スタバTwitterシリーズも第3回となりました。下記は今までの投稿です。
その1:Twitter REST APIsでデータを取り込みmongoDBにインポート
http://qiita.com/kenmatsu4/items/23768cbe32fe381d54a2
その2:取得したTwitterデータからスパムの分離
http://qiita.com/kenmatsu4/items/8d88e0992ca6e443f446
その3:ある日を境にツイート数が増えたわけは?(今回)
http://qiita.com/kenmatsu4/items/02034e5688cc186f224b
その4:Twitterにひそむ位置情報の視覚化
http://qiita.com/kenmatsu4/items/114f3cff815aa5037535
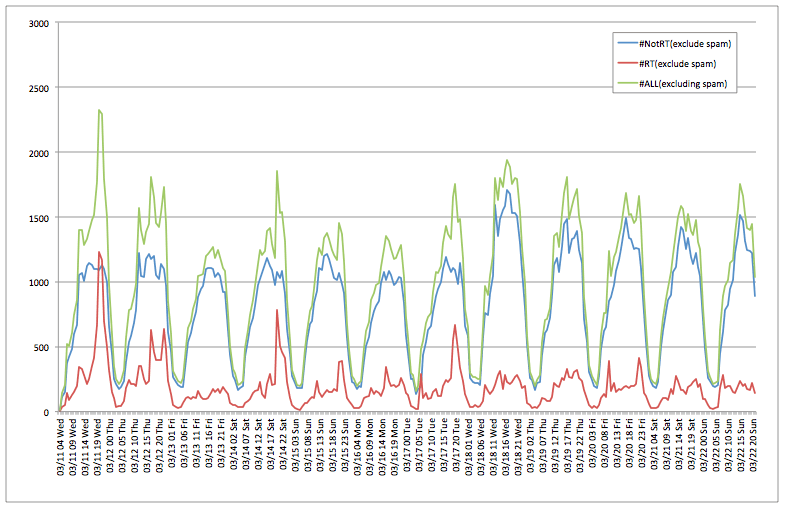
さて、この前回の時系列ツイート数グラフをよく見ると3/18からグラフが全体的に上に持ち上がっているように見えないでしょうか?この日から何ががあったのではないかと思うので、これを分析してみようと思います。
ツイートの内容に何か変化がないかをツイート本文から分析する、ということを試みます。
まず考え方として、ツイートを3/18 0:00を境に前後に分割します。
で、その前後でつぶやきに含まれる単語で増加率が高い単語が何か、というのをあぶり出すことをやってみたいと思います。
しばらくデータ処理の説明になるので、結果を先に見たい人は3. 分析結果に飛んでください。
1.単語の分かち書き##
ツイート本文を統計的に処理するにあたり、単語の分かち書きという処理が必要となります。英語の文書であれば単語毎に間にスペースが入っているので、スペース区切りで単語を特定できるのですが、日本語は膠着語と呼ばれる区切りが無い言語のためこの分かち書きが必要です。
そこで、かの有名なMeCabを導入して分析に使いたいと思います。
1-1.MeCabの導入###
mecab-ipadic-neologdとは、
mecab-ipadic-neologd は、多数のWeb上の言語資源から得た新語を
追加することでカスタマイズした MeCab 用のシステム辞書です。
とあるように、Web上をクローリングしてデータ収集して新語を取り入れた、@overlastさんが作成されたMeCab辞書です。Tweetデータなどは従来の単語辞書には含まれていなかった単語が多く含まれているので、この記事を書く直前にこのような辞書がリリースされたのはラッキーでした!
