こんにちは。自分は現在駒澤大学GMS学部の2年生でタイトルにあるように**ツイッターのトレンドについて研究しています。**この記事では研究やコードや参考になりそうなものを紹介します。
元々、ツイッタートレンドに興味があり、1年生の頃から、PythonとTwitterAPIとMeCabを使っていましたが、形態素解析して単語ごとに集計するという原始的なものでした。他に言語と位置情報や出現する漢字などで遊んでいました()
↓
そしてN-gramの要領で例えば2-12単語節ごとに記録し、全てを集計する簡易的なトレンド解析ができました。補足として、単語節にはツイッターのトレンドにあるように助詞がどこにこないとか助動詞がどうとか、だいぶ手作業で規則を作りました。これが2年生最初の頃です
↓
その後、何を研究するかとなった時に、一日の中で変動する定常トレンドを定義してモデル化というアイデアもありましたが、それをして何になるのかとか自分でも思っていて、某大学の先生からもその点と規則に人の手が入っていることを指摘されました。2年生夏頃です
↓
少し彷徨っていましたが、https://pj.ninjal.ac.jp/corpus_center/goihyo.html
国立国語研究所のUnidic,分類語彙表,意味分類に辿り着き、単語の意味的正規化、クラスタリング?をしようとしました。なかなか良くできましたが、複数の辞書の対応表?逆引きの際に同音異義語のはずなのに意味が極端な方で参照されるだとかで、若干の人の手が入りましたが問題ではない程度だと思います。あと、Unidicには未知語もあり、そのトレンドが考慮されないという問題も。2年生の10月くらいですか
↓
意味の正規化ができたところで、**係り受けを用いて意味の係り受けでトレンドを出したいというのは、前段の頃から思っていたため、CaboChaを使いました。**これが面倒でゼミのサーバでもAWSでもできなかったので、苦労しながら自分のWindowsにインストールして、subprocessでバインディング?しました(Pythonは32bitしかないため)。UnidicとCabochaで(Cabochaも辞書指定できる?)区切る位置が違っていたので、最小公倍数的な要領で共通部分で合わせました
↓
結果、**意味の係り受けに基づいた意味トレンド?は出せました。**しかし、『同音異義語のはずなのに意味が極端な方で参照される』というので修正を加えたり、それこそ『キャンペーンで当たる!フォローしてツイート』とかいうのがあり、『簡易的なトレンド解析』では、表出トレンド?の重複を用いて削除する方法がありましたが、やはりそれを用いることにしました
↓
ここまで、『意味の係り受けに基づいた意味トレンド』と『簡易的文字トレンド』の解析ができていて、今思っているのは、意味トレンドというのは文字と違って分けるのが難しいというか深層心理とか大局的なものであって、この研究では具体的なものにすることが大事だと思っていて、
独立した?文字トレンドに付随する意味トレンドごとに集計するとか、意味トレンドから文字トレンドを推定するとか、どの程度両者を使い分けられるか、どう組み合わせるかというところが今後の課題で、今が2年生の11月で卒業研究に向けてまあ頑張っているところです。
一段落したので書きました。(もっと早くから書いておけばよかったかも)
今更ですが文字トレンドというのは文字の羅列で、意味トレンドというのは文字を意味に置き換えた意味の羅列といった具合です。
もし使いたいとかなったら一言ツイッターでも、教えてくれるとありがたいです。
バックアップ的な意味でも書きたいと思いました。
環境はWindows10-64bit Python3です(雑)
まず、表出トレンドを推定するためのプログラムです。
custam_freq_sentece.txtは解析のために取得した全テキスト
custam_freq_tue.txtはトレンド候補。
custam_freq.txtはトレンド。
custam_freq_new.txtはトレンドから重複したものを除いて最長トレンドを出したプログラムです。
また、トレンドは時間ごとに入れ替えています。
freshtime=int(time.time()*1000)-200000の部分。これはツイート取得の速度によって変えると良いです。
あと、そもそもツイートにこのワードが含まれていたら処理しない単語リストbadwordもあって、これはプログラムのバージョンで無いのもありますが管理がヘタなので、、お好みでどうぞ。
# coding: utf-8
import tweepy
import datetime
import re
import itertools
import collections
from pytz import timezone
import time
import MeCab
# import threading
# from multiprocessing import Pool
import os
# import multiprocessing
import concurrent.futures
import urllib.parse
# インポート
import pdb; pdb.set_trace()
import gc
import sys
import emoji
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = ""
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
authapp = tweepy.AppAuthHandler(consumer_key,consumer_secret)
apiapp = tweepy.API(authapp)
# 認証
m_owaka = MeCab.Tagger("-Owakati")
m_ocha = MeCab.Tagger("-Ochasen")
# mecab形態素分解定義
lang_dict="{'en': '英語', 'und': '不明', 'is': 'アイスランド語', 'ay': 'アイマラ語', 'ga': 'アイルランド語', 'az': 'アゼルバイジェン語', 'as': 'アッサム語', 'aa': 'アファル語', 'ab': 'アプハジア語', 'af': 'アフリカーンス語', 'am': 'アムハラ語', 'ar': 'アラビア語', 'sq': 'アルバニア語', 'hy': 'アルメニア語', 'it': 'イタリア語', 'yi': 'イディッシュ語', 'iu': 'イヌクティトット語', 'ik': 'イヌピア語', 'ia': 'インターリングア', 'ie': 'インターリング語', 'in': 'インドネシア語', 'ug': 'ウイグル語', 'cy': 'ウェールズ語', 'vo': 'ヴォラピュック語', 'wo': 'ウォロフ語', 'uk': 'ウクライナ語', 'uz': 'ウズベク語', 'ur': 'ウルドゥー語', 'et': 'エストニア語', 'eo': 'エスペラント語', 'or': 'オーリア語', 'oc': 'オキタン語', 'nl': 'オランダ語', 'om': 'オロモ語', 'kk': 'カザフ語', 'ks': 'カシミール語', 'ca': 'カタラン語', 'gl': 'ガリシア語', 'ko': '韓国語', 'kn': 'カンナダ語', 'km': 'カンボジア語', 'rw': 'キヤーワンダ語', 'el': 'ギリシャ語', 'ky': 'キルギス語', 'rn': 'キルンディ語', 'gn': 'グアラニー語', 'qu': 'クエチュア語', 'gu': 'グジャラト語', 'kl': 'グリーンランド語', 'ku': 'クルド語', 'ckb': '中央クルド語', 'hr': 'クロアチア語', 'gd': 'ゲーリック語', 'gv': 'ゲーリック語', 'xh': 'コーサ語', 'co': 'コルシカ語', 'sm': 'サモア語', 'sg': 'サングホ語', 'sa': 'サンスクリット語', 'ss': 'シスワティ語', 'jv': 'ジャワ語', 'ka': 'ジョージア語', 'sn': 'ショナ語', 'sd': 'シンド語', 'si': 'シンハラ語', 'sv': 'スウェーデン語', 'su': 'スーダン語', 'zu': 'ズールー語', 'es': 'スペイン語', 'sk': 'スロヴァキア語', 'sl': 'スロヴェニア語', 'sw': 'スワヒリ語', 'tn': 'セツワナ語', 