はじめに
本記事はAWSで提供されているサーバレスサービスを使用し、文章の感情分析および翻訳を行うサービスを構築するハンズオンです。
全3記事の構成となっており、本記事は第3回となります。
- AWSサーバレスアーキテクチャで文章解析サービスを構築する その1
- AWSサーバレスアーキテクチャで文章解析サービスを構築する その2
- AWSサーバレスアーキテクチャで文章解析サービスを構築する その3
構築するアーキテクチャ、使用するサービスなどについては第1回目の記事を参照ください。
注意①
本資料内スクショのAWS管理コンソールのデザインは資料作成当時のものです。
デザインは今後変更される可能性があり、スクショと差異がある場合がありますのでご了承ください。
注意②
今までのハンズオン(前提条件・知識に記載)で実施した手順は基本省略して記載するのでご了承ください。
複雑な手順等は例外として記載する場合があります。
注意③
ハンズオンで作成したリソースについてはハンズオン終了後、各自削除をお願いします。
ゴール
- Amazon API Gateway(以降、API Gatewayと略)の概要が理解できている
- Amazon DynamoDB(以降、DynamoDBと略)の概要が理解できている
- REST APIの概要が理解できている
- リレーショナルデータベースとNoSQLデータベースの違いが理解できている
- API GatewayでREST APIを作成し、実行できる
- ステートマシンからDynamoDBにデータを格納する処理を作成できる
前提条件・知識
- 前回ハンズオンを実施していること
使用サービス紹介
本ハンズオンで触るAWSサービスを説明します。
その他サービスについては以降その都度説明いたします。
Amazon API Gateway
Amazon API Gatewayとは、AWSが提供する、APIの作成および管理を行うことができるフルマネージドサービスです。
作成したAPIはAmazon S3やAWS LambdaなどのAWSサービスと簡単に統合することができ、バックエンドとして利用することができます。
また、HTTPSリクエストを受け付けるAWS以外のサービスにもリクエストを転送することができます。
名前の通りAPIのゲートウェイ(入り口)となるサービスです。
2015年7月に一般公開されました。
以下の図は外部から AWS のバックエンドサービス利用を実現する仕組みをグラレコで解説より
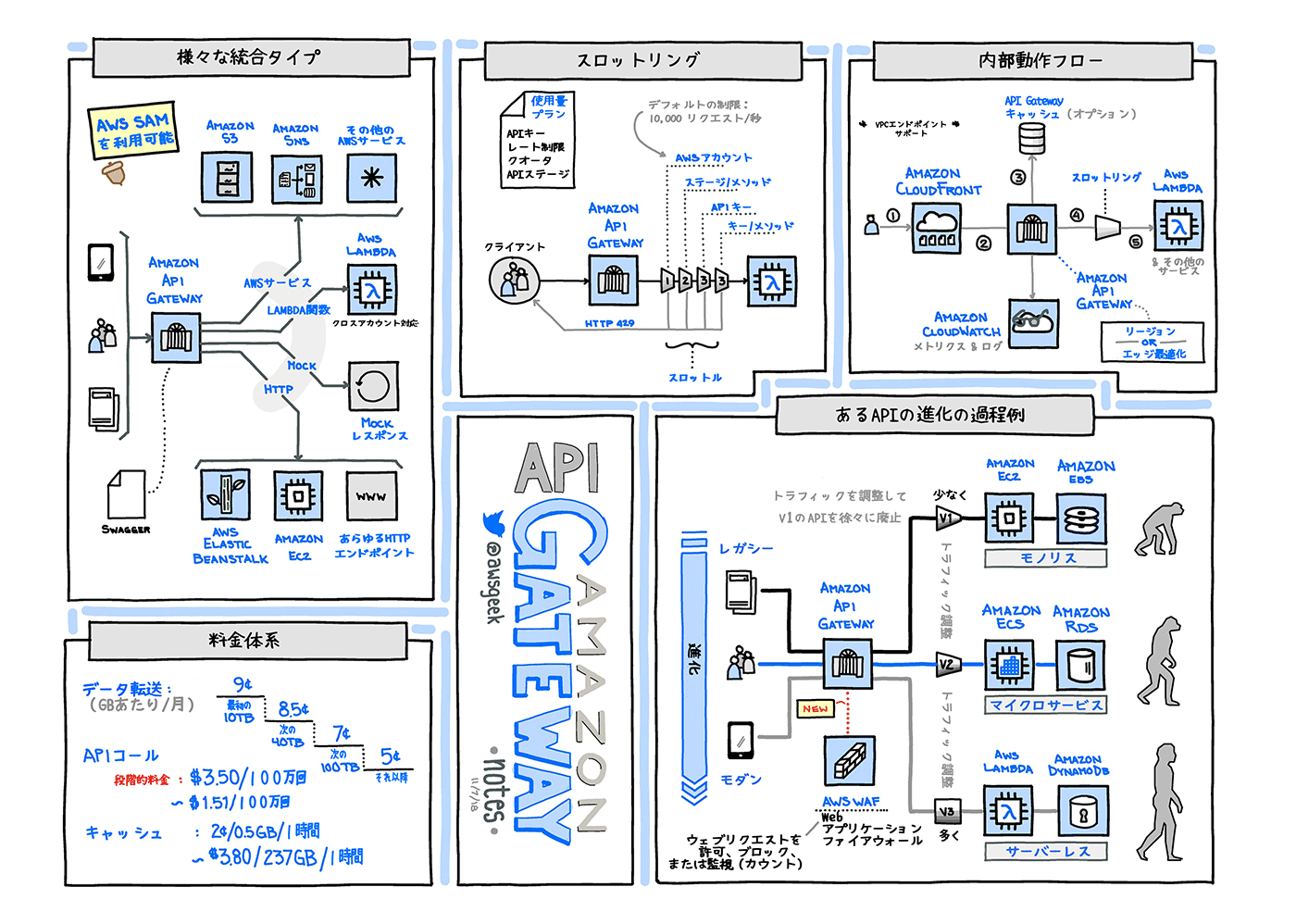
用語
| 用語 | 意味 |
|---|---|
| API | Application Programming Interfaceの略。主にソフトウェアやプログラム同士を定められたルールに従ってつなぐもののことを指す |
| Web API | HTTPなどのWeb技術によってやりとりするAPI |
| REST API | REST(Representational State Transfer)の原則に従って作成されたWeb API。この設計原則は現在主流であるが、GraphQLを使用したAPIが注目を集めている |
| マネージドサービス | サービスで使用するサーバの管理(セキュリティ、可用性、障害対応など)の一部を委託できるサービス |
| フルマネージドサービス | マネージドサービスで提供している内容に加え、より細かく管理業務を委託することができるサービス |
| サーバレスサービス | サーバの設置や管理不要(サーバを意識しない)で利用できるサービス |
| AWS Lambda | サーバの設置や管理不要でコードを実行できるサーバレスサービス(コンピューティングサービス) |
REST APIの4原則について
REST APIとは先ほど説明した通り、REST(Representational State Transfer)の原則に従って作成されたWeb APIを指します。
この原則は大きく4つに集約されます。
- 原則1:ステートレス
- 過去行ったHTTP通信による状態を記憶しておく必要がありません。
- HTTP通信のリクエストのメッセージに全て必要な情報が含まれており、各HTTP通信は独立、分離しています。
- 原則2:全ての情報(リソース)は汎用的な構文で一意に識別できる
- URIによってリソースの場所を文字列で表現できます。
- そのためURIのパス部分が名詞になる場合が多いです。例を以下に示します。
- URIによってリソースの場所を文字列で表現できます。
- 原則3:リソースを操作する命令の体系が予め定義・共有されている
- HTTPのGETやPOSTなどのメソッドで操作方法を表現します。例を以下に示します。
-
POST /user HTTP/1.1だとシステムにユーザを登録するようなAPI呼び出しを表します。 -
GET /animal/dogs HTTP/1.1だと犬の一覧情報を取得するようなAPI呼び出しを表します。
-
- このように、
GETは取得、POSTは登録など操作が定められています。
- HTTPのGETやPOSTなどのメソッドで操作方法を表現します。例を以下に示します。
- 原則4:接続性
- やりとりされる情報内部に、別の情報やその情報の別の状態へのリンクを含めることができます。
- イメージ図はこちらの記事から拝借しました。

