ケンモFMとは
5ちゃんねる嫌儲板で、コロナ感染者を適当に予測したスレが立ち、明確なソースが貼られないまま「ソースはラジオで聴いた」などの一文が添えられていました。それを揶揄し、「ケンモFMかよ」のようなレスが付いたのが元ネタです。
せっかくなので、fmドメインを取得した上で、スレタイ(スレッドのタイトルのことです)を自動で読み上げるサイトを作ったのが https://kenmo.fm です。YouTubeにも同時配信しており、 https://www.youtube.com/channel/UCHBucrED96_pdOCvIs6jNSQ/live で聴けます。
とりあえずサイトにて自動で生成される音声を聴いてみてください。
システム構成
現状はこのようになっています。
ほぼTypeScriptで書かれており、所々にBashも使用しています。
順に解説します。
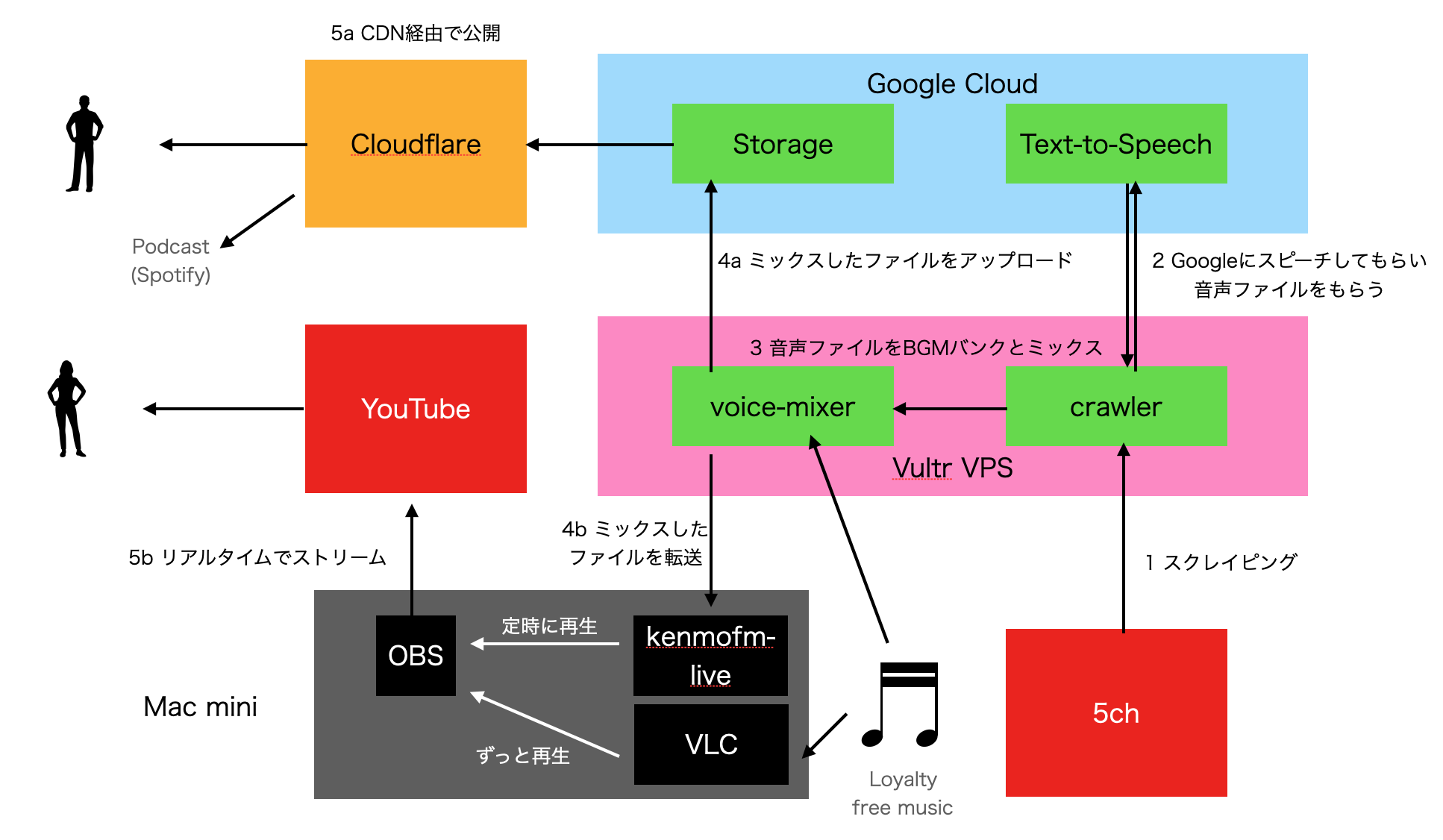
1 スクレイピング
この項目は大して面白くありません。 http://leia.5ch.net/poverty/subback.html をクロールし、chardetで文字コードを変換した後、Cheerioでパースし、XPathを使うことなく非常に簡単なjQueryのようなセレクタでお目当ての部位をスクレイピングできます。
ただ、これは全く無駄な努力で、 http://leia.5ch.net/poverty/subject.txt をスクレイピングすれば正規表現だけで取得できました…
const threadTitleRex = /^\d+:\s+(.+)\s+\[(\d+)\]\s+\((\d+)\)/
export class KenmoBoardParser extends Parser {
public parse() {
const threads: Thread[] = []
this.cheerio('a').each((i: any, elm: any) => {
const scannedRex = this.cheerio(elm).text().match(threadTitleRex)
if (scannedRex) {
threads.push(new Thread({
title: scannedRex[1],
beId: parseInt(scannedRex[2],10),
responseCount: parseInt(scannedRex[3],10),
crawledAt: new Date(),
}))
}
})
return threads
}
}
2 Google Text to Speech (TTS) で読み上げ
ここはコアとなる部分で、読み上げ部分は初期はMacのsayコマンドを利用していましたが、Googleの音声合成を聞くと非常に滑らかだったので変更しました。
Google TTSにはボイスが複数あり、Wavenetというアルゴリズムで作られる音声は非常に滑らかに聞こえます。
今回はja-JP-Wavenet-Bという女声を選択しました。
そのままスレタイを流すとスレタイが繋がって聴こえたので、音声合成マークアップ言語(SSML)を利用してスレタイの間にブレイクを入れました。SSMLは柔軟に読み上げをカスタマイズでき、効果音なども入れられるようです。
以下はSSMLの生成部分です。