'st': 'セト語', 'sr': 'セルビア語', 'sh': 'セルボクロアチア語', 'so': 'ソマリ語', 'th': 'タイ語', 'tl': 'タガログ語', 'tg': 'タジク語', 'tt': 'タタール語', 'ta': 'タミル語', 'cs': 'チェコ語', 'ti': 'チグリニャ語', 'bo': 'チベット語', 'zh': '中国語', 'ts': 'ヅォンガ語', 'te': 'テルグ語', 'da': 'デンマーク 語', 'de': 'ドイツ語', 'tw': 'トウィ語', 'tk': 'トルクメン語', 'tr': 'トルコ語', 'to': 'トンガ語', 'na': 'ナウル語', 'ja': '日本語', 'ne': 'ネパール語', 'no': 'ノルウェー語', 'ht': 'ハイチ語', 'ha': 'ハウサ語', 'be': '白ロシア語', 'ba': 'バシキール語', 'ps': 'パシト語', 'eu': 'バスク語', 'hu': 'ハンガリー語', 'pa': 'パンジャビ語', 'bi': 'ビスラマ語', 'bh': 'ビハール語', 'my': 'ビルマ語', 'hi': 'ヒンディー語', 'fj': 'フィジー語', 'fi': 'フィンランド語', 'dz': 'ブータン語', 'fo': 'フェロー語', 'fr': 'フランス語', 'fy': 'フリジア語', 'bg': 'ブルガリア語', 'br': 'ブルターニュ語', 'vi': 'ベトナム語', 'iw': 'ヘブライ語', 'fa': 'ペルシャ語', 'bn': 'ベンガル語', 'pl': 'ポーランド語', 'pt': 'ポルトガル語', 'mi': 'マオリ語', 'mk': 'マカドニア語', 'mg': 'マダガスカル語', 'mr': 'マラッタ語', 'ml': 'マラヤーラム語', 'mt': 'マルタ語', 'ms': 'マレー語', 'mo': 'モルダビア語', 'mn': 'モンゴル語', 'yo': 'ヨルバ語', 'lo': 'ラオタ語', 'la': 'ラテン語', 'lv': 'ラトビア語', 'lt': 'リトアニア語', 'ln': 'リンガラ語', 'li': 'リンブルク語', 'ro': 'ルーマニア語', 'rm': 'レートロマンス語', 'ru': 'ロシア語'}"
lang_dict=eval(lang_dict)
lang_dict_inv = {v:k for k, v in lang_dict.items()}
# 言語辞書
all=[]
# リスト初期化
if os.path.exists('custam_freq_tue.txt'):
alll=open("custam_freq_tue.txt","r",encoding="utf-8-sig")
alll=alll.read()
all=eval(alll)
del alll
# all=[]
# 書き出し用意
# freq_write=open("custam_freq.txt","w",encoding="utf-8-sig")
sent_write=open("custam_freq_sentece.txt","a",encoding="utf-8-sig", errors='ignore')
# 書き出し用意
use_lang=["日本語"]
use_type=["tweet"]
# config
uselang=""
for k in use_lang:
k_key=lang_dict_inv[k]
uselang=uselang+" lang:"+k_key
# config準備
def inita(f,k):
suball=[]
small=[]
for s in k:
if not int(f)==int(s[1]):
#print("------",f)
suball.append(small)
small=[]
#print(s[0],s[1])
small.append(s)
f=s[1]
suball.append(small)
#2を含むなら
return suball
def notwo(al):
micro=[]
final=[]
kaburilist=[]
for fg in al:
kaburilist=[]
if len(fg)>1:
for v in itertools.combinations(fg, 2):
micro=[]
for s in v:
micro.append(s[0])
micro=sorted(micro,key=len,reverse=False)
kaburi=len(set(micro[0]) & set(micro[1]))
per=kaburi*100//len(micro[1])
#print(s[1],per,kaburi,len(micro[0]),len(micro[1]),"m",micro)
if per>50:
kaburilist.append(micro[0])
kaburilist.append(micro[1])
else:
final.append([micro[0],s[1]])
#print("fin1",micro[0],s[1])
if micro[0] in micro[1]:
pass
#print(micro[0],micro[1])
#print("含まれます"*5)
#if micro[0] in kaburilist:
# kaburilist.remove(micro[0])
else:
pass
#print(fg[0][1],fg[0][0])
final.append([fg[0][0],fg[0][1]])
#print("fin3",fg[0][0],fg[0][1])
#if kaburilist:
#longword=max(kaburilist,key=len)
#final.append([longword,s[1]])
##print("fin2",longword,s[1])
#kaburilist.remove(longword)
#kaburilist=list(set(kaburilist))
#for k in kaburilist:
# if k in final:
# final.remove(k)
# #print("finremove1",k)
return final
def siage(fin):
fin=list(map(list, set(map(tuple, fin))))
finallen = sorted(fin, key=lambda x: len(x[0]))
finallendic=dict(finallen)
finalword=[]
for f in finallen:
finalword.append(f[0])
#print("f1",finalword)
notwo=[]
for v in itertools.combinations(finalword, 2):
#print(v)
if v[0] in v[1]:
#print("in")
if v[0] in finalword:
finalword.remove(v[0])
#print("f2",finalword)
finall=[]
for f in finalword:
finall.append([f,finallendic[f]])
finall = sorted(finall, key=lambda x: int(x[1]), reverse=True)
#print("final",finall)
kk=open("custam_freq_new.txt", 'w', errors='ignore')
kk.write(str(finall))
kk.close()
def eval_pattern(use_t):
tw=0
rp=0
rt=0
if "tweet" in use_t:
tw=1
if "retweet" in use_t:
rt=1
if "reply" in use_t:
rp=1
sword=""
if tw==1:
sword="filter:safe OR -filter:safe"
if rp==0:
sword=sword+" exclude:replies"
if rt==0:
sword=sword+" exclude:retweets"
elif tw==0:
if rp==1 and rt ==1:
sword="filter:reply OR filter:retweets"
