今年もそろそろ終わりなので、Qiita の記事を解析しよう。そう Power BI でね!ということでやっていきます。尚、今回コードは極力書かない方向で頑張ります。また一番最後にコード書いた場合も載せておきます。
Qiita API の仕様を確認する
Qiita Developer Docs に必要な情報があります。
アクセストークンを取得する
まずはトークン。アプリ連携する予定はないので、個人用のトークンを取ります。
1. Qiita 設定ページ より「Generate new token」をクリック。
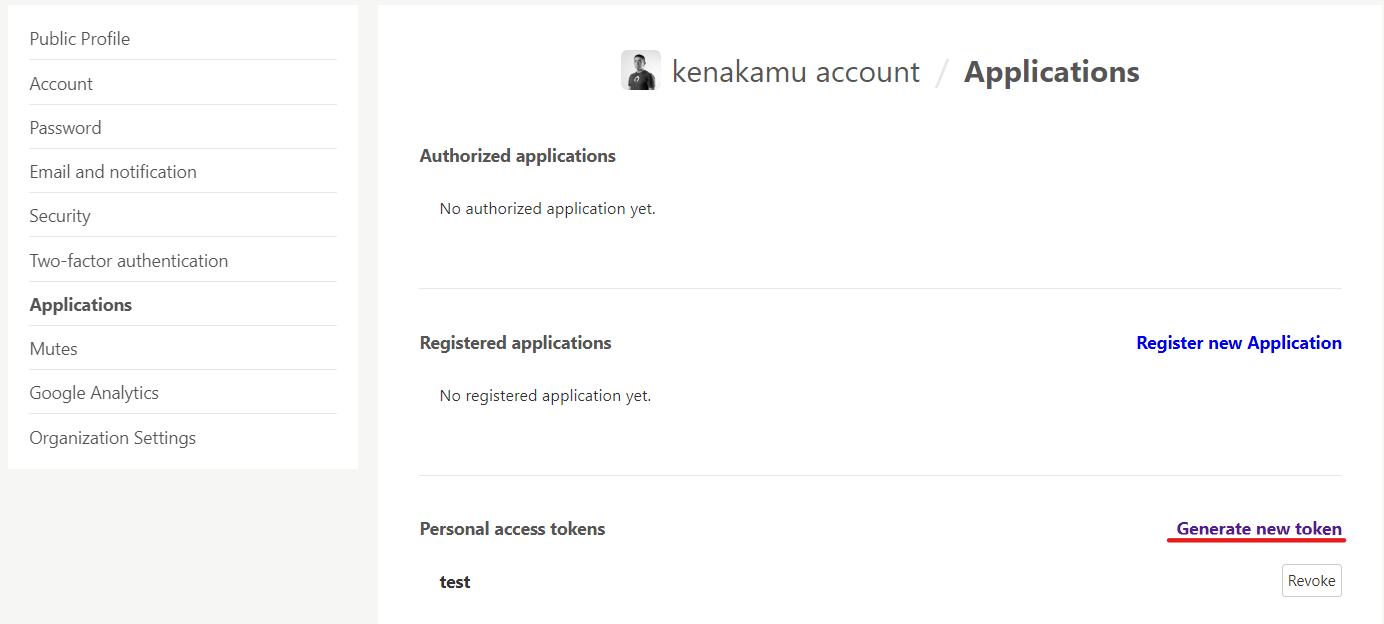
2. 任意の名前と必要なスコープを指定。今回は記事情報取得するだけのため、「read_qiita」のみ。
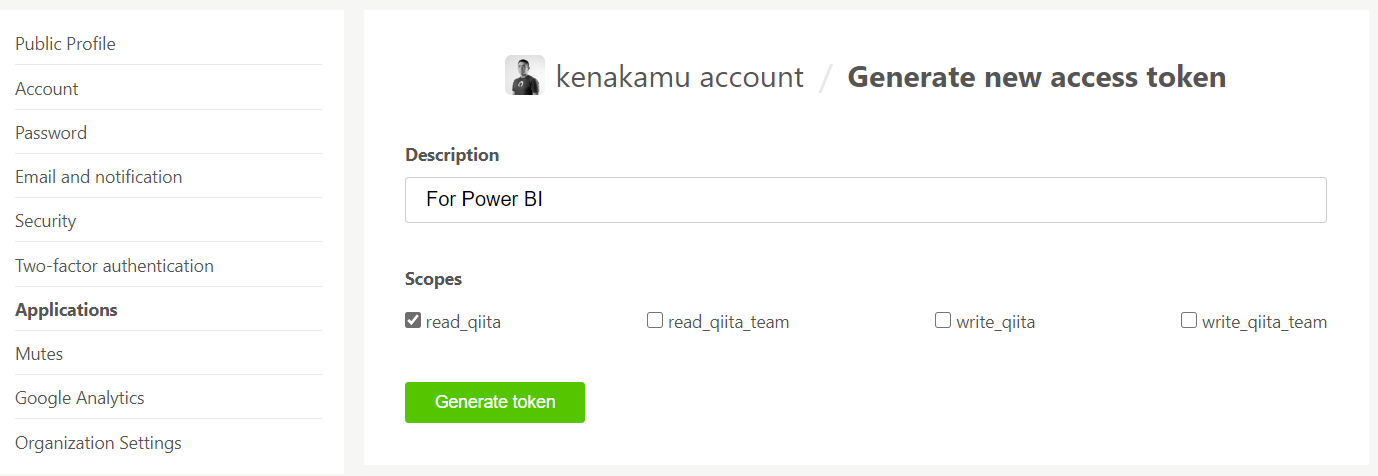
3.「Generate Token」をクリックして、発行されたトークンを大事に保管しておく。
複数記事取得
幾つか考慮事項があります。
