はじめに
独学でpytorchを勉強していても、なかなかまとまった記事がなかったり、プログラミングをする上で自分が躓いた点をtipsとしてまとめるところもなかったので、自分向けに絵や図を使って後から思い出しやすいように工夫をしながら、KnowHowをここにまとめようと思います。
もし私と同じようなポイントで躓いたりしている人がいたら、このknowledgeが参考にあれば嬉しいです。
利用するライブラリ
numpy
pandas
torch
matplotlib
seaborn
IPython.core.display
などです。
他にもimportしているものもありますが、サンプルコードの中で紹介します。
0. 全体の流れ
事前準備
必要モジュールのインストール
- 文書作成サイトで文書の作成と変数に文章を割り当て
- 読み込んだ文章の分ち書き
- 単語のラベル化(word2index)
- 文章のラベル表現化(sentence2index)
- テストデータと正解データの作成
-----------↑↑↑ここまでpandas操作。↓↓↓ここからpytorch操作。
6. データのテンソル化
7. ニューラルNWの定義(←ここのパラメーターの設定がポイント)
8. 学習(←ここのデータの受け渡しがポイント)
9. 評価
事前準備
以下を予めにインストールしておきます。
!apt install aptitude
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3==0.7
これらパッケージはMeCabを利用するためのパッケージ群(のよう)です。以下、引用先を参考にしています。
MeCab (和布蕪)とは
MeCabは 京都大学情報学研究科−日本電信電話株式会社コミュニケーション科学基礎研究所 共同研究ユニットプロジェクトを通じて開発されたオープンソース 形態素解析エンジンです。 言語, 辞書,コーパスに依存しない汎用的な設計を 基本方針としています。 パラメータの推定に Conditional Random Fields (CRF) を用 いており, ChaSenが採用している 隠れマルコフモデルに比べ性能が向上しています。また、平均的に ChaSen, Juman, KAKASIより高速に動作します。 ちなみに和布蕪(めかぶ)は, 作者の好物です。
MeCab: Yet Another Part-of-Speech and Morphological Analyzer
ちなみにMeCabの詳しい使い方はこちらのサイトで紹介がされています。
1. 文章の選定と読み込み
今回文章の学習をさせるための元となる文章の生成には以下サイト『すぐ使えるダミーテキスト』を使わせていただきました。
このサイトでは夏目漱石、宮沢賢治の文章の生成をしてくれます。ここで生成をした文章をcolaboratoryに貼り付けてtest_sentenceに代入をします。
test_sentence = """これは場合ついにその講演らという点のため・・・途中省略・・・"""
TIPS 三重クオート ''' or """
最初の """ から 2番目の """ までが1つの文字列となります。
この方法で文字列を定義した場合、文字列の中で行った改行は文字の改行として扱われます。
2. 分かち書き
先ほど定義したtest_sentence に保存されている文章に対し、品詞ごとに空白を入れて分離をします。
tagger = MeCab.Tagger("-Owakati")
def make_wakati_(sentence):
sentence = tagger.parse(sentence)
#半角全角英数字を除去
sentence = re.sub(r'[0-90-9a-zA-Za-zA-Z]+', " ", sentence)
#記号を除去
sentence = re.sub(r'[\._-―─!@#$%^&\-‐|\\*\“()_■×+α※÷⇒—●★☆〇◎◆▼◇△□(:〜~+=)/*&^%$#@!~`){}[]…\[\]\"\'\”\’:;<>?<>〔〕〈〉?、。・,\./『』【】「」→←○《》≪≫\n\u3000]+', "", sentence)
#スペース区切り
wakati = sentence.split(" ")
#空要素の除去
wakati = list(filter(("").__ne__, wakati))
return wakati
