概要
Stackdriverを使用してGCE(Google Compute Engine)へ基本的な監視設定を行う手順を説明していきます。
Stackdriverの公式ドキュメントがかなり難解なため、Stackdriverの前提知識が薄い方も理解できる内容で記載していきたいと思います。
なお、本記事はDebian系 or RHEL系のLinuxが稼働しているGCEを想定して記載しております。
今回は基本的な監視設定の解説となりますが、Stackdriverはより応用的な活用をすることでクラウドネイティブな監視ツールとしての威力を発揮します。
目次
- 1. Stackdriverとは
- 2. Stackdriverの監視方針
-
3. Stackdriverの起動方法
- 3-1. Stackdriver Monitoringの起動方法
- 3-2. Stackdriver Loggingの起動方法
-
4. Stackdriver Agentの利用
-
4-1. Stackdriver Monitoring Agent
- 4-1-1. インストール方法
- 4-1-2. Stackdriver Monitoring Agentの停止方法
-
4-2. Stackdriver Logging Agent
- 4-2-1. インストール方法(構造化ロギングオフ)
- 4-2-2. インストール方法(構造化ロギングオン)
- 4-2-3. Stackdriver Logging Agentの停止方法
-
4-1. Stackdriver Monitoring Agent
-
5. Stackdriver Monitoringのアラート設定
-
5-1. GCEのCPU使用率(user)監視
- 5-1-1. Conditionに設定するパラメータ
- 5-1-2. Conditionの各パラメータの説明
- 5-1-3. 通知先の設定
- 5−1−4. ポリシー本文の設定
- 5-1-5. ポリシー名の設定
- 5-1-6. 発報テスト
-
5-2. URLへのUptimeCheck
- 5-2-1. Uptime Checkに設定するパラメータ
- 5-2-2. Uptime Checkの各パラメータの説明
- 5-2-3. Conditionに設定するパラメータ
-
5-3. GCEのプロセス稼働数監視
- 5-3-1. Conditionに設定するパラメータ
- 5-3-2. Conditionの各パラメータの説明
- 5-3-3. 発報テスト
-
5-1. GCEのCPU使用率(user)監視
-
6. Stackdriver Loggingのアラート設定
-
6-1. ログベースの指標標の作成
- 6-1-1. ユーザー定義(ログベース)指標に設定するパラメータ
- 6-1-2. ユーザー定義(ログベース)指標に設定するパラメータの説明
- 6-1-3. 作成したユーザー定義(ログベース)指標のフィルターを編集
-
6-2. ユーザー定義(ログベース)指標をアラートとして設定
- 6-2-1. Conditionに設定するパラメータ
- 6-3. 発報テスト
-
6-1. ログベースの指標標の作成
- 7. アラートの無効化
1. Stackdriverとは
Googleが2014年に買収したクラウド監視サービス。
Googleによる買収前はAWSを主としてモニタリング監視サービスを提供していたが、
Googleのサポートにより、AWSのモニタリング監視を継続しつつ、GCPのモニタリング監視も可能となった。
2. Stackdriverの監視方針
Stackdriver Monitoringではインスタンスのリソース使用率監視やUptimeCheck(URLへの死活監視や、GCEへのポート死活監視)、GCE上のプロセス稼働数などで監視を実現します。
