背景
- 訓練セットと検証セットの各ラベルの画像群は、同じような画像で構成されていることを確認したかった
- ただ、70000枚を全て目視は辛いし、「同じような」と言ってもその定義は難しい
- そこで、単純に画像の平均値(平均画像)を見比べることにした
MNISTの概要
-
手書き数字("0"~"9")のデータベース
-
例

0 1 2 3 4 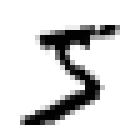
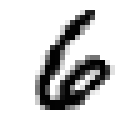
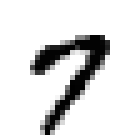
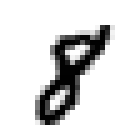
5 6 7 8 9 -
手書き数字認識のHello worldとして利用されている
-
画像の大きさは 28x28
-
0(白)~255(黒)のグレースケール画像
-
文字は中央寄りに配置されている
-
2つのデータセットで構成される
- 訓練セット(60000枚): パターンを見つけるために使う
- 検証セット(10000枚): 見つけたパターンの検証に使う
-
各セットは画像と、その画像が0~9のどの数字なのかを示すラベルの組になっている
-
"0"~"9"のラベル数は、10等分されているのではなく、若干ばらつきがある
|ラベル|0|1|2|3|4|5|6|7|8|9|
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
|訓練セット|5923|6742|5958|6131|5842|5421|5918|6265|5851|5949|
|検証セット|980|1135|1032|1010|982|892|958|1028|974|1009| -
様々な"0"





- 訓練セットの5923枚の"0"の中から、10枚ピックアップ
本題
事前情報
- 「平均画像」という用語が正しいのかあやしいが、本記事においては、「画像の同じ座標のピクセル値を合算して、ラベル数で割って生成した画像」とする。小数点は四捨五入。
- 例えば"0"の場合は5923で割る
- オリジナルの画像は28x28で小さくてピクセルが見えづらいので5倍に拡大している
convert input.png -filter Point -resize 140x140 +antialias output.png- 参考: http://www.alecjacobson.com/weblog/?p=411
平均画像の比較
各セットでラベル毎に生成した平均画像は以下の通り。
| ラベル | 訓練セット | 検証セット |
|---|---|---|
| 0 |  |
 |
| 1 |  |
 |
| 2 | 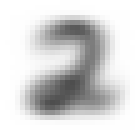 |
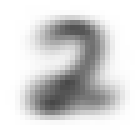 |
| 3 |  |
 |
| 4 |  |
 |
| 5 |  |
 |
| 6 | 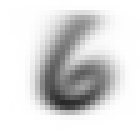 |
 |
| 7 |  |
 |
| 8 | 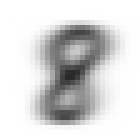 |
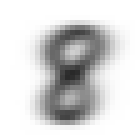 |
| 9 | 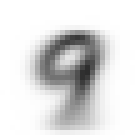 |
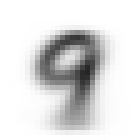 |
所感
- 平均化すると、想像以上にぱっと見は区別がつかないことがわかった
- 目視だと256階調の識別ができないからかもしれない
- 0(真っ白)も1(ほぼ白)も白に見える
- 目視だと256階調の識別ができないからかもしれない
- 違いがなんとなくわかるのは、"6"の上部と"9"の下部
次にやってみたいこと
- 訓練セットの平均画像を使って、検証セットの画像の分類