前回 は文字列以外のメッセージとして、スタンプの送受信や、画像の送信を見ていきました。今回はユーザーが送ってきた画像の受け取り方と、画像の解析、および結果の返信を行います。
ユーザーからの画像を受け取る
まず、前回と同様にユーザーから送られる情報を確認します。
1. メインダイアログの「Unknown intent」直後に「Send a response」を追加。

2. ボットを再起動して LINE クライアントから画像を送信。応答を確認。

3. contentUrl のアドレスをコピーして、Postman でデータ取得を確認。

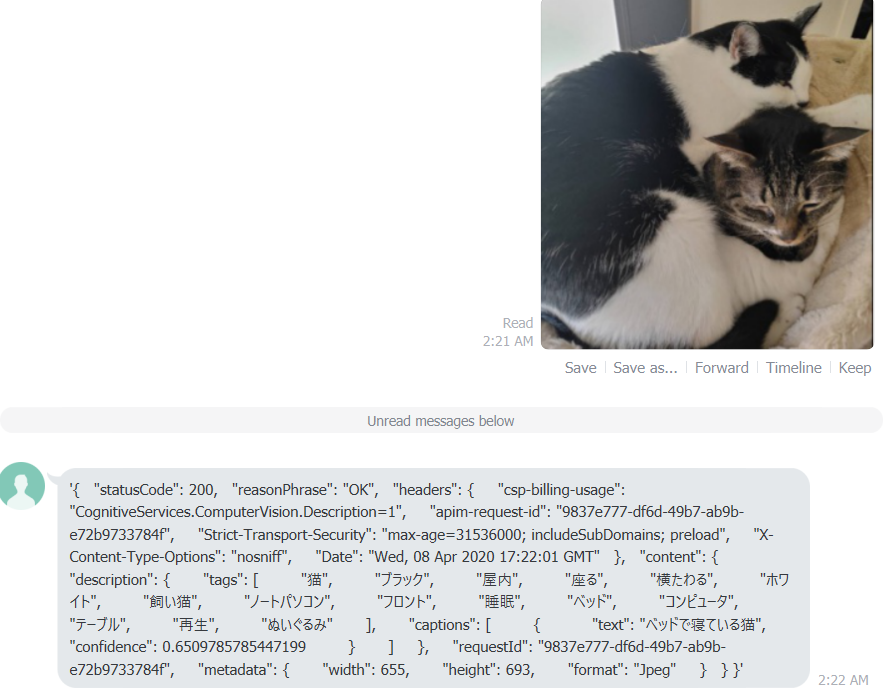
上記の結果より LINE から画像を送ると以下の情報が取れることが分かりました。
- turn.activity.channelData.message.type が image
- turn.activity.attachments[0].contentUrl のアドレスで画像が取得できる
Computer Vision の準備
画像を解析するために、Microsoft が提供する Cognitive サービスより Computer Vision を使います。
Computer Vision のページにあるデモで、機能を試せます。任意の写真を送って解析結果を確認します。