Stackdriver LoggingではGCP/OS/MWのログを監視し、特定の文言でフィルターをかけた指標とよばれるメトリックを作成します。そのメトリックをStackdriver Monitoringでアラート化し監視を実現します。
3. Stackdriverの起動方法
3-1. Stackdriver Monitoringの起動方法
GCPのコンソール画面へ移動し、メニューからモニタリングをクリックする。
Stackdriver Monitoringのコンソール画面が表示される。
3-2. Stackdriver Loggingの起動方法
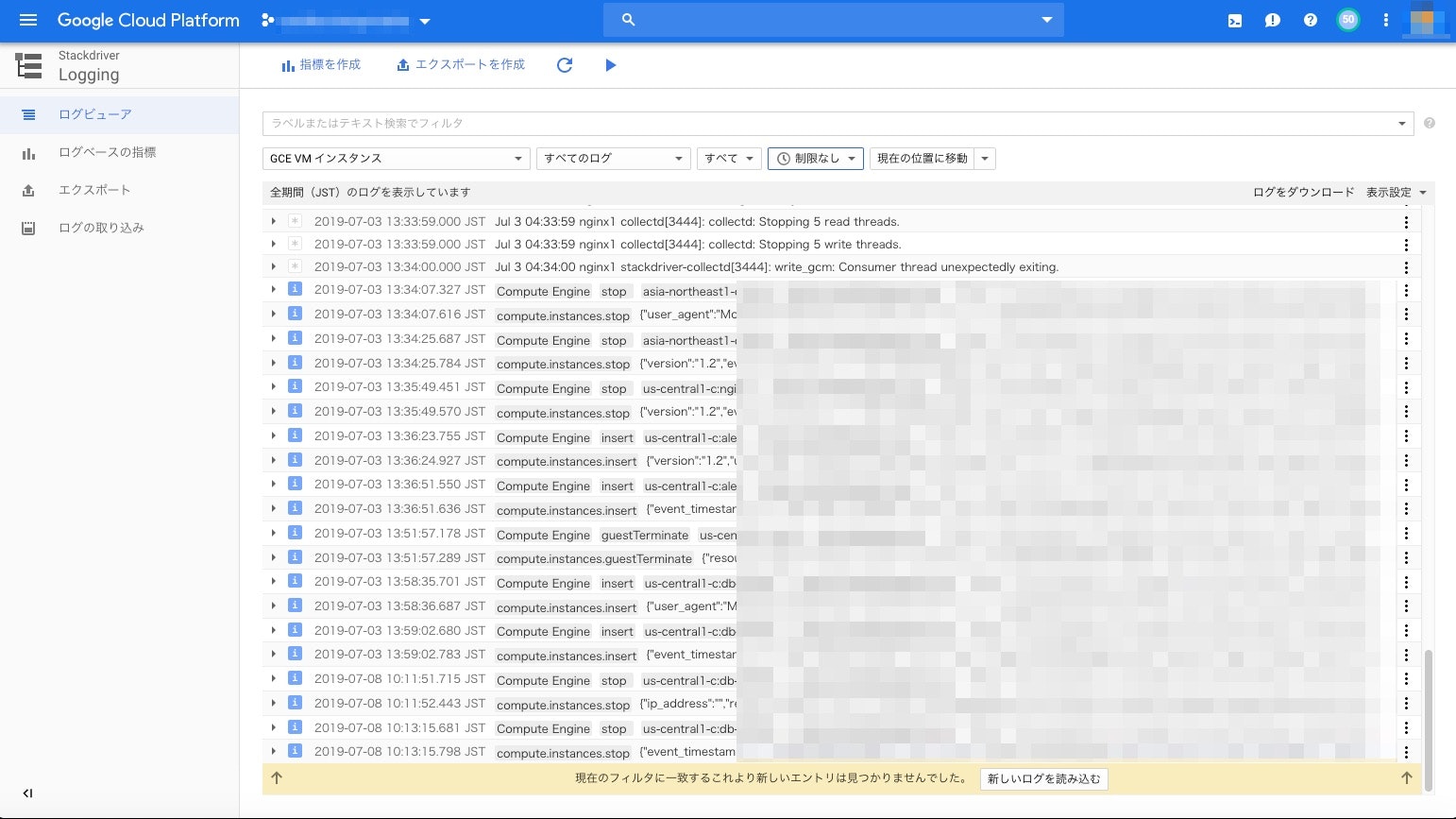
GCPのコンソール画面へ移動し、メニューからLogging⇛ログビューアをクリックする。
Stackdriver Loggingが収集したログのエントリが表示される。
4. Stackdriver Agentの利用
Stackdriver Agentにはそれぞれ、
Stackdriver Monitoring Agent
Stackdriver Logging Agent
がある。Agentをインストールすることによって詳細な監視設定(メトリックの指定)が可能となる。
4-1. Stackdriver Monitoring Agent
collectd ベースのデーモン。プロセス名はstackdriver-collectd。
インストールすることにより、GCEのリソース使用率をより詳細に取得することができる。
さらにサードパーティ製アプリケーション(Apache web serverやnginx,memcachedやMySQLなど)のモニタリングが可能となる。
サードパーティ製アプリケーションのモニタリングをするには、各アプリケーションのプラグインのインストールが必要となる。
https://cloud.google.com/monitoring/agent/plugins/?hl=ja
4-1-1. インストール方法
curl -sSO https://dl.google.com/cloudagents/install-monitoring-agent.sh
sudo bash install-monitoring-agent.sh
# 必要に応じて
sudo rm install-monitoring-agent.sh
4-1-2. Stackdriver Monitoring Agentの停止方法
# プロセスを停止
systemctl stop stackdriver-agent
# 自動起動を無効化
/sbin/chkconfig stackdriver-agent off
4-2. Stackdriver Logging Agent
fluentd ベースのデーモン。プロセス名はgoogle-fluentd。
インストールすることにより、syslogや各種MWログ(apache,nginx,jenkins,mongodb,solrなど)を収集可能となる。
デフォルトで対象となるミドルウェアの場合、ログの出力場所を変更していなければ自動でログが取得される。
またStackdriver Loggingには構造化ロギングと呼ばれるものが存在し、
通常はログの出力はtextPayloadで行われますが、構造化ロギングを有効にするとjsonPayloadでログが格納されます。
どのような利点があるかというと、例えばBigqueryのテーブルへログを格納する際にカラムがより詳細に作成されるため、SQL文によるログの操作がより柔軟になります。
4-2-1. インストール方法(構造化ロギングオフ)