Amazon DynamoDB
Amazon DynamoDBとは、AWSが提供する、フルマネージド・サーバレスなキーバリュー型NoSQLデータベースサービスです。
DynamoDBはAmazon.comの現CTO兼副社長のWerner Vogels氏が開発したDynamoという技術を採用しています。
このDynamoはショッピングシーズンの大量のトラフィックに対してスケーラビリティと可用性を併せ持ったデータベースが必要、というAmazonからの要望から生まれました。
1桁ミリ秒のパフォーマンス、最大99.999%の高可用性を実現しています。
2012年1月に一般公開されました。
以下の図は高速で柔軟な NoSQL データベースサービス。Amazon DynamoDB をグラレコで解説より
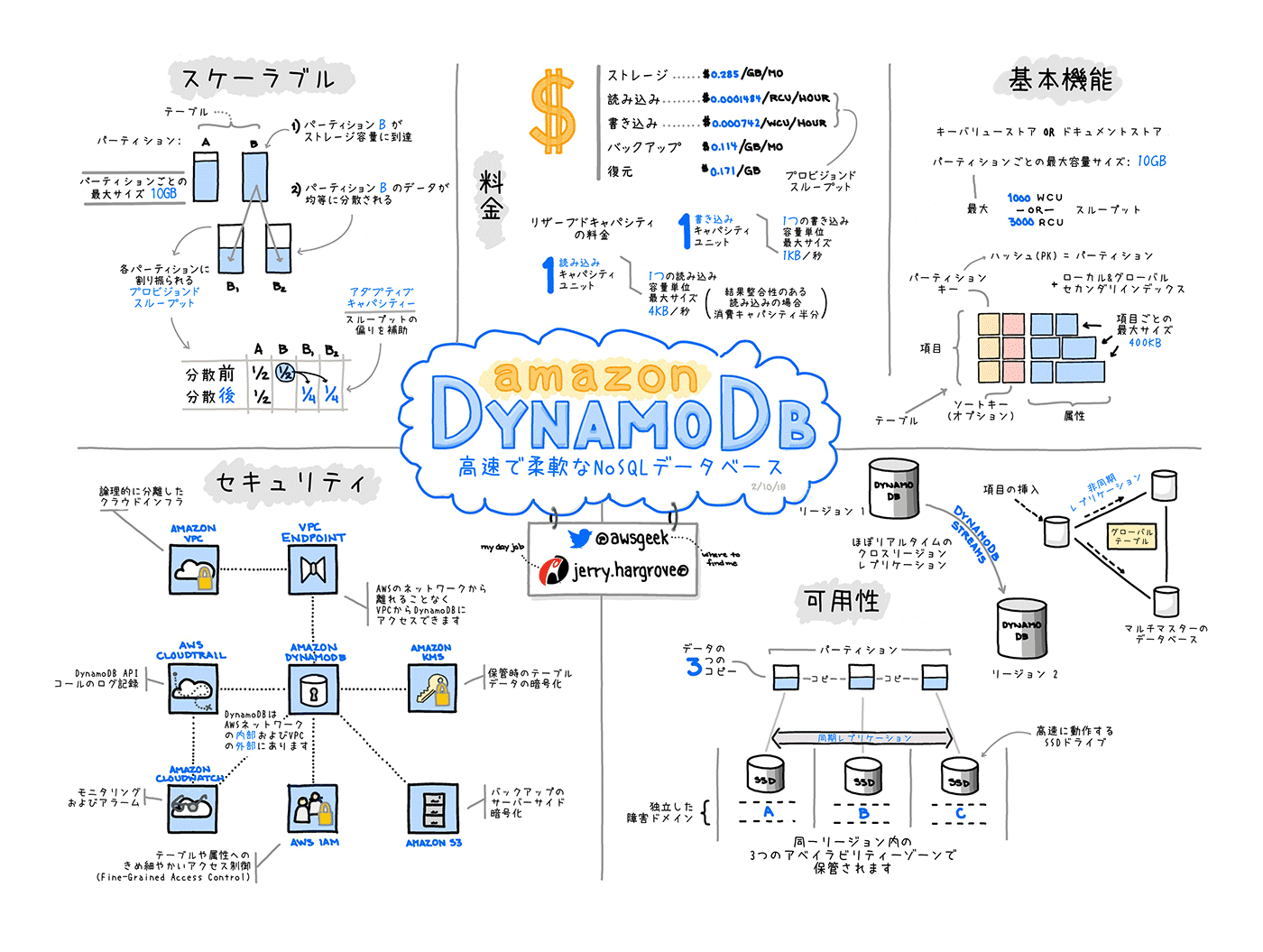
用語
| 用語 | 意味 |
|---|---|
| リレーショナルデータベース | 関連があるデータを表形式で管理するデータベース。関係モデルという理論が基礎となっている。データベース内のデータ操作は主にSQLを使用し行われる |
| NoSQLデータベース | リレーショナルデータベース以外のデータベースを指す。年々増加するデータ量、さまざまなデータ形式、サイズに対して柔軟に対応するため誕生した |
概念
DynamoDBの以下の概念についてAWS公式資料DynamoDB の基礎と設計 / DynamoDB Design Practiceを参考に説明します。
- キーバリュー型
- プライマリーキー
- Secondary Index
まず、キーバリュー型についてです。
DynamoDBはNoSQLデータベースであり、その中でもキーバリュー型の分類にあたります。
キーバリュー型はデータをキーとバリュー(値)の1対1の単純な構造で保持します。
このような単純な構造であるため、データの取得がしやすく、高速であるという特徴があります。

