ChatGPTでシンプルなシステムを実装してみた
ChatGPTは単体のファイルのコードを生成してくれますが、その気になれば小さめなシステムを体系的に作ってくれたりします。
ちょっとしたアプリケーションをstreamlitで実装してみたので、その過程をまとめます。
アプリケーションの仕様
下記のようなKendraのPoC用アプリケーションを作ります。このレベルであれば本来はKendraのExperienceという機能を使えば実現できますが、今回はAPIの動作確認も兼ねて、あえて簡易アプリを作ってみます。
- Amazon Kendraという全文検索サービスに文書を登録する
- ユーザーはWeb UIからで自然言語で検索をする
- Kendraから文書のリストが返却される
- UIに文書のリストが表示される
システム実装の概要
下記のような手順で考えます
- 言語、システムアーキテクチャの選定
- フォルダ構造や、ファイル構成の設計
- ソースコードの実装
※KendraのセットアップやIndexの作成、データの登録は全てAWSのコンソールからやりましたが、この記事ではその過程は省きます。
ChatGPTを使った実装
こちらが実際の会話履歴です。
英語を使った方が高パフォーマンスを出すことが知られているので英語でやっていますが、今回くらいのタスクであれば日本語でも全然問題はないと思います。
https://chat.openai.com/share/468dca8b-4e2b-421f-b7b9-e5958228f242
以下、どういう手順で聞いていって、何を実装したのかについて整理します。
言語、システムアーキテクチャの選定
ここは、ChatGPTには頼らずstreamlitで実装しようと決めました。
UIとサーバーが一体で実装でき、PoC用なので特に拡張性やデザインの特化も必要ないので、最も手早く実装できるかなと思ったのが理由です。
一応ChatGPTにオススメも聞いてみましたが、結構ガチで実装するパターンのやつしか出てこなかったので、やはりstreamlitを採用することに。
https://chat.openai.com/share/49958d36-16f8-496c-b9bf-21cd35f8cfe0
どう作ってよいか全然わからない場合は、ChatGPTの教えに単純に沿うのもアリです。
モジュールやファイルリスト
次にファイルリストについて提案を受けます。あまりに複雑な機能をいきなりお願いすると大変なので、CRUDやミドルウェアなど基本的なパーツは抑えつつ、機能のバリエーションについては最小限に抑えると良いです。
最初は
Can you show what kind of modules we should implement?
と聞いてしまいファイルリストを挙げてもらえなかったので、次の発言で明示的にファイルリストと指示を出しています。
結果得られたファイルリストはこちら
1. frontend
- search_input.py: This file will handle creating and managing the search input components.
- results_display.py: This file will handle displaying the search results returned from the backend.
- pagination.py: This file will handle creating and managing the pagination components.
2. backend
- query_processing.py: This file will handle preprocessing the search query before it is sent to Amazon Kendra.
kendra_interaction.py: This file will handle interactions with the Amazon Kendra API.
- results_processing.py: This file will handle processing the results returned from Amazon Kendra before they are sent to the frontend.
3. streamlit_app.py: This is the main application file where you'd import the frontend and backend modules and coordinate the flow of data between them.