curl -sSO https://dl.google.com/cloudagents/install-logging-agent.sh
sudo bash install-logging-agent.sh
# 必要に応じて
sudo rm install-logging-agent.sh
4-2-2. インストール方法(構造化ロギングオン)
curl -sSO "https://dl.google.com/cloudagents/install-logging-agent.sh"
sudo bash install-logging-agent.sh --structured
# 必要に応じて
sudo rm install-logging-agent.sh
4-2-3. Stackdriver Loggig Agentの停止方法
# プロセスを停止
systemctl stop google-fluentd
# 自動起動を無効化
/sbin/chkconfig google-fluentd off
5. Stackdriver Monitoringのアラート設定
今回は以下のアラートを設定していきます。
GCEのCPU使用率(user)監視
URLへのUptimeCheck
GCEのプロセス稼働数監視
5-1. GCEのCPU使用率(user)監視
Stackdriver Monitoringコンソールの左メニューからalertingを選択しさらにCreate a Policyをクリックします。
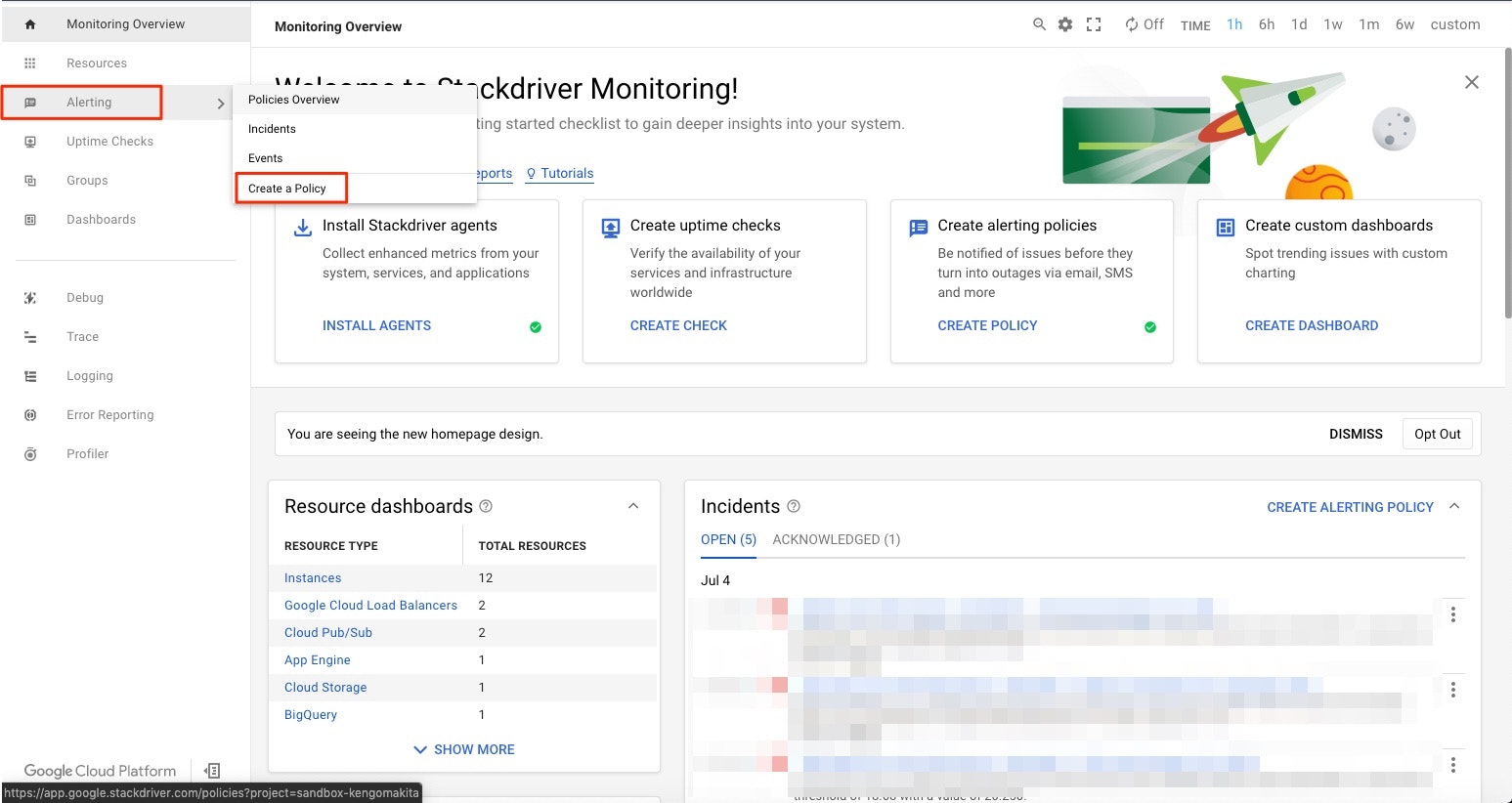
ポリシー作成画面へと遷移します。
各項目の対応は画像内の赤字の通りです。
Stackdriver Monitoringのアラート設定単位はPolicyです。Policyは各ワークスペースに最大で 500 個作成できます。
Policyの中に複数のConditions(条件/アラート)を設定します。
1つのPolicy内にConditionsは最大で6個登録できます。
Policyがインシデントと判断される条件の指定は以下となります。
OR:
=> いずれかの条件が満たされている。
AND:
=> 各条件が 1 つ以上のリソースによって違反されている。異なるリソースが各条件にそれぞれ違反している場合も含む。
AND_WITH_RESOURCES:
=> すべての条件が同じリソースによって違反されている(このオプションは、Monitoring API を使用して作成する条件でのみ使用できます)。もちろん1つのPolicy内に1つのConditionsのみ設定することも可能です。
ではAdd Conditionsをクリックし、実際にアラートを設定して行きましょう。
Add ConditionsをクリックするとCondtionの作成画面へと遷移します。
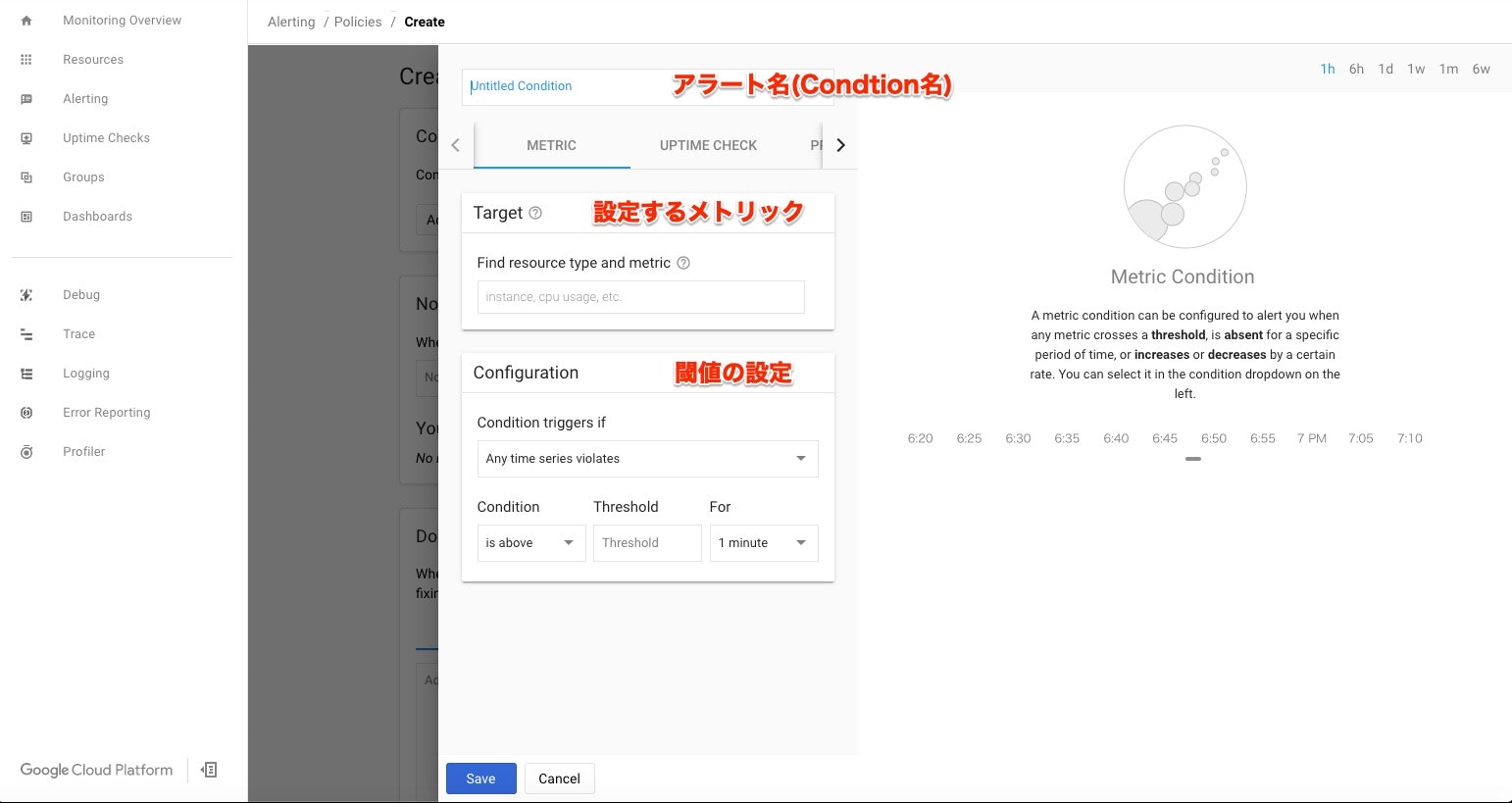
各項目の対応は画像内の赤字の通りです。
ここでは以下をパラメータとして設定します。
5-1-1. Conditionに設定するパラメータ
Conditon名:
GCE VM Instance - CPU utilization for user above 80%
■Target
Find resource type and metric: Resource type: GCE VM Instance Metric: CPU utilization ※CPU utilizationは2つあるので、Metricがagent.googleapis.com/cpu/utilizationのものを選択Filter:
cpu_state = "user"
Group By:
user_labels.name
Aggregator:
mean