wakati = make_wakati_(test_sentence)
# 分ち書きした後の結果表示
print(wakati)
['これ', 'は', '場合', 'ついに', 'その', '講演', 'ら', ・・・省略
これで文章を品詞ベースで分離をすることができました。次は単語と数字のラベルを1対1で紐づけるための辞書を作成します。
3. 単語のラベル化
単語のラベル化でやることは、分かち書きで分離をした単語に対して、単語の重複がないよう単語リストを作成し、そのリストに番号を割り振ります。具体的には、空の辞書 word2indexを定義し、分かち書きした単語を word2indexに入れていきます。その際には番号も一緒に入れることで単語と番号を結びつけて辞書化します。 word2indexは辞書なので同じ単語を別番号で保存したくないため(*)にあるように、これから登録する単語が既に word2indexに存在しないか確認をします。
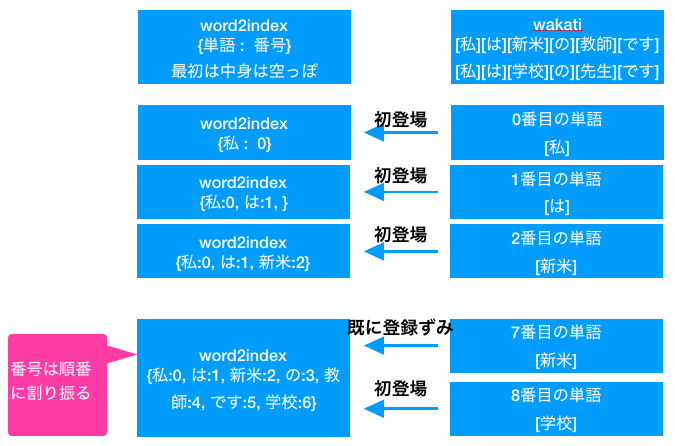
def word2index_(wakati):
word2index = {}
for word in wakati:
if word in word2index: continue #(*) word2indexに既に単語がある場合はスキップ
word2index[word] = len(word2index) #リスト長さ = 次の単語ラベル
return word2index
word2index = word2index_(wakati)
# 単語のラベル化をした後の結果表示
print(word2index)
{'これ': 0, 'は': 1, '場合': 2, 'ついに': 3, 'その': 4, '講演': 5, 'ら': 6, 'という': 7, '点': 8, ・・・省略
4. 文章のラベル表現
ここまでの流れと、ラベル表現でやりたいことを絵にするとこんな感じです。元の文章をラベル表記かすることが目標です。そのためまずはword2indexで文字の重複を省いたwordとindexを紐付けた辞書を作成し、LSTMに読み込ませるためのテストデータと教師データのデータセットを作ります。最後にそのデータセットを作成した辞書を持ちて文字→文字ラベルに置き換えデータセットとします。
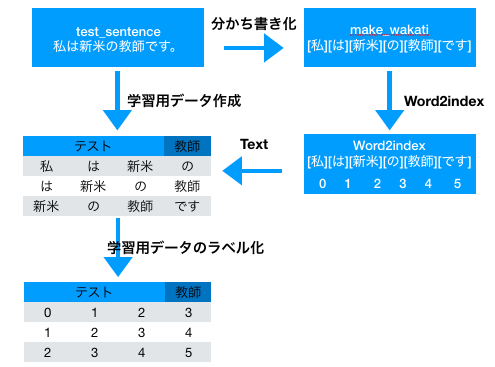
trigrams_train = [[word2index[wakati[i]], word2index[wakati[i + 1]], word2index[wakati[i + 2]], word2index[wakati[i + 3]]] for i in range(len(wakati) - 4)]
trigrams_target = [word2index[wakati[i + 4]] for i in range(len(wakati) - 4)]
ここではテストデータを4つずつピックアップし、5番目のデータを教師データとする作りです。
5. テストデータと正解データの作成
データ分析でお馴染みのtrain_test_splitを使いデータセットを作成します。先ほど作成したtrigrams_trainとtrigrams_targetをインプットとして分割をします。
ちなみに、LSTMで学習する際に利用するバッチ数とテスト時に利用するバッチ数が同じでないといけない?ため、訓練データとテストデータでできるだけ大きい最大公約数を得るためにいろいろいじった結果の数字です。
※コーディング上重要ですが、本質ではないため読み飛ばしてください。
TIPS 学習時と推論時のバッチ数
学習時と推論時で同じバッチ数を与える必要があります。異なるバッチ数で計算をしようとするとLSTM実行時に怒られてしまいます。
train_data, test_data, train_target, test_target = train_test_split(trigrams_train, trigrams_target, test_size=0.1, shuffle = True)
print(trigrams_train)
print(trigrams_target)
print(math.gcd(len(train_), len(test_)))#最大公約数を求める