ソースコードを表示
それぞれのファイルについてソースコードを聞いていきます。
順番に表示されるので、提示してくれた5つについて全部聞いておきます。
最後にフォルダ構成について聞くとこんな感じということでした。
/my_kendra_app
/frontend
__init__.py
search_input.py
results_display.py
pagination.py
/backend
__init__.py
query_processing.py
kendra_interaction.py
results_processing.py
streamlit_app.py
__init__.pyにはなんか書くのかな?と思って一応聞いたらここは空で良いとのこと
実際に実装してみる
VS Codeでプロジェクト立ち上げ、import指定されているモジュールをpip installで順番にインストールしていきます。ここもめんどかったら、ChatGPTにpipコマンドを生成してもらってもいいかもしれません。
次にフォルダとファイルをそれぞれ作っていき、ChatGPTに提案されたソースコードをコピペしていきます。
このあたり、将来的にChatGPTが直接ファイルシステムを操作して埋めてくれる仕組み出てくれないですかね。
仮想環境の設定の仕方や実行の仕方など、わからないところがあればどんどん聞いて解決していきましょう。
一通り聞いて実装したら、実際に立ち上げてみます。
デバッグ
ChatGPTに提案してもらったコードがそのままの形で完全に動くことは稀です。
- すごくありそうなんだけど存在しないメソッド
- 引数の指定が間違えている