次に、プライマリーキーについてです。
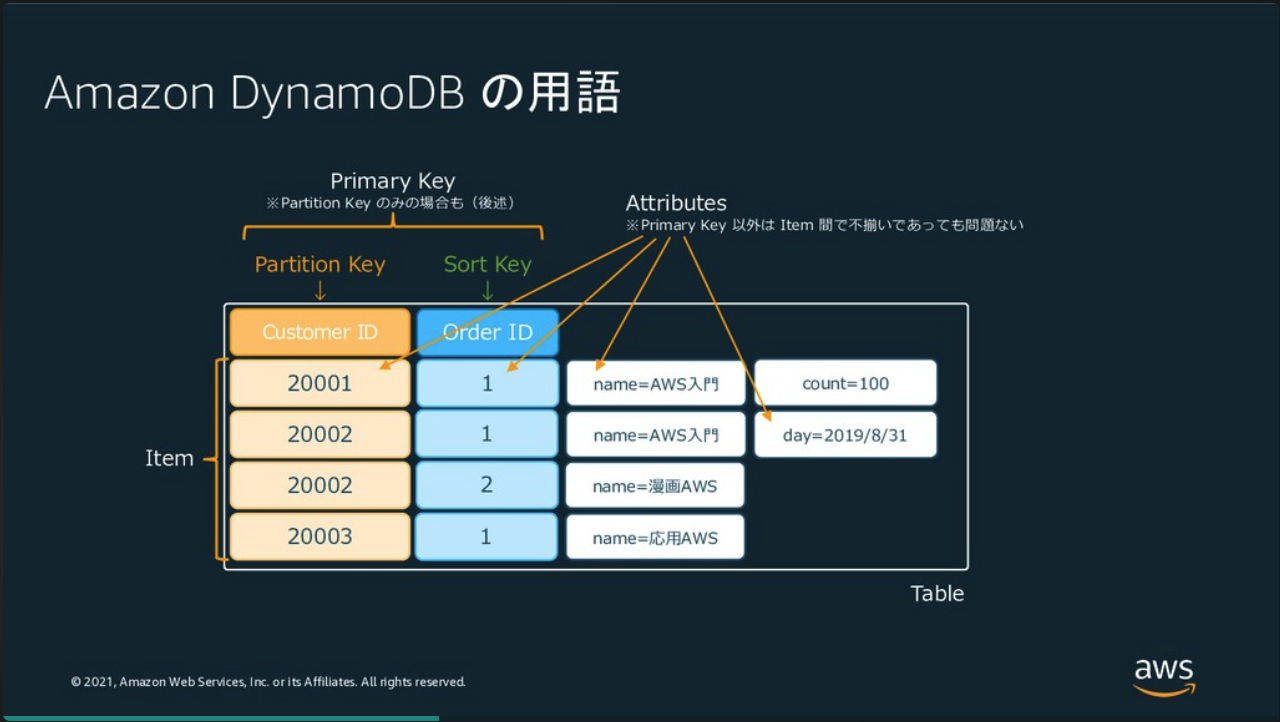
プライマリーキーはデータを一意に識別する項目を指します。
プライマリーキーにはPartition KeyとSort Keyの2種類があります。
Partition Keyはリレーショナルデータベースでいう、主キーに当たります。
Sort KeyはPartition Keyと組み合わせることでデータを一意にする項目です。
Partition KeyとSort Keyの組み合わせはリレーショナルデータベースでいう、複合主キーに当たります。
Partition KeyとSort Keyを条件にすれば、SQLのWHERE句のようにクエリ(検索)することができるようになります。
しかし、それ以外の項目は条件として指定することができません。
指定できるようにするためには項目をSecondary Indexとして指定する必要があります。
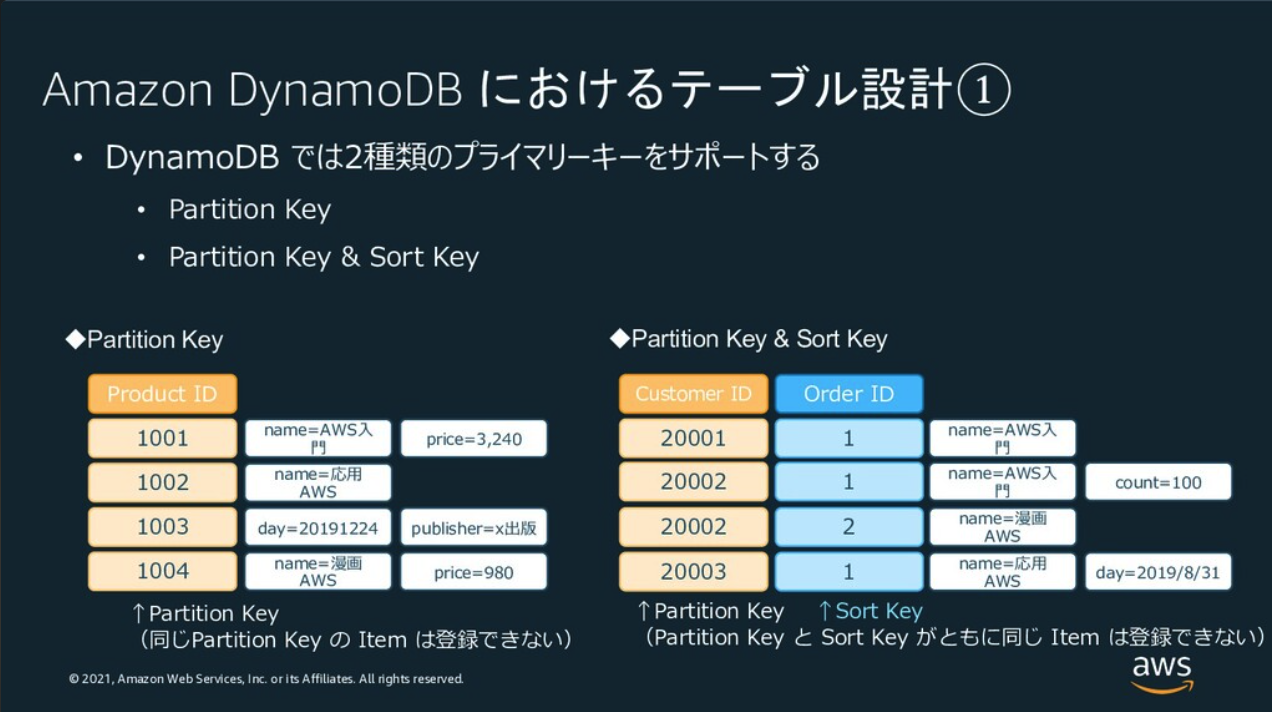
最後に、Secondary Indexについてです。
Secondary IndexはLocal Secondary Index(LSI)とGlobal Secondary Index(GSI)の2種類があります。
LSIはSort Keyの代わりとなるKeyを指定することができます。ただし、Partition Keyは同じです。
GSIはPartition Keyの代わりとなるKeyを指定することができます。テーブルにもう一つ検索可能なPartition Key(+ Sort Keyも指定可能)を追加するイメージです。ただ、GSIとした項目の属性は一意でなくても構いません。
以下に例を示します。
PKはPartition Key、SKはSort Key、GSI-PKはGSIのPartition Key、GSI-SKはGSIのSort Keyを表します。
| Name(PK) | Color(SK) | Season(GSI-SK) | Kind(LSI) | Country(GSI-PK) |
|---|---|---|---|---|
| Apple | Red | Winter | Fruit | Japan |
| Apple | Green | Winter | Fruit | NZ |
| Orange | Orange | Summer | Fruit | USA |
| Tomato | Red | Winter | Vegetable | Japan |
以上のテーブル設定で検索条件に指定可能な項目は以下になります。
- Name(PK)
- Name(PK) + Color(SK)
- Name(PK) + Kind(LSI)
- Country(GSI-PK)
- Country(GSI-PK) + Season(GSI-SK)

