データセットの可視化
iris.csvをサンプルのデータセットとして,pandas, seabornで可視化の練習をした際のメモ.あくまで自分用メモなので図の種類やカラムの選び方など恣意的な箇所があると思いますが,ご了承ください_(..)
データ:
https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
ヒストグラムの描画
iris.csvは,4つのカラムと1つのカテゴリ値
sepal_length, sepal_width, petal_length, peta_width と species から成る.
カテゴリ値であるspeciesの分類を念頭においた可視化をする.
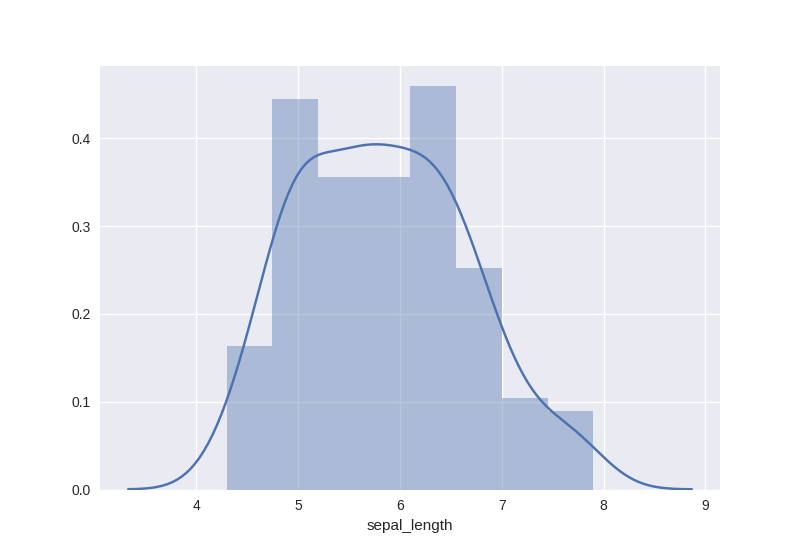
まずは1つのカラムについて,分布を確認する.
・sepal_lengthの分布
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("iris.csv")
# df = sns.load_dataset("iris") #手元にiris.csvがない場合
sns.distplot(df.sepal_length,kde = True)
plt.show()
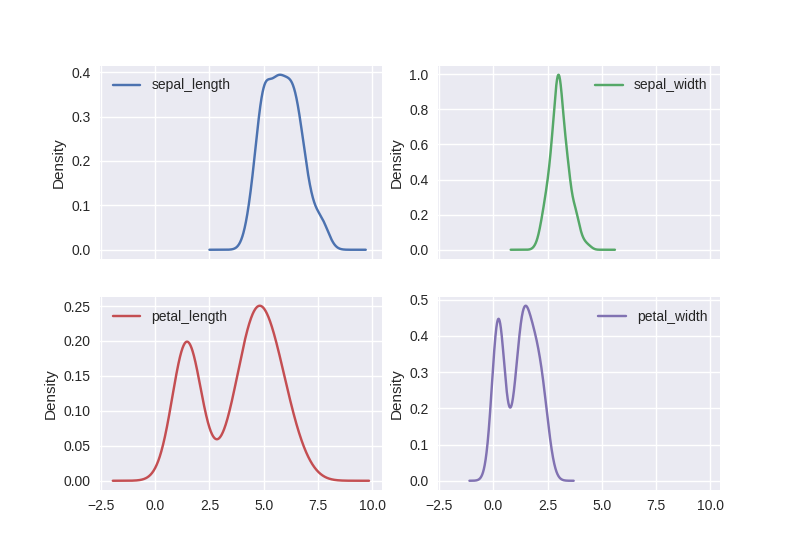
つぎに,4つのカラムの分布を,4つの別々のグラフに描画した.DataFrameのplot()メソッドを用いて,layout=(2,2)と指定すると,4つのグラフを2*2マスのレイアウトで出力できるので便利だと思ったが,ヒストグラムとカーネル密度推定による密度関数を同時に表示する方法がわからない.