- OData に対応というわけでもなく、$select や $filter はなさそう
- Paging が有効であり、既定 20 上限 100 で記事を取得できる
早速 Postman で動作確認。
1. https://qiita.com/api/v2/authenticated_user/items に対して GET を実行。またヘッダーに Authorization: Bearer <アクセストークン> を指定。
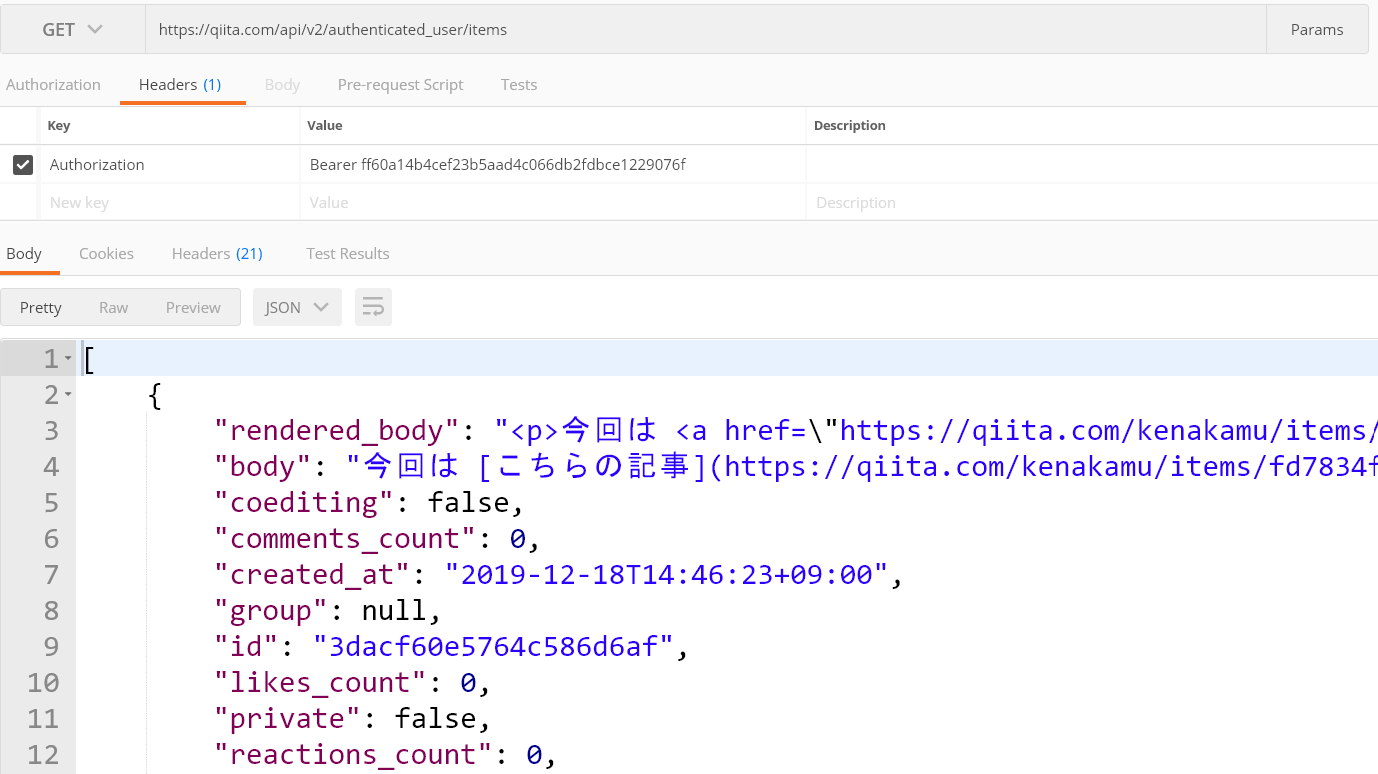
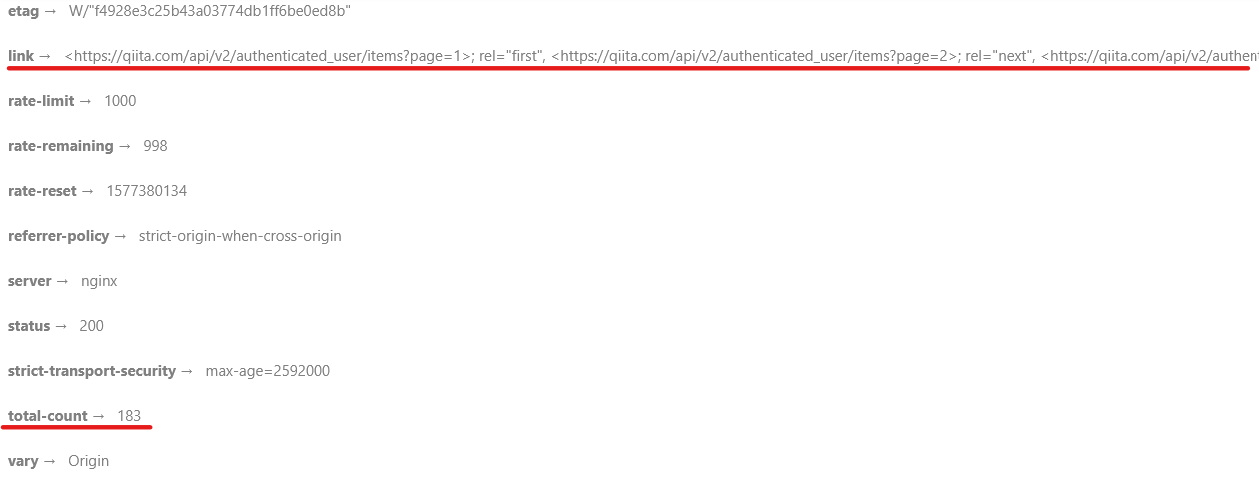
2. ヘッダーを確認すると、記事の合計数と次ページへのリンクなどが返っている。
記事単体取得
ドキュメントを見ている限りできそうだが、page_views_count の値がすべて null になっているため、個別に記事も取得して確認。単体記事だと値が取得できている。
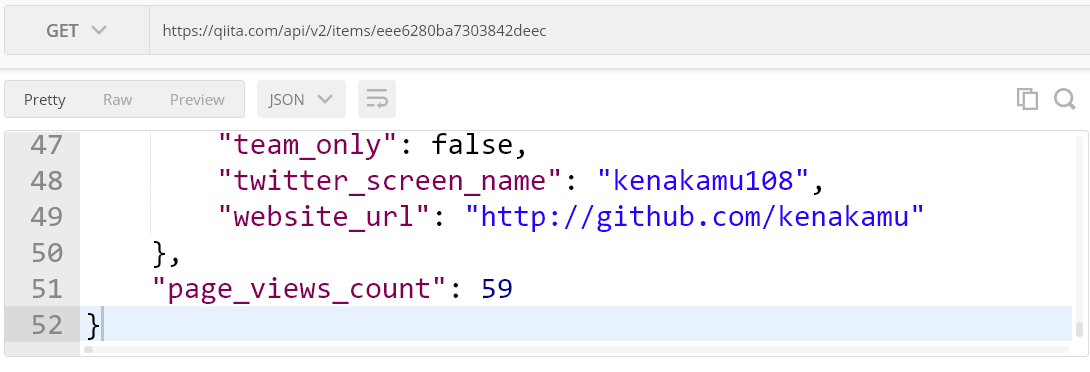
Power BI Desktop でデータを取得