let intro = `<speak>ハロー!ケンモメン。ただいま${date.getMonth()+1}月${date.getDate()}日の${date.getHours()}時です。`
intro += "ただいまのスレ一覧をお知らせいたします。\n\n"
const last = "</speak>"
const threadTitles = threads.map(t => t.title)
const text = intro + threadTitles.reduce((joinedText, title) => {
const speechStr = `${joinedText}<break time="2s"/>${cleanUpText(title).replace(/[ ]/g, "、")}`
if (intro.length + speechStr.length + last.length <= 5000) {
return speechStr
} else {
return joinedText
}
}, "") + last
3 ミキシング: voice-mixer
この部分もまた重要な部分で、読み上げとBGMを全自動でミックスすることでKenmoFMをラジオ局風にする部分です。
この部分は ffmpeg を多用しており、フィルタ定義の文字列を自動生成し ffmpeg に処理を投げるという仕組みになっています。
例えばラジオ局では、以下のようなプログラム構成になっているはずです:
- ジングルが流れます
- 次に音楽が流れ、数秒間続きます
- 音楽が絞られていきます(私はこれをダッキングと言っています)
- DJが挨拶をし、コンテンツが読み上げられていきます
- 番組が終盤になると、DJは話すのをやめ、音楽の音量が上がって(戻って)いきます
これを実行するのが自作の voice-mixer です。
BGMの結合
後ろに流れるBGMはロイヤリティフリー音源の中からランダムに選択されます。以下はその部分です。
読み上げ中の時間を計算し、その長さに合わせてBGMを数曲選び、一つのファイルに結合します。
async prepareBgm(bgmFile: string) {
const [voiceDuration, bgmIntroDuration] = await Promise.all([
this.voice.getDuration(), this.bgmIntro.getDuration()])
let concatTargets = [this.bgmIntroFile]
let totalDuration = 0
do {
const bgmFilename = Mixer.chooseRandomFile(this.bgmDirectory)
const bgm = new Ffmpeg(bgmFilename)
concatTargets.push(bgmFilename)
totalDuration += await bgm.getDuration()
} while (totalDuration < voiceDuration + 10)
this.concatedFile = `${this.tmp.name}/concated.wav`
await Ffmpeg.concatFiles(concatTargets, this.concatedFile)
