前回の記事、スタバのTwitterデータをpythonで大量に取得し、データ分析を試みる その1ではツイッターのREST APIsを使ってツイート本文に「スタバ」と書かれているツイートを大量に取得してデータベースにインポートするところまでやりました。今回はそのデータの中身を見ていきたいと思います。
その1:Twitter REST APIsでデータを取り込みmongoDBにインポート
http://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2
その2:取得したTwitterデータからスパムの分離(今回)
http://qiita.com/kenmatsu4/items/8d88e0992ca6e443f446
その3:ある日を境にツイート数が増えたわけは?
http://qiita.com/kenmatsu4/items/02034e5688cc186f224b
その4:Twitterにひそむ位置情報の視覚化
http://qiita.com/kenmatsu4/items/114f3cff815aa5037535
また、前回から少し追加でデータをインポートしたのでツイート総件数は30万件弱になりました。
###Tweetデータ概要###
- 取得総数
- 296,057件
- 取得データの期間
- 2015-03-11 04:43:42 から 2015-03-22 21:41:14 まで
- 1秒あたりツイート数
- 3.416 tweet/sec
まずはの約30万件のツイート情報がどのようなものか見ていきたいと思います。
また、記事で使っているpythonコードの一式はこちらにあります。
##時系列のツイート数推移##
時系列でのツイート数のグラフです。
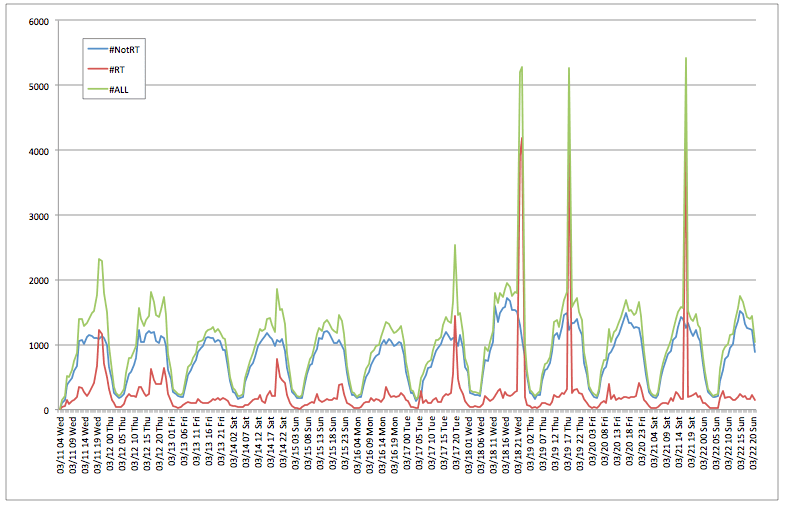
基本的には日中多くツイートされ、リツイートを除く通常ツイートが1時間当たり1000件強投稿されていることがわかります。
また、異常な4つのスパイクが
3/17 20時頃
3/18 22時頃
3/19 18時頃
3/21 17時頃
にあることがわかります。特に後ろの3つは飛び抜けてます。
次の項で調べていきますが、どうやらスパムツイートによるもののようですので、これを分離していきます。
##スパムの分離##
まずは1時間当たり540回(1分に9回)以上リツイートされているものが、誰のツイートに対するリツイートなのかをリストアップするコードを書いてみていきます。
# 1時間の間にlimitに指定した数以上にリツイートされたアカウントを表示する
def select_outlier_retweet_num_per_hour(from_str_datetime_jp, limit=120):
'''
from_str_datetime_jp: 1時間枠の開始時刻
limit: この数を超えてリツイートされたものを検出する
e.g. select_outlier_tweet_num_per_hour("2015-03-18 22:00:00")
'''
result_list = []
from_date = str_to_date_jp_utc(from_str_datetime_jp)
to_date = str_to_date_jp_utc(from_str_datetime_jp) + datetime.timedelta(hours=1)
for d in tweetdata.find({'retweeted_status':{"$ne": None},'created_datetime':{"$gte":from_date, "$lt":to_date}},\
{'user':1,'text':1,'entities':1, 'created_at':1, 'id':1}):
mensioned_username = ""
if len(d['entities']['user_mentions'])!=0:
mensioned_username = d['entities']['user_mentions'][0]['screen_name']
result_list.append({"created_at":utc_str_to_jp_str(d['created_at']),\
"screen_name":d['user']['screen_name'],\
"referred_name":mensioned_username,\
"text":d['text'].replace('\n',' ')\
})
name_dict = defaultdict(int)
for r in result_list:
name_dict[r['referred_name']] += 1
s = sorted(name_dict.iteritems(),key=lambda (k,v): v,reverse=True) # リツイート回数でソート
return s[0:int(np.sum(map(lambda (k,v): 1 if v>limit else 0 ,s)))] # リツイート元ユーザー名, リツイート回数(limitを超えたもの)
start_date = str_to_date_jp_utc("2015-03-10 19:00:00")
to_date = str_to_date_jp_utc("2015-03-22 22:00:00")
d_diff = (to_date - start_date)
d_hours = d_diff.days * 24 + d_diff.seconds/float(3600)
for i in range(int(d_hours)):
d = (start_date + datetime.timedelta(hours=i)).strftime("%Y-%m-%d %H:%M:%S")
result = select_outlier_retweet_num_per_hour(d, limit=540)
if len(result) > 0:
print d, result
結果がこれです。
2015-03-11 20:00:00 [(u'NewsGiga', 972)]
2015-03-11 21:00:00 [(u'NewsGiga', 863)]
2015-03-17 20:00:00 [(u'r***********', 773)]
2015-03-18 22:00:00 [(u'g*********', 3666)]
2015-03-18 23:00:00 [(u'e**********', 3882)]
2015-03-19 18:00:00 [(u'y**********', 3771)]
2015-03-21 17:00:00 [(u'm***********', 4032)]
※スパムアカウントは伏字にしました。
NewsGigaさんのツイート以外は内容を見るに、全てスパムだったので、spamフラグを各レコードに立てていこうと思います。
また、逆にNewsGigaさんの記事は BUZZってるので何が話題になっているか気になって見て調べてみるとこの記事でした。スタバの雰囲気が好きだけどコーヒーが苦手っていう人が結構多いのですね!
コーヒー嫌いに朗報! スタバが紅茶専門のカフェ『TEAVANA』を日本で展開! http://t.co/ZHBPvA6JQF pic.twitter.com/4Jr1x0Ql1v
— GIGADIA (@NewsGiga) 2015, 3月 11
次に、このスパムアカウントへのリツイートと、このリツイートをしているユーザーのツイートをspamと判断し、spamフラグを立てて分別します。
# spamアカウントのツイートにspamフラグを付与する
# 08_spam_detector.pyであぶり出したスパムアカウントのリスト
spam_list = ['r***********', 'g*********', 'e**********', 'y**********', 'm***********']
count = 0
retweeted_name = ""
for d in tweetdata.find({'retweeted_status':{"$ne": None}}): # リツイートデータ一式を取得
try:
retweeted_name = d['entities']['user_mentions'][0]['screen_name']
except:
count += 1
pattern = r".*@([0-9a-zA-Z_]*).*"
ite = re.finditer(pattern, d['text'])
for it in ite:
retweeted_name = it.group(1)
break
if retweeted_name in spam_list: # スパムアカウントへのリツイートだったら
# スパムアカウントへのリツイートにspamフラグを付与
tweetdata.update({'_id' : d['_id']},{'$set': {'spam':True}})
# スパムツイートをしたアカウントもブラックリスト入り
spam_twitter.add(d['user']['screen_name'])
print '%d件のリツイートをスパムに分類しました'%count
# ブラックリスト入りのユーザーのツイートをスパムに分類
count = 0