Advanced Aggregation:
Aligner:
mean
Alignment Period:
1m
Secondary Aggregator:none
Legend Template:
■Configuration
Condition triggers if: Any time series violates Condition: is above Threshold:80(%) For:1minute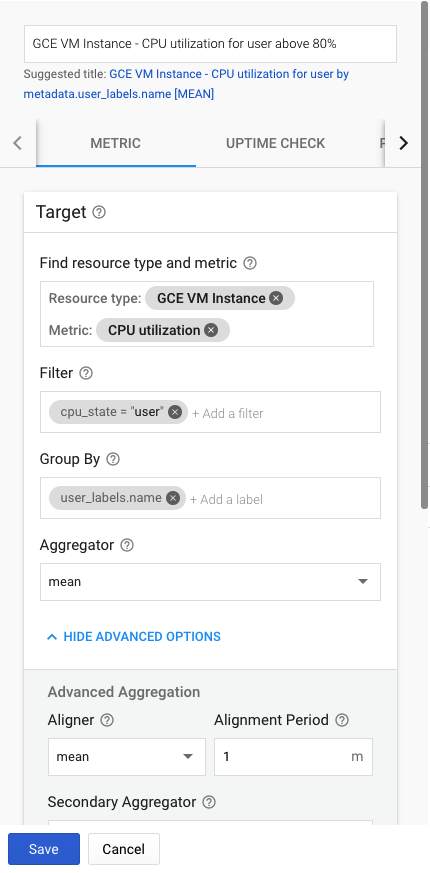
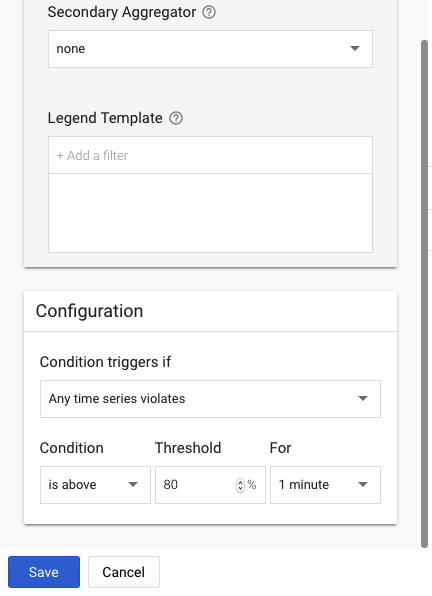
ここまで完了したらsaveをクリックし保存する。
5-1-2. Conditionの各パラメータの説明
■Target
Find resource type and metric: Resource type: Metricの大まかな分類(GCE_VM InstanceやBigquery Datasetといった粒度) Metric:実際にアラート設定する項目(CPU utilizationなど)Filter:
Metricを適用させる対象、何も設定しないと全インスタンスが対象となる。
GCEの場合はネットワークタグやインスタンス名単位でフィルターが可能
Filterは複数設定することが可能で複数設定した場合はAND条件となる。
Group By:
SQL文のgroupby句と考え方は一緒。
プロジェクトIDやゾーン、インスタンス名などを指定可能。
Aggregator:
値の集計方法。minやmaxなどはそのままの通り。
通常の監視ツールの概念と全く違うものは**th percentileのもの。
これは値が100個あるとして、小さい順に並べ替える。
99thの場合は下から99番目に小さいの値を採用するというパラメータ。
50thの場合は50番目に小さい値を採用する。
**th percentileの使い分けとしては
99thの場合、外れ値を除外しつつ集計した中で最大の値を取得したい場合に有効となる。
95thの場合、外れ値が多数ある場合に有効。
50thの場合、大体の平均を取得したい場合に有効。
5thも存在するが、個人的な主観として殆ど使用しないと思われる。
ここの値の指定はユーザーが入力できるようになると柔軟性も高まる。今後のアップデートに期待。
Advanced Aggregation
Aligner: AlignerはAggregatorで取得した値を、指定した時間と指定した集計方法で再集計するパラメータ。 Alignerの詳細は[こちらの記事](https://qiita.com/taisho6339/items/e491216d549e84dd7322#align)で詳しく説明されております。公式ドキュメント
Alignment Period:
値を収集する時間間隔(ポーリング間隔)。分単位で指定。
Secondary Aggregator:
複数の時系列で集計が表されている場合に時系列をさらに集計する。
Legend Template:=> グラフの時系列の説明をカスタマイズ
■Configuration
Condition triggers if: メトリクスの名前, メトリクスのラベルそれぞれの値, Monitored Resourceの3つでグルーピングした一意の値でアラートのトリガーとなる条件を指定Any time series violates
=> (一つでも)測定値が閾値を超えた場合に
Percent of time series violates
=> 測定値が指定の閾値(%)を超えたら
Number of time series violates
=> 測定値が指定の閾値の回数を超えたら
