はじめに
今回は、Ollama・Langchain・Streamlitを使用して、ローカルで動く、RAGを使ったチャットボットを作成しました。自身の学習用に残します。他の方の学習に少しでも役立てると嬉しいです!
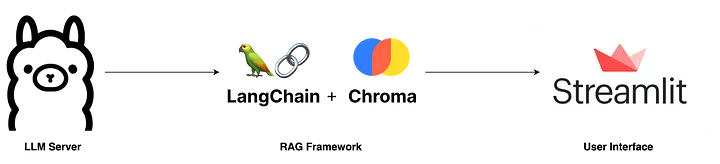
LLM Server
このアプリの最も重要な要素の一つです。Ollamaは、Llama2やLLava、Phiなどのオープンに公開されているLLM(大規模言語モデル)を手元のPCやサーバーで動かすことが出来るツールのことです。OllamaがどのようにローカルLLMを呼び出しているかはこちらが参考になりました。
RAG
RAGの使用にはベクトルデータベースが必要となります、今回は高速な検索性能が特徴でオープンソースのChromaDBを使用しました。RAGを使用するアプリケーションでよく使用されるライブラリにはLangchainやLLamaIndexなどがあります。ChromaDBとの連携性が高く、また私が今学習しているためLangchainを今回は使用しました。
RAGとは
外部の知識ベースから事実を検索して、最新の正確な情報に基づいてLLMに回答を生成させることで、ユーザーの洞察をLLMの生成プロセスに組み込むというAIフレームワークのこと
User Interface
StreamlitはPythonライブラリであり、素早く簡単にUIを構築、Webアプリケーションを作成できます。
やること
- Setup Ollama
- Build RAG Pipeline
- Draft Simple UI
Setup Ollama
まず、ollama.com にアクセスし、使用するOSに適したアプリをダウンロードしましょう。
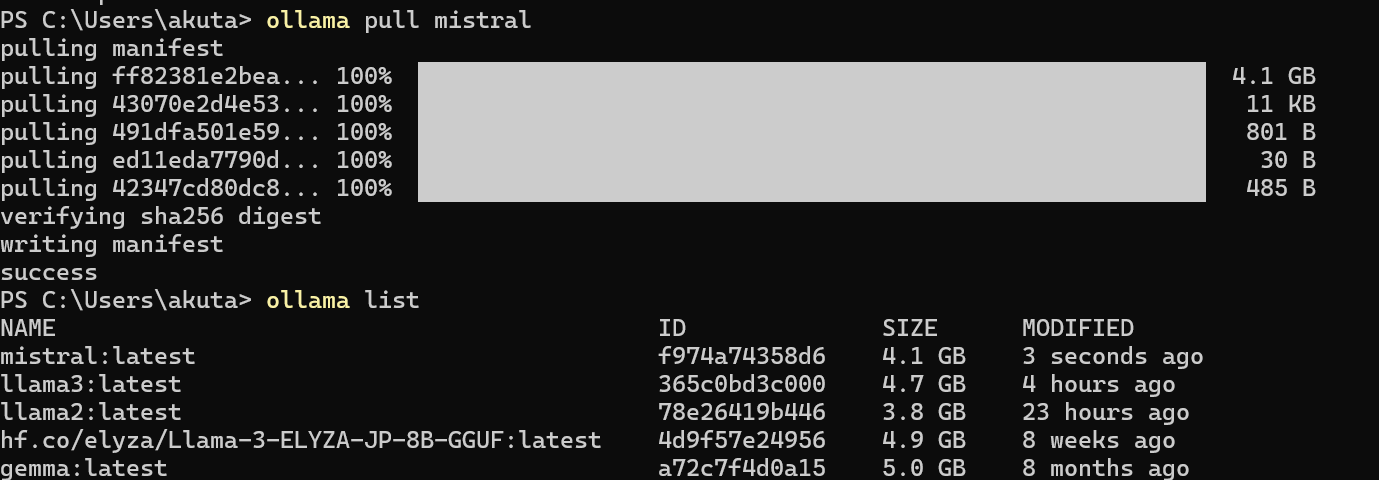
次に、ターミナルを開き、以下のコマンドを実行して最新の Mistral-7B モデルを取得します。Ollamaでは他にも多くのLLMが利用可能ですが、Mistral-7Bはコンパクトなサイズでありながら品質も高いので今回使用しました。
ollama pull mistral
その後、以下のコマンドを実行して、モデルが正しく取得されたか確認してください。
ollama list
ターミナルの出力は以下のようになるはずです
次に、LLMサーバーがまだ起動していない場合は、以下のコマンドでサーバーを起動してください。
ollama serve
もし、以下のようなエラーメッセージが表示された場合
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
これはサーバーが既に起動していることを示していますので、無視して次のステップに進んでください。
Build RAG Pipeline
