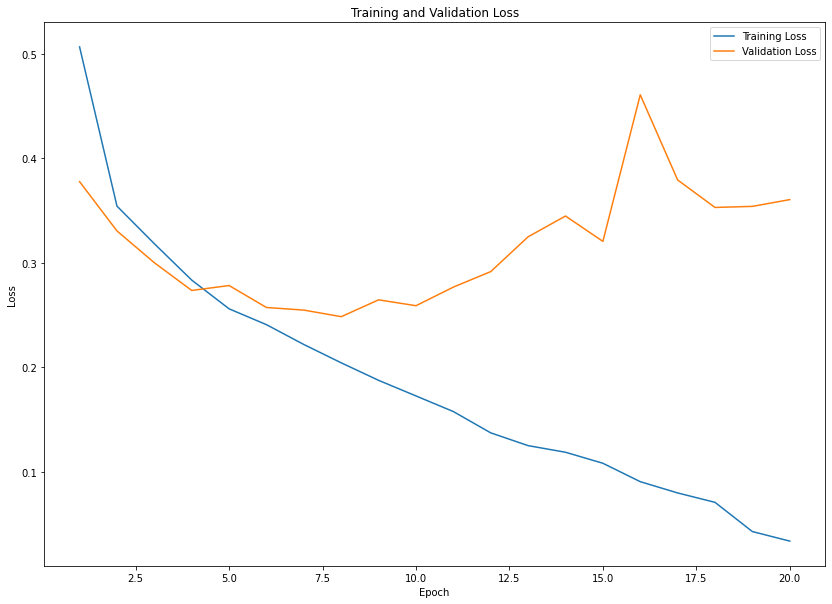
age_acc = age_model.evaluate(X_age_test, y_age_test)[1]
223/223 [==============================] - 1s 2ms/step - loss: 1.0786 - accuracy: 0.6209
ethnicity_model = build_model(5, activation='softmax', loss='sparse_categorical_crossentropy')
ethnicity_history = ethnicity_model.fit(
X_ethnicity_train,
y_ethnicity_train,
validation_split=0.2,
batch_size=batch_size,
epochs=epochs,
callbacks=[tf.keras.callbacks.ReduceLROnPlateau()],
verbose=0
)
plot_show(ethnicity_history)
Model: "sequential_12"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_12 (Rescaling) (None, 48, 48, 1) 0
_________________________________________________________________
conv2d_36 (Conv2D) (None, 48, 48, 16) 160
_________________________________________________________________
max_pooling2d_36 (MaxPooling (None, 24, 24, 16) 0
_________________________________________________________________
conv2d_37 (Conv2D) (None, 24, 24, 32) 4640
_________________________________________________________________
max_pooling2d_37 (MaxPooling (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_38 (Conv2D) (None, 12, 12, 64) 18496
_________________________________________________________________
max_pooling2d_38 (MaxPooling (None, 6, 6, 64) 0
_________________________________________________________________
flatten_12 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_24 (Dense) (None, 128) 295040
_________________________________________________________________
dense_25 (Dense) (None, 5) 645
=================================================================
Total params: 318,981
Trainable params: 318,981
Non-trainable params: 0
_________________________________________________________________

ethnicity_acc = ethnicity_model.evaluate(X_ethnicity_test, y_ethnicity_test)[1]
223/223 [==============================] - 1s 3ms/step - loss: 0.8495 - accuracy: 0.7697