return this.duck(this.concatedFile, voiceDuration, bgmFile)
}
ダッキング処理
BGMを結合した後、読み上げ開始時に音量を絞るため、音量をそのタイミングに調整する必要があります。
以下の関数を実行すると ffmpeg に渡すための文字列が生成されます。これを ffmpeg が解釈し、適切なタイミングでボリュームの調整をおこないます。
async duck(concatedFile: string, voiceDuration: number, bgmFile: string) {
const bgmDuckStartsAt = Math.max(this.voiceStartsAt - (this.bgmMaxVolume - this.bgmVolumeWhileDucking), 0)
const bgmDuckStartCompletesAt = this.voiceStartsAt + this.bgmVolumeWhileDucking
const voiceEndedAt = this.voiceStartsAt + voiceDuration
const bgmDuckEndCompeletesAt = voiceEndedAt + (this.bgmMaxVolume - this.bgmVolumeWhileDucking)
const bgmDuckEndsAt = voiceEndedAt
const bgmDuckEndsCoefficient = bgmDuckEndsAt - this.bgmVolumeWhileDucking
const bgmFadeOutStartsAt = bgmDuckEndsAt + this.bgmLastsDuration
const clipLength = bgmFadeOutStartsAt + this.bgmFadeOutDuration
const filter = `volume='if(lt(t,${bgmDuckStartsAt}), ${this.bgmMaxVolume}, if(lt(t,${this.voiceStartsAt}), ${bgmDuckStartCompletesAt}-t, if(lt(t, ${voiceEndedAt}), ${this.bgmVolumeWhileDucking}, if(lt(t, ${bgmDuckEndCompeletesAt}), t-${bgmDuckEndsCoefficient}, ${this.bgmMaxVolume}))))':eval=frame,afade=t=out:st=${bgmFadeOutStartsAt}:d=${this.bgmFadeOutDuration}`
const ffmpeg = new Ffmpeg(concatedFile)
return ffmpeg.applyAudioFilter(filter, bgmFile, clipLength)
}
読み上げボイスのコンプレッション
ラジオ局では音声の明瞭さが重要です。Googleが生成した声も十分明瞭ですが、こちら側でハイパス・フィルタと音声の音量を整えるノーマライザーをかけます。
例えば以下のようになります。
