はじめに
例えばWeb広告で「あるバナー画像は何度表示されてもクリック, 購入されない」とか「あるwebサイトにいくら広告を配信してもクリック, 購入されない」というとき, 広告主としては「このバナー画像 or webサイトってせいぜい何%ぐらいのクリック率, 購入率なんだろうか?これらの確率がよっぽど低いなら, もうあきらめて切り替えて別のバナーを使うとか, このサイトへ広告掲載をするのをやめるべきだ」よってクリック率や購入率を見積もりたい, ということがあります.
これを, 非常にラフなモデル化をするとベルヌーイ分布で表せそうです. つまり, 以下のような問題を考えます.
- 問題
確率 $p$ で $Z=1$ になり, 確率 $1-p$ で $Z=0$ になるようなベルヌーイ分布を考える. この分布に独立に従う確率変数群 $Z_i$ $(i=1,\dots,N)$ がある. いま $Z_i$ の実現値が全て $0=Z_1=Z_2=\dots=Z_N$ であるとき, $p$ はどのくらいの値でありうるのか?
直感的には, $N$ 回もやってダメなんだから $p \ll 1/N$ だろう...と思えてきますが, 分かっていることはあくまでも「$N$ 回試行したら今のところ全部 $Z=0$ になった」だけなので「実は $p=1/(N+1)$ であり $N+1$ 回目の試行で $Z=1$ が実現する」かもしれませんし,「実は $p=1/2$ なのに, とんでもなく不運なことに今までの結果は $2^{-N}$ の確率を踏んでしまっている」のかも知れません.
シミュレーションしてみる
とりあえずどんな感じになるのか, 適当に乱数で真値 $p$ を定め, 最初に $Z=1$ が出る前に, $Z=0$ が連続で出た回数 $N$ をプロットします.
実行コード
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import pandas as pd
import joblib
import tqdm
import sys
import random
np.random.seed(1)
random.seed(1)
# L個の真値pを用意
L = 20000
ps = stats.loguniform.rvs(1e-6, 1, size=L)
height = 8
width = 16
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(width, height))
iax = ax
iax.hist(ps, bins=np.logspace(-6,0,100))
iax.set_xscale("log")
iax.set_xlabel("p")
fig.savefig("distribution_of_p.png", facecolor="w")
まず真値 $p$ をたくさん作ります. 今回は大幅に $p$ を変えてシミュレーションしたいので, 対数軸で一様になるよう, 適当な範囲で20000個用意しました.
実行コード
def trial_until_first_success(p) :
cnt = 0
while (cnt < sys.maxsize) :
if (np.random.rand() <= p) :
break
cnt = cnt + 1
return cnt
# 最初に成功するまでの試行回数Nをカウント
ns = np.array( joblib.Parallel(n_jobs=-1)(joblib.delayed(trial_until_first_success)(p) for p in tqdm.tqdm(ps)) )
