最近触り始めたので調べたことをまとめてみる・・・!(長くなった!)
DynamoDBとは
- ・AWSの提供する完全マネージドNoSQL DBサービス
- →KVS的に使うもよし
- →インデックスを張って軽いクエリも可能
- →最近ではJSONドキュメントもサポートされ、ドキュメントストアとしても使えるとのこと
- ※まだ自分で試してないのでなんともですが、JSONドキュメントの中を検索とかできるのかな…
- ・ストレージ無限
- ・パフォーマンスも無限
- →ただしある一定以上に設定する場合はAmazon側に上限緩和申請が必要
- →とはいえ項目サイズを1KBとした場合、10000req/sec以上までは申請不要なので通常は十分
- ・ユーザが気にするのはスループット値の設定のみ
- →ReadもWriteも設定値を増やすのは1日何回でも可能だが、減らすのは1日4回までなので注意
- →ReadとWriteの設定値減を同時に1リクエストで行った場合は、1回とカウントされる
- ・トランザクションはサポートしていない
- →ただしトランザクションライブラリが提供されている
- ・テーブル定義はテーブル作成後は変更することができない
- →2015/01/29よりGSIに限り、あとから追加/削除ができるようになりました!
- ・料金はストレージサイズとスループット設定値とデータ転送(Out)にかかる
- →Inは無料、Outも同一リージョン内の他のAWSとの間であれば無料
- ・自動レプリケート、自動フェイルオーバー
- →同一リージョンの3つのAZでレプリケートされる
- ・読み込み一貫性は強一貫性と結果一貫性を選択できる
などなど。
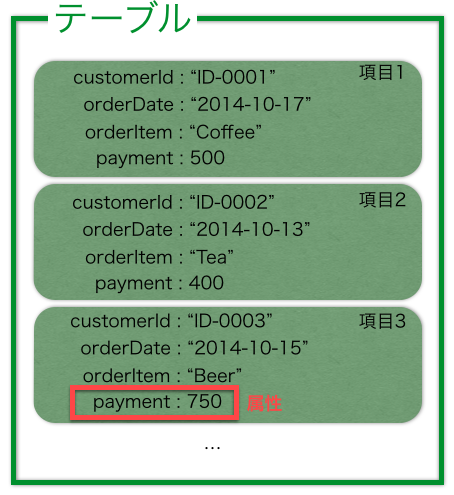
データモデル
ざっくりとイメージはこんな感じ。
テーブル
- ・テーブルは項目の集合体
- →テーブルの集合体がデータベース
- ・1アカウント、1リージョンあたり256まで定義可能
- →ただしAmazonにリクエストすることによって上限を外すことができる
項目
- ・項目は属性の集合体
- ・1つのテーブルに定義できる項目の数は無制限
- ・スキーマレスなので項目毎に違う属性を持つことができる
属性
- ・属性は"属性名"と"属性値"で構成される
- ・1つの項目に定義できる属性の数は無制限
- →ただし1項目中の全ての属性値と属性名の合計サイズ(※1)が400KBを超えることはできない
※1 :
属性のサイズは"属性名"と"属性値"をあわせたサイズ。
例えば属性名が"attribute"、属性値が"hogehoge"
の場合は属性名9byte+属性値8byteで計17byteとなる。
プライマリキー
プライマリキーのタイプは
- Hash keyのみでユニーク
- Hash key + Range keyの2つでユニーク
のいずれかのタイプが指定可能。
セカンダリインデックス
後述の2タイプのセカンダリインデックスを設定することで、簡単なクエリができるようになる。
(Hash + RangeタイプであればそれだけでRangeで絞ることができるけど)
ローカルセカンダリインデックス(LSI)
こっちはプライマリキーのタイプが"Hash key + Range key"の場合のみ設定可能。
簡単にいうと、別のRange keyを増やすようなイメージ。
例えば以下のような注文履歴テーブルがあるとする。
このテーブルは顧客ID(Hash key)と注文日(Range key)がプライマリキー。
■注文履歴テーブル
| 顧客ID(Hash) | 注文日(Range) | 注文品 | 支払い |
|---|---|---|---|
| ID-0001 | 2014-10-13 | Coffee | 500 |
| ID-0001 | 2014-10-17 | Coffee | 500 |
| ID-0002 | 2014-10-10 | Tea | 400 |
| ID-0002 | 2014-10-13 | Coffee | 500 |
| ID-0002 | 2014-10-14 | Tea | 400 |
| ID-0003 | 2014-10-16 | Beer | 700 |
| ID-0003 | 2014-10-17 | Wine | 900 |
このテーブルでは
「顧客"ID-0002"さんの"2014-10-13"以降の注文履歴」は抽出できるが、
「顧客"ID-0002"さんの"Tea"を注文した日」は抽出できない。
そこでローカルセカンダリインデックスを作成し、属性"注文品"をRange keyに設定すると