elif rp==0 and rt ==0:
print("NO")
sys.exit()
elif rt==1:
sword="filter:retweets"
elif rp==1:
sword="filter:replies"
return sword
pat=eval_pattern(use_type)+" "+uselang
# config読み込み関数と実行
def a(n):
return n+1
def f(k):
k = list(map(a, k))
return k
def g(n,m):
b=[]
for _ in range(n):
m=f(m)
b.append(m)
return b
# 連番リスト生成
def validate(text):
if re.search(r'(.)\1{1,}', text):
return False
elif re.search(r'(..)\1{1,}', text):
return False
elif re.search(r'(...)\1{1,}', text):
return False
elif re.search(r'(...)\1{1,}', text):
return False
elif re.search(r'(....)\1{1,}', text):
return False
else:
return True
# 重複を調べる関数
def eval_what_nosp(c,i):
no_term=[]
no_start=[]
no_in=[]
koyu_meisi=[]
if re.findall(r"[「」、。)(『』&@_;【/<>,!】\/@]", c[0]):
no_term.append(i)
no_start.append(i)
no_in.append(i)
if len(c) == 4:
if "接尾" in c[3]:
no_start.append(i)
if "固有名詞" in c[3]:
koyu_meisi.append(i)
if c[3]=="名詞-非自立-一般":
no_term.append(i)
no_start.append(i)
no_in.append(i)
if "助詞" in c[3]:
no_term.append(i)
no_start.append(i)
#no_in.append(i)
if c[3]=="助詞-連体化":
no_start.append(i)
if c[3]=="助詞":
no_start.append(i)
if "お" in c[2]:
if c[3]=="名詞-サ変接続":
no_term.append(i)
no_start.append(i)
no_in.append(i)
if len(c) == 6:
if c[4]=="サ変スル":
no_start.append(i)
if c[3]=="動詞-非自立":
no_start.append(i)
if "接尾" in c[3]:
no_start.append(i)
if c[3]=="助動詞":
if c[2]=="た":
no_start.append(i)
no_in.append(i)
if c[3]=="助動詞":
if c[2]=="ない":
no_start.append(i)
if c[3]=="助動詞":
if "連用" in c[5]:
no_term.append(i)
no_start.append(i)
if c[2]=="する":
if c[3]=="動詞-自立":
if c[5]=="連用形":
no_start.append(i)
no_in.append(i)
if c[2]=="なる":
if c[3]=="動詞-自立":
no_start.append(i)
no_in.append(i)
if c[2]=="てる":
if c[3]=="動詞-非自立":
no_start.append(i)
no_in.append(i)
if c[2]=="です":
if c[3]=="助動詞":
no_start.append(i)
no_in.append(i)
if c[2]=="ちゃう":
if c[3]=="動詞-非自立":
no_start.append(i)
no_in.append(i)
if c[2]=="ある":
if c[3]=="動詞-自立":
no_term.append(i)
no_start.append(i)
no_in.append(i)
if c[2]=="助動詞":
if c[3]=="特殊ダ":
no_term.append(i)
no_start.append(i)
no_in.append(i)
if c[2]=="ます":
if c[3]=="助動詞":
no_term.append(i)
no_start.append(i)
no_in.append(i)
if "連用" in c[5]:
no_term.append(i)
if c[5]=="体言接続":
no_start.append(i)
if c[2]=="くれる":
if c[3]=="動詞-非自立":
no_start.append(i)
no_in.append(i)
x=""
y=""
z=""
koyu=""
if no_term:
x=no_term[0]
if no_start:
y=no_start[0]
if no_in:
z=no_in[0]
if koyu_meisi:
koyu=koyu_meisi[0]
#print("koyu",koyu)
koyu=int(koyu)
return x,y,z,koyu
small=[]
nodouble=[]
seq=""
def process(ty,tw,un,tagg):
global all
global seq
global small
global nodouble
tw=tw.replace("\n"," ")
sent_write.write(str(tw))
sent_write.write("\n")
parselist=m_owaka.parse(tw)
parsesplit=parselist.split()
parseocha=m_ocha.parse(tw)
l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')]
nodouble=[]
no_term=[]
no_start=[]
no_in=[]
km_l=[]
for i, block in enumerate(l):
c=block.split('\t')
#sent_write.write("\n")
#sent_write.write(str(c))
#sent_write.write("\n")
#print(str(c))
ha,hi,hu,km=eval_what_nosp(c,i)
no_term.append(ha)
no_start.append(hi)
no_in.append(hu)
km_l.append(km)
#分かち 書き 完成
if km_l[0]:
for r in km_l:
strin=parsesplit[r]
if not strin in nodouble:
all.append([strin,un])
nodouble.append(strin)
for s in range(2,8):
#2から8の連鎖。
#重くする代わりに精度を上げられるので重要
num=g(len(parsesplit)-s+1,range(-1,s-1))
for nr in num:
#1つの文章に対しての2-8連鎖の全通り
#print(no_term)
if not len(set(nr) & set(no_in)):
if not nr[-1] in no_term:
if not nr[0] in no_start:
small=[]
#print(str(parsesplit))
for nr2 in nr:
#print(nr2,parsesplit[nr2])
#中の配列をインデックスとした位置にある単語をsmallに追加
small.append(parsesplit[nr2])
seq="".join(small)
judge_whole=0
bad_direct_word=["みたいな","\'mat","I\'mat"]
#if "" in seq:
# judge_whole=1
#if "" in seq:
# judge_whole=1
for bd in bad_direct_word:
if seq==bd:
judge_whole=1
break