result_df = pd.DataFrame({"p" : ps,"N" : ns});
# 対数軸でプロットしたい & 関心の対象外なので, N=0の時は無視しておく
result_df = result_df[result_df.N > 0].reset_index(drop=True)
result_df.sort_values(by="N", inplace=True)
height = 8
width = 16
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(width, height))
iax = ax
iax.scatter(result_df.N, result_df.p, marker=".", alpha=0.1, color="gray")
x = result_df.N
y = 1/x
iax.plot(x, y, alpha=0.5, label=f"1/N", color="k", linestyle="--")
iax.set_xlabel("N")
iax.set_ylabel("p")
iax.set_xscale("log")
iax.set_yscale("log")
iax.legend()
fig.savefig("distribution_of_p_and_N.png", facecolor="w")
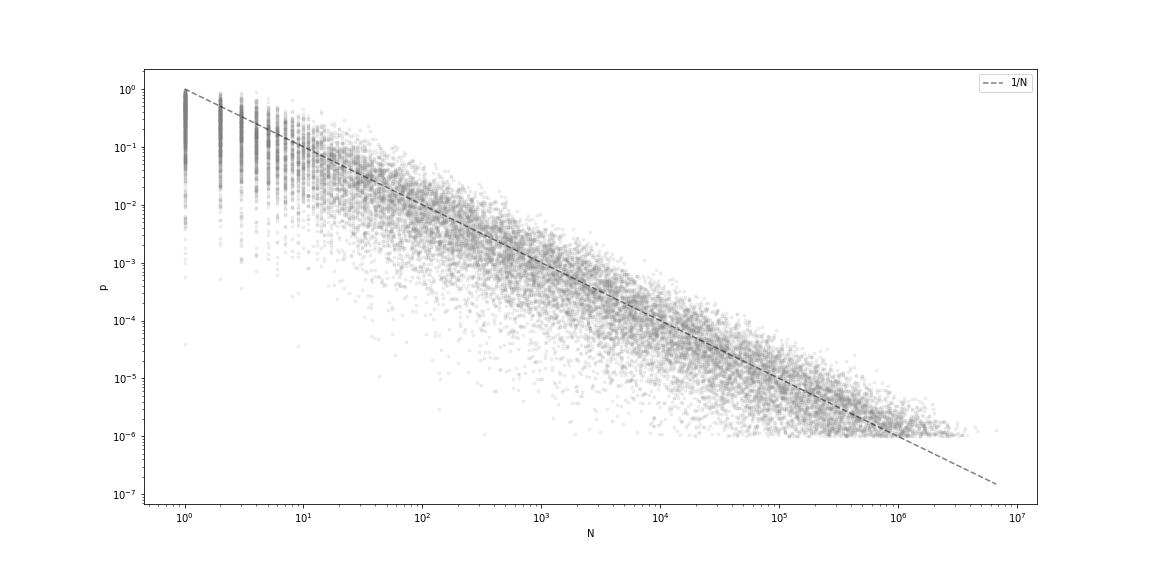
実際に確率 $p$ でベルヌーイ試行して, 最初に成功するまで失敗し続けた回数 $N$ を求め, $p$ と $N$ の関係 = 散布図を描きます. 点線は $1/N$ で, 何となく $1/N$ を中心に分布しているように見えます. 上述の問いは「この点群の分布の上側の端っこってどのくらいなの?」という話です.
アプローチしてみる
さて, 本稿では上述の問題に対して, まずは集中不等式と呼ばれる確率変数の和に関する不等式を使ってアプローチしてみます. 不等式のバリエーションはいろいろありますが, 今回のケースで使いやすいためここではいずれも [1] で述べられている形で引用します.
1.Hoeffding's inequality
集中不等式の代表的なものにHoeffdingの不等式があります. これは学習理論では汎化誤差の理論解析[2,4]や, バンディット問題のアルゴリズムであるUCBの導出[3,5]に出てきたりする有名な不等式です.
- ([1]のTheorem 1) $Z,Z_1, \dots, Z_N$ を i.i.d. かつ $[0,1]$ に値を取る確率変数とし, $\delta > 0$ とする. このとき $Z_1,\dots,Z_N$ について少なくとも $1-\delta$ の確率で次式が成り立つ.
\begin{eqnarray}
\mathbb{E}[Z]-\frac{1}{N}\sum_{i=1}^N Z_i \le \sqrt{\frac{\log(1/\delta)}{2N}} \tag{1}
\end{eqnarray}
これを今回の問題に当てはめると, $Z_i=\dots=Z_N=0$, また $Z_i$ はパラメタ $p$ のベルヌーイ分布に従うことより $\mathbb{E}[Z]-\frac{1}{N}\sum_{i=1}^N Z_i=\mathbb{E}[Z]=p$ です. よって $(1)$ より $p$ の上界を次のように得ることができます.