cleanUpVoice(outputFile: string, startsAt: number, padLength: number) {
return new Promise((resolve, reject) => {
let proc = child_process.execFile(ffmpeg,[
"-y",
"-i", this.filename,
"-ac", "2",
"-ar", "44100",
"-af", `highpass=100,dynaudnorm,adelay=${startsAt}s:all=true,apad=pad_dur=${padLength}s`,
"-c:a", "pcm_f32le", outputFile
], (error: any, stdout: any, stderr: any) => {
if (error) {
console.error("stderr", stderr);
throw error;
}
resolve()
})
})
}
ミキシング処理
選曲して結合し、ダッキング処理が終わったBGMと音声をミキシングする部分です。
static mixFiles(outputFile: string, voiceFile: string, bgmFile: string): Promise<any> {
return new Promise((resolve, reject) => {
let proc = child_process.execFile(ffmpeg,[
"-y",
"-i", bgmFile,
"-i", voiceFile,
"-ac", "2",
"-ar", "44100",
"-filter_complex",
"[1:a]asplit=2[sc][mix];[0:a][sc]sidechaincompress=threshold=0.08:ratio=5:release=1000[compr];[compr][mix]amerge",
"-codec:a", "pcm_f32le",
//`amix=inputs=${inputFiles.length}:duration=longest`,
outputFile
], (error: any, stdout: any, stderr: any) => {
if (error) {
console.error("stderr", stderr);
throw error;
}
resolve()
})
})
}
追記:BGMと読み上げをミックスする前にBGMの音量は下げられているのですが、所々BGMがうるさかったため、さらにミキシング時にもサイドチェーンを掛けるようにしました。読み上げ中のBGMをよく聴いてみると効果がわかります。
ノーマライズ
ミキシングが終わったファイルに対して、EBU R128による音量の調整をおこないます。これは音量の基準で、この規格に従うような音量の正規化が行われ、音量の上下動が少ない音声になります。
static normalize(outputFile: string, inputFile: string): Promise<any> {
return new Promise((resolve, reject) => {
let proc = child_process.execFile(ffmpeg,[
"-y",
"-i", inputFile,