ご本人が第47回R勉強会@東京のセッションで説明されていた通り、超簡単に導入できるので、皆さんも是非^^
MeCab自体のインストールと、この新語対応の辞書mecab-ipadic-neologdのインストールも
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
にインストール方法の記載があるので、ここを参考にMeCabとその新語対応辞書mecab-ipadic-neologdをインストールします。
1-2.mecab-pythonの導入###
https://code.google.com/p/mecab/downloads/list
(※Google Code のダウンロード機能が 2014/1 で終了したようなので下記からDLください)
Google Drive Mecab Python download
ここからダウンロードしてインストールします。
$ python setup.py build
$ python setup.py install
基本的に回答してこの2つのコマンドでインストールされるはず。
1-3.ツイートを形態素に分ける###
PythonからMeCabの軌道を試してみましょう。mecab-ipadic-neologdを導入しているのでTaggerの生成時に引数でそのインストール先ディレクトリを指定しています。
import MeCab as mc
t = mc.Tagger('-Ochasen -d /usr/local/Cellar/mecab/0.996/lib/mecab/dic/mecab-ipadic-neologd/')
sentence = u'今日は良い天気ですが、雨ですね。キャラメルマキアートがうまいです。'
text = sentence.encode('utf-8')
node = t.parseToNode(text) # 先頭行はヘッダのためスキップ
while(node):
if node.surface != "":
print node.surface +"\t"+ node.feature
node = node.next
if node is None:
break
下記のように文章を単語に分けてくれて、品詞もつけてくれます。ちゃんと"キャラメルマキアート"という固有名詞も拾ってくれます!
<<<output>>>
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
良い 形容詞,自立,*,*,形容詞・アウオ段,基本形,良い,ヨイ,ヨイ
天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
が 助詞,接続助詞,*,*,*,*,が,ガ,ガ
、 記号,読点,*,*,*,*,、,、,、
雨 名詞,一般,*,*,*,*,雨,アメ,アメ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ
。 記号,句点,*,*,*,*,。,。,。
キャラメルマキアート 名詞,固有名詞,一般,*,*,*,キャラメル・マキアート,キャラメルマキアート,キャラメルマキアート
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
うまい 形容詞,自立,*,*,形容詞・アウオ段,基本形,うまい,ウマイ,ウマイ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
。 記号,句点,*,*,*,*,。,。,。
で、この形態素解析をツイート本文に適用します。本文をMeCabにかけて、今回は名詞・動詞・形容詞・副詞のみを抽出、それぞれをツイートのレコードに列追加していきます。(※正確にはmongoDBではレコードはドキュメント、列はフィールドです)助詞、助動詞等を抜いているのですが、これらは本文の内容を表すような特徴をそこまで表現していないと思いましたので除外しています。
# mecab 形態素分解
def mecab_analysis(sentence):
t = mc.Tagger('-Ochasen -d /usr/local/Cellar/mecab/0.996/lib/mecab/dic/mecab-ipadic-neologd/')
sentence = sentence.replace('\n', ' ')
text = sentence.encode('utf-8')
node = t.parseToNode(text)
result_dict = defaultdict(list)
for i in range(140): # ツイートなのでMAX140文字
if node.surface != "": # ヘッダとフッタを除外
word_type = node.feature.split(",")[0]
if word_type in ["名詞", "形容詞", "動詞"]:
plain_word = node.feature.split(",")[6]
if plain_word !="*":
result_dict[word_type.decode('utf-8')].append(plain_word.decode('utf-8'))
node = node.next
if node is None:
break
return result_dict
下記で全Tweetデータに対して形態素に分けていく処理を行います。
for d in tweetdata.find({},{'_id':1, 'id':1, 'text':1,'noun':1,'verb':1,'adjective':1,'adverb':1}):
res = mecab_analysis(unicodedata.normalize('NFKC', d['text'])) # 半角カナを全角カナに