Qiita API の仕様を見たので、早速データを取り込みましょう。
データの取得
まずは API のアドレスとアクセストークンでデータを取得してみます。
1. Power BI Desktop を起動し、「データを取得」をクリック。
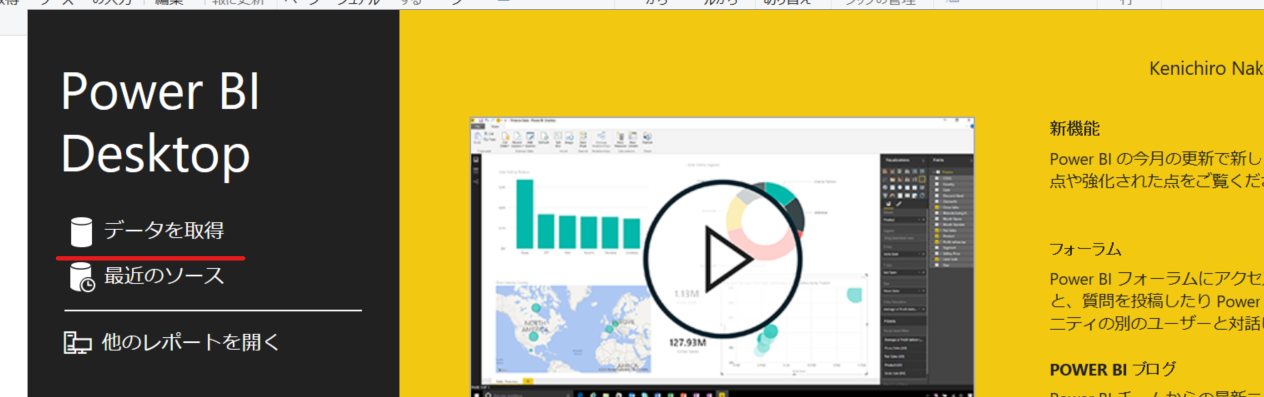
2. 一応 Qiita 用コネクタがないか見ているが、やはり無い。

3.「Web」を選択して「接続」。
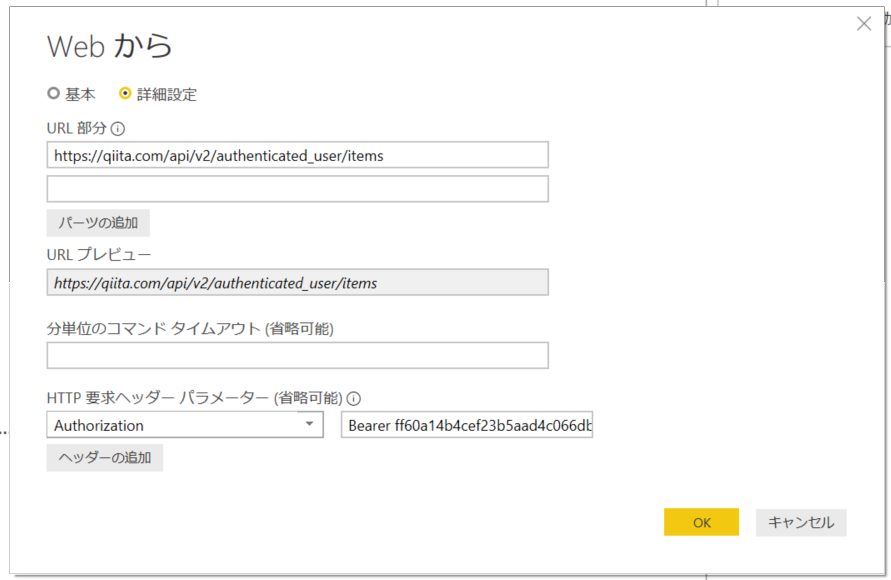
4.「詳細設定」を選択。アドレスと HTTP 要求ヘッダーを入力して、「OK」。
5. レコードがページング既定の 20 件取得できていることを確認。
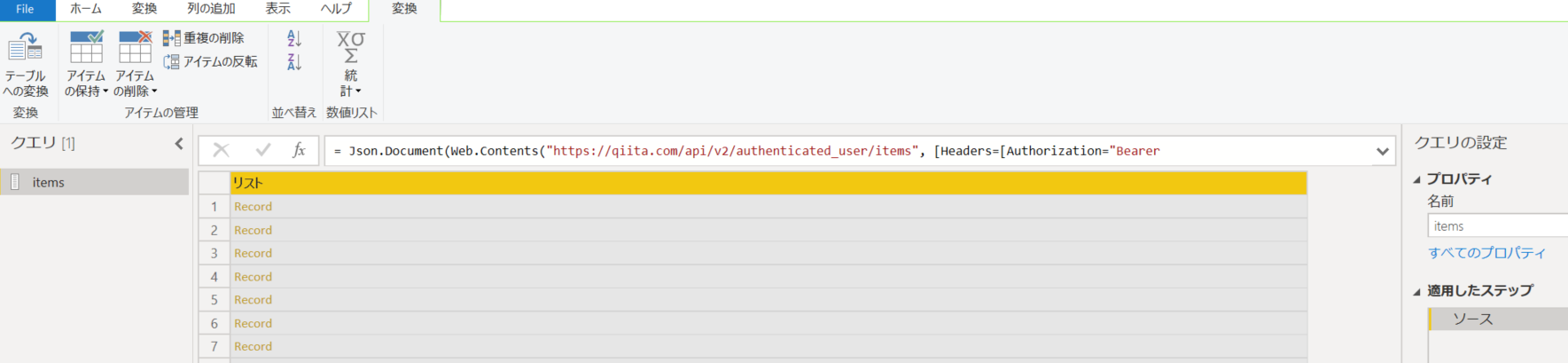
ページングテーブル作成
現在のままでは最新 20 件しか取れませんが、レコードの合計件数は応答ヘッダーに入っています。だがしかし!!Power BI で Web.Content のヘッダーが全部は見れない問題 があるようなので、ちょっとだけ M 言語使ってまずは取得したい記事数/100 のページテーブルを作ります。