"-ac", "2",
"-ar", "44100",
"-af","loudnorm=I=-14:TP=-1.5:LRA=11:measured_I=-27.61:measured_LRA=18.06:measured_TP=-4.47:measured_thresh=-39.20:offset=0.58:linear=true:",
"-codec:a", "pcm_f32le", outputFile
], (error: any, stdout: any, stderr: any) => {
if (error) {
console.error("stderr", stderr);
throw error;
}
resolve()
})
})
}
エンコーディング
最終的に出来上がったファイルは HE-AAC v2 という現状普及している中ではもっとも汎用的かつ、高効率なコーデックで圧縮されます。ビットレートは32kbpsという低さですが、聴いていただければわかるように、問題のない音質です。
4a オンデマンド配信
Google Cloud Storage
エンコードされたファイルは Google Cloud Storage にアップロードされます。
gsutil -h "Content-Type:audio/aac" -h "Cache-Control:public, max-age=31536000" cp /tmp/$MERGED_FILENAME gs://kenmo.fm/static/broadcasts/
Podcast用RSSフィードの作成
Podcastに配信するため、RSSフィードを作成し、これもGoogle Cloud Storageにアップロードします。
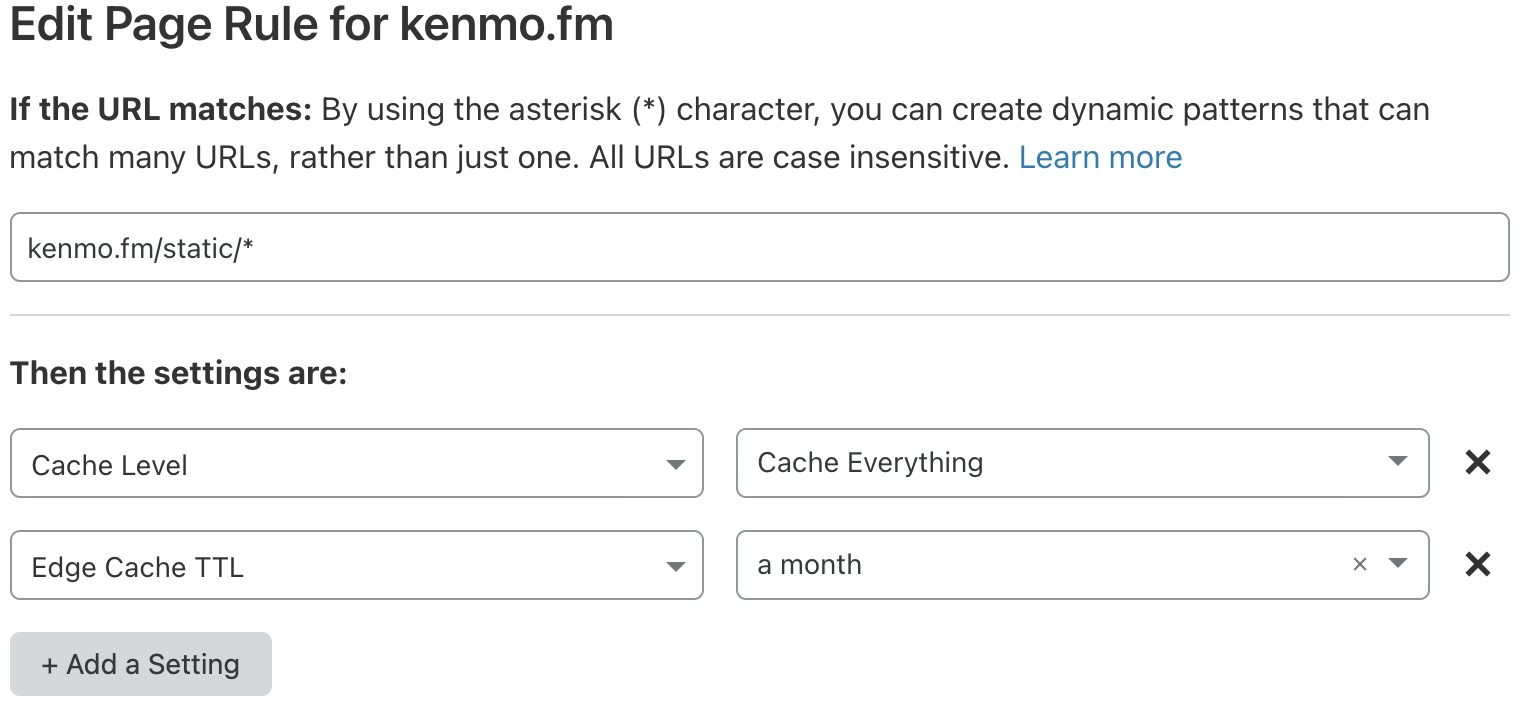
Cloudflare
初期設定ではMP4音声ファイルをエッジキャッシュに載せない設定だったので、Page Rulesを設定し、static/ 以下をキャッシュするように設定しました。
ほぼ全ての配信はCloudflareを通り、Google Cloud Storageにはほとんどアクセスは行かない状態です。
4b YouTube Live 配信
定期的に上で生成した音声を流す配信です。それ以外の時間はBGMを流すものです。
OBSブラウザソース
OBSで「ブラウザソース」を使うと、ブラウザの音声を配信できるため、HTML5 + Javascriptで定期的に最新音声を再生するコードを書き、それをキャプチャしています。
VLC
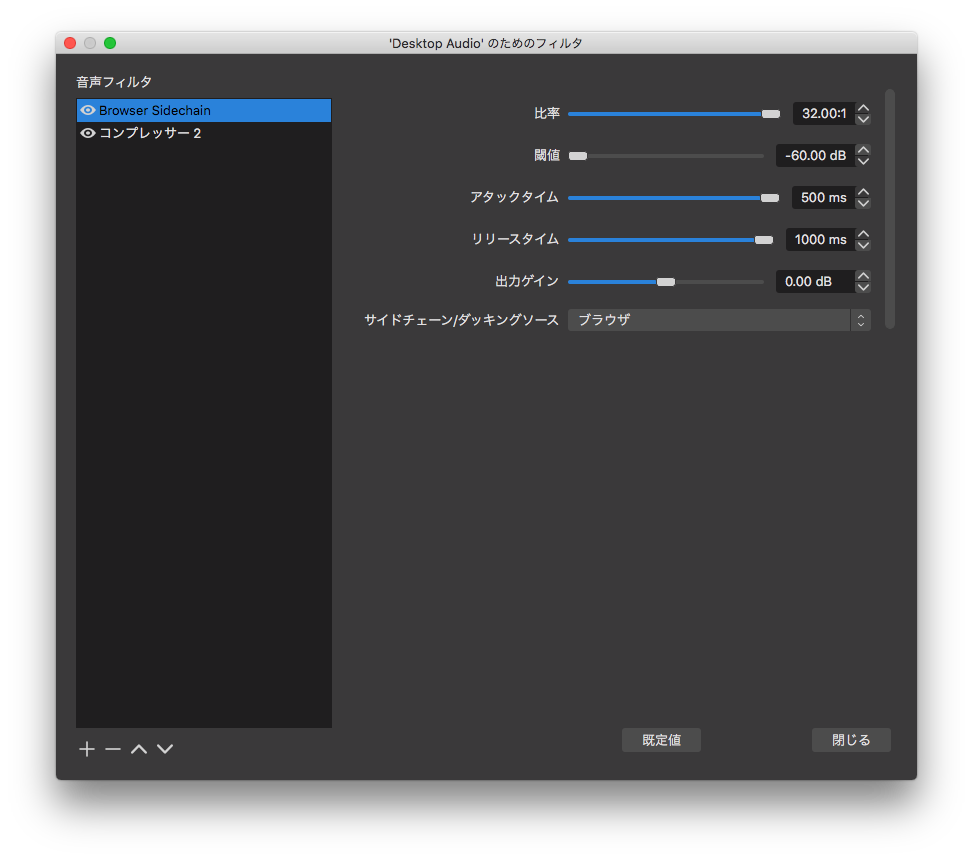
後ろではVLCでBGMを常に流しており、OBSのコンプレッサーの「サイドチェーン」機能により、ブラウザから音声がある場合は音量を絞り、音声がなくなった場合にBGMの音量を戻す仕組みとしています。
以下はブラウザで音声がスタートすると、500msで常時流れているBGMの音量を下げ、逆にストップすると1000msで徐々にBGMを再開するコンプレッサーの設定です。
追記:サイドチェーンの閾値をあまり小さくできず、所々でBGMが混入していたので、ノイズゲートでカットするようにしました。
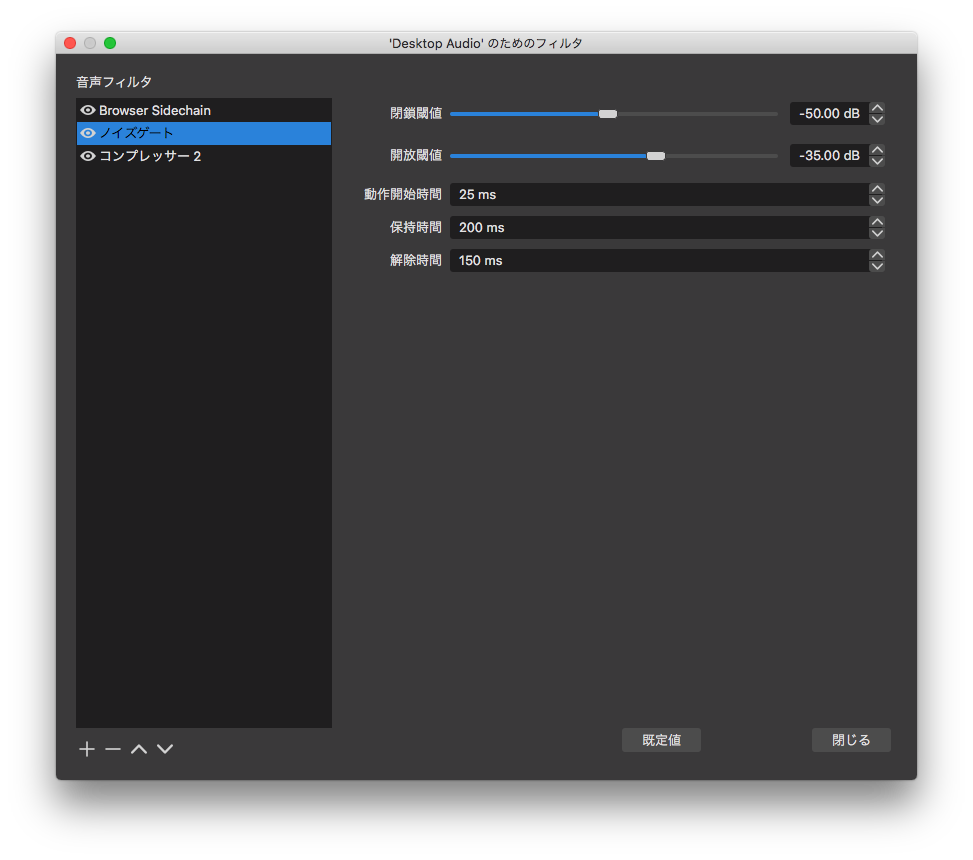
YouTube Liveで聴くとこの設定の意味がわかるでしょう。