[[0, 1, 2, 3], [1, 2, 3, 4], [2, 3, 4, 5], [3, 4, 5, 6], [4, 5, 6, 7], [5, 6, 7, 8],・・・省略
[4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 1, 20, 21, 22, 14, 23,・・・省略
最大公約数
6733
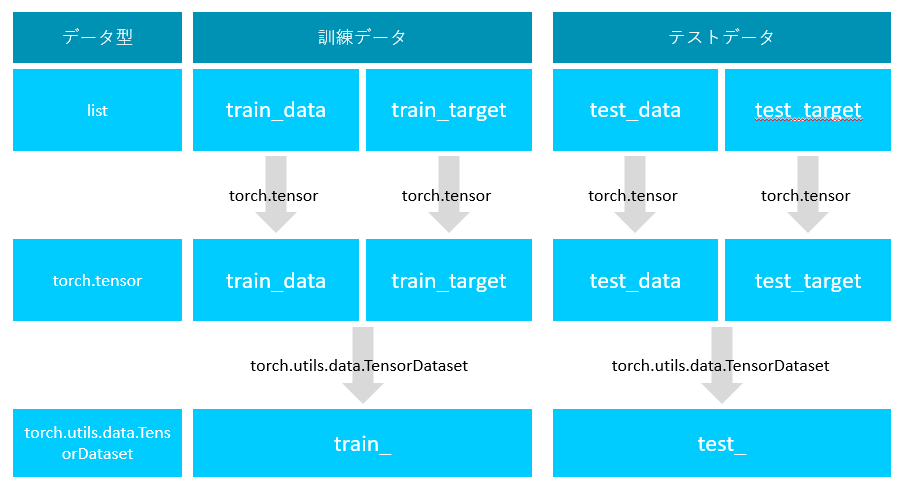
6. データのテンソル化
ここまでの処理で学習をさせるためのデータの準備ができました。ここからは、pytorchでネットワークの定義をして、学習データを読み込ませる操作を行います。
まずは、先ほど作成した訓練用の予測データと正解データ、およびテスト用の予測データと正解データをセットにします。
train_ = torch.utils.data.TensorDataset( torch.tensor(train_data), torch.tensor(train_target) )
test_ = torch.utils.data.TensorDataset( torch.tensor(test_data), torch.tensor(test_target) )
7. ニューラルNWの定義
今回定義をするネットワークを図にするとこのような感じです。
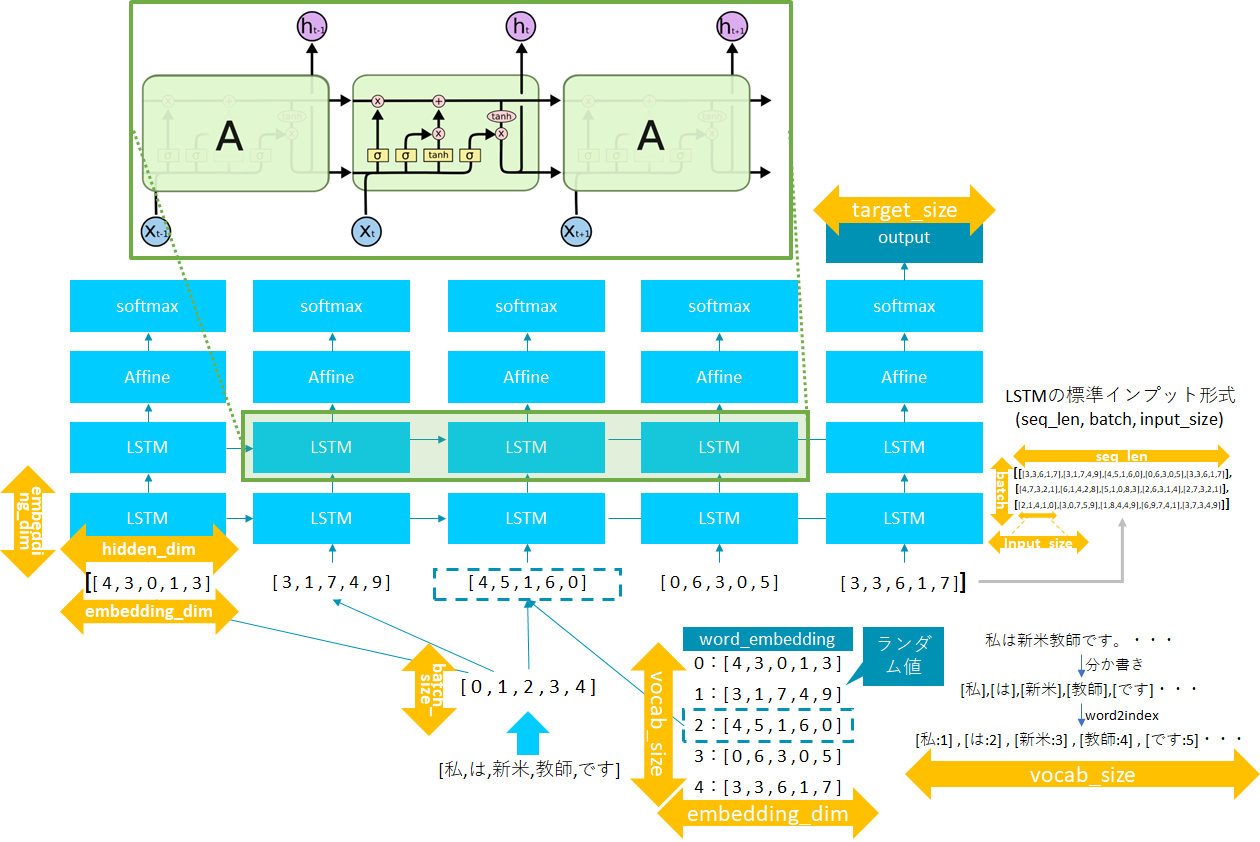
LTSMを2層(やってみたかったので)とアウトプットとしては最後の層の出力を利用しています。またLSTMやembeddingマトリックスの要素数の関係をオレンジ色の矢印で表示しています。
TIPS LSTMの入力形式
LSTMにデータを入力する際には (seq_len, batch, input_size) の順番に入力します。オプションでbatch_first = Trueとした場合には (batch, seq_len, input_size) の順番になります。
class LSTMClassifier(nn.Module):
def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size, batch_size):
super(LSTMClassifier, self).__init__()
self.num_layers=2
self.embedding_dim = embedding_dim
self.dropout=nn.Dropout()
self.batch_size= batch_size
#self.hidden_dim = hidden_dim
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=self.num_layers, batch_first=True, dropout=0.1)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.softmax = nn.LogSoftmax()
def forward(self, sentence):
embeds = self.word_embeddings(sentence)
#embeds = self.dropout(embeds)
# lstmの2出力あるうち、(h,c)の方を用いるため、1つ目は _ としている。
_, lstm_out = self.lstm(embeds.view(self.batch_size, -1, self.embedding_dim))
tag_space = self.hidden2tag(lstm_out[1][0]).squeeze()
tag_scores = self.softmax(tag_space)
return tag_scores
nn.lSTM()の出力形式は各LSTM層の出力と、LSTMの最後の層の出力の2つあります。以下のように定義することで、layer_outputには各LSTMの最後の出力が得られ、h_c_outputにはLSTMの最後の層の出力結果が格納されます。
layer_output, h_c_output = nn.LSTM( batch_size, sequence_length, embedding_length)
layer_outputの出力例は以下の通りです。指定したバッチ数、sequence数、hidden_layerの数だけ出力があります。