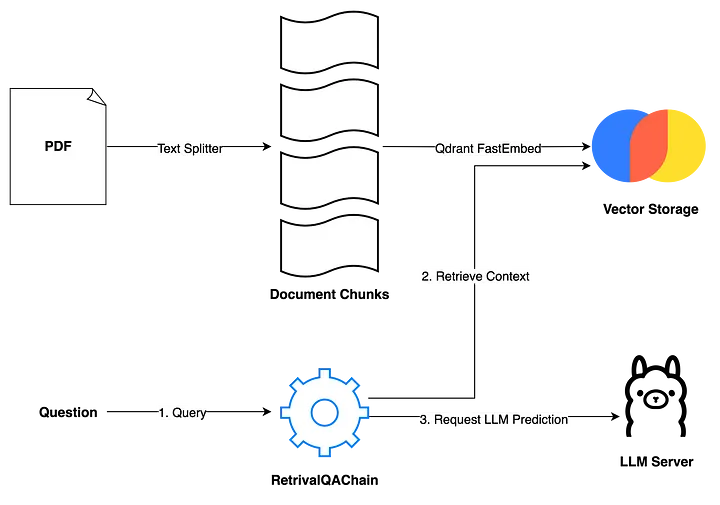
次のステップは、RAGアプリケーションの構築です。学習用のシンプルなアプリケーションを作成するため主に2つのメソッド、ingest メソッド と ask メソッド を用意します。
ingest メソッド
このメソッドはファイルパスを受け取り、以下の2ステップでそのファイル内のデータをベクトルデータベースにロードします。
1. ドキュメントの分割
- ドキュメントを小さなチャンク(塊)に分割します(Chanking)。このプロセスは、大規模なテキストデータを効率的に扱い、モデルがテキストの全体的な意味を失うことなく、各セグメントの内容を理解しやすくするために重要です
2. ベクトル化と保存
- 分割されたチャンクを
Qdrant FastEmbeddingsを使用してベクトル化し、ChromaDBに保存します
ask メソッド
このメソッドはユーザーのクエリを処理します。
ユーザーが質問を入力すると、RetrievalQAChain を使用して、ベクトル類似性検索により関連するコンテキスト(ドキュメントチャンク)を取得します。
ユーザーの質問と取得したコンテキストを基にプロンプトを作成し、LLMサーバーにリクエストを送信します。
これにより、ユーザーの質問に対して適切な回答を生成できます。
上記を実装したコードが以下になります。rag.pyとして保存してください。
from langchain_community.vectorstores import Chroma
from langchain_community.chat_models import ChatOllama
from langchain_community.embeddings import FastEmbedEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain.vectorstores.utils import filter_complex_metadata
class ChatPDF:
vector_store = None
retriever = None
chain = None
def __init__(self):
self.model = ChatOllama(model="llama3")
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
self.prompt = PromptTemplate.from_template(
"""
<s> [INST] You are an assistant for question-answering tasks. Use the following context to answer the question.