- 少なくとも $1-\delta$ の確率で以下が成り立つ.
\begin{eqnarray}
p \le \sqrt{\frac{\log(1/\delta)}{2N}}
\end{eqnarray}
2.Bernstein's inequality
Hoeffdingの不等式では確率変数の分散の情報を考慮していませんでした. 分散を考慮した集中不等式としてBernsteinの不等式というものがあります[1,4,6]. ([1]ではBennett’s inequalityという名前で呼ばれています. Bennett's inequalityの式を簡単に整理した版がBernstein's inequalityという扱いのようです[6])
- ([1] Theorem 3) $Z,Z_1, \dots, Z_N$ を i.i.d. かつ $[0,1]$ に値を取る確率変数とし, $\delta > 0$ とする. $Z$ の分散を $\mathbb{V}[Z]=\mathbb{E}[(Z-\mathbb{E}[Z])^2]$ とする. このとき $Z_1,\dots,Z_N$ について少なくとも $1-\delta$ の確率で次式が成り立つ.
\begin{eqnarray}
\mathbb{E}[Z]-\frac{1}{N}\sum_{i=1}^N Z_i \le \sqrt{\frac{2\mathbb{V}
[Z]\log(1/\delta)}{N}}+ \frac{\log(1/\delta)}{3N} \tag{2}
\end{eqnarray}
さて $(1)$ と同様にこれを今回の問題に当てはめると, 左辺は先ほどHoeffdingの不等式を用いた時と同様に $p$ になります. 問題は $\mathbb{V}[Z]$ です. ここでは $Z$ がパラメタ $p$ のベルヌーイ分布に従うことより $\mathbb{V}[Z]=(1-p)p$ ですが, 具体的な $p$ がわからないためひとまず最大値を取り $(1-p)p<1/4$ で抑えてみます. さて $(2)$ より $p$ の上界を次のように得ることができます.
- 少なくとも $1-\delta$ の確率で以下が成り立つ.
\begin{eqnarray}
p \le \sqrt{\frac{\log(1/\delta)}{2N}}+ \frac{\log(1/\delta)}{3N}
\end{eqnarray}
明らかに $\mathbb{V}[Z]$ の見積もりが緩いので Hoeffding の不等式を使ったときよりも大きな上界しか得られていません. $N$ 回も連続で同じ値が出ているんだから $Z$ の分散なんて相当小さそうですが, これをうまく使えないものでしょうか.
($\mathbb{V}[Z] = (1-p)p \le p$ で $p$ を Hoeffding を使って抑えたら何とかなりそうですが, $1-\delta$ の確率で成り立つ式に $1-\delta$ の確率で成り立つ何かをまた追加で考える...?と考えていると混乱してくるので, ここではこのアプローチの深追いは避けます.)
3.Empirical Bernstein's inequality
前述のBernsteinの不等式を使った評価では、分散 $\mathbb{V}[Z]$ の評価に失敗しています. なんとかならんものかと探したところ, 標本分散を使った版のBernsteinの不等式を見つけました.
- ([1] Theorem 4) $Z,Z_1, \dots, Z_N$ を i.i.d. かつ $[0,1]$ に値を取る確率変数とし, $\delta > 0$ とする. $Z_i$ の標本分散を
\begin{eqnarray}
{\rm V}_N[(Z_1,\dots,Z_N)] = \frac{1}{N(N-1)} \sum_{N\ge i>j\ge 1} (Z_i-Z_j)^2
\end{eqnarray}
とする. このとき $Z_1,\dots,Z_N$ について少なくとも $1-\delta$ の確率で次式が成り立つ.
\begin{eqnarray}
\mathbb{E}[Z]-\frac{1}{N}\sum_{i=1}^N Z_i \le \sqrt{\frac{2{\rm V}_N
[(Z_1,\dots,Z_N)]\log(2/\delta)}{N}}+ \frac{7\log(2/\delta)}{3(N-1)} \tag{3}
\end{eqnarray}
さて $(1),(2)$ と同様にこれを今回の問題に当てはめると, 左辺は先ほどと同様に $p$ になりますね. また今度は標本分散を使うのでいい感じに評価ができて $Z_1=\cdots=Z_N=0$ より ${\rm V}_N[(Z_1,\dots,Z_N)] = 0$ です. よって $(3)$ より $p$ の上界を次のように得ることができます.
- 少なくとも $1-\delta$ の確率で以下が成り立つ.
\begin{eqnarray}
p \le \frac{7\log(2/\delta)}{3(N-1)}
\end{eqnarray}
4.Beta分布の累積分布関数の逆関数
アプローチを変えてみます. ベルヌーイ分布の共役事前分布はベータ分布なので, $p$ がベータ分布に従うとして, $Beta(1, 1+N)$ の上側 $\delta$ 点を $p$ の上界としてみます. いわば, 「Hoeffdingの不等式を使うこと」がバンディット問題でいうUCBに倣った方法なら, こちらはThompson Samplingに倣った方法です[7].