All time series violate
=> (全ての)測定値が指定の閾値を超えたら
Condition:
Thresholdの値がどのように変動したらトリガーとなるのかを指定
CPU(user)の使用率が80%以上の場合はThresholdが80%でConditionはIs aboveを設定
Is above
=> 閾値を上回ったら
Is below
=> 閾値を下回ったら
Increases by
=> (前回取得した値から)閾値分増加したら
Decreases by
=> (前回取得した値から)閾値分減少したら
Is absent
=> 値が取得できない場合
Threshold:閾値として設定する値。
For:閾値としてThresholdの値が継続する時間。most recent valueの場合はThresholdの値となった瞬間にインシデントと判断されます。
1minuteの場合は、Thresholdの値が1分間継続した場合にインシデントと判断。
5-1-3. 通知先の設定
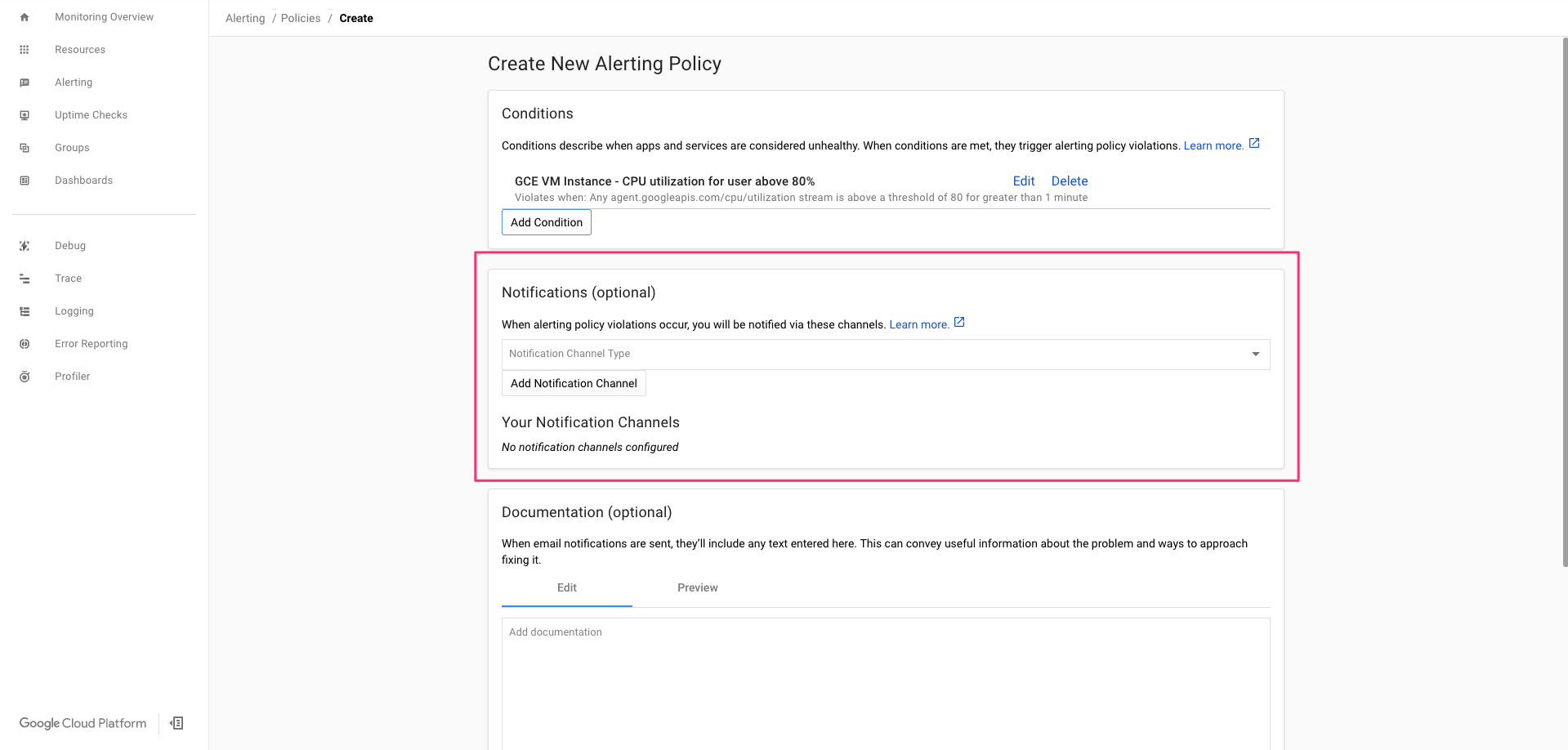
アラートの通知先にはEmail, Slack, Webhookなどを設定可能。
詳細な設定方法は公式ドキュメントを参照。
今回は通知先をEmailで設定していきます。
Notification Channel TypeをクリックしEmailを選択。
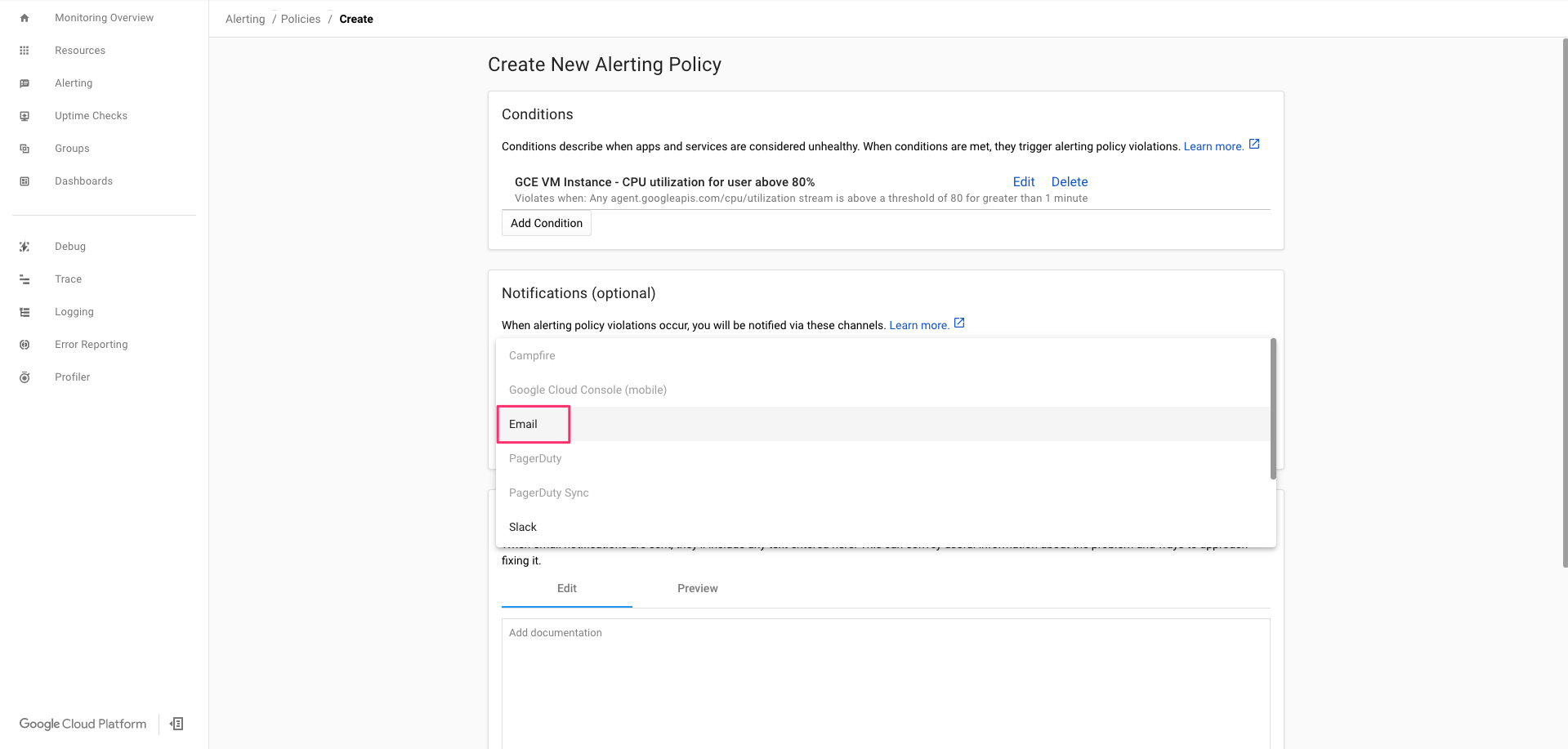
Emailアドレスの入力欄が表示されるので、通知先として設定したEmailアドレスを入力し、Add Norification Channelをクリックし反映させる。
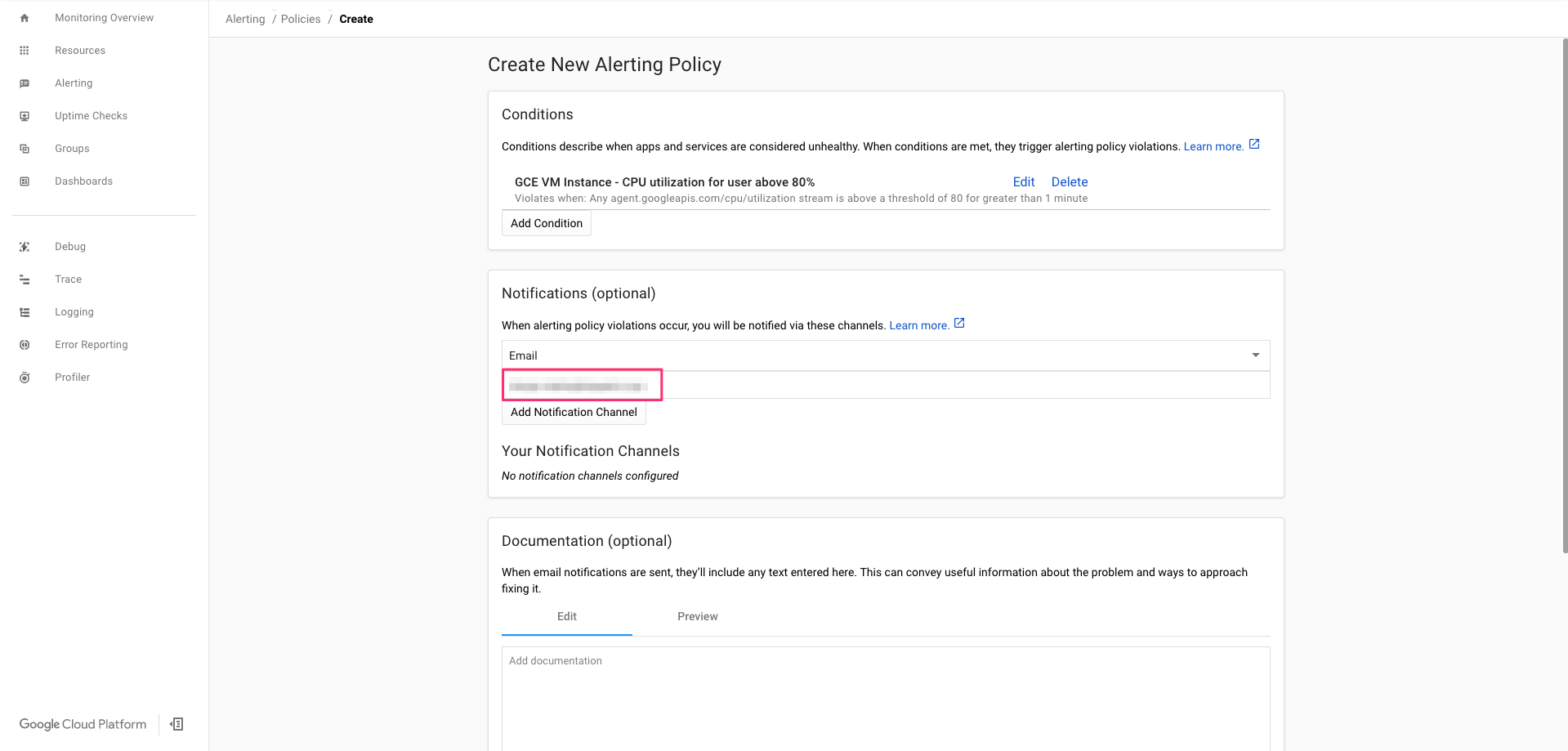
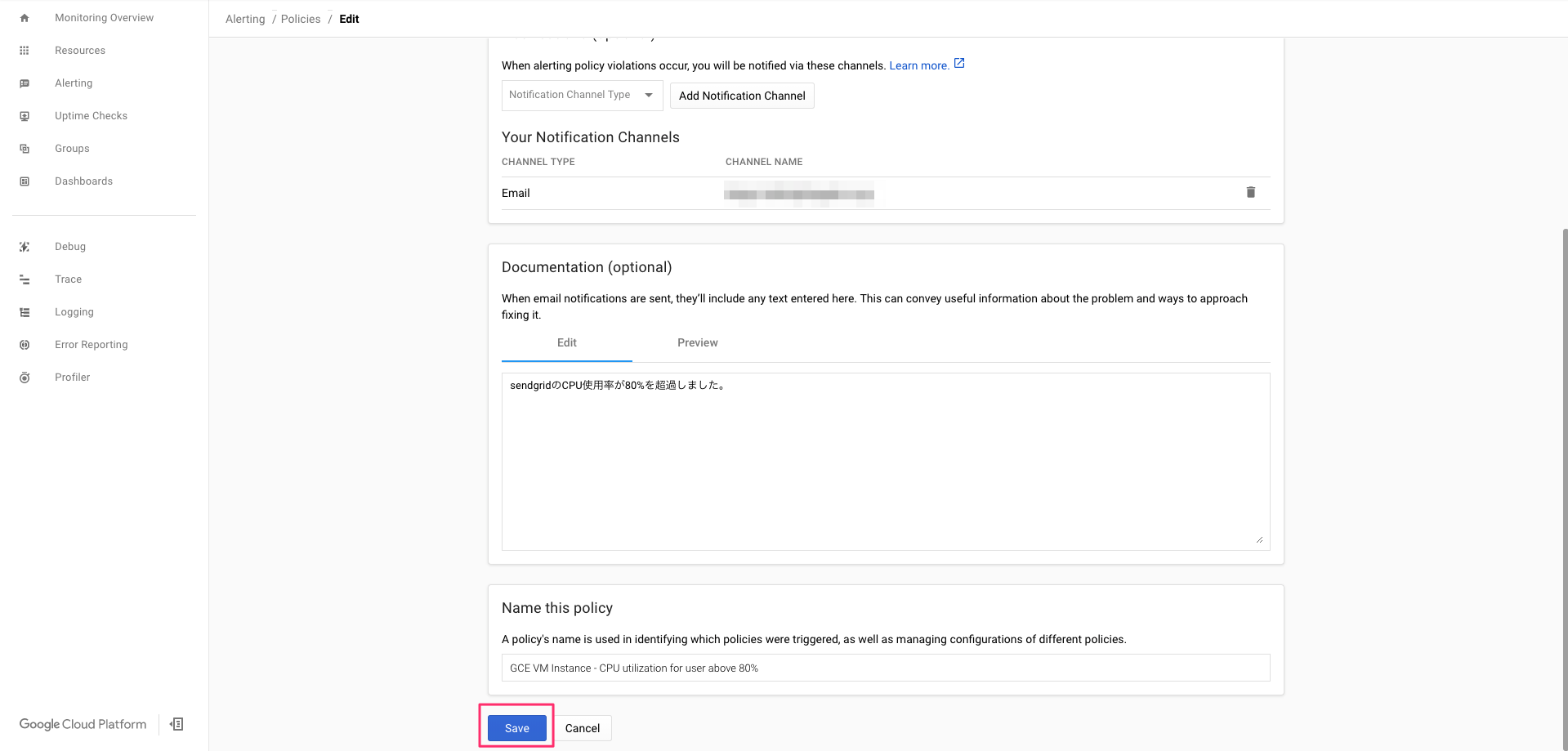
5−1−4. ポリシー本文の設定
アラートメール(メッセージ)内のPolicy documentationに任意の文言を設定可能。

基本的にどのサーバからどのような事象が発生したのか、が理解できる内容を記載。
ここには変数を設定することも可能で、${policy.name}といった形式で記載する。
どの変数が対応しているかは公式ドキュメントを参照。
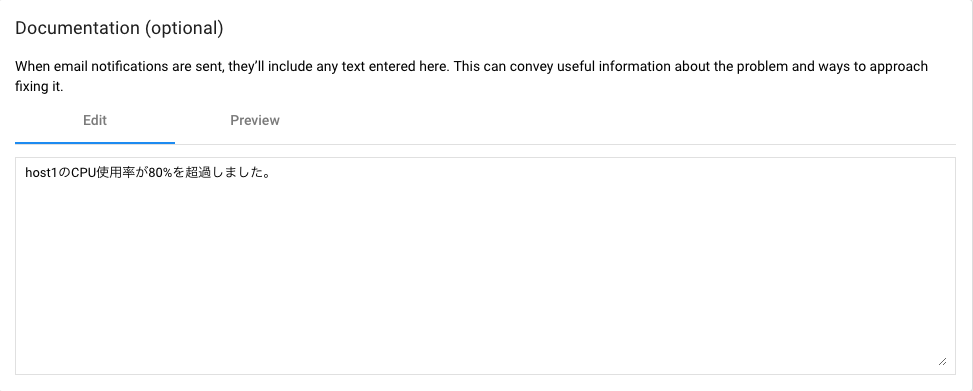
今回はhost1のCPU使用率が80%を超過しました。を設定する。
5-1-5. ポリシー名の設定
Policy名はアラート数など状況に応じて命名規則を定めるのがよいです。
今回はConditionと同じ名前とします。

ここまで設定したら、saveをクリックしPolicyを保存します。
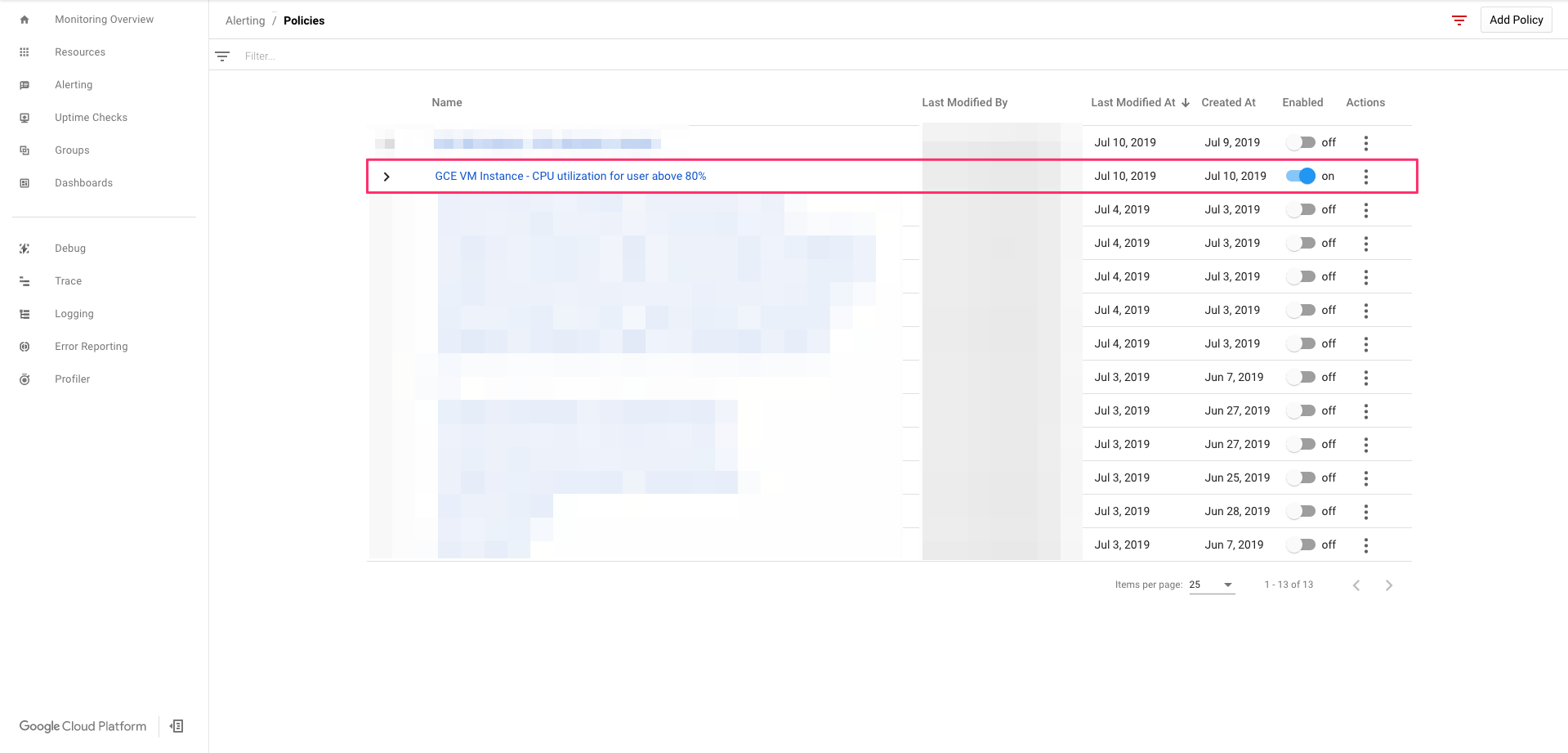
Policies一覧に追加されます。これで設定完了となります。
5-1-6. 発報テスト
実際にアラート対象となるGCEにsshログインし、CPU(user)負荷をあげてみましょう。
sudo yum install -y stress
stress -c 1 -q &
# 停止方法
jobs
fg #stressコマンドのjob番号
Ctrl + C キーを入力
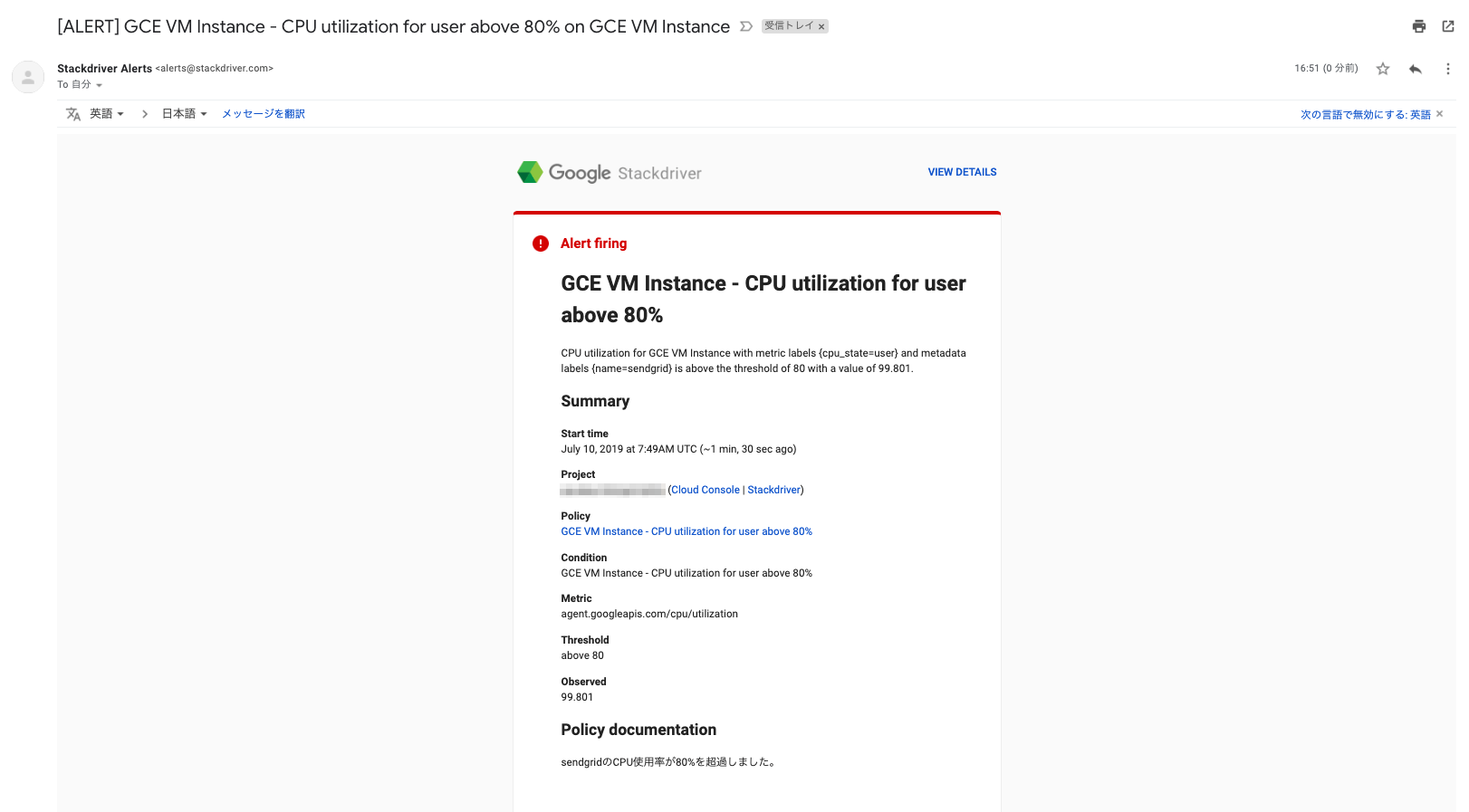
設定した内容でアラートとなっていることが確認できる。
5-2. URLへのUptimeCheck
ここではPolicy内の説明と発報テストは割愛し、URLへのUptimeCheckのConditionの説明を行います。
UptimeCheckは先にUptimeCheckの設定内容をMetric化し、そのMetricをCondition内で指定する流れとなります。