1. 新しいパラメーターを追加。
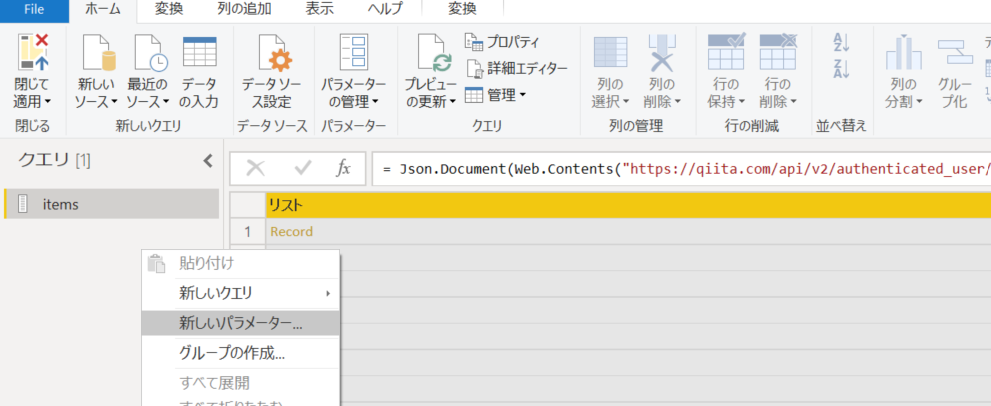
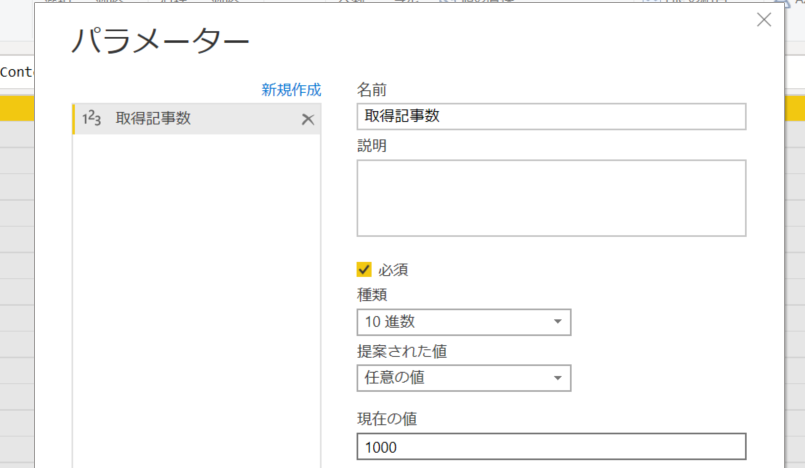
2. 取得したい記事数を指定できるように設定。
3. 指定された数字をつかってリストを作成。「新しいクエリ」より「空のクエリ」をクリック。
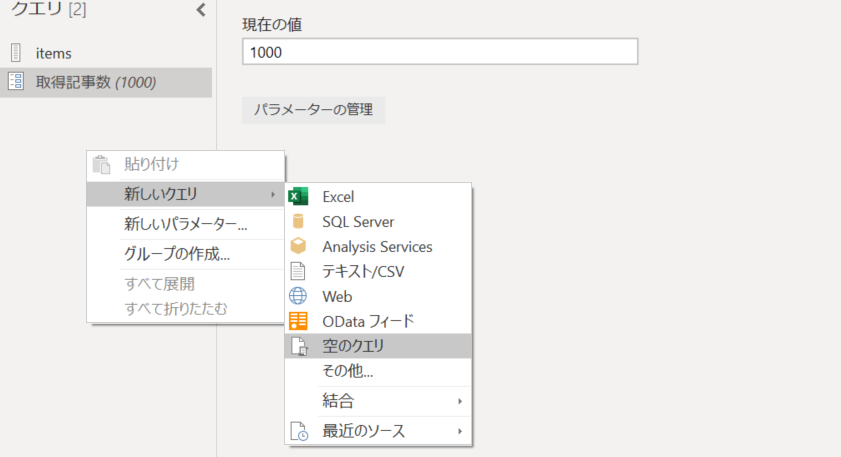
4. クエリ名を「PagingInfo」に変更。式に = List.Generate(()=>取得記事数, each _> 0, each _-100) を入力してリストを動的作成。
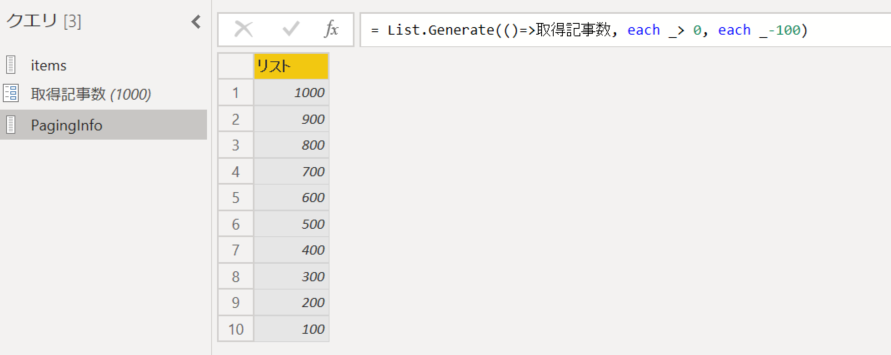
5. リストをテーブルに変換。既定のオプションのまま変換を実行。
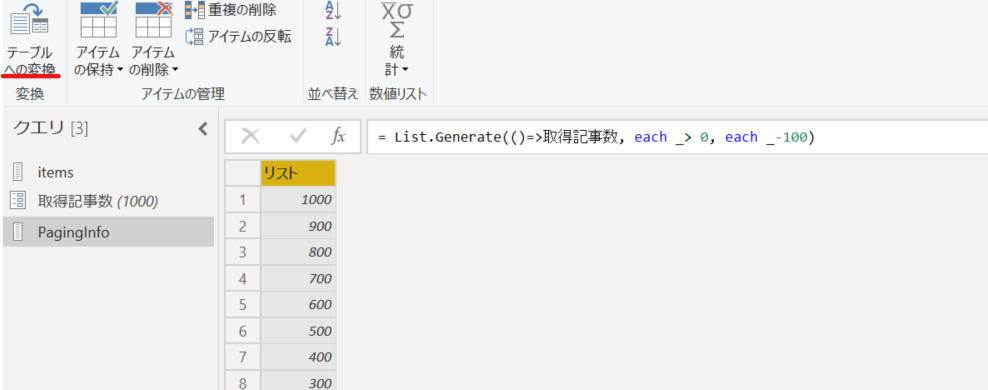