# 品詞毎にフィールド分けして入れ込んでいく
for k in res.keys():
if k == u'形容詞': # adjective
adjective_list = []
for w in res[k]: adjective_list.append(w)
tweetdata.update({'_id' : d['_id']},{'$push': {'adjective':{'$each':adjective_list}}})
elif k == u'動詞': # verb
verb_list = []
for w in res[k]:
verb_list.append(w)
tweetdata.update({'_id' : d['_id']},{'$push': {'verb':{'$each':verb_list}}})
elif k == u'名詞': # noun
noun_list = []
for w in res[k]: noun_list.append(w)
tweetdata.update({'_id' : d['_id']},{'$push': {'noun':{'$each':noun_list}}})
elif k == u'副詞': # adverb
adverb_list = []
for w in res[k]:
adverb_list.append(w)
tweetdata.update({'_id' : d['_id']},{'$push': {'adverb':{'$each':adverb_list}}})
# 形態素解析済みのツイートにMecabedフラグの追加
tweetdata.update({'_id' : d['_id']},{'$set': {'mecabed':True}})
2. CountVectorizerで単語を数える
Scikit-learnというpythonの機械学習ライブラリにCountVectorizerというものがあるのですが、単語数を数えるのにこれを使ってみたいと思います。
2-1. CountVectorizerの使い方の簡単な例###
3つの文章を例にとってCountVectorizerでどういうことができるのかを説明します。CountVectorizerはfit関数に渡された文字列データに含まれる単語を単語毎にその出現回数をカウントして、それをベクトルとして表現してくれるクラスです。文字での説明より、下記のコードを見たほうが早いかもしれませんw
# 3つの文章 (1つの文が1つのツイート本文と思ってください)
data=["This is a pen.",
"This is also a pen. Pen is useful.",
"These are pencils.",
]
c_vec = CountVectorizer() # CountVectorizerオブジェクトの生成
c_vec.fit(data) # 対象ツイート全体の単語の集合をセットする
c_terms = c_vec.get_feature_names() # ベクトル変換後の各成分に対応する単語をベクトル表示
c_tran = c_vec.transform([data[1]]) # 2つ目の文章の数を数える
print c_terms
print data[1]
print c_tran.toarray()
下記がアウトプット結果です。
1行目にget_feature_names()関数で生成されたベクトルが表示されています。1つ目の成分はalsoのカウント数、2つ目の成分はareのカウント数…のように解釈します。fit()関数に渡したデータ一式に含まれる単語がuniqueになって入っています。
2行目はtransform()関数に渡したカウントしたい対象の文章です。
3行目が欲しかった単語毎のカウント数です。このように"This is also a pen. Pen is useful."という文章にはalsoが1つ、areは無し、isが2つ、penも2つ入っている、と言ったように単語数をカウントした数字が入っています。これはテストなのでベクトルの成分が8個しかないですが、このあと行うTweetデータに対してこの処理を行うと45001個の成分を持つベクトルが生成されます。30万件のツイートにユニークワードが4万5千個あるということですね。
<<<output>>>
[u'also', u'are', u'is', u'pen', u'pencils', u'these', u'this', u'useful']
This is also a pen. Pen is useful.
[[1 0 2 2 0 0 1 1]]
2-2. TweetデータをCountVectorizerにかける
では、Tweetデータで同じことをしていきたいと思います。
まずは必要なライブラリのインポート、DBへの接続と、Utility的な関数の宣言です。
from sklearn.feature_extraction.text import CountVectorizer
from pymongo import Connection
import numpy as np
from collections import defaultdict
import sys, datetime
connect = Connection('localhost', 27017)
db = connect.starbucks
tweetdata = db.tweetdata
def str_to_date_jp_utc(str_date):
if str_date is not None:
return datetime.datetime.strptime(str_date,'%Y-%m-%d %H:%M:%S') - datetime.timedelta(hours=9)
else:
return None