Uptime Checks => Uptime Checks Overviewをクリック。
遷移先の画面の右上、Add Uptime Checkをクリック。
Uptime Checkの作成画面が表示される。
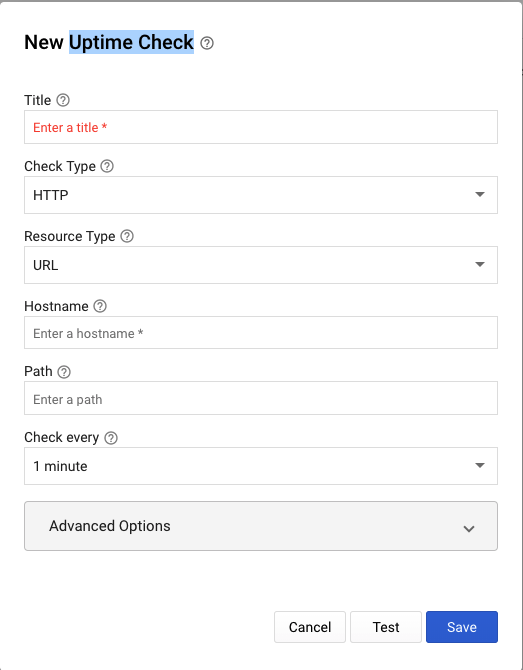
5-2-1. Uptime Checkに設定するパラメータ
※今回は弊社HPの https://www.topgate.co.jp/gcp/ に対してUptime Checkを行います。
Title:uptime check - www.topgate.co.jp
Check Type:HTTPS
Resource Type:URL
Hostname:www.topgate.co.jp
Path:/gcp
Check every:1 minute
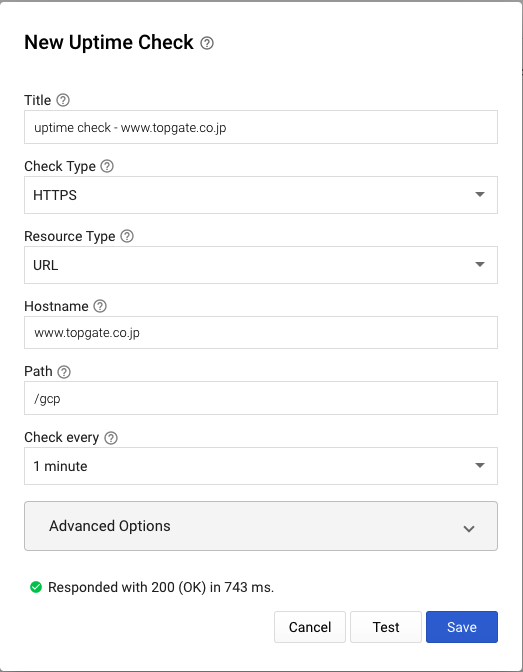
5-2-2. Uptime Checkの各パラメータの説明
公式ドキュメントに詳細な説明の記載があります。
5-2-3. Conditionに設定するパラメータ
UPTIME CHECKタブを選択
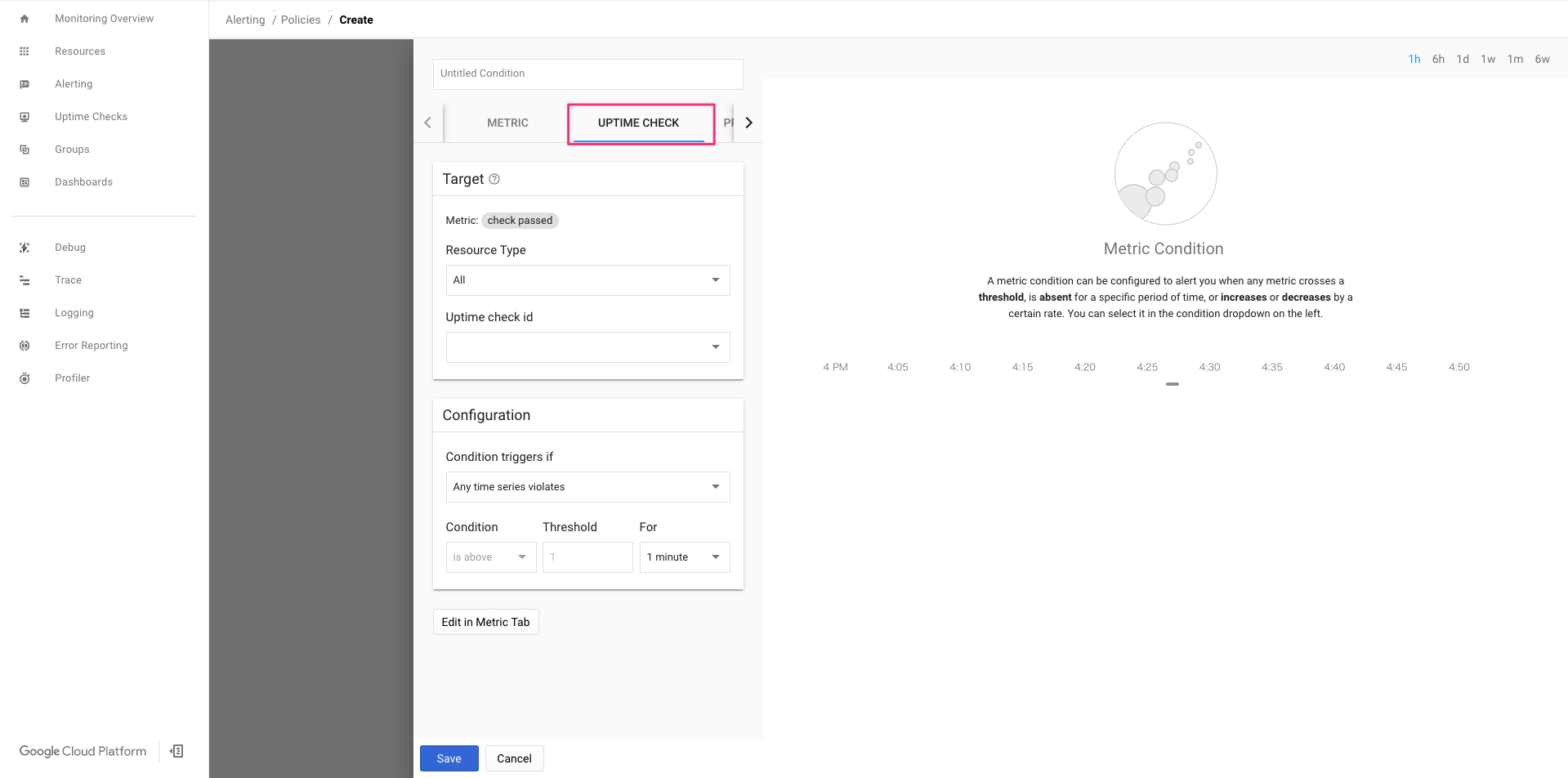
Condition名:uptime check - www.topgate.co.jp
■Target
Metric:check passed Resource Type:Uptime Monitoring Url Uptime check id:uptime check - www.topgate.co.jp■Configuration
Condition triggers if:Any time series violates For:1 minute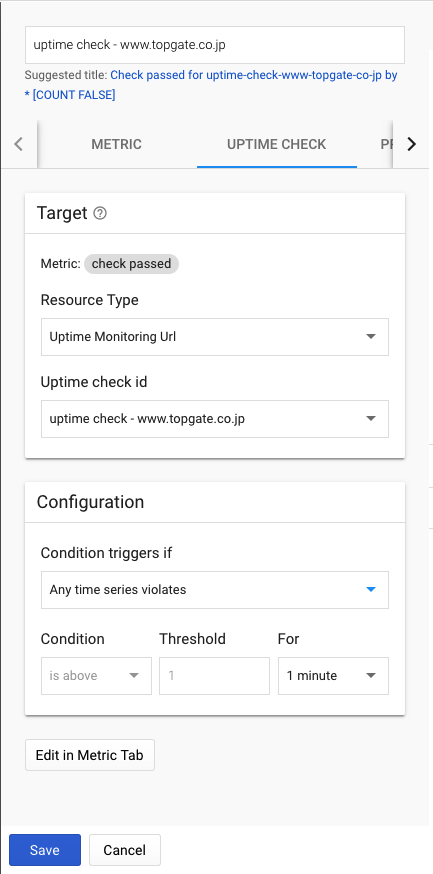
5-3. GCEのプロセス稼働数監視
ここではPolicy内の説明は割愛し、Process health内のConditionの説明と発報テストを行います。
PROCESS HEALTHを選択。
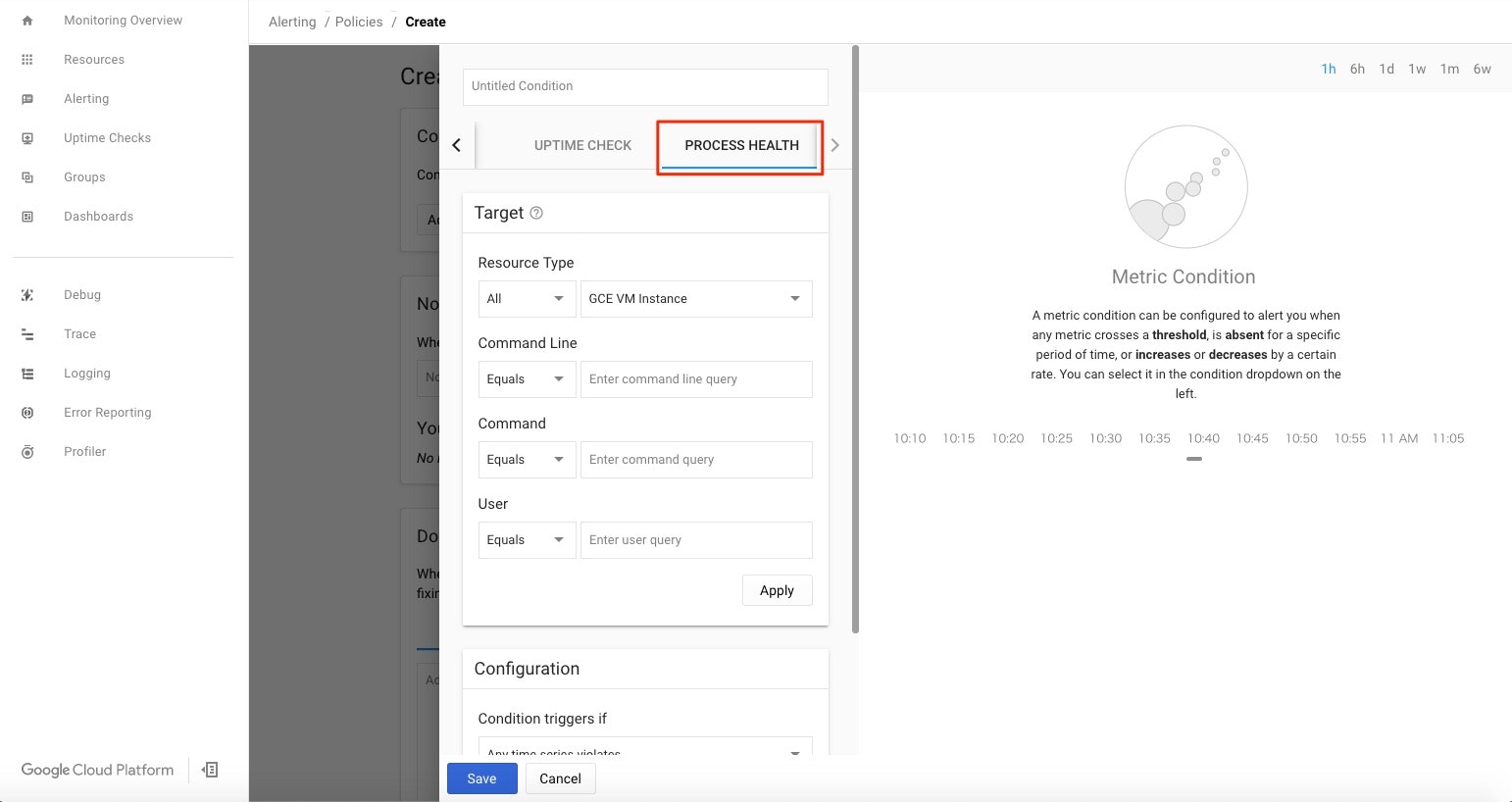
5-3-1. Conditionに設定するパラメータ
Condition名:GCE VM Instance - Process Health Nginx
■Target
Resource Type:Single:GCE VM Instance Instance:host1 Command Line:Contains:nginx Command: User:■Configuration
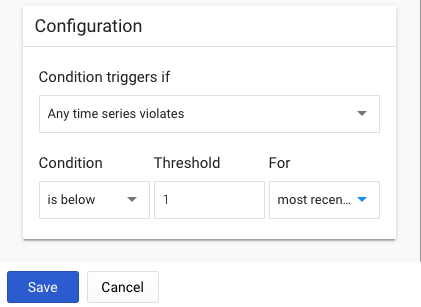
Condition triggers if:Any time series violates Condition:is below Threshold:1 For:most recent value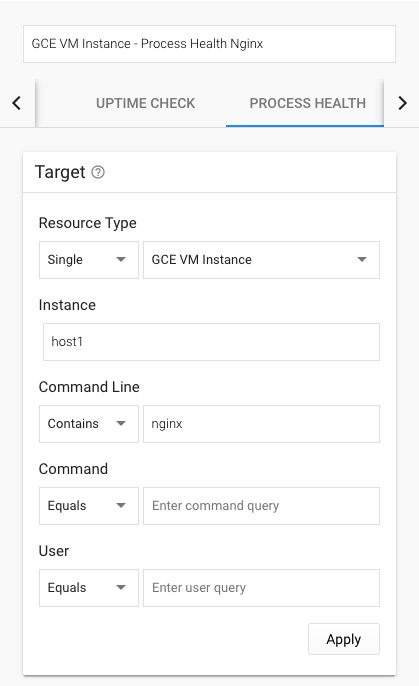
5-3-2. Conditionの各パラメータの説明
■Target
Resource Type:対象はインスタンスグループか、インスタンス単体か、すべてかを指定。またEC2かGCEかを指定する。Command Line:プロセス名。Command Line, Command, Userに共通する文字列照合条件のパラメータは以下の通り。
Equals: (指定した文字列)と一致する
Contains: (指定した文字列)を含む
Starts with: (指定した文字列)で始まる
Ends with: (指定した文字列)で終わる
Regex: (指定した文字列)の正規表現(*、?等)に一致する