6. 現在の値は記事数であるため、最大ページ数の 100 で割った値を作成。「標準計算」より「除算」をクリック。
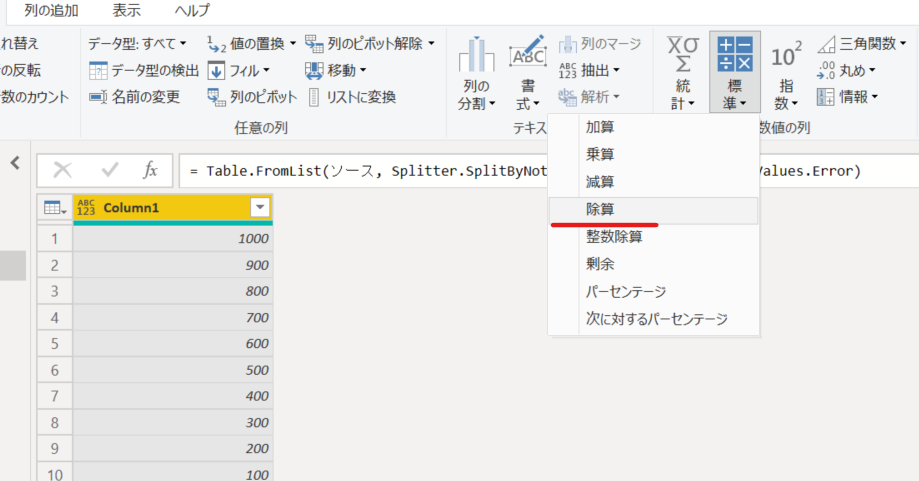
7.「100」を入力して「OK」
8. 値を昇順で並べ替えておく。
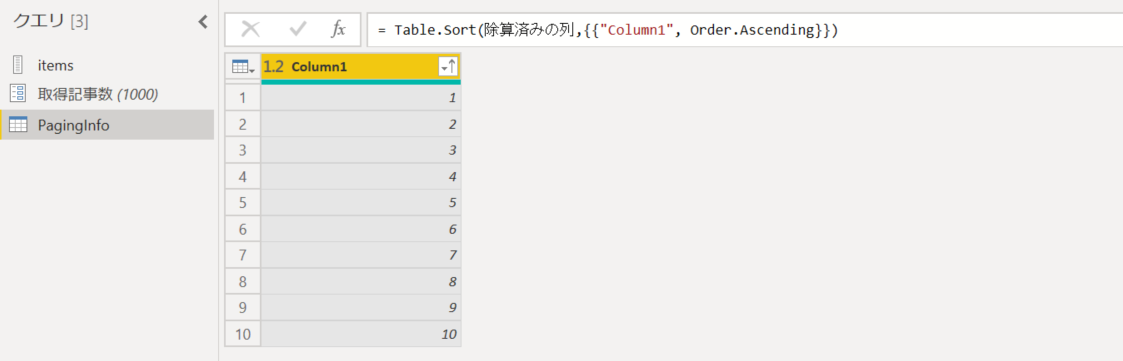
ページングを使ったレコード ID の取得
次にレコードの ID を取得していきます。
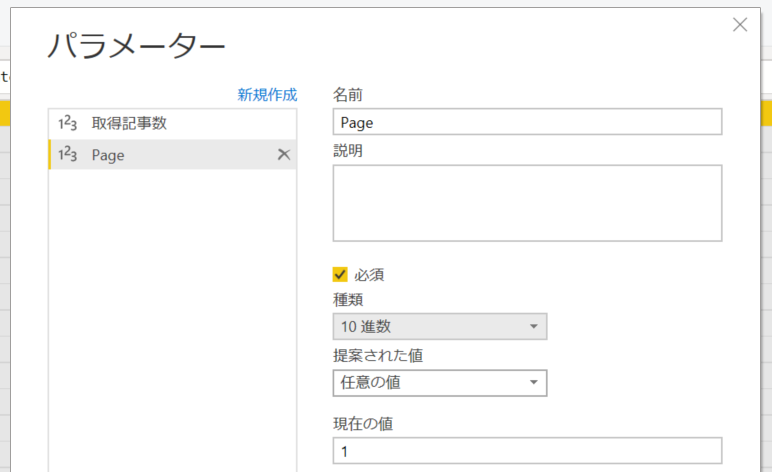
1. 新しくパラメーターを追加。名前を Page、10 進数で作成。
2. items クエリのアドレスを変更してページング情報を付加。
- Page パラメータを使用
- Number.ToText を使って数値を文字列に変換
"https://qiita.com/api/v2/authenticated_user/items?per_page=100&page=" & Number.ToText(Page)
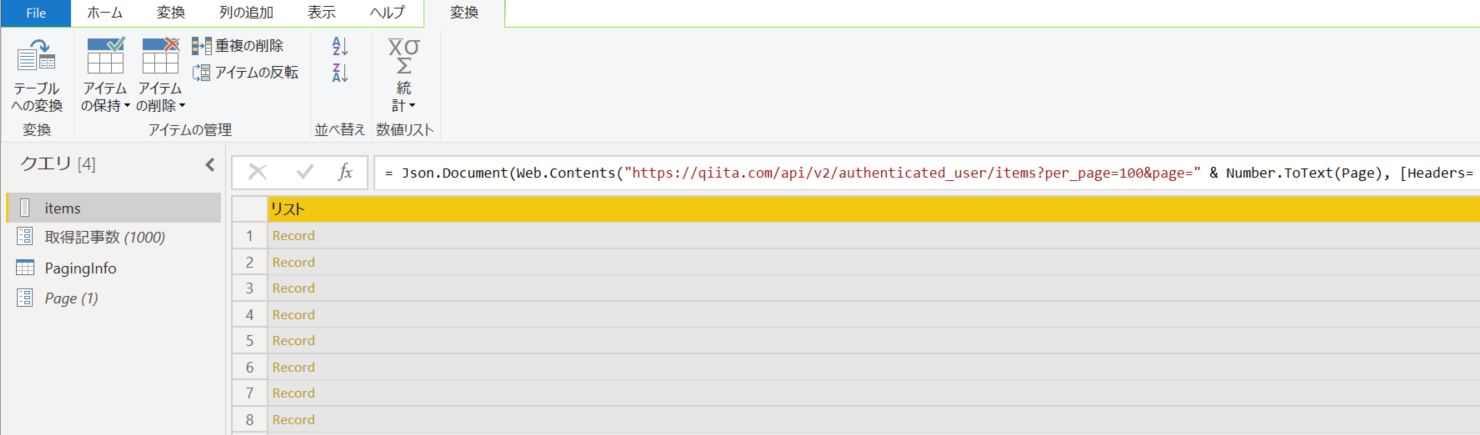