次にMeCabで分かち書きをした文字列を取得する関数です。これはmongoDBに蓄積されたTweetデータから指定した期間の物を取り出し、MeCabで単語化されたものをリストに集約してそれを返します。
# mecabで分解した単語を連結して文字列化する。
def get_mecabed_strings(from_date_str=None, to_date_str=None,include_rt=False):
tweet_list = []
tweet_texts = []
from_date = str_to_date_jp_utc(from_date_str)
to_date = str_to_date_jp_utc(to_date_str)
# 取得対象期間の条件設定
if (from_date_str is not None) and (to_date_str is not None):
query = {'created_datetime':{"$gte":from_date, "$lt":to_date}}
elif (from_date_str is not None) and (to_date_str is None):
query = {'created_datetime':{"$gte":from_date}}
elif (from_date_str is None) and (to_date_str is not None):
query = {'created_datetime':{"$lt":to_date}}
else:
query = {}
# spam除去
query['spam'] = None
# リツイートを含むか否か
if include_rt == False:
query['retweeted_status'] = None
else:
query['retweeted_status'] = {"$ne": None}
# 指定した条件のツイートを取得
for d in tweetdata.find(query,{'noun':1, 'verb':1, 'adjective':1, 'adverb':1,'text':1}):
tweet = ""
# Mecabで分割済みの単語をのリストを作成
if 'noun' in d:
for word in d['noun']:
tweet += word + " "
if 'verb' in d:
for word in d['verb']:
tweet += word + " "
if 'adjective' in d:
for word in d['adjective']:
tweet += word + " "
if 'adverb' in d:
for word in d['adverb']:
tweet += word + " "
tweet_list.append(tweet)
tweet_texts.append(d['text'])
return {"tweet_list":tweet_list,"tweet_texts":tweet_texts}
上記関数を利用して何か変化がありそうだった3/18 0:00の前後でそれぞれ単語のリストを取得します。今回リツイートは除外しています。
# "2015-03-18 00:00:00"以前
ret_before = get_mecabed_strings(to_date_str="2015-03-18 00:00:00")
tw_list_before = ret_before['tweet_list']
# "2015-03-18 00:00:00"以降
ret_after = get_mecabed_strings(from_date_str="2015-03-18 00:00:00")
tw_list_after= ret_after['tweet_list']
# 全期間
ret_all = get_mecabed_strings()
tw_list_all = ret_all['tweet_list']
ここから先は先ほど説明したCountVectorizerの出番です。
c_vec = CountVectorizer(stop_words=[u"スタバ"]) # 「スタバ」は全Tweetに含まれるので除外
c_vec.fit(tw_list_all) # 全Tweetに含まれる単語の集合をここでセット
c_terms = c_vec.get_feature_names() # 各ベクトル要素に対応する単語を表すベクトル
# 期間の前後でひとまとまりと考え、transformする
transformed = c_vec.transform([' '.join(tw_list_before),' '.join(tw_list_after)])
はい、これで単語を数えることができました。ここからがやりたかったことですが、この期間の前後で増えている単語が何か、を表示させていきます。
# afterからbeforeを引くことで増分をsubに代入
sub = transformed[1] - transformed[0]
# トップ50がどの位置にあるかを取り出す
arg_ind = np.argsort(sub.toarray())[0][:-50:-1]
# トップ50の表示
for i in arg_ind:
print c_vec.get_feature_names()[i]
3. 分析結果
長かったですが、やっとたどり着きました!
下記が期間の前後で増加率の高い単語トップ50です。
「カウント順位」は単純に前後での該当単語が出現するツイート数の差分ですが、前後のツイート数が違うので、率を算出してランキングしています。
(表が見にくくてスミマセン・・・)
| 順位 | 単語 |
出現率 の差 |
カウント差 | カウント 順位 |
before | after | ||||
| 出現 | 出現しない | 出現率 | 出現 | 出現しない | 出現率 | |||||