# layer_outputの出力結果例(batch=3、sequence=4、hidden_layer=2の場合)
print(layer_output)
# 1つ目batchで4つ分のsequence結果
[[[ 0.1476, -0.0936],
[ 0.1761, -0.1207],
[ 0.1875, -0.1490],
[ 0.1888, -0.1530]],
# 2つ目batchで4つ分のsequence結果
[[ 0.1476, -0.0932],
[ 0.1783, -0.1261],
[ 0.1858, -0.1366],
[ 0.1880, -0.1541]],
# 3つ目batchで4つ分のsequence結果
[[ 0.1392, -0.0606],
[ 0.1787, -0.1202],
[ 0.1890, -0.1497],
[ 0.1896, -0.1530]]]
print(layer_output[1,1,0])
# 2つ目batchの2番目sequenceの0番目の結果
0.1783
TIPS layer_outputの隠れ層の出力
LSTMの層が縦に複数重なっている時(num_layer>1)、最後のLSTM層から出力される値は取得ができるが、最後の層までのinputとなるLSTM層の出力値は取得ができなさそう。
TIPS layer_outputの値取得
batchが2以上の場合、LSTMからの出力はbatch数だけ次元が増えます。取り出す際はlayer_output[ 対象batch列, 対象sequence ]で取り出すことができます。
h_c_outputは大きく分けて出力hと出力cに分けることができます。またh_c_outputの値はLSTMの最後の層の出力を表します。そのため、layer_outputの最後の出力値とh_c_outputの出力とは一致します。hの出力を取り出す際はh_c_output[0]で取り出せ、cの出力を取り出す際はh_c_output[1]で取り出すことができます。hとcの中身はさらにLSTMの層数(num_layer)の塊で保存されていて、2層目の出力を取り出したいときはh_c_output[0][1]のように記載をします。
print(h_c_output)#上の塊がh、下の塊がc
[[[-0.0184, -0.1253],
[-0.0353, -0.0496],
[-0.0218, -0.1240]],
[[ 0.1888, -0.1530],
[ 0.1880, -0.1541],
[ 0.1896, -0.1530]]
[[[-0.0421, -0.1409],
[-0.1836, -0.0702],
[-0.0513, -0.1620]],
[[ 0.4628, -0.3615],
[ 0.4612, -0.3577],
[ 0.4456, -0.3618]]]]
print(h_c_output[0])#hの出力
[[-0.0184, -0.1253],
[-0.0353, -0.0496],
[-0.0218, -0.1240]],
[[ 0.1888, -0.1530],
[ 0.1880, -0.1541],
[ 0.1896, -0.1530]]
print(h_c_output[0][1])#LSMTのhの2層目の出力(h1)
[[ 0.1888, -0.1530],
[ 0.1880, -0.1541],
[ 0.1896, -0.1530]]

8. 学習
lossesは1エポック毎のloss関数の値を保存していて、losses2は1バッチ毎のloss関数の値を保存しています。全体の流れはmodel.zero_grad()で勾配の0リセット、model(学習データ)で予測、loss_function(予測データ、学習用正解データ)で損失計算、loss.backward()で誤差逆伝播、optimizer.step()で更新です。
EMBEDDING_DIM = 300
HIDDEN_DIM = 200
VOCAB_SIZE = len(word2index)
TAG_SIZE = len(word2index)
# 学習と予測に同じLSTMのマトリックス形状が必要なため、trainとtestで最大公約数を取り、それをbatch数とする。
BATCH_SIZE = np.gcd(len(train_), len(test_)).tolist()
model = LSTMClassifier(EMBEDDING_DIM, HIDDEN_DIM, VOCAB_SIZE, TAG_SIZE, BATCH_SIZE).to(device)