実施は API 経由で利用するため、サービスを作成します。
1. Azure ポータル より現在ボットがあるリソースグループを選択し、「追加」をクリック。

2.「Computer Vision」で検索して、サービスを作成。

3. 無償版である F0 を選択して「作成」。

4. リソースが作成されたらリソースに移動し、キーとアドレスをコピーしておく。

Computer Vision を試す
1. リソースの画面より「API コンソール」をクリック。

2. リソースを作成した地域をクリック。今回の場合は West US 2。
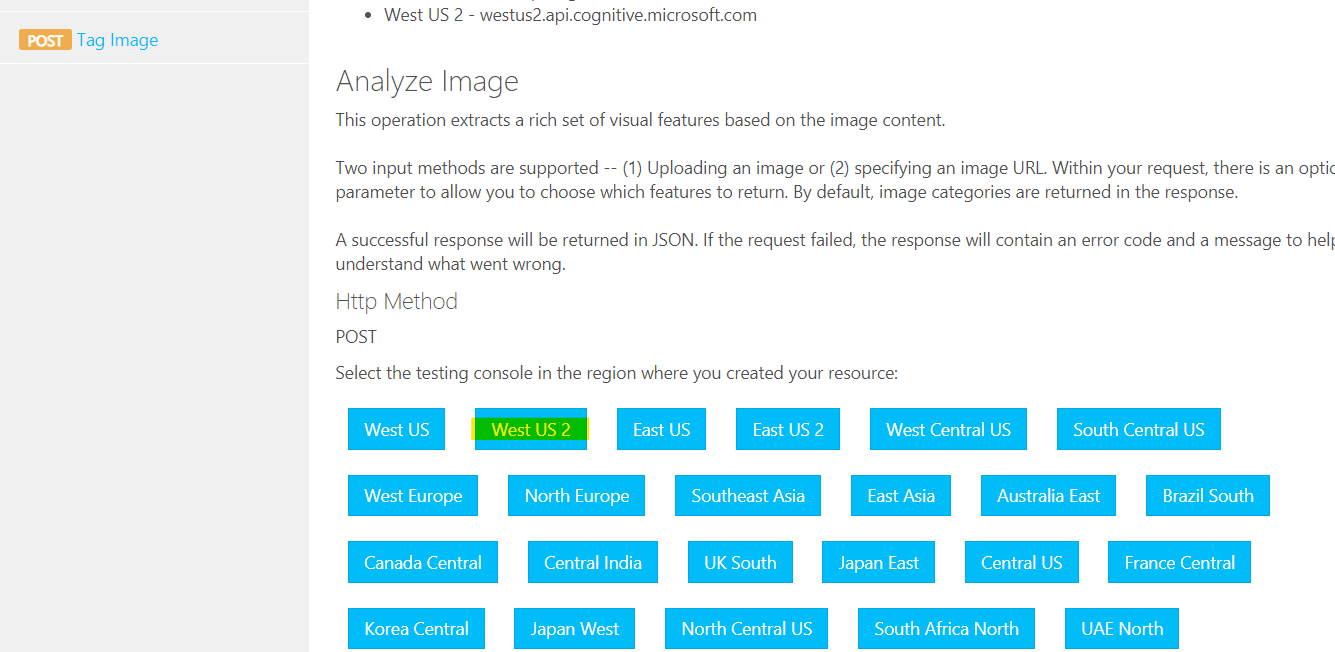
3. visualFeatures より「Description」、languageで「ja」を選択。

4.「Ocp-Apim-Subscription-Key」に先ほど確認したキーを入力。リクエストのボディに画像のアドレスを設定。
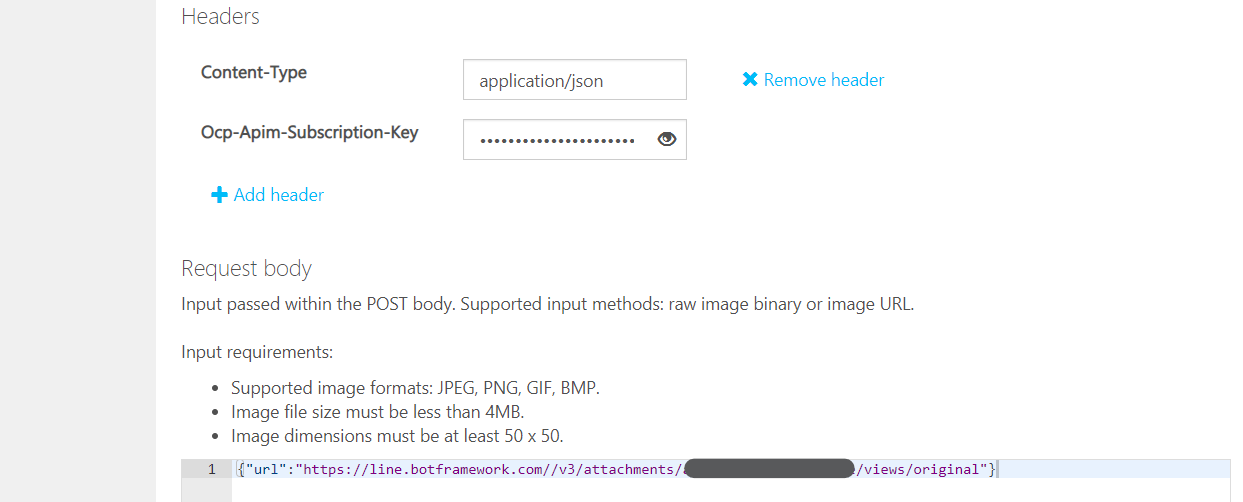
5. 「HTTP Request」が実際に送信される内容。後ほど利用。画面一番下の「Send」をクリックし結果を確認。

ダイアログの作成
受け取った画像を Computer Vision に送信し、結果を返すダイアログを作成します。
1.「New Dialog」より「AnalyzeImageDialog」を追加。

2. BeginDialog より「Access External resources」の「Send an HTTP request」アクションを追加。
3.「POST」を選択し、アドレスを先ほどテストした画面より https://westus2.api.cognitive.microsoft.com/vision/v2.0/analyze?visualFeatures=Description&language=ja を張り付け。

4. Body に以下 JSON を張り付け。
- first(): Common Expression の関数で、配列の中で一番初めのものを取得
{
"url": "${first(turn.activity.attachments).contentUrl}"
}
5. ヘッダーも先ほどのテスト画面を参考に 2 つ追加。
- ContentType: application/json
- Ocp-Apim-Subscription-Key: Computer Vision のキー
6. 結果を dialog.response で取得。形式は JSON のまま。