AWSが提供するデータベースサービス
AWSが提供しているデータベースサービスはリレーショナルデータベースサービス、NoSQLデータベースサービスの大きく分けて2種類あります。
また、ユースケースごとにさまざまなサービスを提供しています。
-
リレーショナルデータベースサービス
-
NoSQLデータベースサービス
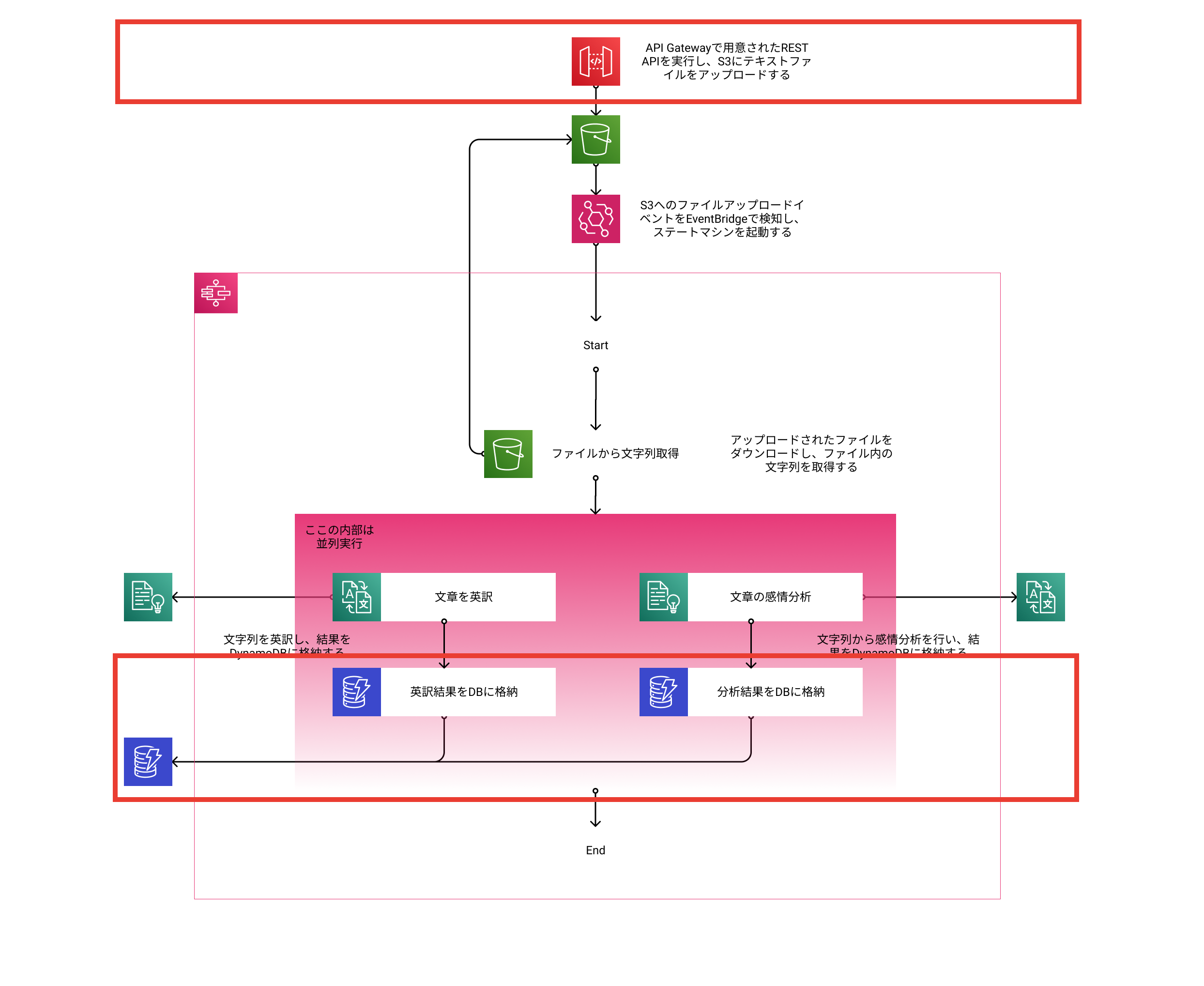
今回ハンズオンで作成する構成
今回は赤枠で囲まれた部分をハンズオンで作成します。
処理の流れとしては以下になります。(前回記事で記載した流れは省略しています)
- Amazon API Gatewayで用意したREST APIを実行し、Amazon S3に日本語文章が記載されたテキストファイルをアップロードする
- EventBridgeで起動したステートマシンは以下の処理を行う
- Amazon Translate、Amazon Comprehendの結果をAmazon DynamoDBに登録する
ハンズオン
S3バケットにファイルをアップロードするREST APIをAPI Gatewayに定義する
IAMロールにポリシーを追加
S3バケットにファイルをアップロードするためには、API Gatewayにアップロードするための権限が必要です。
Step Functionsと同様にIAMロールに必要な権限を付与します。
必要な権限はs3:PutObjectです。
実はこの権限は、第1回目「IAMロールに権限(IAMポリシー)を追加」でIAMロールに付与したAmazonS3FullAccessポリシーにすでに含まれています。
実際に当該権限が付与されているか確認します。
画面上部の検索窓にiamと入力し、表示されたIAMをクリックしてください。

左側または中央にあるロールをクリックしてください。

一覧の検索窓にユーザ名を入力し、当該IAMロールを選択します。

許可タブを選択し、許可ポリシー一覧に表示されているAmazonS3FullAccessリンクをクリックしてください。

AmazonS3FullAccessポリシーの詳細画面に遷移します。
許可タブを選択し、このポリシーで定義されている許可一覧のサービス蘭に表示されているS3リンクをクリックしてください。

再び許可タブを選択し、検索窓にputobjectと入力してください。
このポリシーで定義されている許可一覧の書き込みセクションのアクション蘭にPutObjectが表示されていることを確認してください。

IAMロールに信頼関係の追加
API GatewayにIAMロールの権限の使用を許可するため、信頼ポリシーを追加します。
IAMロールの詳細画面に戻り、信頼関係タブを選択し、信頼ポリシーを編集をクリックしてください。

続いて、信頼ポリシーを追加します。既存のStatementオブジェクトに以下のJsonオブジェクトを追加し、ポリシーを更新ボタンを押下してください。
{
"Effect": "Allow",
"Principal": {
"Service": "apigateway.amazonaws.com"
},
"Action": "sts:AssumeRole"
}