parselist=m_owaka.parse(seq)
l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')]
for n in range(len(l)):
if len(l[n].split("\t"))==6:
if l[n].split("\t")[3]=="動詞-自立":
if len(l[n+1].split("\t"))==6:
if l[n+1].split("\t")[3]:
judge_whole=1
break
if judge_whole==0:
if validate(seq) and len(seq) > 3 and not re.findall(r'[「」、。『』/\\/@]', seq):
if not seq in nodouble:
#連続回避
all.append([seq,un])
nodouble.append(seq)
#print("正常に追加",seq)
#同じ単語を2度集計しない
else:
#print("既に含まれています",seq)
pass
else:
#print("除外",seq)
pass
else:
#print("始まりがno_startです",seq)
pass
else:
#print("終わりがno_termです",seq)
pass
#print("\n")
#print(parsesplit)
#print(l)
if tagg:
print("tagg",tagg)
for sta in tagg:
all.append(["#"+str(sta),un])
#tagを含める
N=1
# 取得ツイート数
def print_varsize():
import types
print("{}{: >15}{}{: >10}{}".format('|','Variable Name','|',' Size','|'))
print(" -------------------------- ")
for k, v in globals().items():
if hasattr(v, 'size') and not k.startswith('_') and not isinstance(v,types.ModuleType):
print("{}{: >15}{}{: >10}{}".format('|',k,'|',str(v.size),'|'))
elif hasattr(v, '__len__') and not k.startswith('_') and not isinstance(v,types.ModuleType):
print("{}{: >15}{}{: >10}{}".format('|',k,'|',str(len(v)),'|'))
def collect_count():
global all
global deadline
hh=[]
tueall=[]
#print("alllll",all)
freshtime=int(time.time()*1000)-200000
deadline=-1
#import pdb; pdb.set_trace()
#print(N_time)
print(len(N_time))
for b in N_time:
if int(b[1]) < freshtime:
deadline=b[0]
print("dead",deadline)
dellist=[]
if not deadline ==-1:
for b in N_time:
print("b",b)
if int(b[0]) < int(deadline):
dellist.append(b)
for d in dellist:
N_time.remove(d)
#print(N_time)
#import pdb; pdb.set_trace()
#time.sleep(2)
#import pdb; pdb.set_trace()
for a in all:
if int(a[1]) > freshtime:
#取得したいツイート数/45*1000の値を引く。今は5000/45*1000=112000
tueall.append(a[0])
#print("tuealllappend"*10)
#print(tueall)
else:
all.remove(a)
#print("allremove",a)
#import pdb; pdb.set_trace()
c = collections.Counter(tueall)
c=c.most_common()
#print("c",c)
#print(c)
for r in c:
if r and r[1]>1:
hh.append([str(r[0]),str(r[1])])
k=str(hh).replace("[]","")
freq_write=open("custam_freq.txt","w",encoding="utf-8-sig", errors='ignore')
freq_write.write(str(k))
#import pdb; pdb.set_trace()
oldunix=N_time[0][1]
newunix=N_time[-1][1]
dato=str(datetime.datetime.fromtimestamp(oldunix/1000)).replace(":","-")
datn=str(datetime.datetime.fromtimestamp(newunix/1000)).replace(":","-")
dato=dato.replace(" ","_")
datn=datn.replace(" ","_")
#print(dato,datn)
#import pdb; pdb.set_trace()
freq_writea=open("trenddata/custam_freq-"+dato+"-"+datn+"--"+str(len(N_time))+".txt","w",encoding="utf-8-sig", errors='ignore')
freq_writea.write(str(k))
#import pdb; pdb.set_trace()
freq_write_tue=open("custam_freq_tue.txt","w",encoding="utf-8-sig", errors='ignore')
freq_write_tue.write(str(all))
#print(c)
def remove_emoji(src_str):
return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI)
def deEmojify(inputString):
return inputString.encode('ascii', 'ignore').decode('ascii')
def get_tag(tw,text_content):
taglist=[]
entities=eval(str(tw.entities))["hashtags"]
for e in entities:
text=e["text"]
taglist.append(text)
for _ in range(len(taglist)+2):
for s in taglist:
text_content=re.sub(s,"",text_content)
#text_content=re.sub(r"#(.+?)+ ","",text_content)
return taglist,text_content
def get_time(id):
two_raw=format(int(id),'016b').zfill(64)
unixtime = int(two_raw[:-22],2) + 1288834974657
unixtime_th = datetime.datetime.fromtimestamp(unixtime/1000)
tim = str(unixtime_th).replace(" ","_")[:-3]
return tim,unixtime
non_bmp_map = dict.fromkeys(range(0x10000, sys.maxunicode + 1), '')
N_time=[]
def gather(tweet,type,tweet_type,removed_text):
global N
global N_all
global lagtime
global all_time
global all
