簡単に機械学習のAPIを作成したいという目的で、Google Cloud AI Platform Predictionを触ってみました。
手順としては以下の通りです。
- モデルを作成するためのデータを用意する
- AI Platform Trainingを利用してXGBoostのモデルを作る
- AI Platform Predictionでモデルをデプロイ
- curlで叩いてみる
1. モデルを作成するためのデータを用意する
AI Platform Trainingにてモデルを作成するためのデータを用意します。
今回はアヤメの計測データセットを利用しました。
私は、以下のコードをGoogle Coraboratory上で実行し、 iris.csv という学習用データセットをGoogleDriveにエクスポートしました。
from sklearn.datasets import load_iris
iris = load_iris()
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df.loc[df['target'] == 0, 'target'] = "setosa"
df.loc[df['target'] == 1, 'target'] = "versicolor"
df.loc[df['target'] == 2, 'target'] = "virginica"
df = df[df.columns[::-1]] # 目的変数を1列目にする必要があるため
from google.colab import drive
drive.mount('/content/drive')
df.to_csv(path_or_buf="/content/drive/My Drive/iris.csv", index=False, header=False, encoding='utf-8') # headerは削除する必要があるため
AI Platform Training(組み込みアルゴリズムによるトレーニング)では、読み込ませるデータの仕様が以下の通り決まっているので注意です。
- 目的変数がデータセット1列目である必要がある。
- headerは削除する必要がある。
AI Platform Trainingでモデル作成を実行する際、学習用のデータセットがGoogle Cloud Storage上に保存されている必要があるので、 先ほどGoogle Driveに保存した iris.csv をCloud Storageにアップロードします。
AI Platform Trainingで作成されるモデルもGoogle Cloud Storage上にエクスポートされるため、バケットを用意してもいいかもしれません。