VLCに入れる曲はあらかじめ「foobar2000」にてReplayGainをスキャンし、音量レベルを均等に保つことで曲間における音量差を少なくしています。
さらに放送時に軽くコンプレッションをかけています。
音質へのこだわり
Google TTSの出力ファイルはWAVで出力しています。
自動化プロセスの中間ファイルは全て32bit PCM WAVで処理されており、多数の自動処理パイプラインのどこにおいても劣化しないようにしています。
On Demand版の最終的な出力は現状でもっとも圧縮効率の高いHE-AAC v2 32kbpsとしています。これにより最小のパケット使用量で最高の音質を実現します。
YouTube Liveへの送出は本当であれば可逆圧縮または無圧縮で送信したいのですが、OBSでは不可能のため最大の320kbpsで送出しています。こちらは音楽もお楽しみいただくためOn demand版より音質は高いです。
読み上げ中のコンテンツはEBU R128により音量が平均化されています。YouTube Liveでの読み上げていない時間帯に流れる曲はReplayGainにより音量が整えられています。
YouTube Liveではさらに配信時にコンプレッサーをかけていて音量のばらつきを抑えています。
直したいところ
スマホ向けの「音声のみ」配信をしたい
Icecast2
私は以前、Icecast2を用いた配信システムを構築したことがありますが、それを使えばスマホ向けに配信できると思います。
Icecast2の配信はスマホブラウザで開いたあと、バックグラウンドで再生できるため非常にモバイルと相性がいいのです。
しかしながらコネクションを張り続けるストリーミングのためスケールせず、爆発的な需要に耐えられない問題があります。
HLS
そこでHLSの出番です。HLSはAppleの開発した配信プロトコルで、ストリームを細切れのチャンクに分割し、それを逐次HTTP GETで取得するため、CDNを通すことが可能になります。これは非常にスケールしやすく、大規模な配信が可能となります。
HLSはビデオのストリーミングで数多く使われていますが、オーディオの配信が可能であることは以前確認してあります。
nginx-rtmp-module
どちらの配信にしても、OBSから直接行うことはできません。そのため使われるのが nginx-rtmp-module です。コードベースが古いのが心配ではありますが、以前テストした際は問題なく動作しました。
これを使って立てたnginxサーバに対してRTMPストリームを送ると、このモジュールの設定で定義した ffmpeg が動作し、例えば Icecast2 への配信やHLS化といったことが可能になります。この部分は以前作ったことがあるので、ケンモFMに組み込むのは容易です。
ただ、そこまで需要があるかという問題と、nginx-rtmp-module を動かすサーバが必要となります。
AWS MediaLive
AWSのMediaLiveを利用すると、RTMPを受け取ってS3に流すといった仕組みが簡単に構築できるので、これを使うのもアリです。
ただ、当然ながらコストがかかります。
番組を自動再生
現状、ライブ配信は単なるif文でコンテンツの再生を振り分けていますが、これをうまく汎用化したいですね。
let programs = {