・sepal_length, sepal_width, petal_length, peta_width の分布
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("iris.csv")
# df = sns.load_dataset("iris") #手元にiris.csvがない場合
df.plot(kind="kde",subplots=True,layout=(2,2)) #kind="hist"でヒストグラム
plt.show()
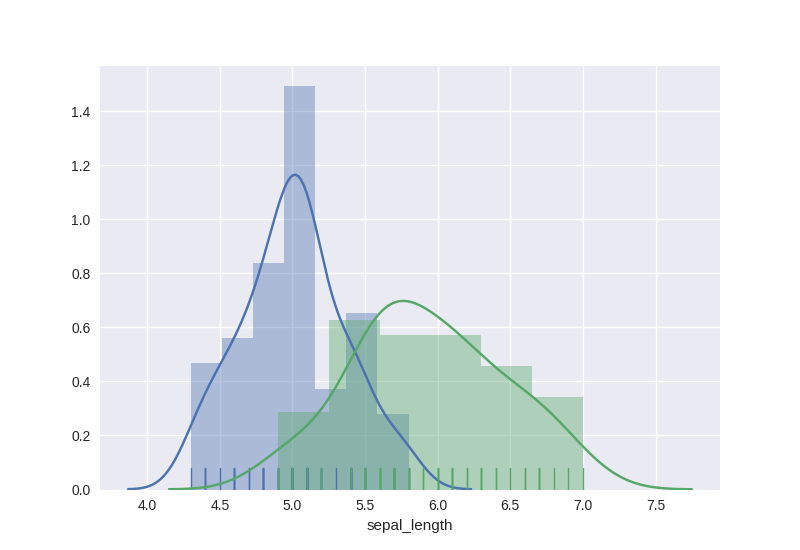
・カテゴリ別のsepal_lengthの分布
setosaとversicolorで,sepal_lengthの分布の仕方がどのように異なるかを確認する.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("iris.csv")
# df = sns.load_dataset("iris") #手元にiris.csvがない場合
sns.distplot(df[df["species"]=="setosa"].sepal_length,kde=True,rug=True)
sns.distplot(df[df["species"]=="versicolor"].sepal_length,kde=True,rug=True)
plt.show()
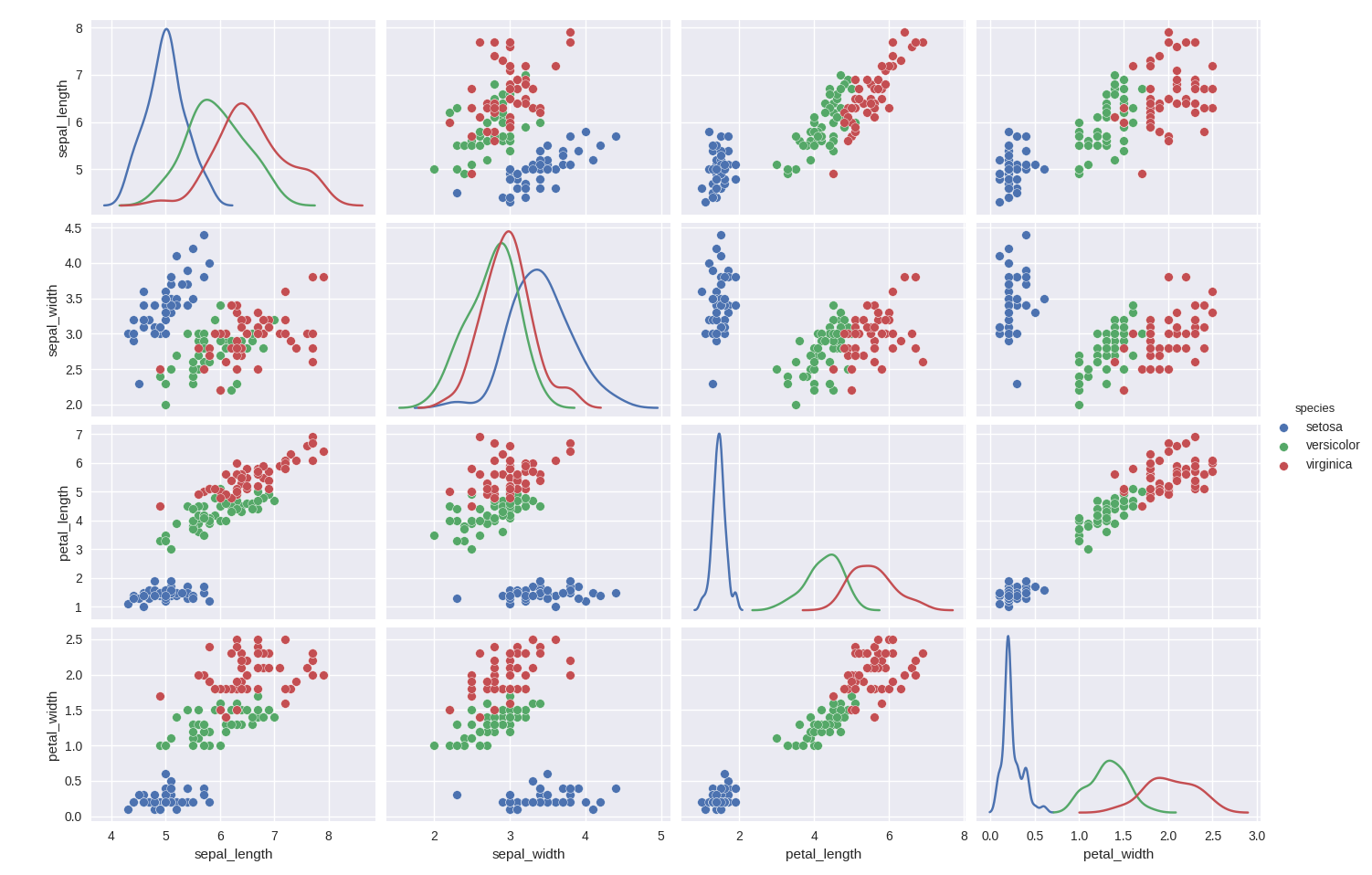
散布図行列の描画
データを概観するのに,散布図行列は有用な可視化方法である(と思う).Seabornでは,pairplot()を使うと簡単に描画できる.
以下の例では,pairplot()の引数としてhue="species"を設定している.これによって,irisデータセットのカテゴリ値"species"の種類別に色分けをしてくれる.diag_kind="kde"とすると,対角線成分には,カーネル密度推定による密度関数を描画する.何も指定しないと単にヒストグラムが表示される.
・カテゴリ別のsepal_lengthの分布
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("iris.csv")
# df = sns.load_dataset("iris") #手元にiris.csvがない場合
# pairplot: 散布図行列を描く
g = sns.pairplot(df,hue = "species",diag_kind="kde")
plt.show()