2. AI Platform Trainingを利用してXGBoostのモデルを作る
作成した iris.csv を用いて、AI Platform Training(組み込みアルゴリズムによるトレーニング)にてモデルを作成していきます。
AI Platform Training(組み込みアルゴリズムによるトレーニング)を利用して、ノーコーディングでモデルを作成していきます。
Google Cloudのコンソールから、AI Platformのサービス画面に移動します。
まず、AI PlatformのAPIを有効にしていない場合は有効にします。
続いて左のメニューから「ジョブ」を選択し、「新規トレーニングジョブ」をクリックします。「組み込みアルゴリズムによる トレーニング」か「カスタムコード トレーニング」のどちらかが選択できます。今回は「組み込みアルゴリズムによる トレーニング」を選択します。
はじめにアルゴリズムの選択画面となります。複数のアルゴリズムが選択可能ですが、今回はXGBoostを選択します。
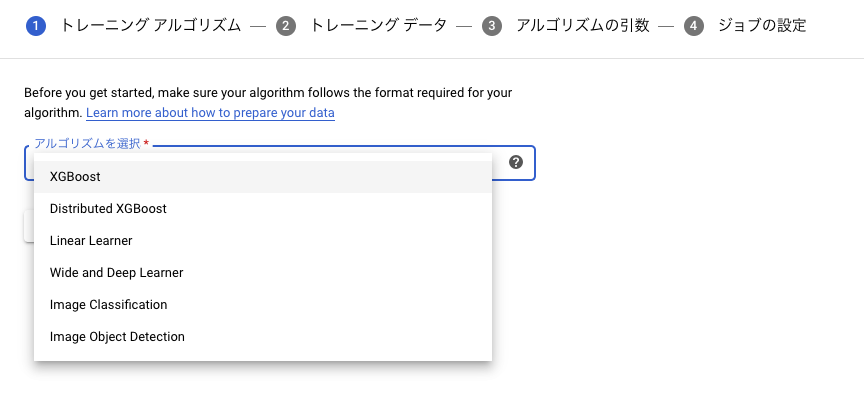
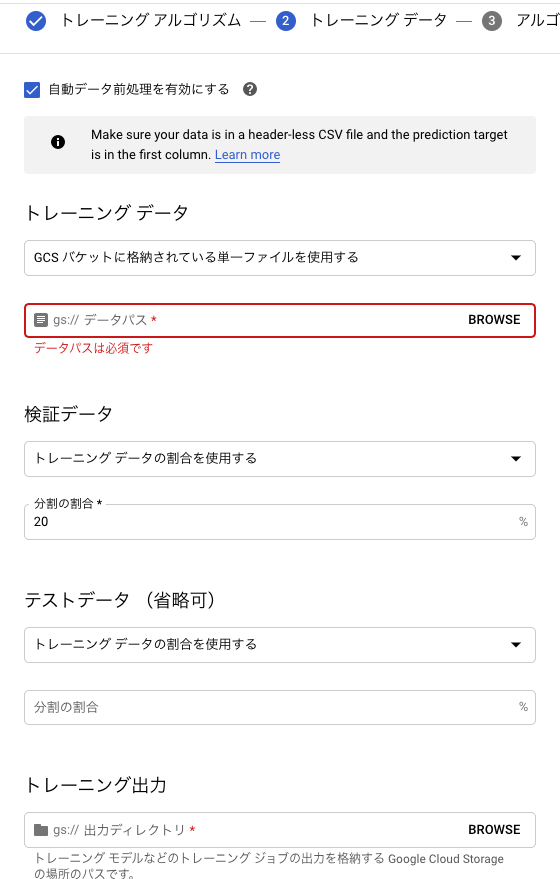
続いてトレーニングデータについての設定画面となります。
トレーニングデータのGoogle Cloud Storageのパスを入力する画面があるため、先ほどデータを格納したパスを入力します。
検証データは、今回 iris.csv の20%を利用することにしました。
そして、トレーニング出力(=モデルの出力先)となるGoogle Cloud Storageのパスも記入する必要があります。
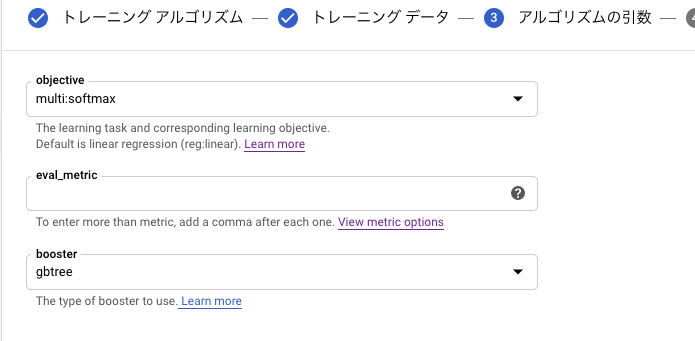
続いて、XGBoostのパラメータ設定画面が表示されます。
今回は複数クラス分類になるため、objectiveの欄は multi:softmax を選択しました。
最後の画面では任意のジョブ名記入、トレーニングを実行するリージョン名選択、スケール階層選択ができます。
スケール階層というのは、トレーニングに割り当てるインスタンスリソースを指すようです。
小さく試すときは BASIC、重ための学習を行うときには CUSTOM で適切なリソースサイズを選ぶのが良いでしょう。
今回はデータも非常に小さいので BASIC を選択しました。
全て記入が終わったら、「完了」ボタンを押してトレーニングを開始します。
トレーニング完了には5分ほどかかります。恐らくバックエンドの環境整備(インスタンスリソースの割り当て)に時間がかかっているものだと思います。