7. 応答送信のアクションを追加し、- '${dialog.response}' を指定。

これで解析結果が JSON として返ります。
トリガーの作成
スタンプを取得した時同様、message.type で判定します。今後もパターンが増える可能性があるため、if/else で分岐していたものを switch/cases に変更しておきます。
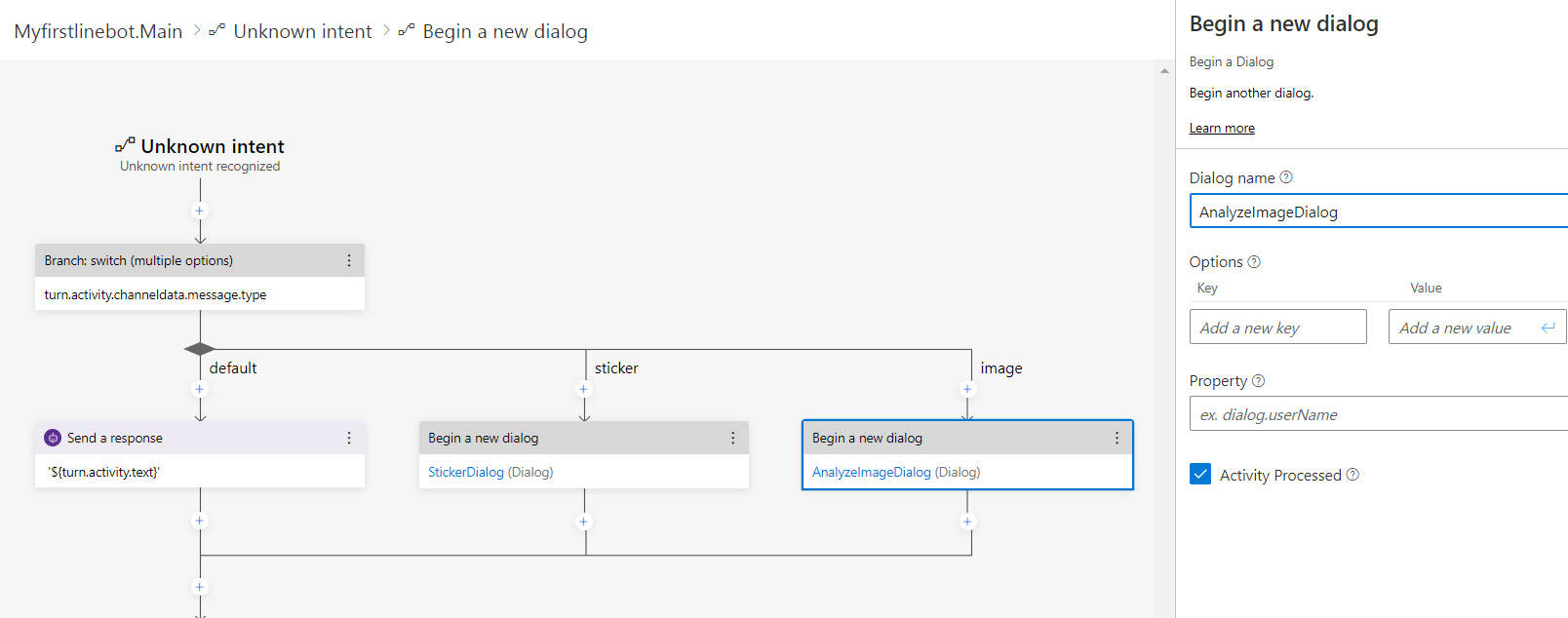
1. メインダイアログの「Unknown intent」を開き、既存の内容を一旦削除。その後「Branch: switch」を追加。「Condition」に turn.activity.channeldata.message.type を指定。また「Cases」には「sticker」と「image」を追加。
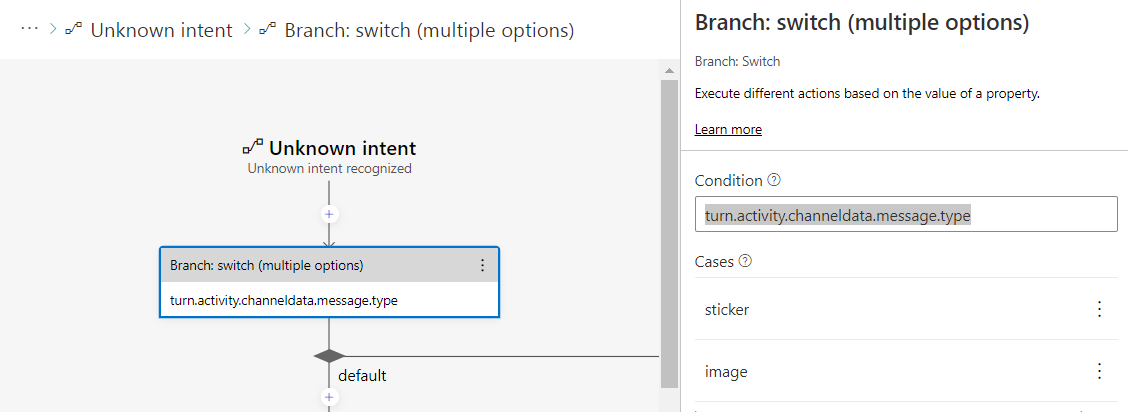
2. default ブランチに応答の送信アクションを追加し、- '${turn.activity.text}' を指定。また「sticker」ブランチ、「image」ブランチはそれぞれ対応するダイアログの開始を追加。
テスト
ボットを再起動して LINE クライアントより画像を送ります。結果無事帰ってくれば成功です。
応答メッセージの加工
現在結果が JSON のままである為、結果の返し方を変更します。
1. AnalyzeImageDialog の BeginDialog より最後の応答送信アクションを選択。
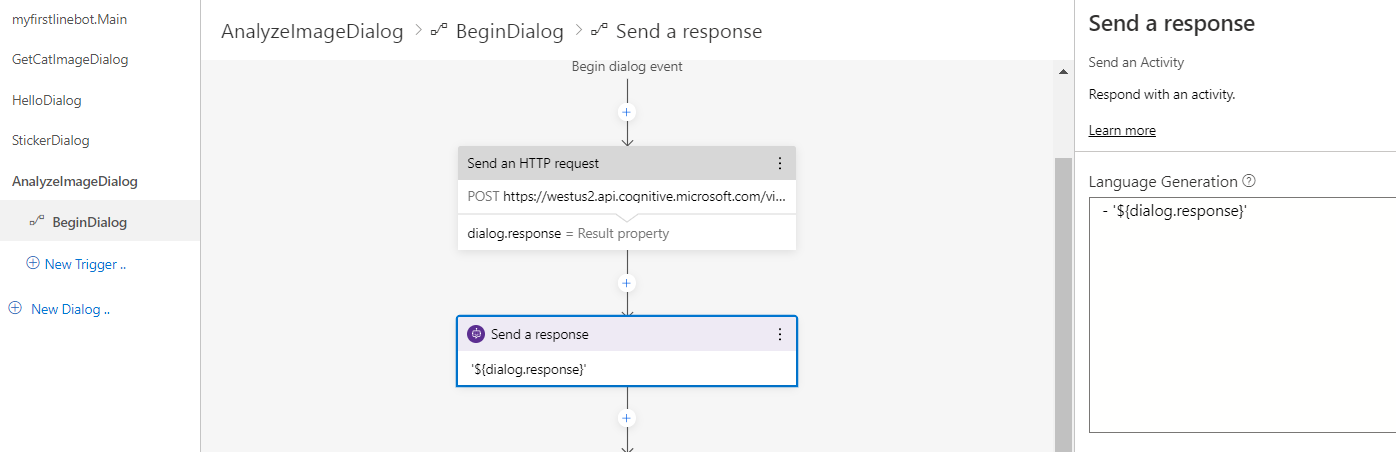
2. 中身を以下に変更。
[Herocard
title = ${first(dialog.response.content.description.captions).text}
subtitle = ${concat('確率:', first(dialog.response.content.description.captions).confidence)}
text = ${concat('タグ:', join(dialog.response.content.description.tags, ','))}
images = ${first(turn.activity.attachments).contentUrl}
]

テスト
再度 LINE クライアントから写真を送信して、解析結果が変わることを確認してください。

Custom Vision
Computer Vision はマイクロソフトが事前に作成したモデルを使いますが、カスタムビジョンを使うと、独自の解析モデルを使う事もできます。Composer からの呼び出し方はほぼ同じのため、興味があれば試してください。
以下の GitHub レポジトリに使い方を含めた情報があります。
Microsoft Cognitive Services を利用した 画像分析アプリ (201906 版)
まとめ
今回は画像の受け取り方法と外部サービスの呼び出しを見ていきました。画像は LINE プラットフォームから Bot Connector に自動で変換されているため、容易に取得できました。
外部 Web サービスについては、呼び出しの方法は簡単ですが、サービスごとにアドレスやヘッダー、ボディの内容が異なる他、戻り値も異なるため、サービスの使い方をよく調べることが必要となります。Postman などを活用しながら、API 連携をしてください。