3. レコードが取得できていることを確認し、「テーブルへの変換」をクリック。
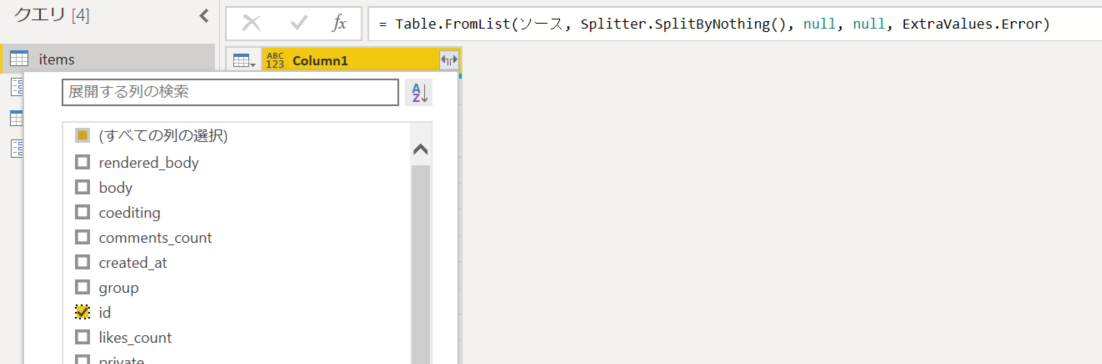
4. 「列の展開」アイコンをクリックして「id」の未選択。プレフィックスは付けない。
5. 記事の id 一覧が取得できたことを確認。
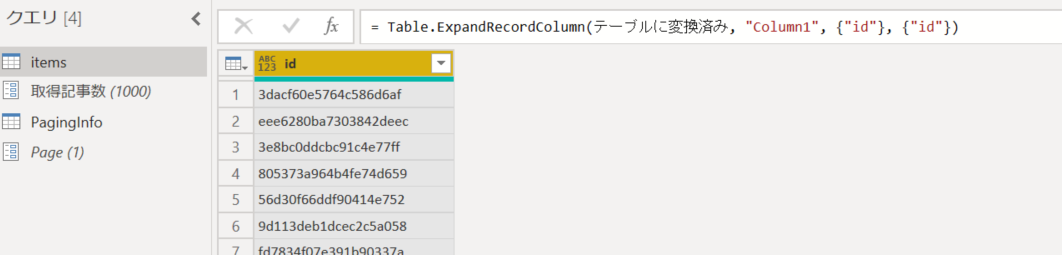
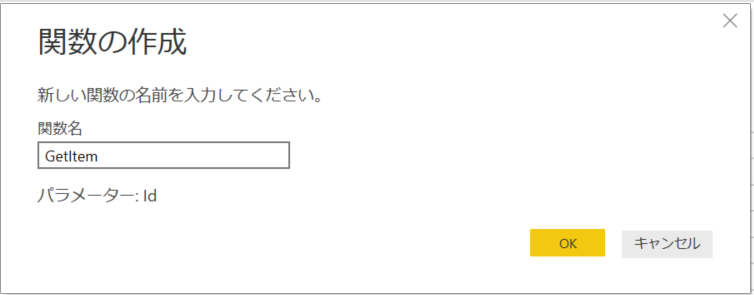
6. items クエリを右クリックして「関数の作成」をクリック。
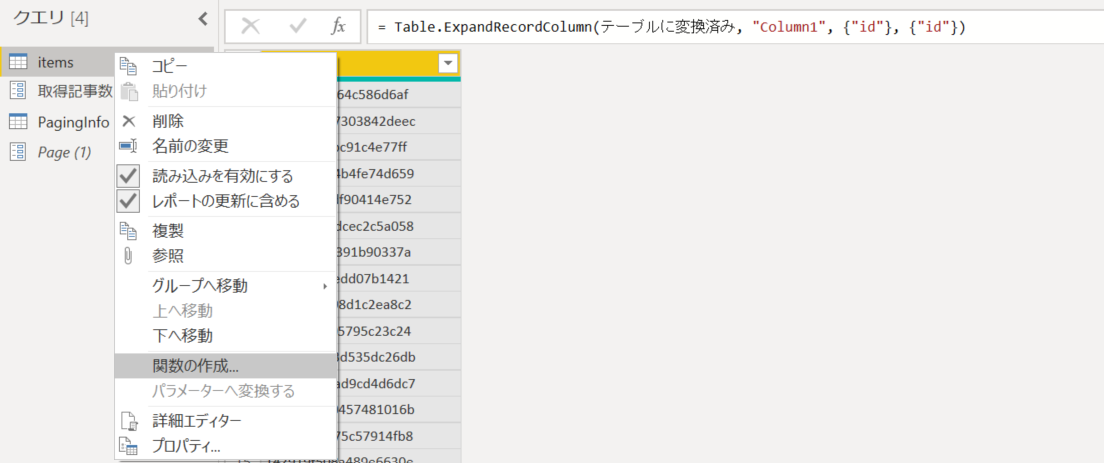
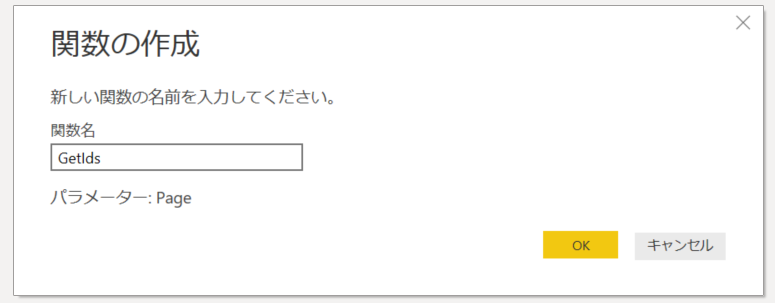
7.「GetIds」と名前をつけて「OK」をクリック。
ページングを使ったレコード ID の取得
次にページングテーブルから、作成した関数を呼び出してレコードを取得します。
1. PagingInfo クエリに戻り、「カスタム関数の呼び出し」をクリック。