3. AI Platform Predictionでモデルをデプロイ
ジョブの画面から、先ほどトレーニングしたジョブの詳細画面を開きます。
上方にある「モデルをデプロイ」をクリックします。
以下のような画面が表示されるので、モデル名とデプロイ先のリージョンを選択し、確認を押します。
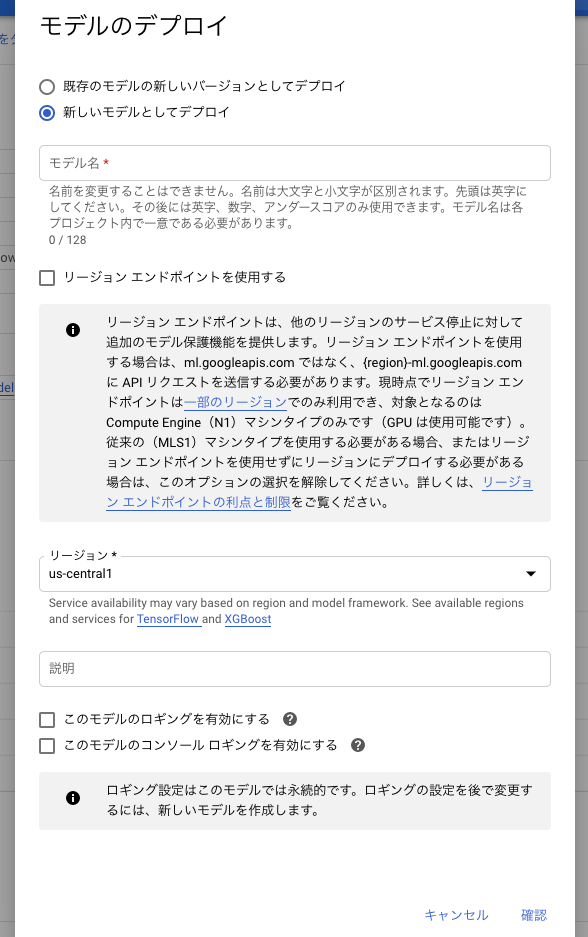
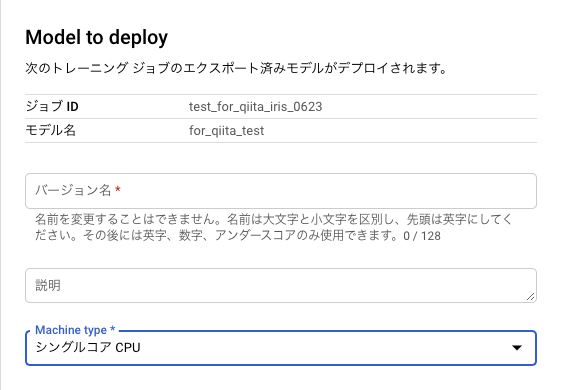
続いて Model to Deployと表示された画面に遷移します。
ここで、デプロイメントに対する任意のバージョン名と、推論用のインフラリソースのMachine Typeを選択します。
入力が完了したら「保存」を押します。
モデルのデプロイには5分ほどかかります。
4. curlで叩いてみる
デプロイされたモデルをcurlで叩いてみます。
はじめに以下二つの権限を持たせたサービスアカウントを作成し、キー(json)をローカル環境にダウンロードします。
ml.models.predictml.versions.predict
環境変数 GOOGLE_APPLICATION_CREDENTIALS にダウンロードしたJSONファイルのパスを指定します。
以下のコマンドを実行します。
$ export GOOGLE_APPLICATION_CREDENTIALS="YOUR_SERVICE_ACCOUNT_JSON_PATH"
$ curl -H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json" \
-X POST \
-d '{"instances": [[0.5, 1.6, 2.6, 6.3]]}' \
https://ml.googleapis.com/v1/projects/{YOUR_PROJECT_ID}/models/{YOUR_MODEL_NAME}:predict
# => {"predictions": [2.0]}
推測の結果が帰ってきました。
APIにアクセスする際には、サービスアカウントでtokenを取得して渡す必要があります。(Authorizataion~ の部分)
推測したいデータは、上記の通りにJSON形式で記述します。({"instances": ~} の部分)
モデルをデプロイする際に、「リージョンエンドポイントを利用する」設定にしている場合は、エンドポイントの ml.googleapis.com の部分が (リージョン名)-ml.googleapis.com のような形になります。(例: us-central1-ml.googleapis.com)