global auth
global N_time
if get_time(tweet.id):
tim,unix=get_time(tweet.id)
else:
exit
#細かいツイート時間を取得
#original_text=tweet.text
nowtime=time.time()
tweet_pertime=str(round(N/(nowtime-all_time),1))
lag=str(round(nowtime-unix/1000,1))
#ラグを計算
lang=lang_dict[tweet.lang]
print(N_all,N,tweet_pertime,"/s","+"+lag,tim,type,tweet_type,lang)
#情報表示。(全ツイート、処理ツイート、処理速度、ラグ、実時間、入手経路、ツイートタイプ、言語)
print(removed_text.replace("\n"," "))
taglist,tag_removed_text=get_tag(tweet,removed_text)
#import pdb; pdb.set_trace()
#print(type(tweet))
#import pdb; pdb.set_trace()
#タグを除く
noemoji=remove_emoji(tag_removed_text)
try:
process(tweet_type,tag_removed_text,unix,taglist)
N_time.append([N,unix])
print("trt",tag_removed_text)
except Exception as pe:
print("process error")
print(pe)
#import pdb; pdb.set_trace()
#実処理に送る
surplus=N%1000
if surplus==0:
#sumprocess()
try:
collect_count()
except Exception as eeee:
print(eeee)
#exit
#集計しよう
cft_read=open("custam_freq.txt","r",encoding="utf-8-sig")
cft_read=cft_read.read()
cft_read=eval(cft_read)
max_freq=cft_read[0][1]
#最大値
allen=inita(max_freq,cft_read)
#同じ頻度のトレンドでまとめたリストにする。
finf=notwo(allen)
#重複する文字列、重複するトレンドを探して削除する
siage(finf)
#それをnew_freqとして書き込む
print_varsize()
#メモリ情報を表示
N=N+1
# streaming本体
def judge_tweet_type(tweet):
text = re.sub("https?://[\w/:%#\$&\?\(\)~\.=\+\-]+","",tweet.text)
if tweet.in_reply_to_status_id_str :
text=re.sub(r"@[a-zA-Z0-9_]* ","",text)
text=re.sub(r"@[a-zA-Z0-9_]","",text)
return "reply",text
else:
head= str(tweet.text).split(":")
if len(head) >= 2 and "RT" in head[0]:
text=re.sub(r"RT @[a-zA-Z0-9_]*: ","",text)
return "retwe",text
else:
return "tweet",text
badword=["質問箱","マシュマロを投げ合おう","質問がじゃんじゃん届く","参戦","配信","@","フォロー","応募","スマホRPG","ガチャ","S4live","キャンペーン","ドリフトスピリッツ","プレゼント","協力ライブ","完全無料で相談受付中","おみくじ","当たるチャンス","GET","ゲット","shindanmaker","当たる","抽選"]
N_all=0
def gather_pre(tweet,type):
global N_all
N_all=N_all+1
#ここを通過する全ツイート数カウント
go=0
for b in badword:
if b in tweet.text:
go=1
break
#テキスト内にbadwordがあるか判断、0で含まれないからGO判断
if go == 0:
if tweet.lang=="ja":
tweet_type,removed_text=judge_tweet_type(tweet)
#ツイートタイプを判断
if tweet_type=="tweet":
try:
gather(tweet,type,tweet_type,removed_text)
#print(type(tweet))
#gather処理に送る。
except Exception as eee:
#gather("あ","あ","あ","あ")
#import pdb; pdb.set_trace()
pass
lagtime=0
def search(last_id):
#print(pat)
global pat
time_search =time.time()
for status in apiapp.search(q=pat,count="100",result_type="recent",since_id=last_id):
#searchで最後に取得したツイートよりも新しいツイートを取得
gather_pre(status,"search")
# search本体
interval = 2.16
# search呼び出し間隔
# min2
trysearch=0
# search呼び出し回数
class StreamingListener(tweepy.StreamListener):
def on_status(self, status):
global time_search
global trysearch
gather_pre(status,"stream")
time_stream=time.time()
time_stream-time_search % interval
if time_stream-time_search-interval>interval*trysearch:
#一定時間(interbal)ごとにsearchを実行する。
last_id=status.id
#executor = concurrent.futures.ThreadPoolExecutor(max_workers=8)
#executor.submit(search(last_id))
#並列処理を試す場合
search(last_id)
trysearch=trysearch+1
# streaming本体
def carry():
listener = StreamingListener()
streaming = tweepy.Stream(auth, listener)
streaming.sample()
# stream呼び出し関数
time_search =time.time()
# searchを最後に実行した時間だがstream前に定義
executor = concurrent.futures.ThreadPoolExecutor(max_workers=8)
# 並列定義
all_time=time.time()
# 実行開始時間定義
try:
carry()
except Exception as e:
import pdb; pdb.set_trace()
print(e)
#import pdb; pdb.set_trace()
pass
#except Exception as ee:
#print(ee)
#import pdb; pdb.set_trace()
# carry本体とエラー処理
下は意味トレンドのプログラムですが、絶賛作業中なので、自信をもってオススメできます()。シソーラスから持ってくる部分は自分が書いたものではないですが、残しておきます。
from bs4 import BeautifulSoup
import collections
import concurrent.futures
import datetime
import emoji
import itertools
import MeCab
from nltk import Tree
