0 はじめに
本記事はsklearnでOne Class SVMを実装する際の自分用メモとして記載した内容です。他の記事を読んで理解した点や、記憶しておきたい点を図を用いてまとめています。
1 準備
読み込む関数は以下です。
2 データ定義
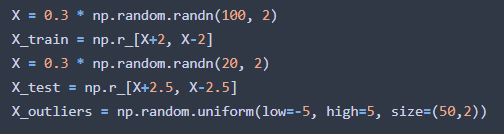
今回訓練データ、試験データ、外れ値データとして以下を定義します。
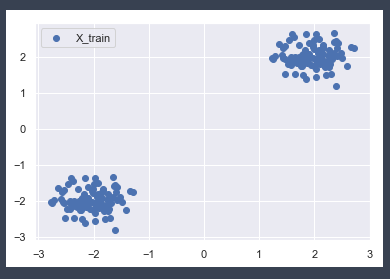
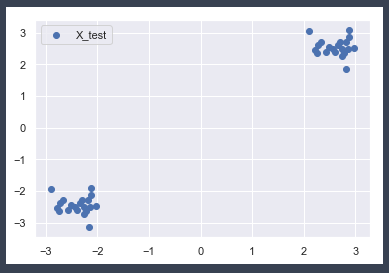
X_trainとX_testとX_outliersのグラフはそれぞれ以下の通りです。
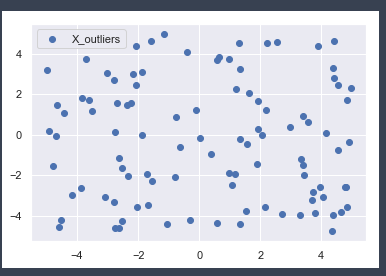
3 データ学習
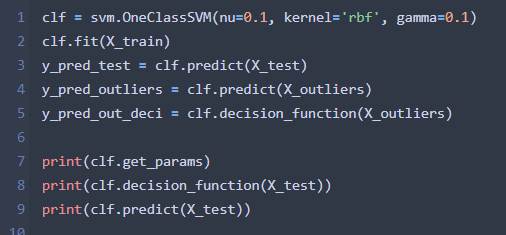
clf.get_paramsで学習に使われたパラメータが表示される

clf.decision_function(X_test)では各分布点における識別境界との距離を表しプラス値が分類内、マイナス値で分類外を意味する。
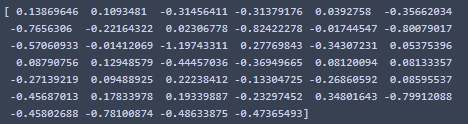
clf.predict(X_test)は1もしくは-1を返し、与えられた各点が外れ値かどうかがわかる。

外れ値として与えたX_outliersの範囲内外を調べるためにpredictとdecision_functionを一つの表にまとめると以下のようになる。

外れ値が多いため、-1となっているデータが多いが、一部1となっているところがあり学習データ範囲内になっていることがわかる。
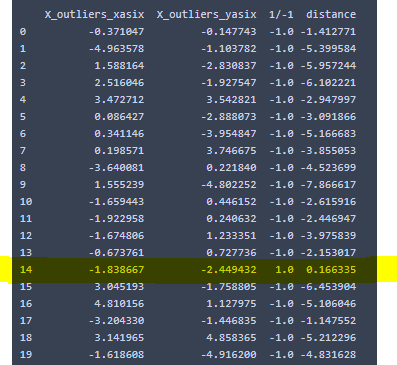
4 結果表示
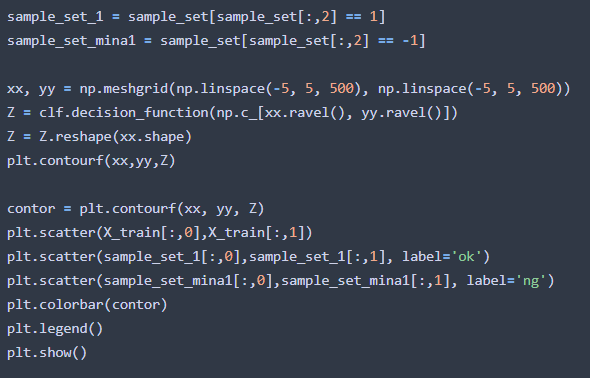
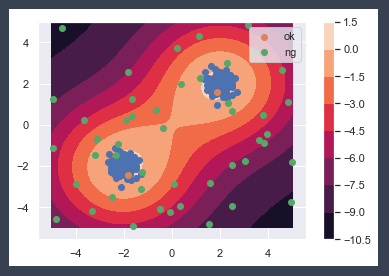
sample_set_1は外れ値データセットの中で学習範囲内であったものの集合で、sample_set_mina1は外れ値データセットの中で外れ値であったものの集合です。
以下OKとなっている2点が1の点です。
以上、簡単な実装メモでした。