- データの構造が間違えている
とか色々ありえますが、まずは提案されたコードを動かしてみます。
streamlit run streamlit_app.pyで動かします。起動は無事にできましたが、初期表示しようとするとエラー出現です。
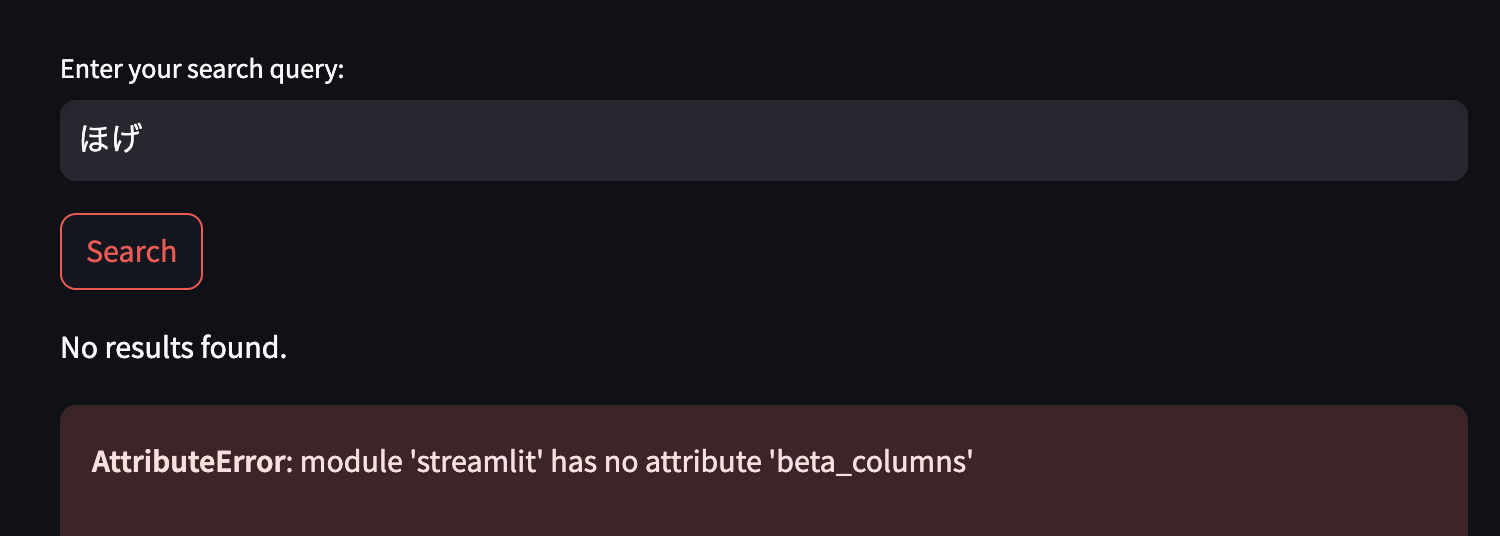
自分で調べてみると、pagination.pyの下記の行がエラーを起こしていました。
col1, col2, col3 = st.beta_columns(3)
どうやらbeta_columnsは2021-11-2にbetaから卒業されたらしいです。
https://github.com/bpw1621/streamlit-topic-modeling/issues/4
ChatGPTは2021年7月がカットオフなので、それ以降のことについては知りません。
これで初期表示まではたどり着きました。
ところが検索インプットフィールドに試しに「ほげ」とか入れてみると…
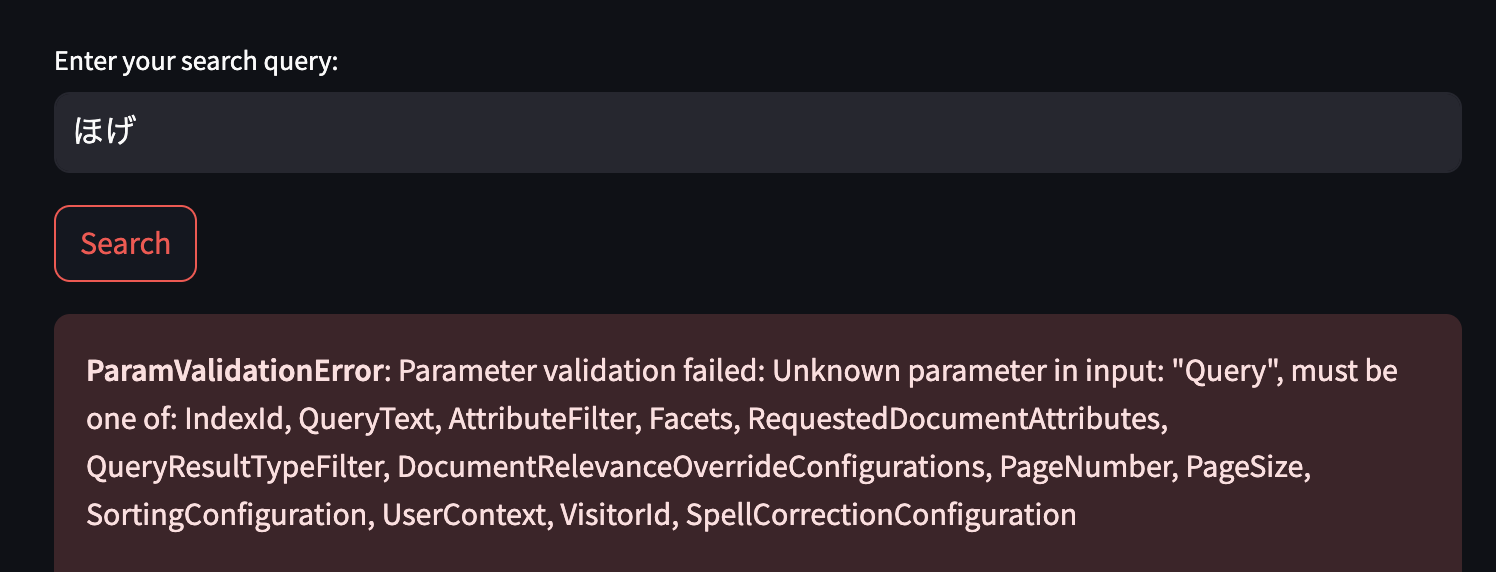
次なるエラー出現です。
メッセージに従って調べてみると、kendra_interaction.pyの中でkendraのクエリに渡す引数の設定があるのですが、ここが QueryではなくQueryTextでないとだめなようです。
query_params = {
"Query": query,
"IndexId": index_id
}
これはGPTに聞かずに自分で調べました。GPTに聞いてもいいのですが、APIの変更や正確な表現についてはむしろ遠回りになることもあるので、聞きませんでした。