APIの作成
画面上部の検索窓にapiと入力し、表示されたAPI Gatewayをクリックしてください。

作成するAPIの種類を選択します。
今回はREST APIを作成します。(プライベートではない)REST APIの構築ボタンをクリックしてください。

APIのプロトコルや名前などを入力します。
プロトコルを選択するはRESTになっていることを確認してください。
新しいAPIの作成は新しいAPIを選択してください。
つづいて名前と説明の入力です。
API名は<ユーザ名>APIとしてください。
説明は入力不要です。
エンドポイントタイプはリージョンを選択してください。他にエッジ最適化、プライベートが選択できます。
細かい説明は省略しますが、リージョンはリージョンにデプロイされるパブリックなAPI、エッジ最適化は高パフォーマンスなAPI、プライベートはパブリックからアクセスできないAPIという感じです。
入力し終わったら、画面右下APIの作成ボタンをクリックしてください。

リソースの作成
フォルダを表すリソースを作成します。
左メニューリソースが選択されていることを確認し、アクションプルダウンを選択、リソースの作成をクリックしてください。
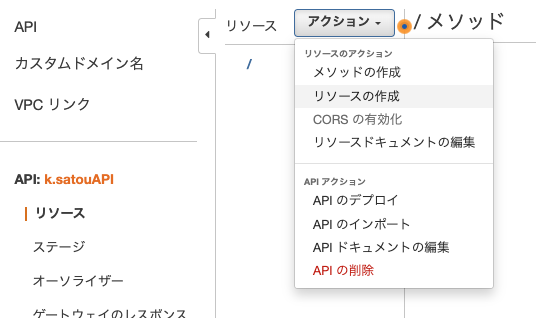
リソース情報を入力します。
リソース名にbucketと入力してください。
リソースパスは{bucket}と入力してください。
リソースパスを中括弧で指定することでその部分は可変項目になります。
可変項目にしたい場合、この後のURLパスパラメータの設定も必要です。
入力し終わったら、画面右下リソースの作成ボタンをクリックしてください。
作成が終わるとリソースに/{bucket}が追加されていることを確認し、クリックしてください。
そして、再度アクションプルダウンを選択、リソースの作成をクリックしてください。

bucketリソース配下のリソース情報を入力します。
リソース名にfolderと入力してください。
リソースパスは{folder}と入力してください。
入力し終わったら、画面右下リソースの作成ボタンをクリックしてください。

作成が終わるとリソースに/{folder}が追加されていることを確認し、クリックしてください。
そして、再度アクションプルダウンを選択、リソースの作成をクリックしてください。

folderリソース配下のリソース情報を入力します。
リソース名にobjectと入力してください。
リソースパスは{object}と入力してください。
入力し終わったら、画面右下リソースの作成ボタンをクリックしてください。

メソッドの作成
リソースへの操作を表すメソッドを作成します。
objectリソースの作成が終わるとリソースに/{bucket}/{folder}/{object}が追加されていることを確認し、クリックしてください。
そして、アクションプルダウンを選択、メソッドの作成をクリックしてください。

/{bucket}/{folder}/{object}リソース配下にメソッドを選択するプルダウンが表示されます。
PUTを選択し、チェックマークをクリックしてください。

PUTメソッドの情報を入力します。
統合タイプはAWSサービスを選択してください。
AWSリージョンはap-northeast-1を選択してください。
AWSサービスはSimple Storage Service (S3)を選択してください。
AWSサブドメインは空で構いません。
HTTPメソッドはPUTを選択してください。
アクションの種類はパス上書きの使用を選択してください。
パス上書き(省略可能)は{bucket}/{folder}/{object}と入力してください。
※パスの上書きを使用すると、API GatewayはリクエストをAmazon S3のREST APIに対応するリクエストに変換して転送してくれます。
実行ロールはIAMロールにポリシーを追加で扱ったIAMロールのARNを入力してください。
コンテンツの処理はパススルーを選択してください。
入力し終わったら、画面右下保存ボタンをクリックしてください。

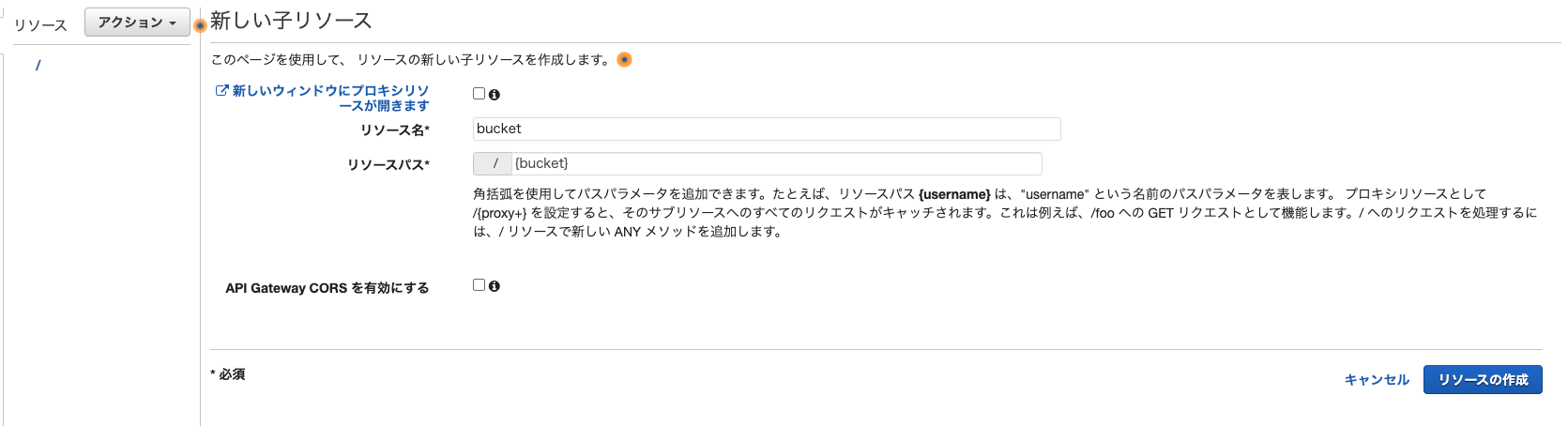
パラメータマッピング
リクエスト情報を加工し、バックエンドのAWSサービスに渡したり、AWSサービスから受け取った返却値を加工し、APIのレスポンスとして返却する設定を行います。
/{bucket}/{folder}/{object}リソースのPUTメソッドを選択した状態で、統合リクエストリンクをクリックしてください。