for d in tweetdata.find({},{'user.screen_name':1}):
sc_name = d['user']['screen_name']
if sc_name in spam_twitter:
count += 1
tweetdata.update({'_id' : d['_id']},{'$set': {'spam':True}})
print "%d件のツイートをスパムに分類しました"
スパムを分類できたので、時系列ツイート数データを再度表示させます。
ただ、人の目でスパムを見分ける形になったので、今後はここの自動検出も課題です。
# 時系列ツイート数データの表示
date_dict = defaultdict(int)
ret_date_dict = defaultdict(int)
norm_date_dict = defaultdict(int)
spam_dict = defaultdict(int)
not_spam_norm_dict = defaultdict(int)
not_spam_ret_dict = defaultdict(int)
for d in tweetdata.find({},{'_id':1, 'created_datetime':1,'retweeted_status':1,'spam':1}):
str_date = date_to_Japan_time(d['created_datetime']).strftime('%Y\t%m/%d %H %a')
date_dict[str_date] += 1
# spamの除去
if ('spam' in d) and (d['spam'] == True):
spam_dict[str_date] += 1
else:
spam_dict[str_date] += 0
# spamでないもののRetweet数のカウント
if 'retweeted_status' not in d:
not_spam_ret_dict[str_date] += 0
not_spam_norm_dict[str_date] += 1
elif obj_nullcheck(d['retweeted_status']):
not_spam_ret_dict[str_date] += 1
not_spam_norm_dict[str_date] += 0
else:
not_spam_ret_dict[str_date] += 0
not_spam_norm_dict[str_date] += 1
# Retweet数のカウント
if 'retweeted_status' not in d:
ret_date_dict[str_date] += 0
norm_date_dict[str_date] += 1
elif obj_nullcheck(d['retweeted_status']):
ret_date_dict[str_date] += 1
norm_date_dict[str_date] += 0
else:
ret_date_dict[str_date] += 0
norm_date_dict[str_date] += 1
print "日付" + "\t\t\t" + "#ALL" + "\t" + "#NotRT" + "\t" + "#RT" + "\t" "#spam" + "\t" "#NotRT(exclude spam)" + "\t" + "#RT(exclude spam)"
keys = date_dict.keys()
keys.sort()
for k in keys:
print k + "\t" + str(date_dict[k]) + "\t" + str(norm_date_dict[k]) + "\t" + str(ret_date_dict[k]) \
+ "\t" + str(spam_dict[k])+ "\t" + str(not_spam_norm_dict[k]) + "\t" + str(not_spam_ret_dict[k])
外れ値のスパイクがなくなりきれいになりました![]()
11日にちょっと上に出てるのは先ほどのNewsGigaさんへのリツイートですね。
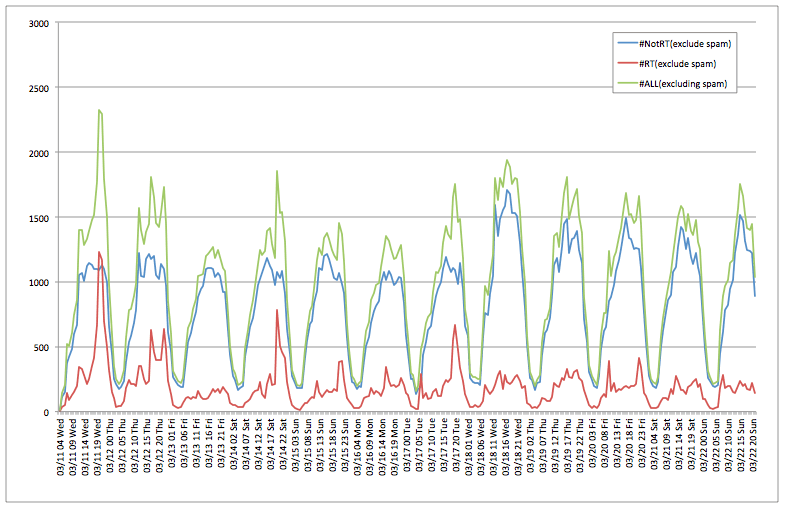
だいたい、1時間当たりツイート数が1000件を越えてくるのがお昼の12時から。そこから22時くらいまで1000件台をキープしてその後深夜早朝になると下がっていきます。
もしプロモーションをかけるならこの12時〜22時の間が効果的な感じがします。
次回はツイート本文に対して形態素解析を掛けて単語を分解したり、感情分析を掛けてみたりをやってみる予定です。