以下のようなインデックスができる。
■LSI(ローカルセカンダリインデックス)テーブル
| 顧客ID(Hash) | 注文品(Range) | 注文日 | 支払い |
|---|---|---|---|
| ID-0001 | Coffee | 2014-10-13 | 500 |
| ID-0001 | Coffee | 2014-10-17 | 500 |
| ID-0002 | Tea | 2014-10-10 | 400 |
| ID-0002 | Coffee | 2014-10-13 | 500 |
| ID-0002 | Tea | 2014-10-14 | 400 |
| ID-0003 | Beer | 2014-10-16 | 700 |
| ID-0003 | Wine | 2014-10-17 | 900 |
これで「顧客"ID-0002"さんの"Tea"を注文した日」が抽出できる。
グローバルセカンダリインデックス(GSI)
こっちはプライマリキーのタイプによらずに設定可能。
ローカルセカンダリインデックスのHash keyがプライマリのHash key固定なのに対し、
こちらは別のHash key (+ Range key)を設定することができる。
※Range keyは必ずしも設定する必要はない
前述した「注文履歴テーブル」や「LSIテーブル」では
「全顧客データの中から"Coffee"が注文された日」
は抽出できない。
そこでグローバルセカンダリインデックスを作成し、属性"注文品"をHash keyに設定すると
以下のようなインデックスができる。
■GSI(グローバルセカンダリインデックス)テーブル
| 注文品(Hash) | 顧客ID | 注文日 | 支払い |
|---|---|---|---|
| Coffee | ID-0001 | 2014-10-13 | 500 |
| Coffee | ID-0001 | 2014-10-17 | 500 |
| Tea | ID-0002 | 2014-10-10 | 400 |
| Coffee | ID-0002 | 2014-10-13 | 500 |
| Tea | ID-0002 | 2014-10-14 | 400 |
| Beer | ID-0003 | 2014-10-16 | 700 |
| Wine | ID-0003 | 2014-10-17 | 900 |
これで「全顧客データの中から"Coffee"が注文された日」が抽出できる。
さらに"注文日"をRange keyに設定しておけば、
「全顧客データの中から2014-10-15以降で"Coffee"が注文された日」
といった抽出ができるようになる。
属性の射影
セカンダリインデックスを張るというのは、セカンダリインデックス用のテーブルを作るイメージに近い。
つまりそれだけストレージ容量を食うので、データサイズが大きい場合は注意する必要がある。
どのくらい追加でストレージが必要なのかは、セカンダリインデックスを作成する際に設定する
属性の射影設定に依存し、最大で2倍となる。
テーブルに定義された属性をインデックス側にも含めることを「射影」といって、
DynamoDBではテーブル作成時に射影設定を以下の3タイプから選択できる。
- ・All Attributes (全ての属性を射影)
- →テーブルにある全ての属性を射影する
- →これが一番容量を食うタイプで、追加で必要なストレージサイズは2倍となる。
- ・Table and Index Keys (キー属性のみを射影)
- →Hash keyやRange keyといったキー属性のみを射影する
- ・Specify Attributes (射影する属性を指定)
- →射影する属性を指定できるが、最大20個まで
- →つまり射影したい属性が21以上ある場合は"All Attributes"を選択する必要がある
射影しなかった属性データはインデックスでのクエリ結果に含まれないので、
クエリした際に欲しい属性は射影しておく必要がある。
もし射影してない属性データが欲しい場合は改めてテーブル側から取得する必要があり、
その分余計なユニットを消費してしまうので逆にコストが高くなることも。
その他
・DynamoDBの制限
項目の最大サイズが64KBまでになっていたり、最新情報がまだ反映されてないかも。。。
(2014/10/18現在)
・DynamoDBのベストプラクティス
とりあえずここまで。
次はAWS SDKを使用してのDynamoDBアクセスとか、料金について書こうかなあ〜・・・