URLパスパラメータを選択し、パスの追加をクリックしてください。
この設定はリソースの作成で指定したパスパラメータを有効にするため必要です。
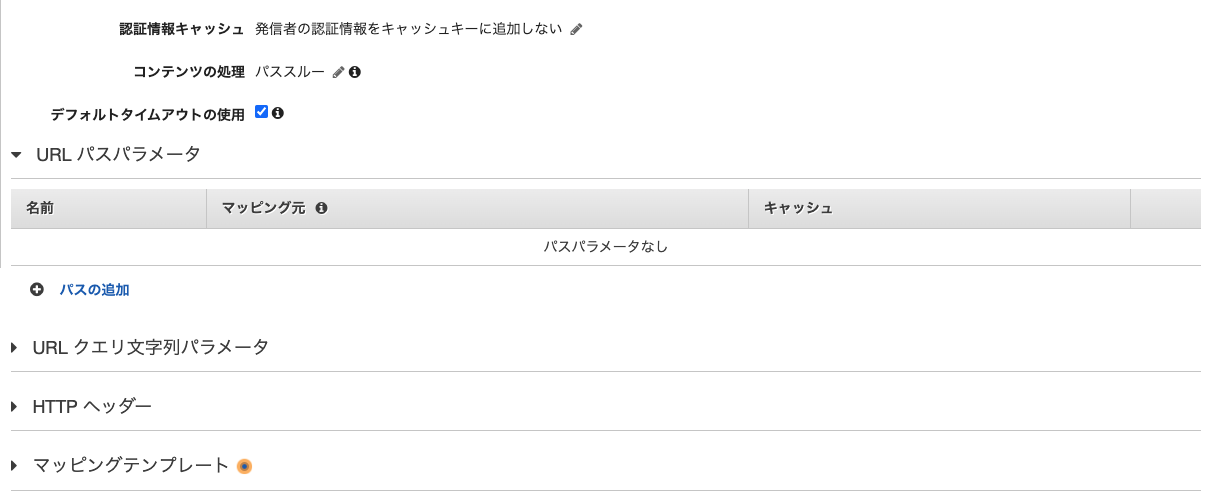
名前にbucketと入力してください。
メソッドの作成のパス上書き(省略可能)で{bucket}/{folder}/{object}を指定しました。
この{bucket}の値と名前に指定する値を同じにすることでリクエスト時に指定したパスの値が自動的にマッピングされるようになります。
例えば、パス上書き(省略可能)が{hoge}/{folder}/{object}である場合、名前もhogeにしなければ、パスの値がマッピングされず、パス上書きで指定した値そのままでリクエストされます。
マッピング元にmethod.request.path.bucketと入力し、チェックマークをクリックしてください。
末尾部分bucketはリソースの作成で指定したリソースパス(中括弧は除く)と一致させる必要があります。

再度パスの追加をクリックしてください。
名前にfolderと入力してください。
マッピング元にmethod.request.path.folderと入力し、チェックマークをクリックしてください。

再度パスの追加をクリックしてください。
名前にobjectと入力してください。
マッピング元にmethod.request.path.objectと入力し、チェックマークをクリックしてください。

APIのデプロイ
作成したAPIを実際呼べるようにデプロイを行います。
左メニューリソースを選択し、アクションプルダウンを選択、APIのデプロイをクリックしてください。

デプロイに関する情報を入力します。
デプロイされるステージは[新しいステージ]を選択してください。
ステージ名はv1と入力してください。
入力し終わったら、右下デプロイボタンをクリックしてください。

APIファイルアップロード確認
APIはCloudShellでcurlコマンドを叩いて実行します。
CloudShellはブラウザベースのコマンドラインです。Amazon Linuxベースであり、手軽にShellを実行させることができます。
curlコマンドはさまざまなプロトコル(HTTPなど)で通信を行うことができるコマンドです。
画面上部の右側にCloudShellのアイコンがあるのでクリックしてください。

CloudShellの右上のアクションプルダウンをクリックしてください。
ファイルのアップロードをクリックし、翻訳、感情分析対象のテキストファイルを選択してアップロードしてください。

lsコマンドでアップロードしたファイルが表示されることを確認してください。

ファイルをアップロードするAPIを実行するcurlコマンドは以下です。CloudShellで実行してください。
APIIDはAPI GatewayのAPI一覧から確認してください。
curl -i --location --request PUT 'https://<APIID>.execute-api.ap-northeast-1.amazonaws.com/v1/<S3バケット名>/uploads/<アップロードしたファイル名>' --data '@<アップロードしたファイル名>'
実行例は以下になります。HTTP/2 200が表示されたらAPIの実行に成功です。
[cloudshell-user@ip-10-6-53-91 ~]$ curl -i --location --request PUT 'https://<APIID>.execute-api.ap-northeast-1.amazonaws.com/v1/<S3バケット名>/uploads/<アップロードしたファイル名>' --data '@<アップロードしたファイル名>'
HTTP/2 200
date: Mon, 21 Aug 2023 16:10:06 GMT
content-type: application/json
content-length: 0
x-amzn-requestid: xxxxxxxxxxxxxxxxx
x-amz-apigw-id: xxxxxxxxxxxxxxxxx
x-amzn-trace-id: xxxxxxxxxxxxxxxxx
S3バケットのuploadsフォルダに遷移し、ファイルがアップロードされていることを確認してください。
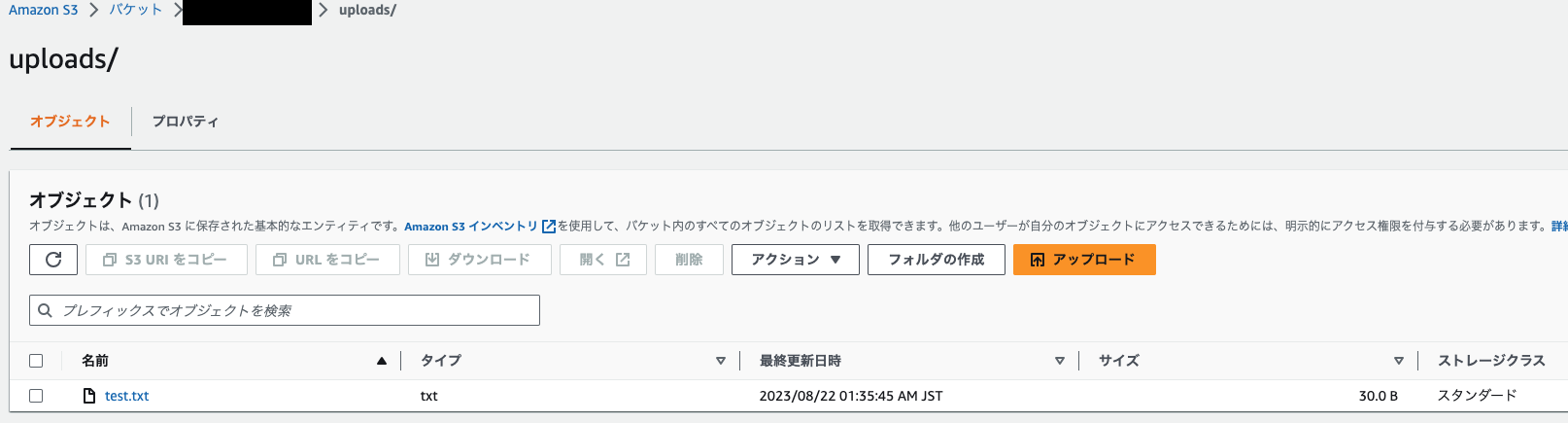
英訳結果、感情分析結果をDynamoDBに格納する
テーブルを設計する
天下り的ですが、今回は以下の項目をテーブルに格納させたいと思います。
実施日時(ExecutionDateTime)(PK)、翻訳後テキスト(TranslatedText)、センチメント(Sentiment)(GSI-PK)
実施日時はPartition Keyとし、フォーマットはYYYY-MM-DDThh:mm:ss.fffZとします。
翻訳後テキストは出力文字列をそのまま格納します。
センチメントは検索項目としたいという想定でGSIにします。出力文字列をそのまま格納します。
今回はテーブルがシンプルであるため、設計は楽でしたが、複雑な場合、ER図作成などデータモデリングをしていく必要があります。
詳細は以下の記事を参照ください。
テーブルを作成する
設計に従ってDynamoDBのテーブルを作成します。
画面上部にある検索窓にdynamoと入力し、検索結果にDynamoDBが表示されるので、クリックしてください。