| 1 | 新作 | 7.75% | 7,816 | 1 | 2,446 | 119,717 | 2.00% | 10,262 | 94,928 | 9.76% |
| 2 | 飲む | 3.34% | 2,203 | 3 | 9,455 | 112,708 | 7.74% | 11,658 | 93,532 | 11.08% |
| 3 | アーモンドミルク | 2.23% | 2,266 | 2 | 561 | 121,602 | 0.46% | 2,827 | 102,363 | 2.69% |
| 4 | ハニー | 1.38% | 1,420 | 4 | 263 | 121,900 | 0.22% | 1,683 | 103,507 | 1.60% |
| 5 | 美味しい | 1.24% | 726 | 9 | 4,167 | 117,996 | 3.41% | 4,893 | 100,297 | 4.65% |
| 6 | 新しい | 1.21% | 1,174 | 6 | 748 | 121,415 | 0.61% | 1,922 | 103,268 | 1.83% |
| 7 | アーモンド | 1.21% | 1,230 | 5 | 290 | 121,873 | 0.24% | 1,520 | 103,670 | 1.45% |
| 8 | http | 1.02% | -3,605 | - | 33,705 | 88,458 | 27.59% | 30,100 | 75,090 | 28.61% |
| 9 | クランチ | 0.90% | 932 | 7 | 139 | 122,024 | 0.11% | 1,071 | 104,119 | 1.02% |
| 10 | with | 0.86% | 869 | 8 | 287 | 121,876 | 0.23% | 1,156 | 104,034 | 1.10% |
| 11 | おいしい | 0.80% | 592 | 10 | 1,772 | 120,391 | 1.45% | 2,364 | 102,826 | 2.25% |
| 12 | フラペチーノ | 0.73% | 378 | 12 | 2,775 | 119,388 | 2.27% | 3,153 | 102,037 | 3.00% |
| 13 | 今日 | 0.68% | -185 | - | 6,497 | 115,666 | 5.32% | 6,312 | 98,878 | 6.00% |
| 14 | 甘い | 0.67% | 547 | 11 | 1,121 | 121,042 | 0.92% | 1,668 | 103,522 | 1.59% |
| 15 | やつ | 0.56% | 268 | 18 | 2,291 | 119,872 | 1.88% | 2,559 | 102,631 | 2.43% |
| 16 | https | 0.45% | 57 | 75 | 3,023 | 119,140 | 2.47% | 3,080 | 102,110 | 2.93% |
| 17 | みる | 0.42% | -14 | - | 3,255 | 118,908 | 2.66% | 3,241 | 101,949 | 3.08% |
| 18 | 商品 | 0.40% | 301 | 13 | 829 | 121,334 | 0.68% | 1,130 | 104,060 | 1.07% |
| 19 | うまい | 0.39% | 274 | 17 | 982 | 121,181 | 0.80% | 1,256 | 103,934 | 1.19% |
| 20 | くる | 0.34% | -740 | - | 7,878 | 114,285 | 6.45% | 7,138 | 98,052 | 6.79% |
| 21 | ちゃ | 0.30% | 284 | 16 | 228 | 121,935 | 0.19% | 512 | 104,678 | 0.49% |
| 22 | 問題 | 0.30% | 298 | 14 | 102 | 122,061 | 0.08% | 400 | 104,790 | 0.38% |
| 23 | 人種 | 0.28% | 291 | 15 | 29 | 122,134 | 0.02% | 320 | 104,870 | 0.30% |
| 24 | 期間限定 | 0.26% | 233 | 19 | 264 | 121,899 | 0.22% | 497 | 104,693 | 0.47% |
| 25 | はちみつ | 0.23% | 233 | 20 | 81 | 122,082 | 0.07% | 314 | 104,876 | 0.30% |
| 26 | 飲める | 0.23% | 53 | 81 | 1,338 | 120,825 | 1.10% | 1,391 | 103,799 | 1.32% |
| 27 | すぎる | 0.22% | -199 | - | 3,104 | 119,059 | 2.54% | 2,905 | 102,285 | 2.76% |
| 28 | 開始 | 0.22% | 221 | 21 | 75 | 122,088 | 0.06% | 296 | 104,894 | 0.28% |
| 29 | ハチミツ | 0.22% | 220 | 22 | 64 | 122,099 | 0.05% | 284 | 104,906 | 0.27% |
| 30 | 自宅 | 0.20% | 200 | 25 | 103 | 122,060 | 0.08% | 303 | 104,887 | 0.29% |
| 31 | 印象 | 0.20% | 179 | 26 | 208 | 121,955 | 0.17% | 387 | 104,803 | 0.37% |