loss_function = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=0.005)
losses = []
losses2 = []
def sample_code2(batch_size):
for epoch in range(100):
total_loss = 0
train_batch = torch.utils.data.DataLoader(train_, batch_size, shuffle=True)
for i, train_data in enumerate(train_batch):
data, target = train_data
context_idxs = torch.tensor(data, dtype=torch.long).to(device)
target_idxs = torch.tensor(target, dtype=torch.long).to(device)
model.zero_grad()
log_probs = model(context_idxs)
loss = loss_function(log_probs, target_idxs)
loss.backward()
optimizer.step()
total_loss += loss.item()
losses2.append(loss.item())
losses.append(total_loss)
print("epoch", epoch, "loss", total_loss)
return log_probs
log_probs=sample_code2(BATCH_SIZE)
TIPS batch数を求める
先ほども記載の通り、batch処理をする際は学習時とテスト時で同じbatchを使う必要があります。(←経験上の理解です。間違っていたら教えて下さい。)batch数の最大値を求めるため、学習データ数とテストデータ数の最大公約数を利用します。最大公約数はnp.gcd( data1, data2 ).tolist()の形式で指定します。.tolistにしているのはnumpy形式だとLSTMの処理の際、errorが出てしまい、list形式に変換した場合処理が進んだため使っています。math.gcd()であれば、.tolist()は必要ないです。
TIPS データのbatch化
LSTMに入れるデータをbatch化する際にはtorch.utils.data.DataLoaderを使う。入力形式はtorch.utils.data.DataLoader(データセット, batch_size=1, shuffle=False/True)です。詳細な説明は以下サイトに記載があります。
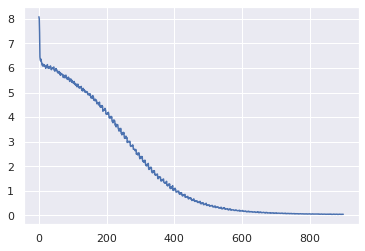
学習の結果は以下の通りです。学習が進んでいることがわかります。
plt.plot(losses2)
9. 評価
テストデータで評価します。
test_batch = torch.utils.data.DataLoader(test_, batch_size=BATCH_SIZE, shuffle=False)
model.eval()
with torch.no_grad():
for test_data_ in test_batch:
data, target = test_data_
inputs = torch.tensor(data, dtype=torch.long).to(device)
out = model(inputs)
_, predict = torch.max(out, 1)
pred = predict.cpu().numpy()
answer = target.cpu().numpy()
print(np.count_nonzero(pred == answer)/pred.shape[0]*100)
print(np.count_nonzero(pred == answer))
print(pred.shape[0])
39.195009653943266
2639
6733
39.19%(6733中2639個正解)の正答率。。。低いですね。改良が必要です。
pytorch初心者なので、もし変な個所があったらご指摘いただけると嬉しいです。