左メニューテーブルを選択するとテーブル一覧が表示されます。
一覧右上のテーブルの作成ボタンをクリックしてください。

作成するテーブルに関する情報を入力します。
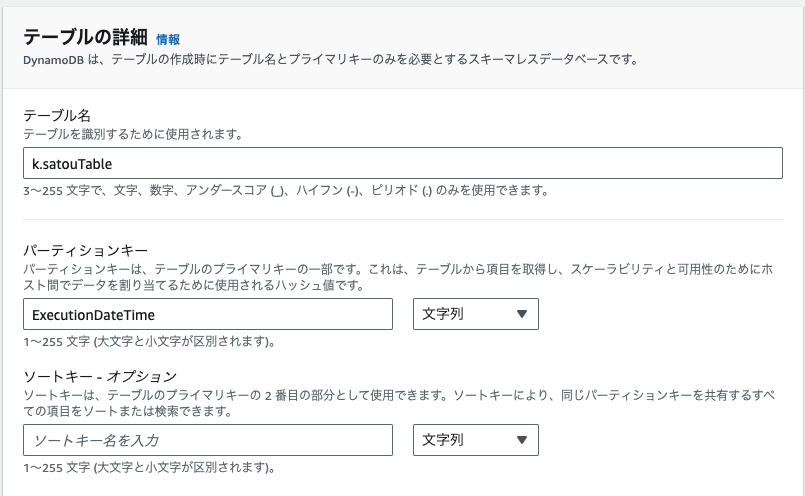
テーブルの詳細セクションの入力です。
テーブル名は<ユーザー名>Tableにしてください。
パーティションキーはExecutionDateTimeと入力し、文字列を選択してください。
ソートキー - オプションは未入力で構いません。
テーブル設定セクションの入力です。
テーブル設定は設定をカスタマイズを選択してください。

テーブルクラスセクションの入力です。
テーブルクラスはDynamoDB標準を選択してください。

読み込み/書き込みキャパシティーの設定セクションの入力です。
キャパシティーモードはプロビジョンドを選択してください。
読み込みキャパシティーのAuto Scalingはオフにしてください。
読み込みキャパシティーのプロビジョンドキャパシティーユニットは1にしてください。
書き込みキャパシティーのAuto Scalingはオフにしてください。
書き込みキャパシティーのプロビジョンドキャパシティーユニットは1にしてください。

セカンダリインデックスセクションの入力です。
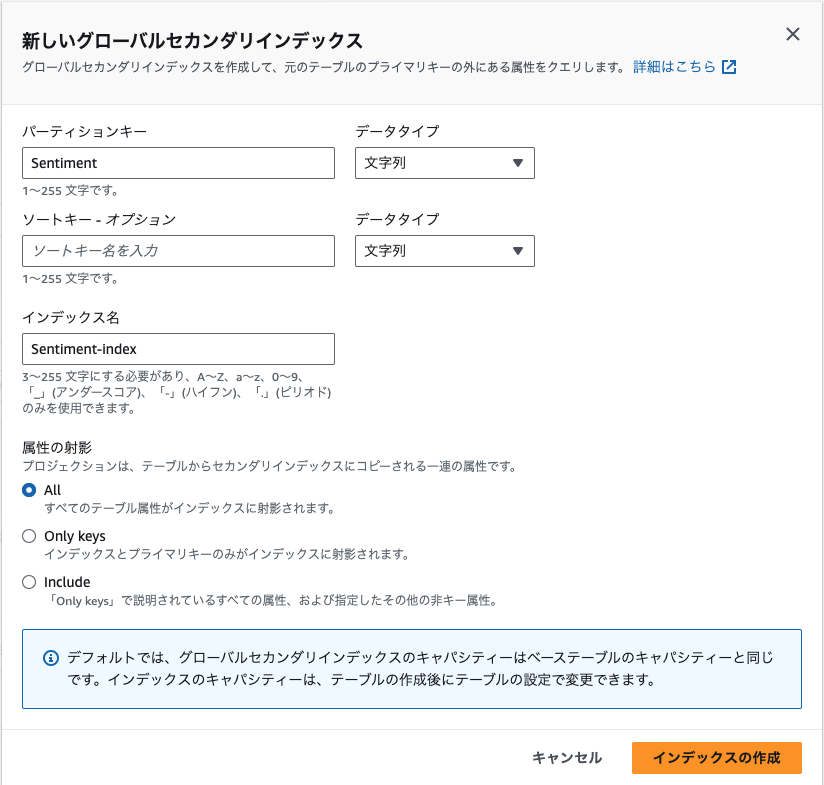
今回センチメントをグローバルインデックスに指定するため、グローバルインデックスの作成ボタンをクリックしてください。
なお、ローカルインデックスの作成はテーブル作成時のみ実施可能です。必要な場合忘れずに追加してください。(GSIはいつでも追加可能です)

パーティションキーにSentimentと入力し、文字列を選択してください。
ソートキー - オプションは未入力で構いません。
インデックス名は自動的に入力されるSentiment-indexであることを確認してください。
属性の射影はAllを選択してください。
この値はセカンダリインデックスでの検索結果で何を返却するかを指定します。指定項目はKEYS_ONLY、INCLUDE、ALLの3種類です。
KEYS_ONLYは文字通り、キーの値のみ返却する設定です。
INCLUDEはキーの他指定した項目を返却する設定です。
ALLは検索された行を全て返却する設定です。
入力し終わったら、インデックスの作成ボタンをクリックしてください。
それ以降の値はデフォルト値で構いません。
画面最下部右下のテーブルの作成ボタンをクリックしてください。
テーブル一覧に遷移します。テーブルの状態がアクティブになれば作成完了です。