"thread-tts": {
name: "ニュース速報 嫌儲板",
filename: "new.wav",
},
"music1": {
name: "ケンモ・ミュージック・ステーション #1",
filename: "kenmo-music-station-1.wav",
},
"music2": {
name: "ケンモ・ミュージック・ステーション #2",
filename: "kenmo-music-station-2.wav",
},
}
// ...省略
if (now.getHours() == 13 && now.getMinutes() == 54) {
playIfNotPlaying(programs["music1"])
} else if (now.getHours() == 17 && now.getMinutes() == 0) {
playIfNotPlaying(programs["music2"])
} else if (now.getMinutes() === 40 || now.getMinutes() === 10) {
playIfNotPlaying(programs["thread-tts"])
}
自動番組送出システム
現状、ライブ配信は単なるif文でコンテンツの再生を振り分けていますが、これをうまく汎用化したいですね。
何曜日の何時にどれを放送、とかそういう仕組みが欲しいです。
let programs = {
"thread-tts": {
name: "ニュース速報 嫌儲板",
filename: "new.wav",
},
"music1": {
name: "ケンモ・ミュージック・ステーション #1",
filename: "kenmo-music-station-1.wav",
},
"music2": {
name: "ケンモ・ミュージック・ステーション #2",
filename: "kenmo-music-station-2.wav",
},
"music3": {
name: "ケンモ・ミュージック・ステーション #3",
filename: "kenmo-music-station-3.wav",
},
}
// ...省略
setInterval(function(){
const now = new Date()
if (now.getHours() == 13 && now.getMinutes() == 54) {
playIfNotPlaying(programs["music1"])
} else if (now.getHours() == 17 && now.getMinutes() == 0) {
playIfNotPlaying(programs["music2"])
} else if (now.getHours() == 15 && now.getMinutes() == 0) {
playIfNotPlaying(programs["music3"])
} else if (now.getMinutes() === 40 || now.getMinutes() === 10) {
playIfNotPlaying(programs["thread-tts"])
}
$clock.text("配信側時刻:"+ now.toLocaleTimeString())
},1000)