Command:プロセス名。Command Lineと同じ動作をするが、Command Line, Commandのどちらも設定した場合それぞれの値が含まれる(AND)プロセスが対象となる。
User:プロセスの実行ユーザー
ここまで入力してApplyをクリックすると入力した設定値の現在のサーバ状況がグラフに表示される。
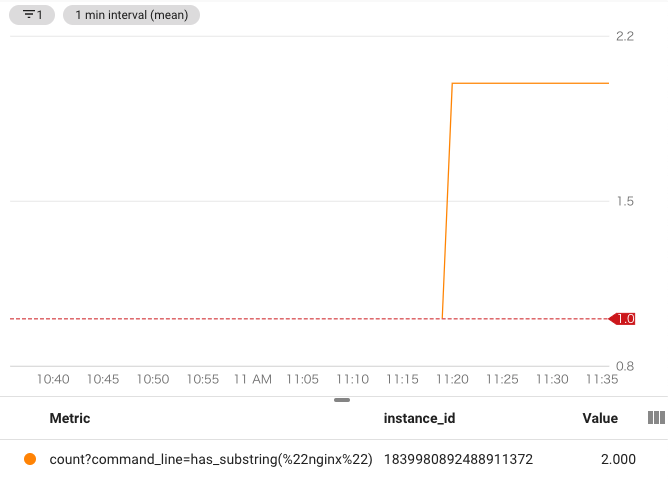
5-3-3. 発報テスト
Nginxサービスを停止させます。
# nginxが稼働していることを確認
sudo systemctl status nginx
# nginxサービスを停止
sudo systemctl stop nginx
# nginxが停止したことを確認
sudo systemctl status nginx
アラートメールが受信された。
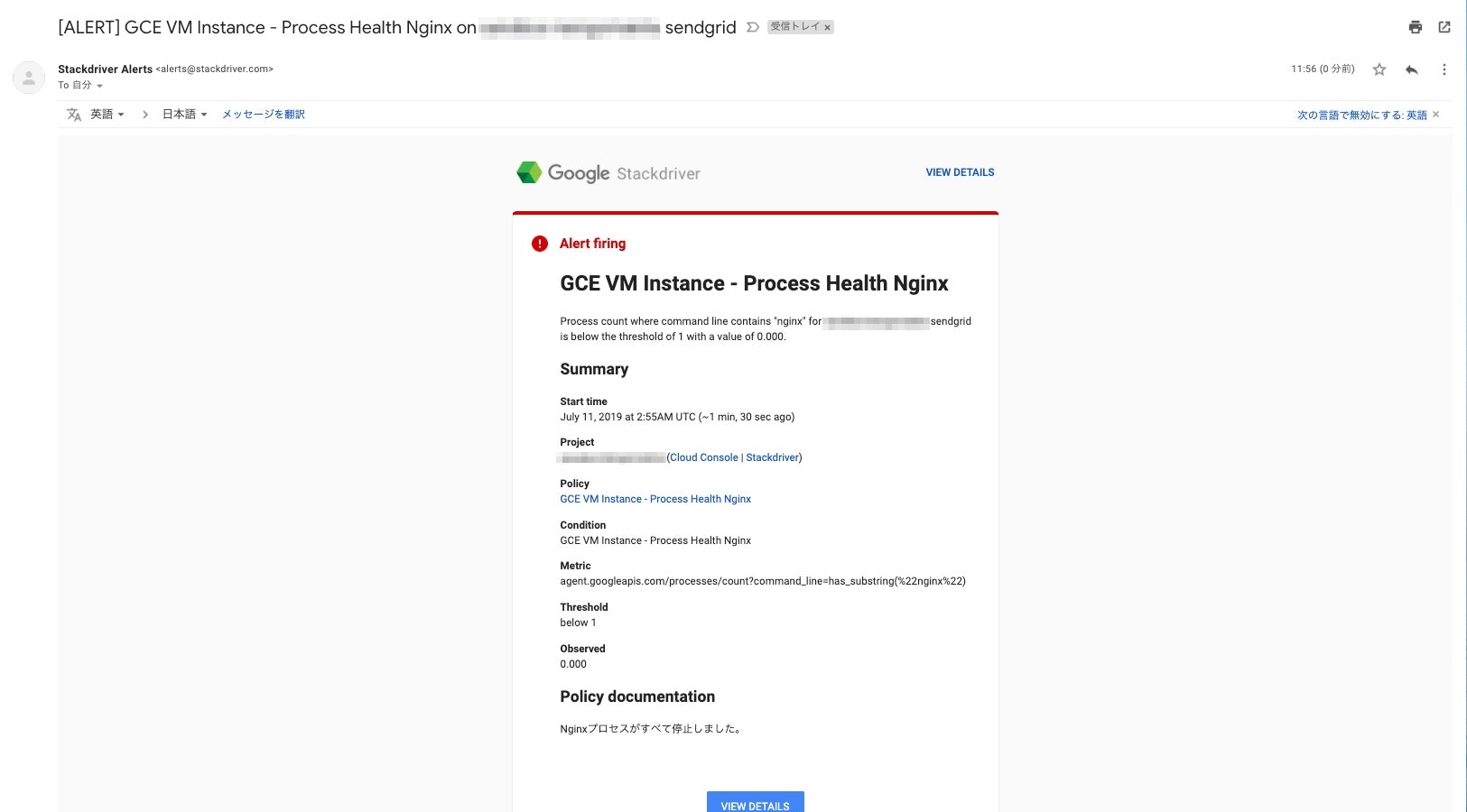
6. Stackdriver Loggingのアラート設定
Stackdriver Loggingでは、ログベースの指標という機能でGCPログや、Stackdriver Logging Agentが収集したOSログのログ内で、特定の文言でフィルターをかけて指標にすることが可能です。指標をMetricとしてStackdriver Monitoringでアラート化することができます。公式ドキュメント
ログベースの指標にはシステム(ログベース)指標とユーザー定義(ログベース)指標があり、
システム(ログベース)指標はStackdriver Logging によって事前定義されています。特定の期間内に発生したロギング イベントの数が記録されます。
ユーザー定義(ログベース)指標はユーザーによって作成され、特定のフィルタに一致するログエントリの数をカウントするか、一致するログエントリ内の特定の値を追跡します。
今回はユーザー定義(ログベース)指標で、CentOS7上でOOM KillerによってKillされたプロセスのログを指標として作成し、その指標をアラート化する設定を行います。
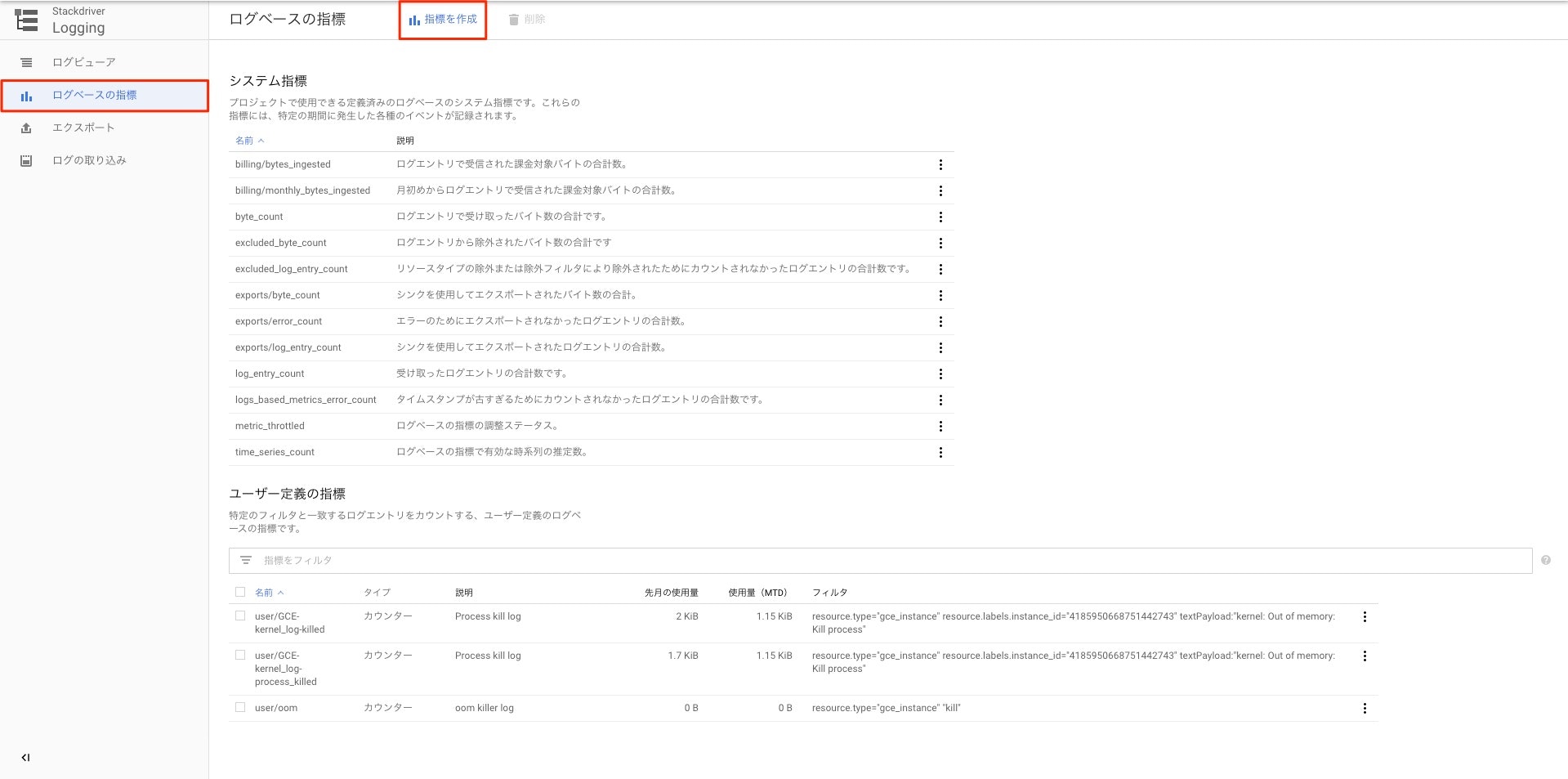
6-1. ログベースの指標の作成
Stackdriver Loggingコンソール画面でログベースの指標をクリックし、指標の作成をクリックする。
指標作成エディタが表示される。
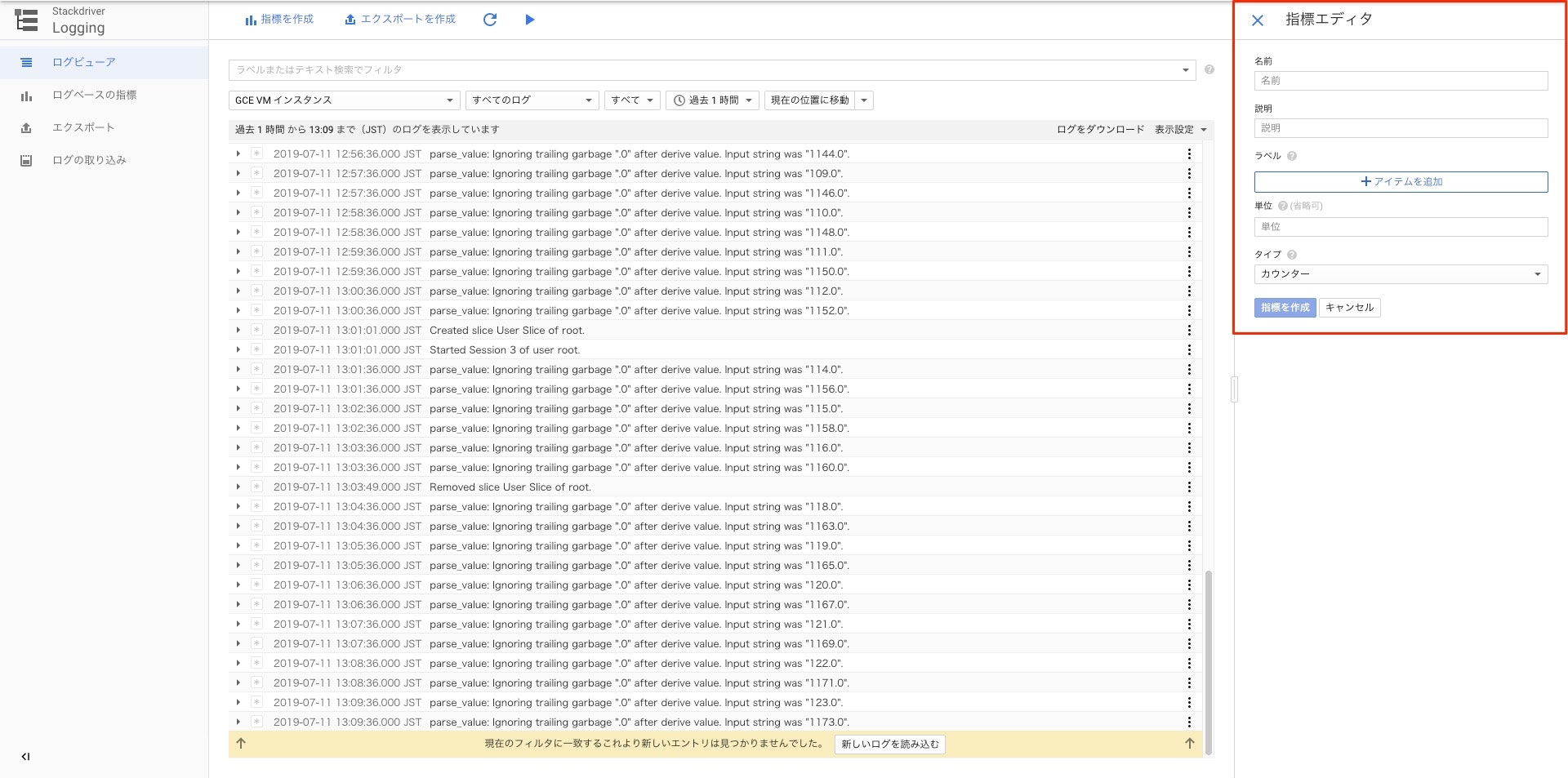
6-1-1. ユーザー定義(ログベース)指標に設定するパラメータ
Syslogに出力されたOOM KillerによるプロセスKillのログは、Stackdriver Loggingで以下の様に出力されます。
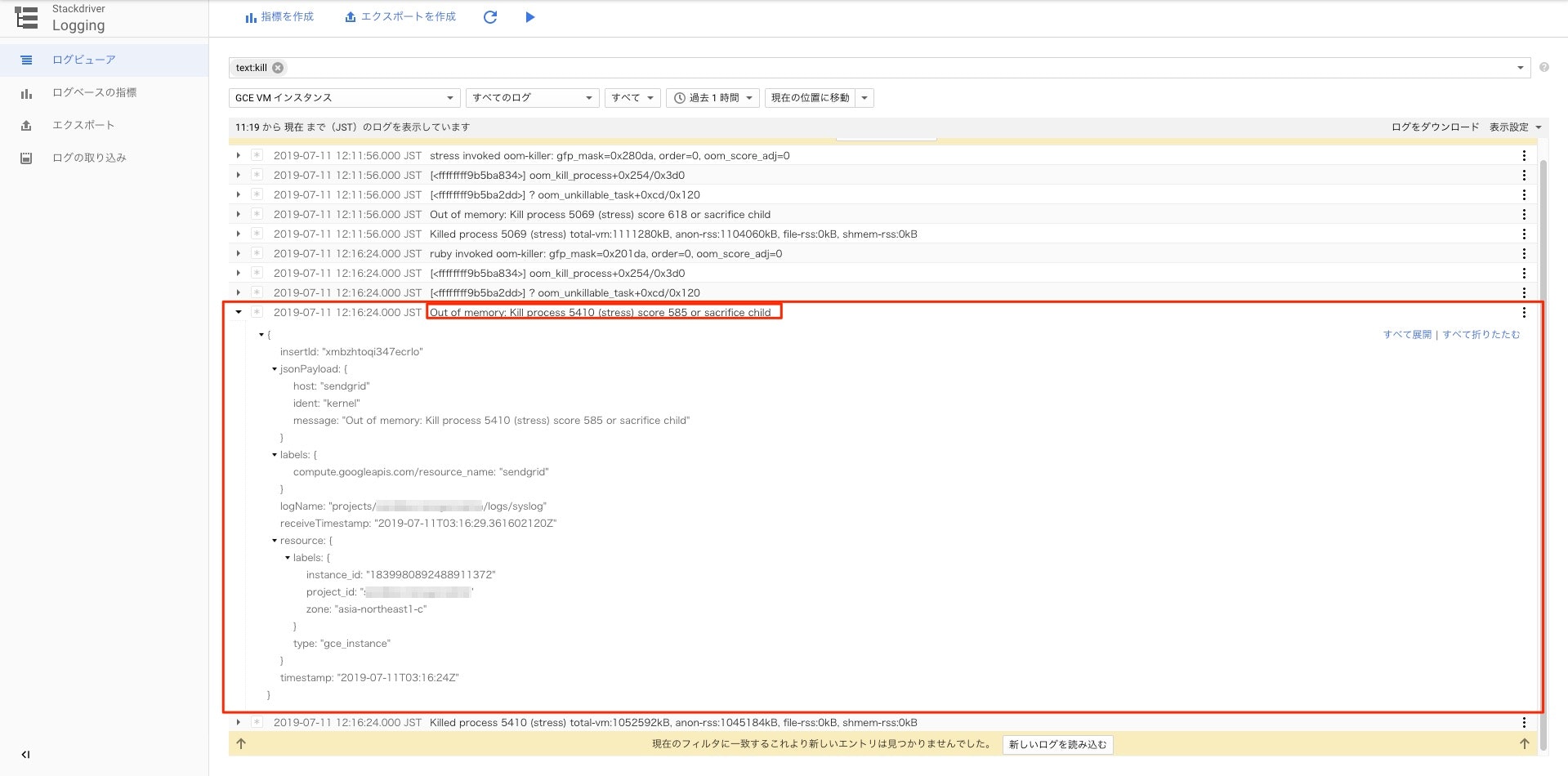
この Out of memory: Kill process を含むログを指標として作成しアラート化していきます。
名前:killed-prosess
説明:OOM Killer Kiled Prosess
ラベル:
単位:1
タイプ:カウンター
6-1-2. ユーザー定義(ログベース)指標に設定するパラメータの説明
名前:プロジェクトのログベースの指標で一意の名前を選択します。
説明:指標を説明します。
ラベル:(省略可)ラベルごとに [アイテムを追加] をクリックして、ラベルを追加します。
単位:カウンタ指標では、空白のままにするか、数字「1」を挿入します。
タイプ:カウンタ
6-2. 作成したユーザー定義(ログベース)指標のフィルターを作成
指標作成エディタ画面で、ログ検索欄の右端のプルダウンメニューをクリックし、高度なログフィルターに変換をクリックする。