さて、作成するテーブルに格納したい情報は以下でした。
しかし、テーブル作成時に翻訳後テキストについて何も指定はせず、実施日時(PK)とセンチメント(GSI-PK)のみ入力しました。
リレーショナルデータベースに慣れていると翻訳後テキストはテーブルに格納できないのではないかと感じます。本当でしょうか?
実施日時(ExecutionDateTime)(PK)、翻訳後テキスト(TranslatedText)、センチメント(Sentiment)(GSI-PK)
DynamoDBはキーバリュー型のNoSQLでありスキーマレスです。リレーショナルデータベースとは異なり、格納することができます。
以下の通り、プライマリーキー以外は何を入力しても構わないのです。
結果を格納する
テーブルができたのでStep Functionsのステートマシンから必要なデータを格納するステートを追加しましょう。
前回ハンズオンで作成したステートマシンのWorkflow Studioに移動してください。
次に、左メニューでアクションタブを選択し、検索窓にdynamoと入力してください。
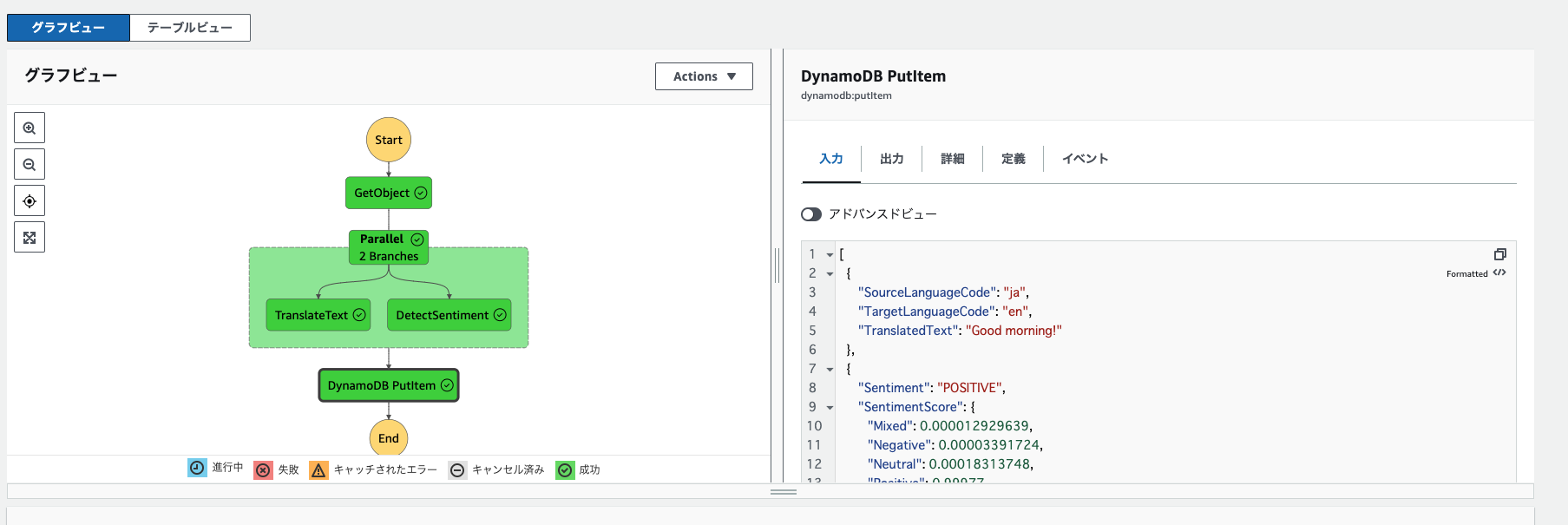
検索結果のPutItemステートをParallelの箱の下にそれぞれドラッグ&ドロップしてください。

Amazon Translateの翻訳結果を格納する処理を追加します。
Amazon Translateのステートを選択してください。
APIパラメータのJsonにどのテーブルのどのカラムにどのような値をINSERTするか定義します。
Jsonの構文は以下の通りです。
【データ型】は文字列や数値を表します。Sは文字列、Nは数値を表します。その他は以下を参照ください。
{
"TableName": "【テーブル名】",
"Item": {
"【カラム名】": {
"【データ型】": "【値】"
}
}
}
格納するデータの元となるParallelステート後のJsonを以下に示します。
[
{
"SourceLanguageCode": "ja",
"TargetLanguageCode": "en",
"TranslatedText": "Good morning!"
},
{
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000012929639,
"Negative": 0.00003391724,
"Neutral": 0.00018313748,
"Positive": 0.99977
}
}
]
翻訳後テキスト(TranslatedText)、センチメント(Sentiment)(GSI-PK)は上記Jsonから取得できそうですが、実施日時(ExecutionDateTime)(PK)はどのように取得するのでしょうか?
方法は色々ありますが、今回はステートマシンのContextオブジェクトから取得します。
Contextオブジェクトはステートマシン起動時に生成されるオブジェクトでステートマシンのメタ情報が含まれます。
この情報にはExecution.StartTimeという、ステートマシンの起動時間(UTC)が含まれているのでこれを格納することにします。
Contextオブジェクトへのアクセスは$$ですることができます。
以下が今回APIパラメータに指定する値です。入力してください。
{
"TableName": "【テーブル名】",
"Item": {
"ExecutionDateTime": {
"S.$": "$$.Execution.StartTime"
},
"TranslatedText": {
"S.$": "$.[0].TranslatedText"
},
"Sentiment": {
"S.$": "$.[1].Sentiment"
}
}
}
入力が終わったら、ステートマシンの状態を保存してください。
IAMロールにポリシーを追加
このままではステートマシンにDynamoDBを操作する権限がないため実行に失敗します。
ステートマシンに付与しているIAMロールに必要な権限を付与します。
画面上部の検索窓にiamと入力し、表示されたIAMをクリックしてください。
左側または中央にあるロールをクリックしてください。
一覧の検索窓にユーザ名を入力し、当該IAMロールを選択します。
許可タブを選択すると許可ポリシーが表示されます。
その右上の許可を追加プルダウンを選択し、ポリシーのアタッチをクリックしてください。
検索窓にdynamoと入力し、Enterしてください。
ポリシーAmazonDynamoDBFullAccessが表示されるのでチェックし、右下の許可を追加をクリックしてください。

許可ポリシーの一覧にAmazonDynamoDBFullAccessが表示されたら追加完了です。

処理確認
今まで作成したものが期待通り動くか確認します。
最初にAPI Gatewayで作成したファイルアップロードAPIの実行です。
APIファイルアップロード確認と同様にCloudShellでcurlコマンドを実行し、S3にファイルをアップロードしてください。
次に、ステートマシンの実行の確認です。
作成したステートマシンの直近の実行結果を確認し、全てのステートが成功していることを確認してください。
最後に、DynamoDBにデータが格納されているかの確認です。
DynamoDBのダッシュボードに遷移し、左メニュー項目を探索をクリックしてください。
テーブルで自分が作成したテーブルを選択し、期待通りのデータが表示されていることを確認してください。

参考
- https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/integrating-api-with-aws-services-s3.html
- https://tenshoku-careerchange.jp/column/3737/
- https://dev.classmethod.jp/articles/aws-release-durable-redis-amazon-memorydb-for-redis/
- https://tech.nri-net.com/entry/aws_history_and_chronology_all
- https://xtech.nikkei.com/it/article/NEWS/20120119/378871/