import os
from pathlib import Path
from pytz import timezone
import re
import spacy
import subprocess
import sys
import time
import tweepy
import unidic2ud
import unidic2ud.cabocha as CaboCha
from urllib.error import HTTPError, URLError
from urllib.parse import quote_plus
from urllib.request import urlopen
m=MeCab.Tagger("-d ./unidic-cwj-2.3.0")
os.remove("bunrui01.csv")
os.remove("all_tweet_text.txt")
os.remove("all_kakari_imi.txt")
bunrui01open=open("bunrui01.csv","a",encoding="utf-8")
textopen=open("all_tweet_text.txt","a",encoding="utf-8")
akiopen=open("all_kakari_imi.txt","a",encoding="utf-8")
catedic={}
with open('categori.txt') as f:
a=f.read()
aa=a.split("\n")
b=[]
bunrui01open.write(",,,")
for i, j in enumerate(aa):
catedic[j]=i
bunrui01open.write(str(j))
bunrui01open.write(",")
bunrui01open.write("\n")
print(catedic)
with open('./BunruiNo_LemmaID_ansi_user.csv') as f:
a=f.read()
aa=a.split(",\n")
b=[]
for bb in aa:
if len(bb.split(","))==2:
b.append(bb.split(","))
word_origin_num_to_cate=dict(b)
with open('./cate_rank2.csv') as f:
a=f.read()
aa=a.split("\n")
b=[]
for bb in aa:
if len(bb.split(","))==2:
b.append(bb.split(","))
cate_rank=dict(b)
class Synonym:
def getSy(self, word, target_url, css_selector):
try:
# アクセスするURLに日本語が含まれているのでエンコード
self.__url = target_url + quote_plus(word, encoding='utf-8')
# アクセスしてパース
self.__html = urlopen(self.__url)
self.__soup = BeautifulSoup(self.__html, "lxml")
result = self.__soup.select_one(css_selector).text
return result
except HTTPError as e:
print(e.reason)
except URLError as e:
print(e.reason)
sy = Synonym()
alist = ["選考"]
# 検索する先は「日本語シソーラス 連想類語辞典」を使用
target = "https://renso-ruigo.com/word/"
selector = "#content > div.word_t_field > div"
# for item in alist:
# print(sy.getSy(item, target, selector))
consumer_key = ""
consumer_secret = ""
access_token = ""
access_token_secret = ""
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
authapp = tweepy.AppAuthHandler(consumer_key,consumer_secret)
apiapp = tweepy.API(authapp)
# 認証(ここではapi)
def remove_emoji(src_str):
return ''.join(c for c in src_str if c not in emoji.UNICODE_EMOJI)
def get_tag(tw,text_content):
taglist=[]
entities=eval(str(tw.entities))["hashtags"]
for e in entities:
text=e["text"]
taglist.append(text)
for _ in range(len(taglist)+2):
for s in taglist:
text_content=re.sub(s,"",text_content)
#text_content=re.sub(r"#(.+?)+ ","",text_content)
return taglist,text_content
def get_swap_dict(d):
return {v: k for k, v in d.items()}
def xcut(asub,a):
asub.append(a[0])
a=a[1:len(a)]
return asub,a
def ycut(asub,a):
asub.append(a[0])
a=a[1:len(a)]
return asub,a
def bunruikugiri(lastx,lasty):
hoge=[]
#import pdb; pdb.set_trace()
editx=[]
edity=[]
for _ in range(500):
edity,lasty=ycut(edity,lasty)
#target=sum(edity)
for _ in range(500):
target=sum(edity)
#rint("sum",sum(editx),"target",target)
if sum(editx)<target:
editx,lastx=xcut(editx,lastx)
elif sum(editx)>target:
edity,lasty=ycut(edity,lasty)
else:
hoge.append(editx)
editx=[]
edity=[]
if lastx==[] and lasty==[]:
return hoge
break
all_appear_cate=[]
all_unfound_word=[]
all_kumiawase=[]
nn=1
all_kakari_imi=[]
def process(tw,ty):
global nn
wordnum_toword={}
catenum_wordnum={}
word_origin_num=[]
mozisu=[]
try:
tw=re.sub("https?://[\w/:%#\$&\?\(\)~\.=\+\-]+","",tw)
tw=tw.replace("#","")
tw=tw.replace(",","")
tw=tw.replace("\u3000","") #文字数合わせのため重要
tw=re.sub(re.compile("[!-/:-@[-`{-~]"), '', tw)
parseocha=m.parse(tw)
print(tw)
l = [x.strip() for x in parseocha[0:len(parseocha)-5].split('\n')]
bunrui_miti_sentence=[]
for i, block in enumerate(l):
if len(block.split('\t')) > 1:
c=block.split('\t')
d=c[1].split(",")
#単語の処理過程
print(d,len(d))
if len(d)>9:
if d[10] in ["する"]:
word_origin_num.append(d[10])
bunrui_miti_sentence.append(d[8])