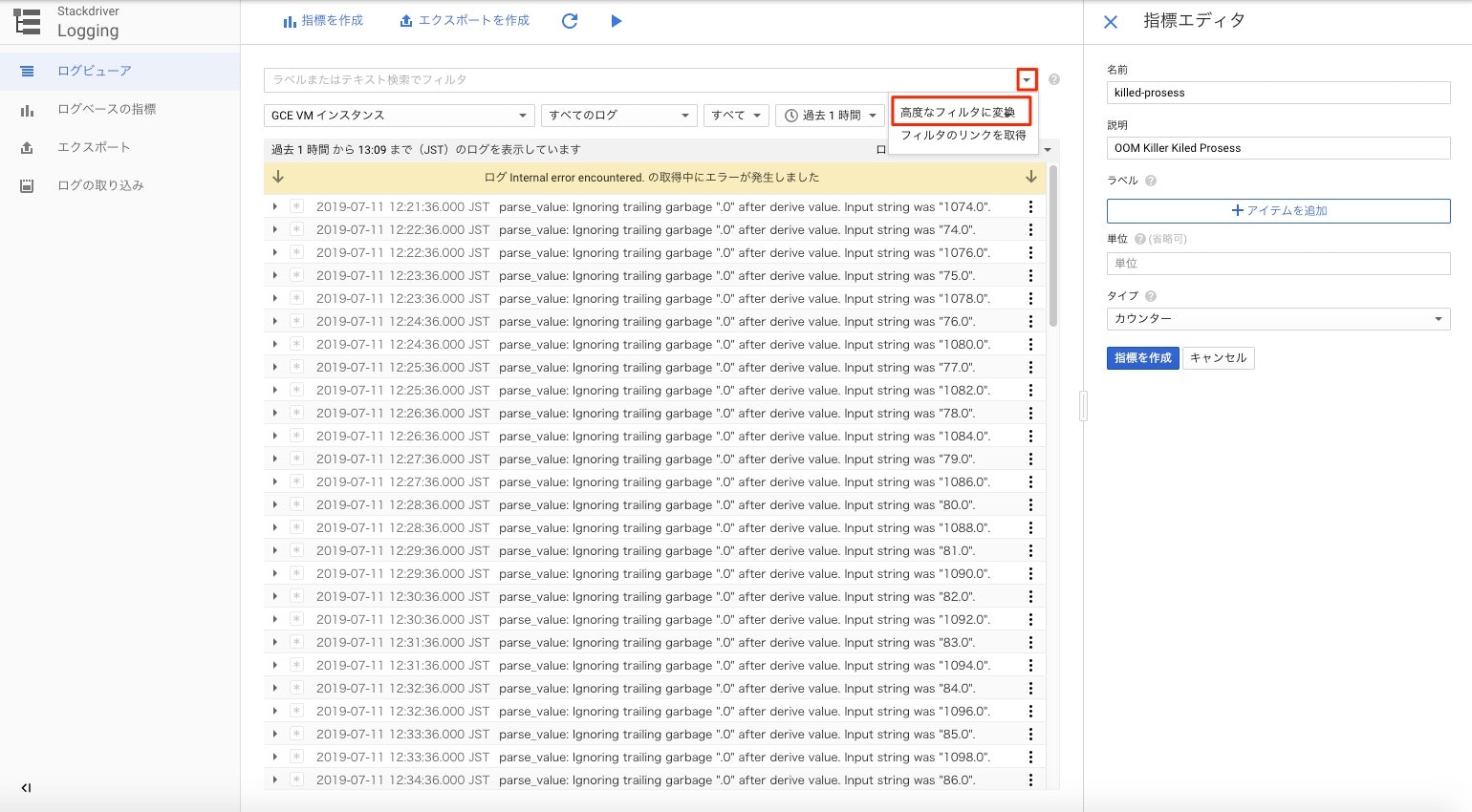
フィルター入力ボックスが表示されるので、フィルター条件を入力する。
6-2-1.フィルターに入力する条件。
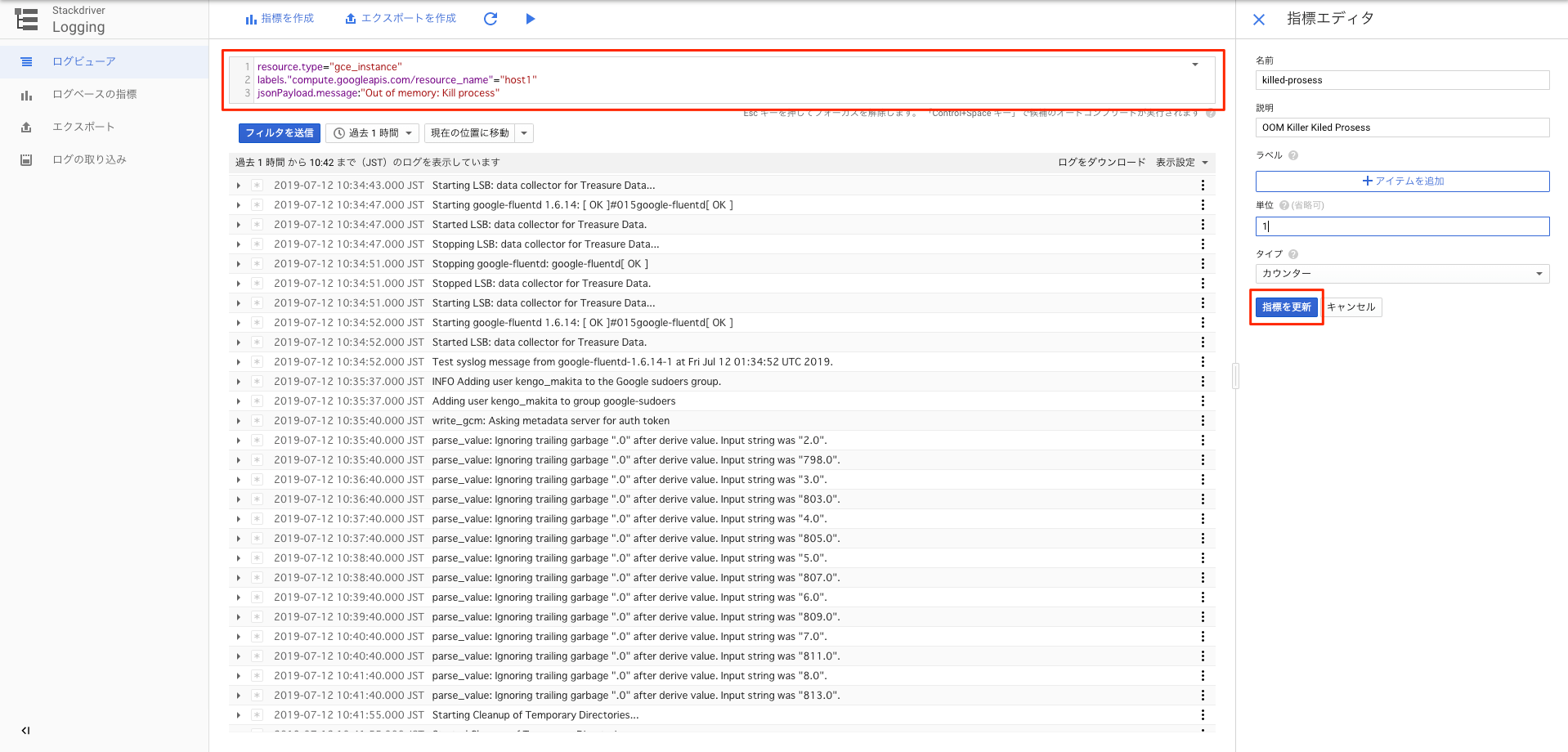
resource.type="gce_instance"
labels."compute.googleapis.com/resource_name"="host1"
jsonPayload.message:"Out of memory: Kill process"
※構造化ロギングをオフにしている場合は、jsonPayload.message:をtextPayload:にする。
ここで=(イコール)とすると全文一致となり、:(コロン)は部分一致となる。
指標を作成をクリック。
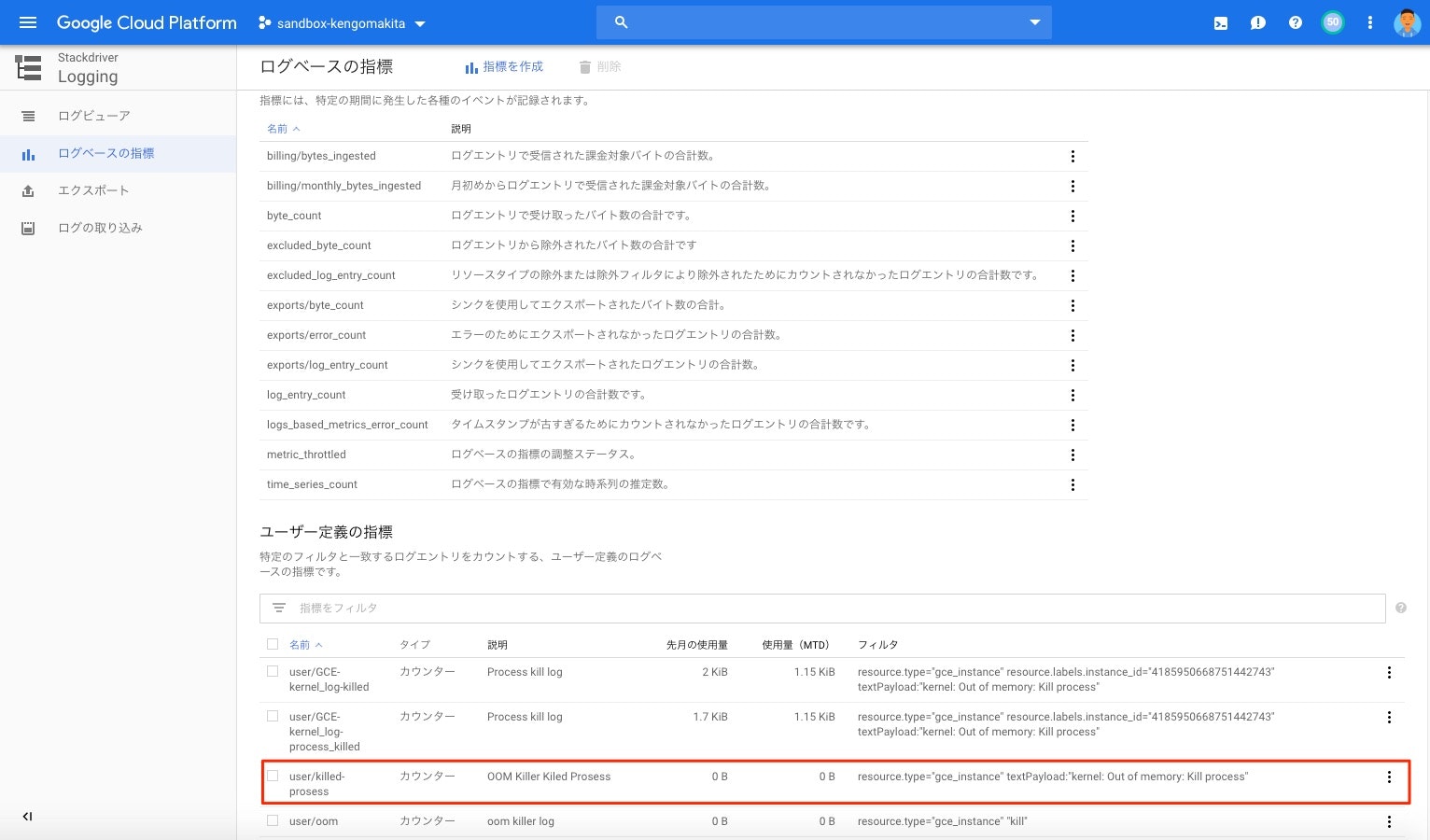
ユーザー定義の指標内の一覧に作成された指標が表示される。
6-2. 指標をアラートとして設定
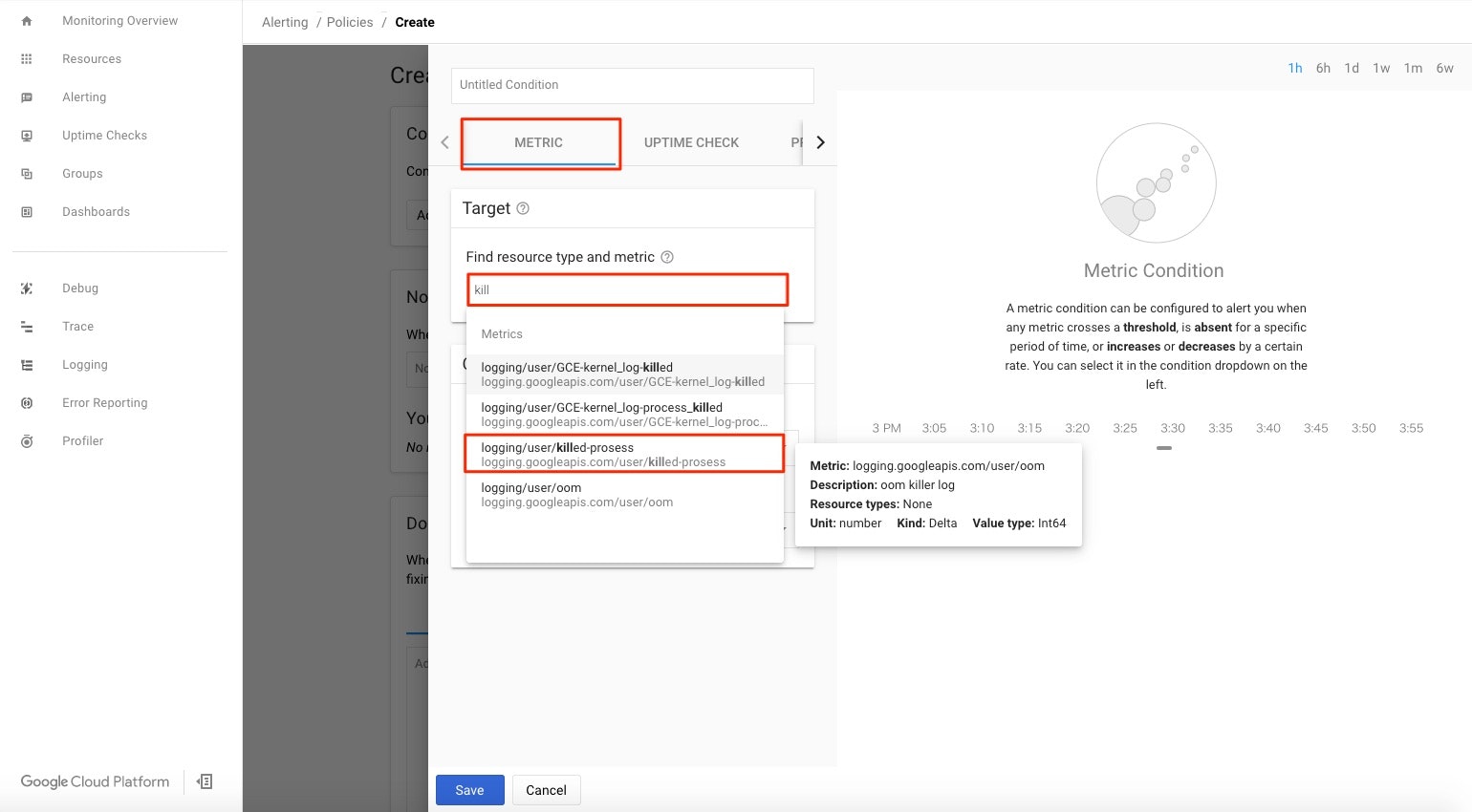
Stackdriver MonitoringのコンソールからPolicy作成画面を開く。
Metricが選択された状態で、Find resource type and metricの検索欄にkillと入力。先程作成した指標のが表示されるのでkilled-prosessをクリック。
6-2-1. Conditionに設定するパラメータ
Conditon名:GCE VM Instance - Killed-Prosess
■Target
Find resource type and metric: Resource type:logging/user/killed-prosess Metric:Filter:
Group By:
Aggregator:
Advanced Aggregation:
Aligner:delta
Alignment Period:1m
Secondary Aggregator:none
Legend Template:
■Configuration
Condition triggers if:Any time series violates Condition:is above Threshold:0 For:most recent value※Alignerをdeltaにすることで1分前に取得した状態からの差分を次に取得する値として集計する。
6-3. 発報テスト
では実際にメモリに負荷をかけて、OOM KillerによってプロセスをKillさせましょう。
free -b
# stress: FAIL:~got signal 9 のエラーメッセージが表示されるまで繰り返す
stress -m 1 --vm-bytes 上記コマンドのavailable列の値 --vm-hang 0 -q &
# 停止方法
jobs
fg #stressコマンドのjob番号
Ctrl + C キーを入力
アラートメールが受信された。
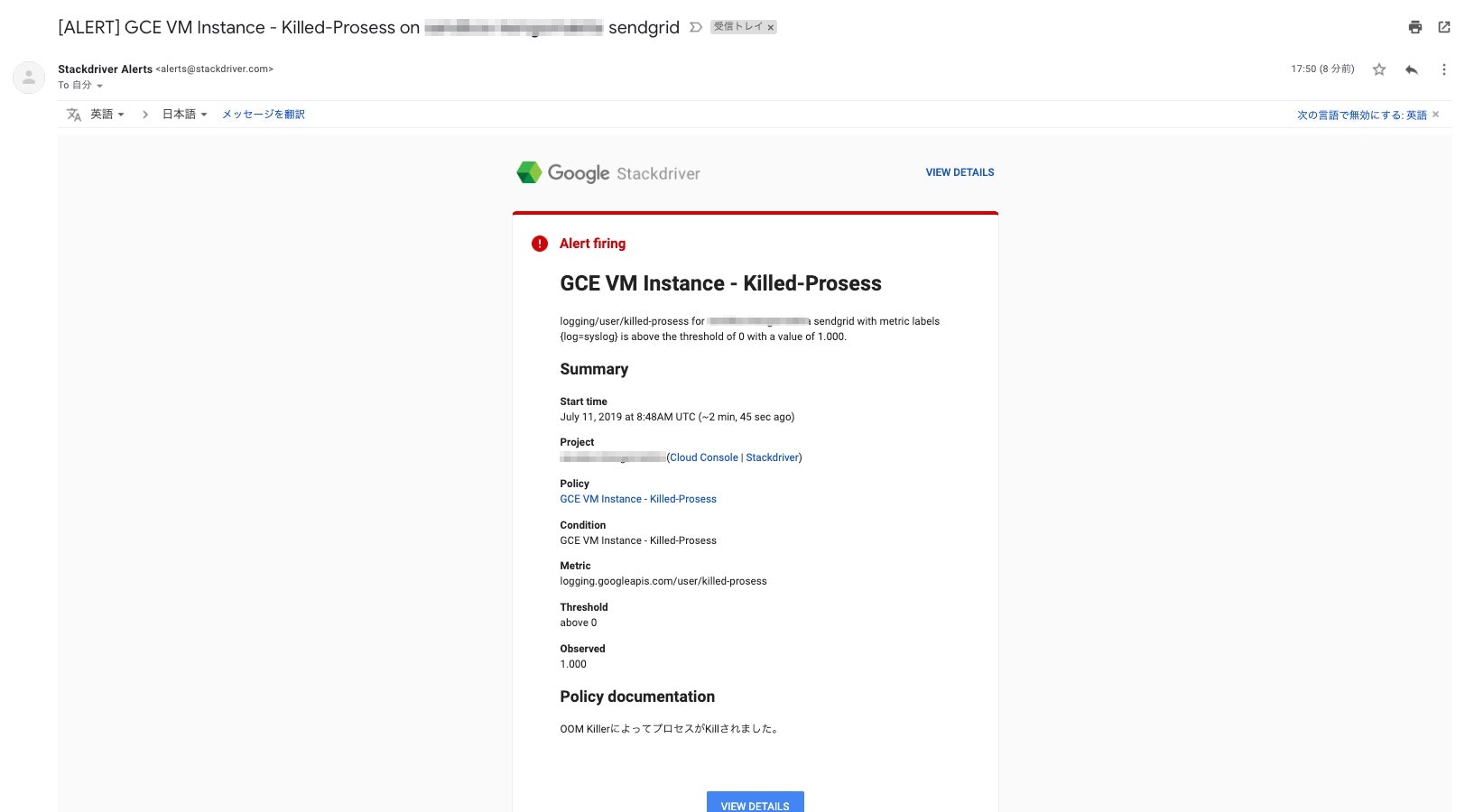
7. アラートの無効化
Stackdriver Monitoringコンソールの左メニューからAlerting => Policies Overviewを選択。
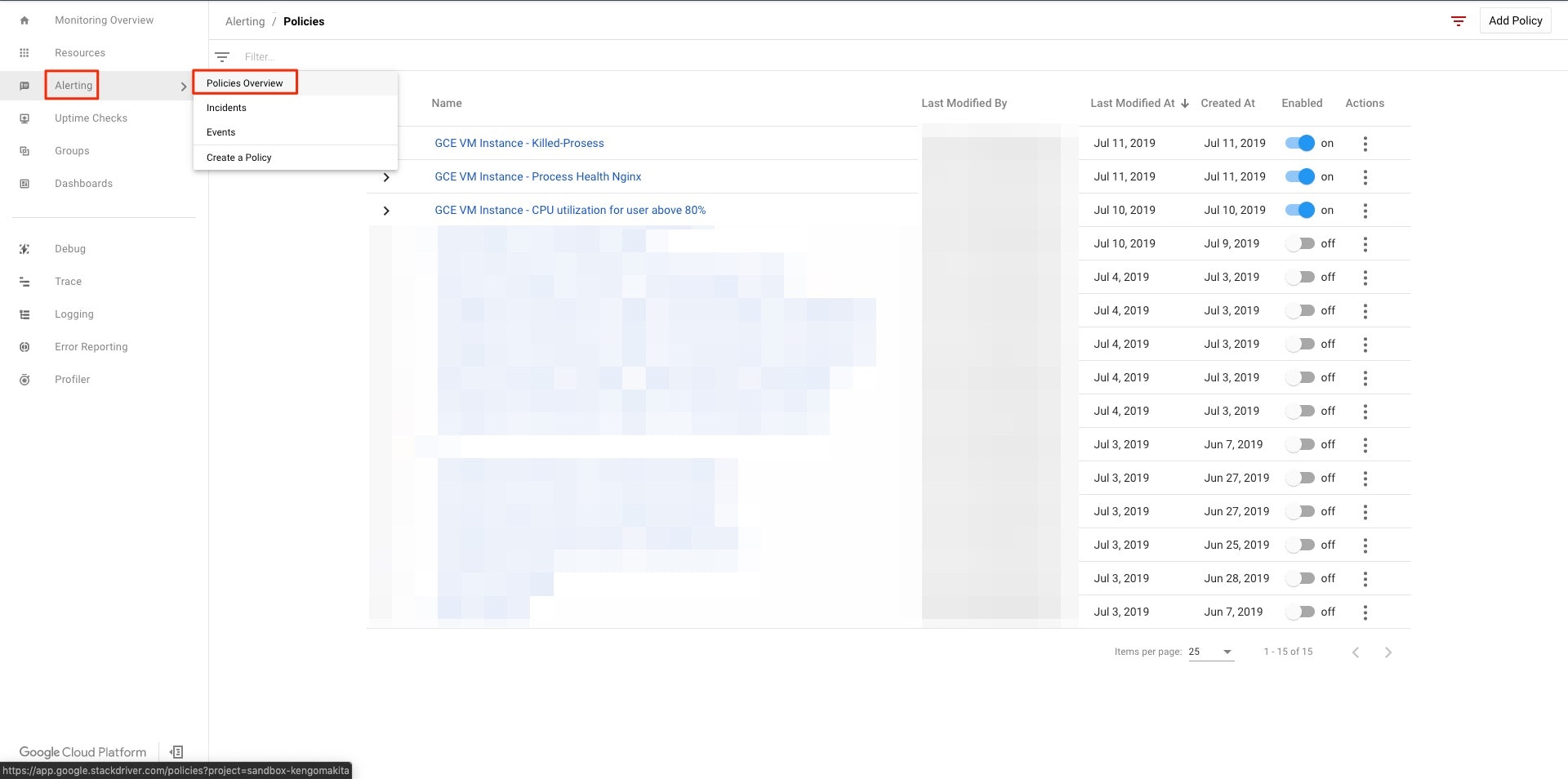
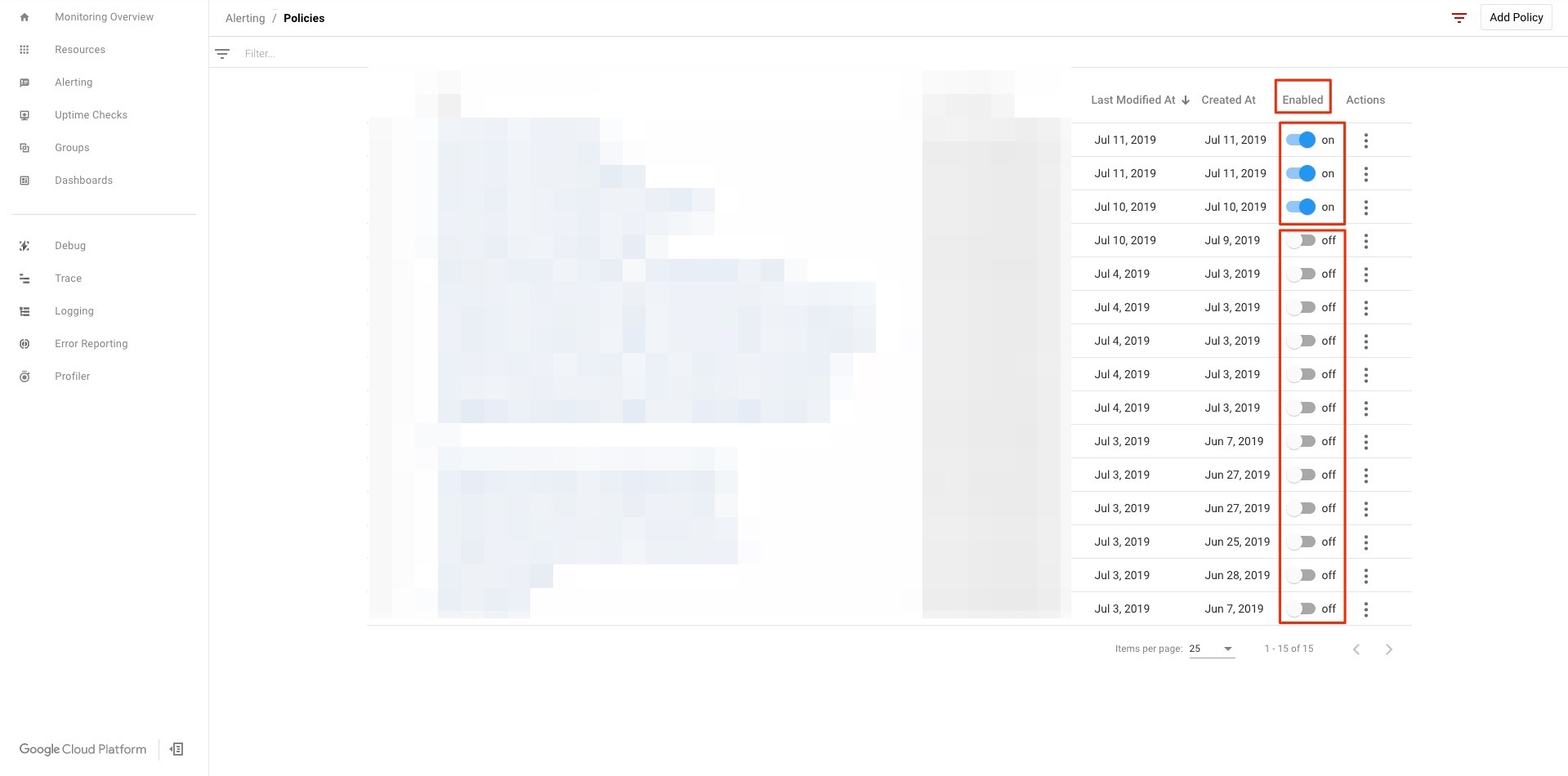
Policyの一覧が表示される。Enabledが青くなっているのが有効になっている。
無効化したいアラートのEnabledをクリックし灰色になれば無効化される。