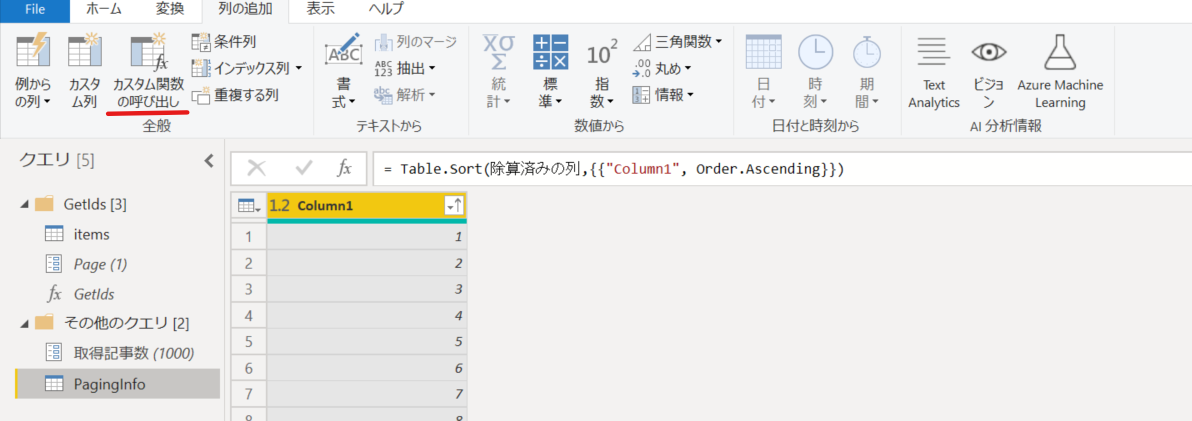
2. GetIds 関数を指定し、パラメータに「Column1」を指定。「OK」をクリック。これで Column1 の値を使って各行に対してカスタム関数が実行される。
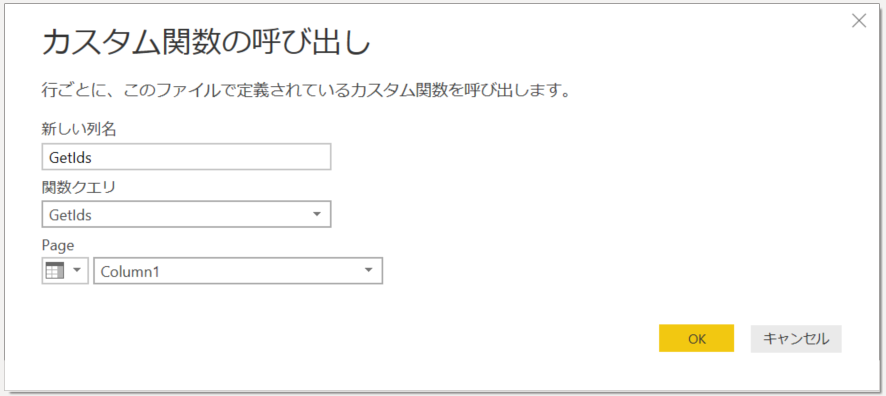
3. ページングを指定したものの、レコードが無い場合は「Error」となる為、列を右クリックして、「エラーの削除」をクリック。
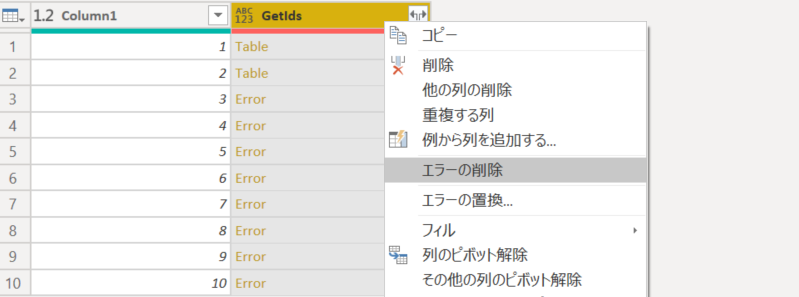
4. Table を展開。
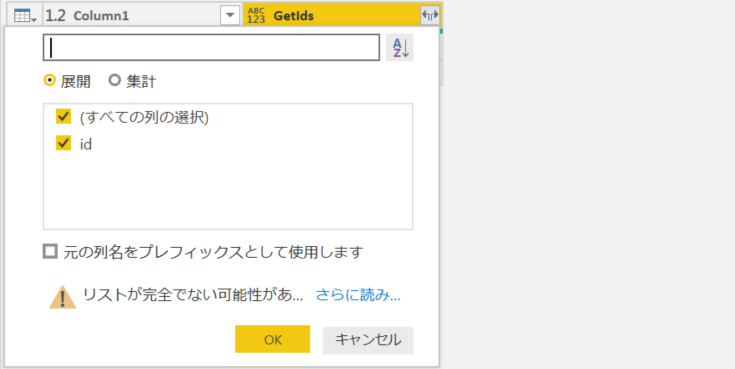
5. ページングを利用して 100 件以上レコードをが取得できていることを確認。

レコード詳細取得関数の作成
ID 一覧を取得した時のように、関数を作成。
1. 新しいパラメーターより、名前を Id、テキスト型で作成。値は任意の記事 Id を指定。