mozisu.append(len(d[8]))
elif d[-1] in word_origin_num_to_cate:
word_origin_num.append(int(d[-1]))
wordnum_toword[int(d[-1])]=d[8]
bunrui_miti_sentence.append(word_origin_num_to_cate[str(d[-1])])
mozisu.append(len(d[8]))
else:
#print("nai",d[8])
#未知語の表示
all_unfound_word.append(d[10])
bunrui_miti_sentence.append(d[8])
mozisu.append(len(c[0]))
else:
mozisu.append(len(c[0]))
all_unfound_word.append(c[0])
bunrui_miti_sentence.append(c[0])
#else:
# mozisu.append(l[])
#print("kouho",word_origin_num,"\n")
#単語をオリジナル番号に
#print(tw)
#意味分類と未知語で作った文を見るなら
for s in bunrui_miti_sentence:
print(s," ",end="")
print("\n")
stn=0
cmd = "echo "+str(tw)+" | cabocha -f1"
cmdtree="echo "+str(tw)+" | cabocha "
proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE,shell=True)
proctree = subprocess.Popen(cmdtree, stdout=subprocess.PIPE, stderr=subprocess.PIPE,shell=True)
proc=proc.communicate()[0].decode('cp932')
proctree=proctree.communicate()[0].decode('cp932')
print(proctree)
proclist=proc.split("\n")
#print(proc)
#f1情報
#print(proclist)
#リスト化情報
procnumlist=[]
wordlis=[]
eachword=""
num=0
for p in proclist:
if p[0]=="*":
f=p.split(" ")[1]
t=p.split(" ")[2].replace("D","")
procnumlist.append([f,t])
if eachword:
wordlis.append([num,eachword])
num=num+1
eachword=""
elif p=="EOS\r":
wordlis.append([num,eachword])
num=num+1
eachword=""
break
else:
#print("aaaaa",p.split("\t")[0])
eachword=eachword+p.split("\t")[0]
tunagari_num_dict=dict(procnumlist)
print(tunagari_num_dict)
bunsetu_num_word=dict(wordlis)
#print(bunsetu_num_word)
bunsetu_mozisu=[]
for v in bunsetu_num_word.values():
bunsetu_mozisu.append(len(v))
if sum(bunsetu_mozisu) != sum(mozisu):
return
#print("mozisu",mozisu)
#print("bunsetumozi",bunsetu_mozisu)
res=bunruikugiri(mozisu,bunsetu_mozisu)
#print("res",res)
nnn=0
small_cateandcharlist=[]
big_cateandcharlist=[]
for gc in res:
for _ in range(len(gc)):
print(bunrui_miti_sentence[nnn],end=" ")
if bunrui_miti_sentence[nnn] in list(catedic.keys()):
small_cateandcharlist.append(bunrui_miti_sentence[nnn])
nnn=nnn+1
#未知語や助詞も同じものだとみなされているからmecabnegold辞書使えそう
if small_cateandcharlist==[]:
big_cateandcharlist.append(["null"])
else:
big_cateandcharlist.append(small_cateandcharlist)
small_cateandcharlist=[]
print("\n")
#print("bcacl",big_cateandcharlist)
twewtnai_kakari_imi=[]
if len(big_cateandcharlist)>1 and len(big_cateandcharlist)==len(bunsetu_num_word):
#係り受け、形態素解析の区切りが一致しない
for kk, vv in tunagari_num_dict.items():
if vv != "-1":
for aaw in big_cateandcharlist[int(kk)]:
for bbw in big_cateandcharlist[int(vv)]:
twewtnai_kakari_imi.append([aaw,bbw])
if not "順位記号" in str([aaw,bbw]):
if not "null" in str([aaw,bbw]):
if not "数記号" in str([aaw,bbw]):
if not "事柄" in str([aaw,bbw]):
all_kakari_imi.append(str([aaw,bbw]))
akiopen.write(str([aaw,bbw]))
else:
break
else:
return
akiopen.write("\n")
akiopen.write(str(bunrui_miti_sentence))
akiopen.write("\n")
akiopen.write(str(tw))
akiopen.write("\n")
print("tki",twewtnai_kakari_imi)
tweetnai_cate=[]
word_cate_num=[]
for k in word_origin_num:
if str(k) in word_origin_num_to_cate:
ram=word_origin_num_to_cate[str(k)]
print(ram,cate_rank[ram],end="")
tweetnai_cate.append(ram)
all_appear_cate.append(ram)
word_cate_num.append(catedic[ram])
catenum_wordnum[catedic[ram]]=int(k)
stn=stn+1
else:
if k in ["する"]:
all_appear_cate.append(k)
tweetnai_cate.append(k)
print("\n")
#print(tweetnai_cate)
#import pdb; pdb.set_trace()
for k in tweetnai_cate:
if k in catedic:
aac=catedic[k]
#print("gyaku",word_cate_num)
#print("wt",wordnum_toword)
#print("cw",catenum_wordnum)
bunrui01open.write(str(tw))
bunrui01open.write(",")
bunrui01open.write(str(tim))
bunrui01open.write(",")
bunrui01open.write(str(unix))
bunrui01open.write(",")
ps=0
for tt in list(range(544)):