| 32 | 届ける | 0.20% | 201 | 23 | 31 | 122,132 | 0.03% | 232 | 104,958 | 0.22% |
| 33 | 購入 | 0.19% | 176 | 27 | 204 | 121,959 | 0.17% | 380 | 104,810 | 0.36% |
| 34 | 新サービス | 0.19% | 201 | 24 | 0 | 122,163 | 0.00% | 201 | 104,989 | 0.19% |
| 35 | line | 0.18% | 141 | 33 | 378 | 121,785 | 0.31% | 519 | 104,671 | 0.49% |
| 36 | 買う | 0.18% | -316 | - | 3,660 | 118,503 | 3.00% | 3,344 | 101,846 | 3.18% |
| 37 | 交換 | 0.17% | 161 | 30 | 153 | 122,010 | 0.13% | 314 | 104,876 | 0.30% |
| 38 | 感じ | 0.16% | 59 | 72 | 791 | 121,372 | 0.65% | 850 | 104,340 | 0.81% |
| 39 | 行く | 0.16% | -1,843 | - | 14,473 | 107,690 | 11.85% | 12,630 | 92,560 | 12.01% |
| 40 | プーさん | 0.16% | 165 | 28 | 13 | 122,150 | 0.01% | 178 | 105,012 | 0.17% |
| 41 | キャンペーン | 0.16% | 159 | 31 | 33 | 122,130 | 0.03% | 192 | 104,998 | 0.18% |
| 42 | 昨日 | 0.15% | -9 | - | 1,232 | 120,931 | 1.01% | 1,223 | 103,967 | 1.16% |
| 43 | ceo | 0.15% | 161 | 29 | 8 | 122,155 | 0.01% | 169 | 105,021 | 0.16% |
| 44 | latte | 0.15% | -78 | - | 1,704 | 120,459 | 1.39% | 1,626 | 103,564 | 1.55% |
| 45 | 一言 | 0.15% | 134 | 35 | 162 | 122,001 | 0.13% | 296 | 104,894 | 0.28% |
| 46 | 呼び方 | 0.15% | 142 | 32 | 97 | 122,066 | 0.08% | 239 | 104,951 | 0.23% |
| 47 | ビスケット | 0.14% | 136 | 34 | 87 | 122,076 | 0.07% | 223 | 104,967 | 0.21% |
| 48 | 家族 | 0.14% | 123 | 39 | 167 | 121,996 | 0.14% | 290 | 104,900 | 0.28% |
| 49 | 微妙 | 0.14% | 131 | 36 | 86 | 122,077 | 0.07% | 217 | 104,973 | 0.21% |
| 50 | 美味い | 0.13% | 93 | 47 | 322 | 121,841 | 0.26% | 415 | 104,775 | 0.39% |
「新作」、「アーモンドミルク」など 3/18から始まったアーモンドミルクラテに関するツイートが増加していたのですね!
トップ10の単語を並べ替えると「新作 アーモンドミルク with ハニー クランチ 飲む 美味しい」です!どうやら好評のようです(^ー^*)これ、狙って作ったデータではないのですが、キレイに結果が出ました。
「アーモンドミルク ラテ with ハニー クランチ」はこれです。
「新作」がダントツトップなのは、「スタバの新作飲みたい!」みたいに具体的な名称「アーモンドミルクラテ」がでてこないツイートが結構多かったことが理由のようです。アーモンドミルクでつくった初めてのラテ。ふわふわのミルク、カリカリのクランチ、とろりと濃厚な「アーモンドミルク ラテ with ハニー クランチ」で、1週間の疲れを癒してみませんか。 http://t.co/i3IIusHw1E pic.twitter.com/1CCN2lG251
— スターバックス コーヒー (@Starbucks_J) 2015, 3月 20
次に上位の単語のうち「飲む」を除いた"新作", "アーモンドミルク","ハニー", "アーモンド", "新しい"が含まれるツイート数を集計してみます。
def is_include_word_list(text, word_list,f):
for word in word_list:
if text.find(word) > -1:
return True
return False
date_dict = defaultdict(int)
word_list = [u"新作", u"アーモンドミルク",u"ハニー", u"アーモンド", u"新しい", "with", u"クランチ"]
with open('armond.txt','w') as f:
for d in tweetdata.find({'spam': None, 'retweeted_status': None},{'created_datetime':1,'text':1}):
str_date = date_to_Japan_time(d['created_datetime']).strftime('%Y\t%m/%d %H %a')
text = d['text']
if is_include_word_list(text, word_list,f):
date_dict[str_date] += 1