プロットしてみる
さて今回出してみた4つの $p$ の上界を最初の散布図と比較してみます. このプロットに期待することは, 上界よりも上に来る灰色の点が, 全体の $\delta$ % 以下であることです. ここではとりあえず $\delta=0.05$ としておきます.
実行コード
height = 8
width = 16
fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(width, height))
iax = ax
iax.scatter(result_df.N, result_df.p, marker=".", alpha=0.1, color="gray")
delta = 0.05
def hoeffding(delta, n) :
return np.sqrt(np.log(1/delta)/(2*n))
def bernstein(delta, n) :
return np.log(1/delta)/(3*n)+np.sqrt(np.log(1/delta)/(2*n))
def empirical_bernstein(delta, n) :
return (7/3)*np.log(2/delta)/(n-1)
def beta_cdf_perentile(delta, n) :
return stats.beta.ppf(1-delta, 1, 1+n)
x = result_df.N
y = 1/x
iax.plot(x, y, alpha=0.5, label=f"1/N", color="k", linestyle="--")
y = np.array([hoeffding(delta, n) for n in x])
iax.plot(x, y, alpha=1, label=f"hoeffding {100*delta}%")
y = np.array([bernstein(delta, n) for n in x])
iax.plot(x, y, alpha=1, label=f"bernstein {100*delta}%")
y = np.array([empirical_bernstein(delta, n) for n in x[x>1]])
iax.plot(x[x>1], y, alpha=1, label=f"emp.bernstein {100*delta}%")
y = np.array([beta_cdf_perentile(delta, n) for n in x])
iax.plot(x, y, alpha=1, label=f"beta cdf upper {100*delta}%")
iax.set_xlabel("N")
iax.set_ylabel("p")
iax.set_xscale("log")
iax.set_yscale("log")
iax.legend()
fig.savefig("upperbound_of_p.png", facecolor="w")
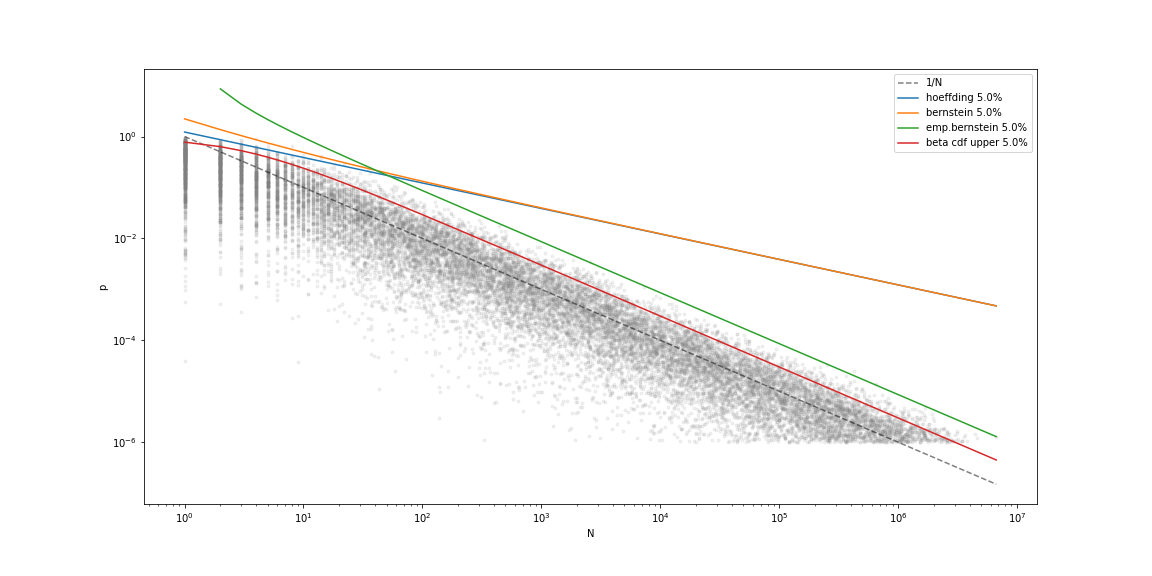
なんとなく灰色の点群を上から抑える, それっぽい感じ(?)になっています. Hoeffdingの不等式を使った上界は $p$ が大きい所で有効な上界に見えますが, $O(1/\sqrt{N})$ なので $p$ が小さくなると $1/N$ から外れていきます. 一方でEmpirical Bernsteinの上界は $O(1/N)$ なので, 裾の部分でも
有効な評価ができていそうです. さて, では実際どのくらいの点が上界より上にあるのでしょうか.