If you don't know the answer, simply say you don't know. Use a maximum of three sentences and be concise in your response. [/INST] </s>
[INST] Question: {question}
Context: {context}
Answer: [/INST]
"""
)
def ingest(self, pdf_file_path: str):
docs = PyPDFLoader(file_path=pdf_file_path).load()
chunks = self.text_splitter.split_documents(docs)
chunks = filter_complex_metadata(chunks)
vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings())
self.retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 3,
"score_threshold": 0.5,
},
)
self.chain = ({"context": self.retriever, "question": RunnablePassthrough()}
| self.prompt
| self.model
| StrOutputParser())
def ask(self, query: str):
if not self.chain:
return "Please, add a PDF document first."
return self.chain.invoke(query)
def clear(self):
self.vector_store = None
self.retriever = None
self.chain = None
さらなる実装の詳細
ingest メソッド
-
PDFファイルの読み込み
ユーザーがアップロードしたPDFファイルを読み込むために、PyPDFLoaderを使用します -
チャンク分割
Langchain が提供するRecursiveCharacterSplitterを使用して、このPDFを小さなチャンクに分割します -
メタデータのフィルタリング
filter_complex_metadata関数を使用して、ChromaDBでサポートされていない複雑なメタデータをフィルタリングします -
ベクトルデータベース
ベクトルデータベースにはChromaDBを使用し、埋め込みモデルとしてQdrant FastEmbedを採用します。 -
会話チェーンの構築
LCEL (LangChain Expression Language)を用いてシンプルな会話チェーンを構築します。
Draft Simple UI
シンプルなユーザーインターフェースを構築するために、Streamlit を使用します。Streamlit は、AI/MLアプリケーションのプロトタイピングを迅速に行うために設計されたUIフレームワークです。
以下のコードをapp.pyとして保存し、rag.pyと同じディレクトリ配下に配置します。
import os
import tempfile
import streamlit as st
from streamlit_chat import message
from rag import ChatPDF
st.set_page_config(page_title="ChatPDF")
def display_messages():
st.subheader("Chat")
for i, (msg, is_user) in enumerate(st.session_state["messages"]):
message(msg, is_user=is_user, key=str(i))
st.session_state["thinking_spinner"] = st.empty()
def process_input():
if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0:
user_text = st.session_state["user_input"].strip()