# マッチした対象をファイルに書き出す(for 検証用)
ret_str = str_date +' '+ text.replace('\n', ' ')+'\n'
f.write(ret_str.encode('utf-8'))
print "date_dict", len(date_dict)
print "階級数:", len(date_dict)
print "日付" + "\t\t\t" + "# of Tweet"
keys = date_dict.keys()
keys.sort()
for k in keys:
print k + "\t" + str(date_dict[k])
結果をプロットしたのが下記のグラフです。紫の線がリストアップした単語を含むツイート数です。

この紫の数を、リツイート含まないツイート数(青い線)から引いてあげると…

ほとんど山が平らになりました!3/18日以降に増えていた単語は先ほどリストアップしたものでだいたい説明がつくようです。
でも、毎週のツイート数サイクルがこんなに安定しているのはなんででしょうかね、大数の法則ってこと(・ω・)? この謎を解ける人がいたら是非教えて欲しいです。
このスタバTweet分析もあと、1回か2回くらい続く予定です。
なんか、統計学的に難しいモデルとか使えないかと思って始めたのですが、データ眺めて加工するだけでも結構面白いことができた気がします。
次回はもう少し検定とか推定とかそんな話をしたいかなと思っています。もう少しお付き合いいただければ幸いです。
使用したコードの全体はgistにあります。
https://gist.github.com/matsuken92/72a0da8d9b42bed28e61
APPENDIX:期間前後の単語の出現確率の検定###
3/18 0:00の前後、各単語の出現有無を2x2のマトリクスにして考えると下記のようになります。これはカイ二乗適合度検定が行える形ですね。beforeとafterで本当に出現率に差があったのかどうか、を検定してみます。
| 単語: アーモンドミルク |
出現 |
出現 しない |
計 |
| Before | 561 | 121,602 | 122,163 |
| After | 2,827 | 102,363 | 105,190 |
| 計 | 3,388 | 223,965 | 227,353 |
下記がカイ二乗検定をかけた結果の表です。No.39を除き全て有意な結果が出ているので、やはり3/18以前と以降で出現率に変化があったと考えて良さそうです。No.39「行く」ですが、今回の分析対象としては、この単語が増えたと言えないことにさほど不都合はないかなと思いますので、良い結果かと思います。
| 順位 | 単語 | chi2 | p-val | 結果 |
| 1 | 新作 | 6437.337845 | 0 | 有意 |
| 2 | 飲む | 749.5007818 | 5.15E-165 | 有意 |
| 3 | アーモンドミルク | 1910.25734 | 0 | 有意 |
| 4 | ハニー | 1275.398025 | 2.51E-279 | 有意 |
| 5 | 美味しい | 227.0216513 | 2.66E-51 | 有意 |
| 6 | 新しい | 717.7324129 | 4.17E-158 | 有意 |
| 7 | アーモンド | 1042.145835 | 1.24E-228 | 有意 |
| 8 | http | 29.34665299 | 6.05E-08 | 有意 |
| 9 | クランチ | 871.5525659 | 1.50E-191 | 有意 |
| 10 | with | 667.7020689 | 3.16E-147 | 有意 |
| 11 | おいしい | 200.486648 | 1.64E-45 | 有意 |
| 12 | フラペチーノ | 116.9898183 | 2.89E-27 | 有意 |
| 13 | 今日 | 49.35872884 | 2.13E-12 | 有意 |
| 14 | 甘い | 207.6474174 | 4.48E-47 | 有意 |
| 15 | やつ | 83.8410031 | 5.36E-20 | 有意 |
| 16 | https | 44.31937829 | 2.79E-11 | 有意 |
| 17 | みる | 35.19560616 | 2.98E-09 | 有意 |
| 18 | 商品 | 103.1110711 | 3.17E-24 | 有意 |
| 19 | うまい | 87.88641968 | 6.93E-21 | 有意 |
| 20 | くる | 10.3550916 | 0.001291181 | 有意 |
| 21 | ちゃ | 155.9814931 | 8.54E-36 | 有意 |
| 22 | 問題 | 224.6028811 | 8.96E-51 | 有意 |
| 23 | 人種 | 288.2657541 | 1.19E-64 | 有意 |
| 24 | 期間限定 | 110.5936405 | 7.26E-26 | 有意 |
| 25 | はちみつ | 174.3777441 | 8.19E-40 | 有意 |
| 26 | 飲める | 24.391691 | 7.86E-07 | 有意 |
| 27 | すぎる | 10.62339463 | 0.001116659 | 有意 |
| 28 | 開始 | 166.5727271 | 4.15E-38 | 有意 |
| 29 | ハチミツ | 173.6897162 | 1.16E-39 | 有意 |
| 30 | 自宅 | 130.4736816 | 3.23E-30 | 有意 |
| 31 | 印象 | 83.82905236 | 5.39E-20 | 有意 |
| 32 | 届ける | 184.6605771 | 4.65E-42 | 有意 |