修正後に実行すると、もう1個エラーが出ます。
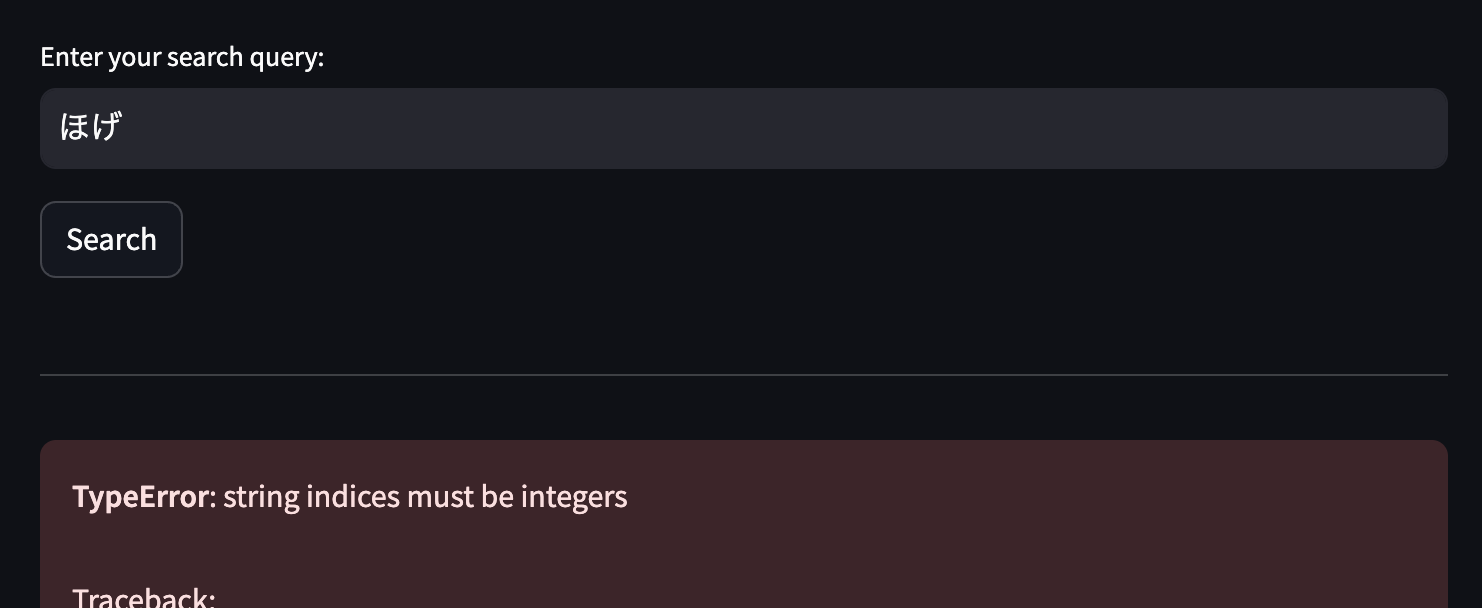
result_processing.pyの下記の行で
result['DocumentTitle'] = item['DocumentTitle']['Text']
とあるんですが、['Text']の部分が不要のようです。これを削ります。
これでようやく表示が正常にできました!
ページングの機能も実装してほしかったのですが、これは完全に動いていませんでした。
色々聞いてみましたが、簡単にはいきそうになかったのでこれについては諦めです。
今から考えるとページネーションまで初期実装で要求したのはスコープが大きすぎたかなと思っています。
他にもDockerfile生成してもらったり、環境変数からAWSのキーをもらうようにしたり、「ちょっとこれやってよ」みたいのはどんどんChatGPTにお願いしていますので、もしご興味があればチャット履歴を御覧ください
まとめ
- ChatGPTを使って、Kendra + streamlitのシンプルな文書検索システムを実装しました
- ファイルの一覧を作成 -> 実装 -> デバグと一連の流れでChatGPTを活用できます
- streamlitは完全に初学者だったのですが、ChatGPTの出すコードとstreamlitの公式ドキュメントを行ったり来たりすることで非常に勉強にもなります(ここ重要)
- そのままコードが動くことはやはりないのですが、思ったほどデバグも大変ではないし、素でイチから自分で実装するよりはだいぶ時間が短縮できたと思います