with st.session_state["thinking_spinner"], st.spinner("Thinking"):
agent_text = st.session_state["assistant"].ask(user_text)
st.session_state["messages"].append((user_text, True))
st.session_state["messages"].append((agent_text, False))
st.session_state["user_input"] = ""
def read_and_save_file():
st.session_state["assistant"].clear()
st.session_state["messages"] = []
st.session_state["user_input"] = ""
for file in st.session_state["file_uploader"]:
with tempfile.NamedTemporaryFile(delete=False) as tf:
tf.write(file.getbuffer())
file_path = tf.name
with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"):
st.session_state["assistant"].ingest(file_path)
os.remove(file_path)
def page():
if "messages" not in st.session_state:
st.session_state["messages"] = []
if "assistant" not in st.session_state:
st.session_state["assistant"] = ChatPDF()
st.header("ChatPDF")
st.subheader("Upload a document")
st.file_uploader(
"Upload document",
type=["pdf"],
key="file_uploader",
on_change=read_and_save_file,
label_visibility="collapsed",
accept_multiple_files=True,
)
st.session_state["ingestion_spinner"] = st.empty()
display_messages()
st.text_input("Message", key="user_input", on_change=process_input)
if __name__ == "__main__":
page()
rag.py および app.py が準備できたら、ターミナルを開き、ファイルが配置されているディレクトリに移動してから、以下のコマンドを実行してStreamlitアプリケーションを起動しましょう。
streamlit run app.py
以下の画面が表示されたら上手くいってます。
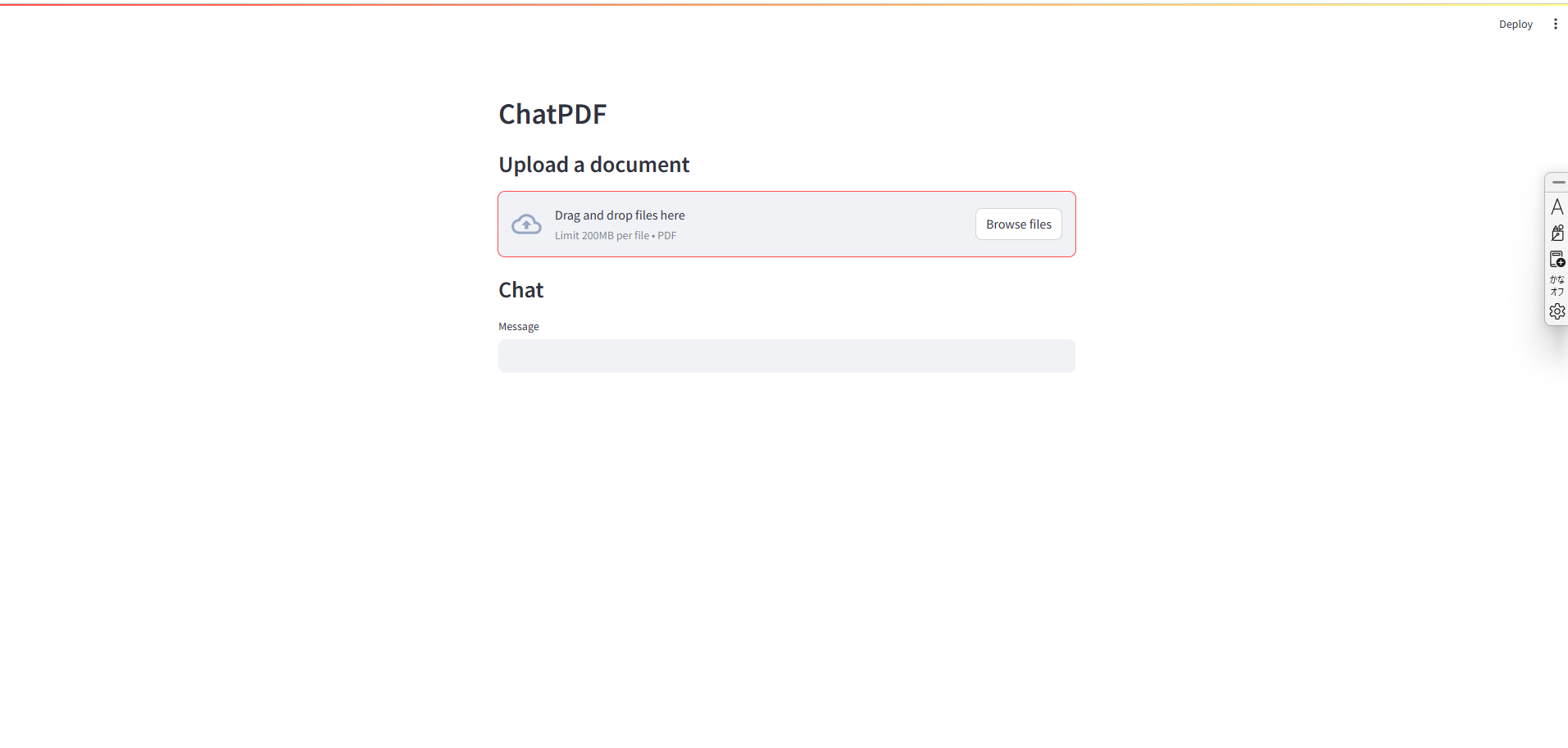
これで完成です!ここで、AIに回答して欲しい内容があるPDFファイルをアップロードして、それに関する質問をすると適切に回答してくれると思います。
最後に
読んでいただきありがとうございます!
この記事では、学習のためにシンプルなRAGを使ったアプリケーションを構築するための概要に焦点を当てていますが、改善が必要な部分もいくつかあります。
以下の提案を参考にして、アプリをさらに改善し、学習を進めてみるのも良いかもしれません。
改善案
-
会話チェーンにメモリを追加する
現在の状態では、会話の流れを記憶していません。一時的なメモリを追加することで、AIが文脈を把握できるようになります。 -
複数ファイルのアップロードを許可する
現在は1つのドキュメントについてのみチャットが可能ですが、複数のドキュメントに対応できるようになると便利です。 -
他のLLMモデルを使用する
今回はMistralを使用しましたが、他にも多くのLLMがあります。ただし、LLMモデルの選択はハードウェア(特にRAMの容量)に依存することを忘れないでくださいね。