| 33 | 購入 | 82.49458545 | 1.06E-19 | 有意 |
| 34 | 新サービス | 231.4807808 | 2.83E-52 | 有意 |
| 35 | line | 48.21110495 | 3.83E-12 | 有意 |
| 36 | 買う | 6.279272571 | 0.012215823 | 有意 |
| 37 | 交換 | 81.93429413 | 1.41E-19 | 有意 |
| 38 | 感じ | 20.1122379 | 7.30E-06 | 有意 |
| 39 | 行く | 1.355305558 | 0.244352729 | 有意でない |
| 40 | プーさん | 167.4411384 | 2.68E-38 | 有意 |
| 41 | キャンペーン | 136.6923979 | 1.41E-31 | 有意 |
| 42 | 昨日 | 12.43299481 | 0.000421815 | 有意 |
| 43 | ceo | 170.5916319 | 5.49E-39 | 有意 |
| 44 | latte | 8.815476835 | 0.002986861 | 有意 |
| 45 | 一言 | 61.49900119 | 4.43E-15 | 有意 |
| 46 | 呼び方 | 82.67724362 | 9.66E-20 | 有意 |
| 47 | ビスケット | 81.23778177 | 2.00E-19 | 有意 |
| 48 | 家族 | 53.7386464 | 2.29E-13 | 有意 |
| 49 | 微妙 | 77.40857135 | 1.39E-18 | 有意 |
| 50 | 美味い | 29.5887298 | 5.34E-08 | 有意 |
カイ二乗適合度検定を行ったコードは下記です。
data = np.array([[2446,119717,10262,94928],
[9455,112708,11658,93532],
[561,121602,2827,102363],
[263,121900,1683,103507],
[4167,117996,4893,100297],
[748,121415,1922,103268],
[290,121873,1520,103670],
[33705,88458,30100,75090],
[139,122024,1071,104119],
[287,121876,1156,104034],
[1772,120391,2364,102826],
[2775,119388,3153,102037],
[6497,115666,6312,98878],
[1121,121042,1668,103522],
[2291,119872,2559,102631],
[3023,119140,3080,102110],
[3255,118908,3241,101949],
[829,121334,1130,104060],
[982,121181,1256,103934],
[7878,114285,7138,98052],
[228,121935,512,104678],
[102,122061,400,104790],
[29,122134,320,104870],
[264,121899,497,104693],
[81,122082,314,104876],
[1338,120825,1391,103799],
[3104,119059,2905,102285],
[75,122088,296,104894],
[64,122099,284,104906],
[103,122060,303,104887],
[208,121955,387,104803],
[31,122132,232,104958],
[204,121959,380,104810],
[0,122163,201,104989],
[378,121785,519,104671],
[3660,118503,3344,101846],
[153,122010,314,104876],
[791,121372,850,104340],
[14473,107690,12630,92560],
[13,122150,178,105012],
[33,122130,192,104998],
[1232,120931,1223,103967],
[8,122155,169,105021],
[1704,120459,1626,103564],
[162,122001,296,104894],
[97,122066,239,104951],
[87,122076,223,104967],
[167,121996,290,104900],
[86,122077,217,104973],
[322,121841,415,104775]])
from scipy.stats import chi2_contingency as chi2_con
for i, d in zip(range(len(data)), data):
chi2, p, dof, ex = chi2_con(d.reshape(2,2))
print i+1, " chi2", chi2, " p-val", p, u"有意" if p < 0.05 else u"有意でない"
参考##
MeCab:形態素解析ライブラリ
http://mecab.googlecode.com/svn/trunk/mecab/doc/index.html
MeCabの新語辞書:Neologism dictionary for MeCab
https://github.com/neologd/mecab-ipadic-neologd/blob/master/README.ja.md
Scikit-leaern:Python用機械学習ライブラリ
http://scikit-learn.org/stable/