if int(tt) in word_cate_num:
a=catenum_wordnum[tt]
#かてごりから単語番号
bunrui01open.write(str(wordnum_toword[a]))
#単語番号から単語
bunrui01open.write(",")
ps=ps+1
else:
bunrui01open.write("0,")
bunrui01open.write("end")
bunrui01open.write("\n")
textopen.write(str(nn))
textopen.write(" ")
textopen.write(tw)
textopen.write("\n")
nn=nn+1
#全ての通りを入れる
for k in list(itertools.combinations(tweetnai_cate,2)):
all_kumiawase.append(k)
except Exception as ee:
print(ee)
import pdb; pdb.set_trace()
pass
def judge_tweet_type(tweet):
if tweet.in_reply_to_status_id_str:
return "reply"
else:
head= str(tweet.text).split(":")
if len(head) >= 2 and "RT" in head[0]:
return "retwe"
else:
return "tweet"
# リプ、リツイート、ツイートか判断
def get_time(id):
two_raw=format(int(id),'016b').zfill(64)
unixtime = int(two_raw[:-22],2) + 1288834974657
unixtime_th = datetime.datetime.fromtimestamp(unixtime/1000)
tim = str(unixtime_th).replace(" ","_")[:-3]
return tim,unixtime
# idからツイート時間
N=1
def gather(tweet,type,tweet_typea):
global all_appear_cate
global N
global all_time
global tim
global unix
tim,unix=get_time(tweet.id)
original_text=tweet.text.replace("\n","")
taglist,original_text=get_tag(tweet,original_text)
nowtime=time.time()
tweet_pertime=str(round(N/(nowtime-all_time),1))
lag=str(round(nowtime-unix/1000,1))
#lang=lang_dict[tweet.lang]
try:
process(remove_emoji(original_text),tweet_typea,)
except Exception as e:
print(e)
#import pdb; pdb.set_trace()
pass
print(N,tweet_pertime,"/s","+"+lag,tim,type,tweet_typea)
N=N+1
if N%500==0:
ccdd=collections.Counter(all_appear_cate).most_common()
for a in ccdd:
print(a)
#ccdd=collections.Counter(all_unfound_word).most_common()
#for a in ccdd:
# print("ない",a)
ccdd=collections.Counter(all_kumiawase).most_common(300)
for a in ccdd:
print(a)
ccdd=collections.Counter(all_kakari_imi).most_common(300)
for a in ccdd:
print("all_kakari_imi",a)
#import pdb; pdb.set_trace()
# streamとsearchの全ツイートが集まる
def pre_gather(tw,ty):
#print(ty)
# if "http://utabami.com/TodaysTwitterLife" in tw.text:
print(tw.text)
if ty=="stream":
tweet_type=judge_tweet_type(tw)
if tw.lang=="ja" and tweet_type=="tweet":
gather(tw,ty,tweet_type)
elif ty=="search":
gather(tw,ty,"tweet")
def search(last_id):
time_search =time.time()
for status in apiapp.search(q="filter:safe OR -filter:safe -filter:retweets -filter:replies lang:ja",count="100",result_type="recent",since_id=last_id):
pre_gather(status,"search")
# search本体
class StreamingListener(tweepy.StreamListener):
def on_status(self, status):
global time_search
global trysearch
pre_gather(status,"stream")
time_stream=time.time()
time_stream-time_search % interval
if time_stream-time_search-interval>interval*trysearch:
last_id=status.id
#executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)
#executor.submit(search(last_id))
search(last_id)
trysearch=trysearch+1
# streaming本体
def carry():
listener = StreamingListener()
streaming = tweepy.Stream(auth, listener)
streaming.sample()
interval = 2.1
trysearch=0
time_search =time.time()
# executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)
all_time=time.time()
try:
#executor.submit(carry)
carry()
except Exception as er:
print(er)
import pdb; pdb.set_trace()
pass
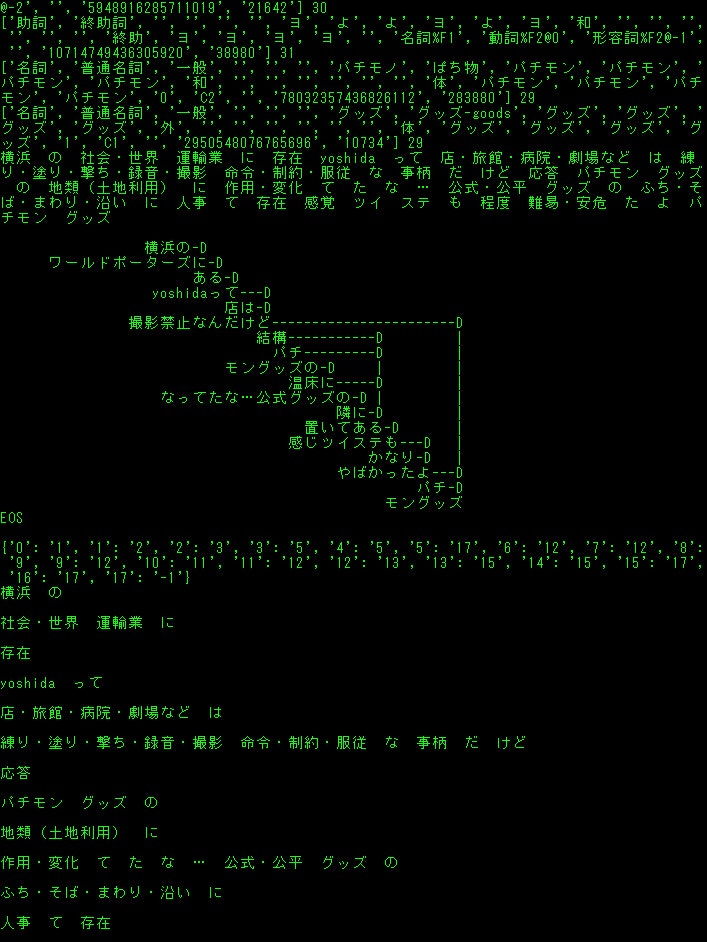
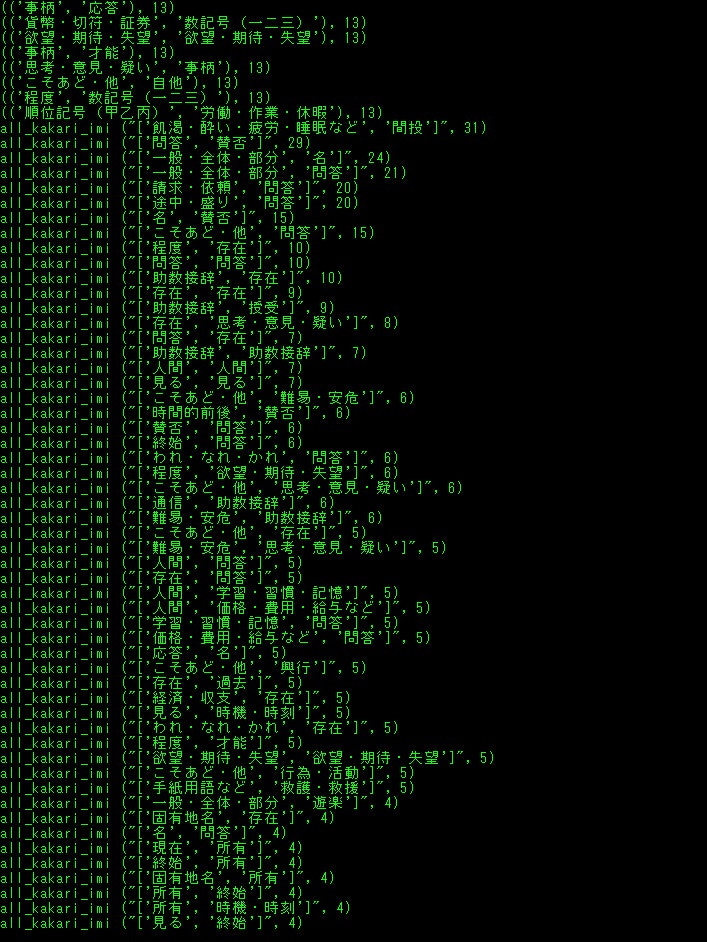
500ツイートごとに、
単純な意味の出現数
2-gramの意味の出現数
2-gram間の係り受けのある意味連続?の出現数
また全てに、
ツイート本文、Unidic解析情報、CaboCha係り受け、意味分類との置き換えなどあります。
bunrui01.csvー横軸に544の意味分類、縦軸にツイートで、0は存在しない、1は該当する単語となるよう書き込むcsvです
all_tweet_textー処理ツイートとそれが何番目か
all_kakari_imiー係り受け意味ペア、意味分類置き換え、本文
categori.txtー544の意味分類を記したtxtで実行時にindexで辞書を作ります。
BunruiNo_LemmaID_ansi_user.csvーは詳しくはhttps://pj.ninjal.ac.jp/corpus_center/goihyo.html
を見れば分かるのですが、単語オリジナルNoと意味分類の対応表です。
cate_rank2.csvーある時に作った意味分類の出現順辞書です。
他の変数の説明はまた後ほど、、
自分のメモ用で、分かる人は頑張って理解してというくらいなのでこれくらいにします。