実行コード
result_df["hoef_ub"] = [hoeffding(delta, n) for n in x]
result_df["bern_ub"] = [bernstein(delta, n) for n in x]
result_df["emp_bern_ub"] = [empirical_bernstein(delta, n) if n > 1 else 1 for n in x]
result_df["beta_ub"] = [beta_cdf_perentile(delta, n) for n in x]
# 求めた「最低でも確率1-δでpの上界」よりもpのほうが大きい割合
pd.DataFrame({
"delta" : [delta],
"hoeffding" : [sum(result_df.p > result_df.hoef_ub) / len(result_df)],
"bernstein" : [sum(result_df.p > result_df.bern_ub) / len(result_df)],
"emp_bernstein" : [sum(result_df.p > result_df.emp_bern_ub) / len(result_df)],
"beta" : [sum(result_df.p > result_df.beta_ub) / len(result_df)]
})
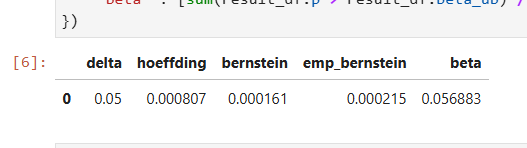
プロットではベータ分布の上側$\delta$点を使った式が一番いい感じ(?)に見えますが, この方法は「確率 $1-\delta$ 以上で $p$ の上界になる数字」を得ることを厳密には満たせていなさそうです. 少なくとも今回は Beta 分布を使って出した $p$ の上界であるハズの値が真値 $p$ より小さい事例が $\delta$ %よりちょっとだけ多くあります.
おわりに
集中不等式(特に Empirical Bernstein's ineq.)を使って $i=1,\dots ,N$ で $Z_i=0$ という情報だけからベルヌーイ分布の真値 $p$ の上界を求めてみました. 実用上は Beta 分布の上側 $\delta$ %点で十分そうです. しかし厳密性に欠けるのと, (あまりちゃんと考えていないですが, おそらく) $N$ に関する明示的なオーダーが分からないので, 何らかの定理の証明や収束オーダーの評価...といった目的だと不等式の出番になりそうです. また, Bernstein の不等式で今回上手く評価できなかった分散 $\mathbb{V}[Z]$ について, 何かうまいこと抑える方法はないものか(分散を期待値で書いて Hoeffding するのか, あるいは直接的に分散を評価する版の集中不等式みたいなものってあるのか)は気になるところです.
参考文献
[1]Andreas Maurer, Massimiliano Pontil. Empirical Bernstein Bounds and Sample Variance Penalization, Proceedings of the 22nd Annual Conference on Learning Theory, 2009.
[2]金森敬文. 統計的学習理論. 講談社 機械学習プロフェッショナルシリーズ.
[3]Peter Auer, Nicolo Cesa-Bianchi and Paul Fischer. Finite-time Analysis of the Multiarmed Bandit Problem, Machine Learning, 2002.
[4]鈴木大慈. 統計的学習理論チュートリアル: 基礎から応用まで, IBIS 2012.
[5]本多淳也. 多腕バンディット問題の理論とアルゴリズム, IBIS 2014.
[6]https://dora119.hateblo.jp/entry/2022/06/13/151813
[7]Shipra Agrawal, Navin Goyal. Analysis of Thompson Sampling for the Multi-armed Bandit Problem, Proceedings of the 25th Annual Conference on Learning Theory, 2012.