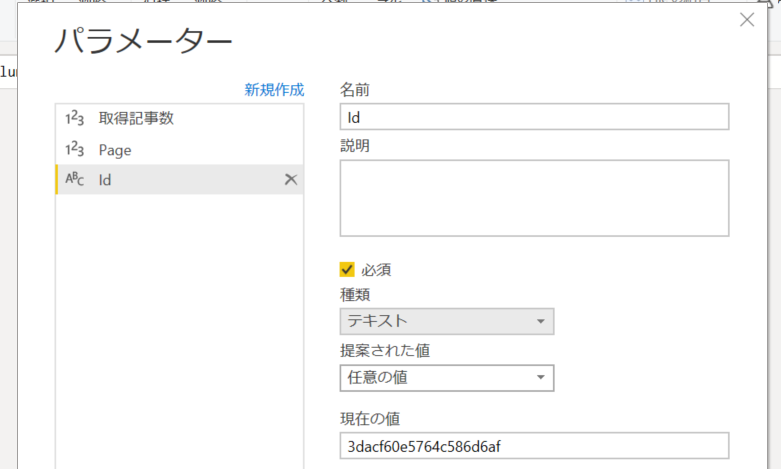
2.「新しいソース」より「Web」を選択。
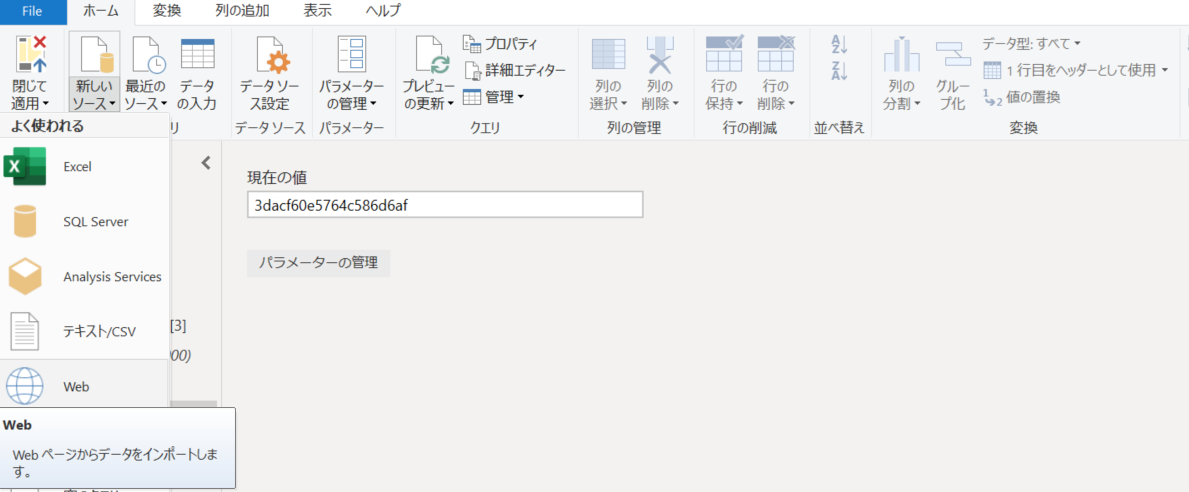
3. 詳細設定より、作成した id パラメーターを使った URL、および認証を指定。
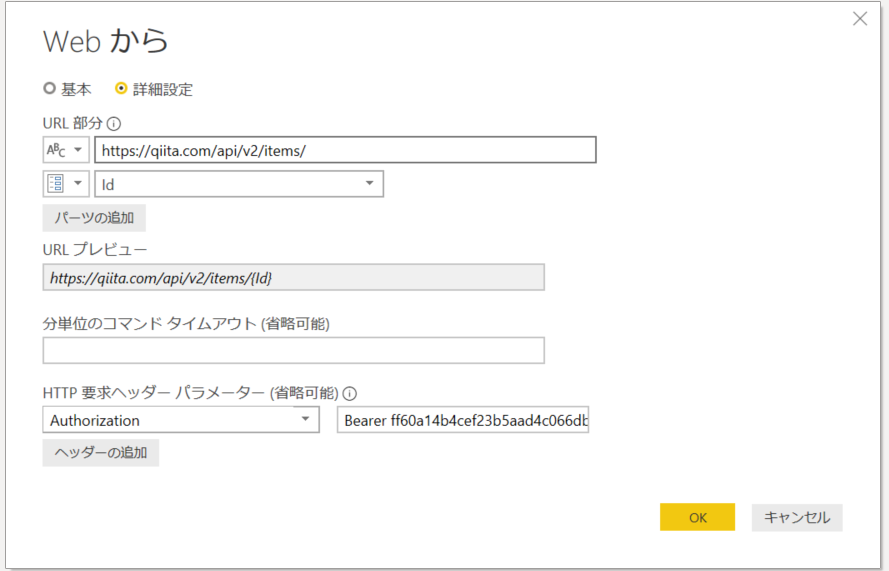
4.「接続」をクリック。
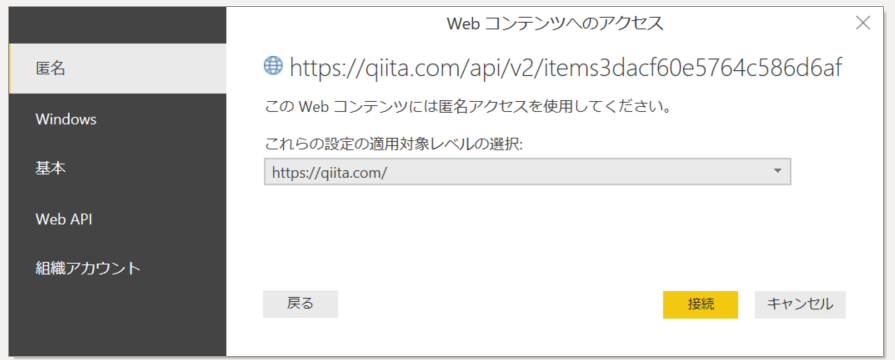
5. レコードが取得できることを確認。
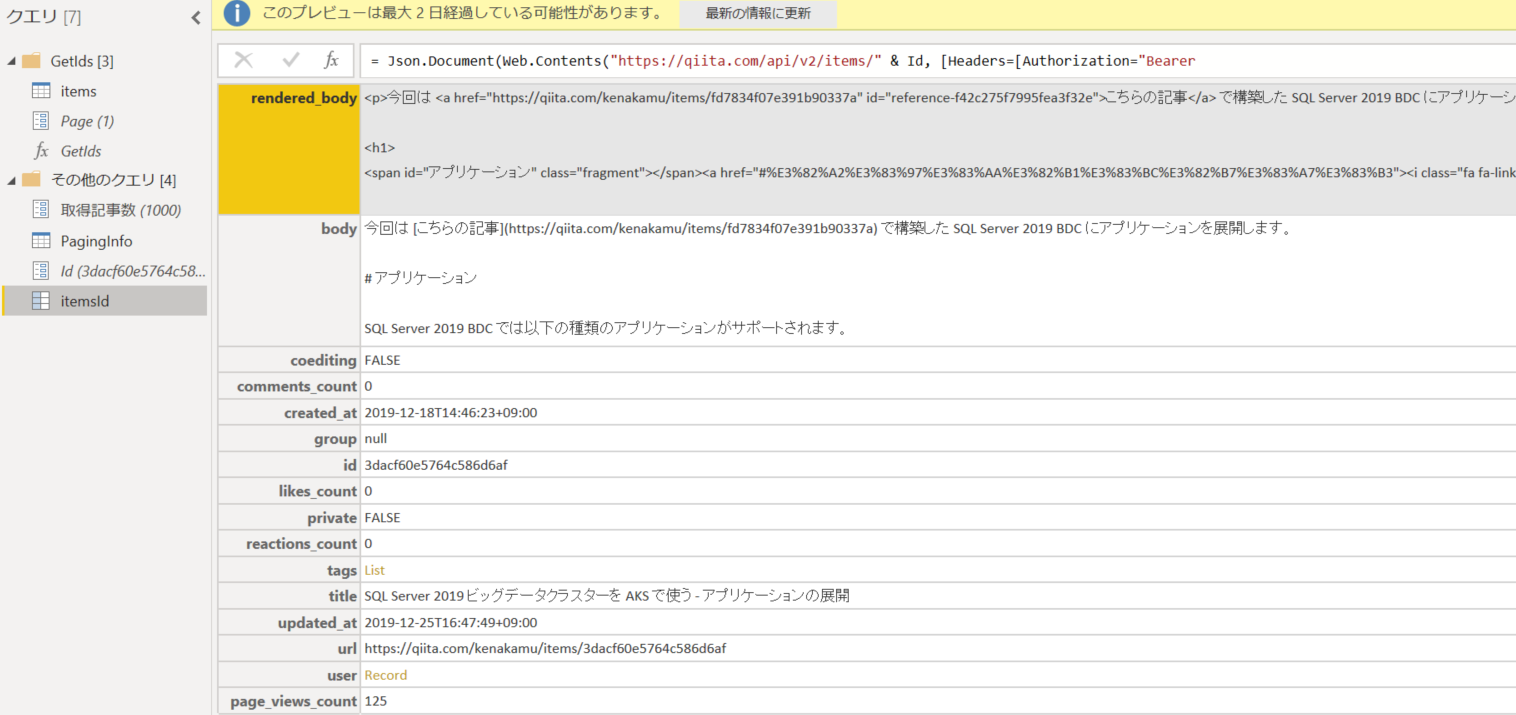
6. クエリを右クリックして「関数の作成」をクリック。
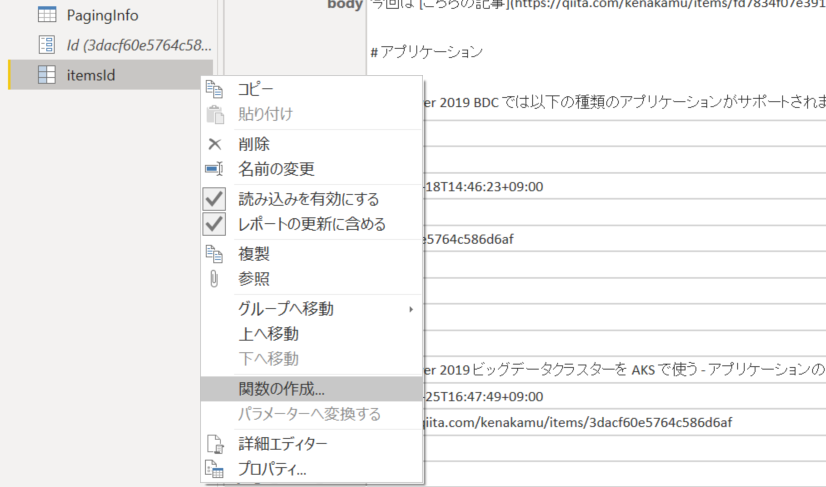
7.「GetItem」を名前を付けて作成。
レコード詳細の取得
最後にレコードを取得します。
1. PagingInfo に戻って、「カスタム関数の呼び出し」をクリック。
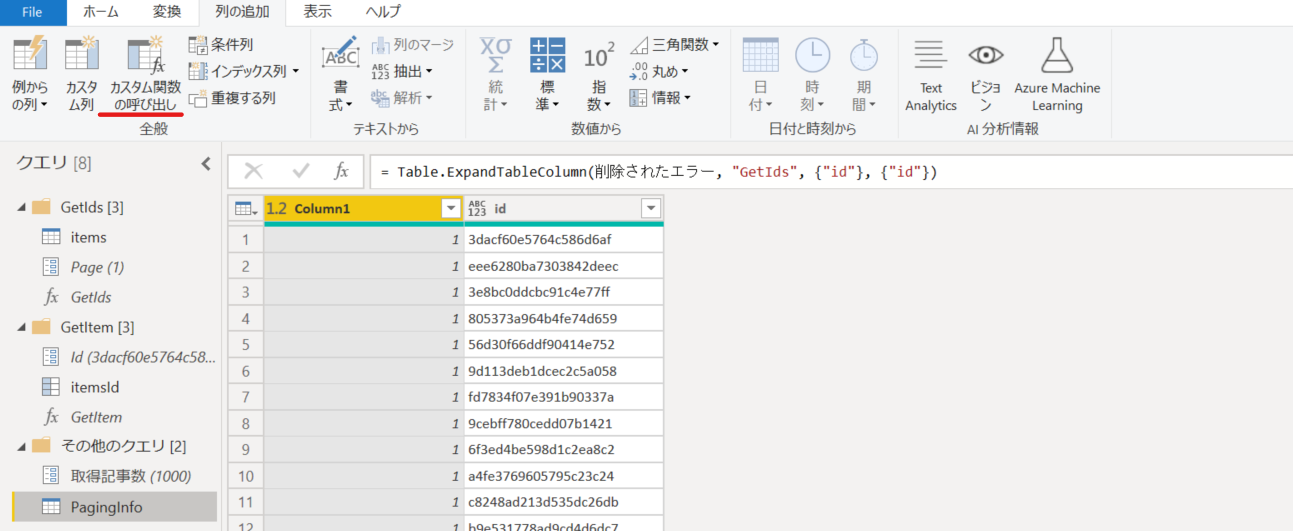
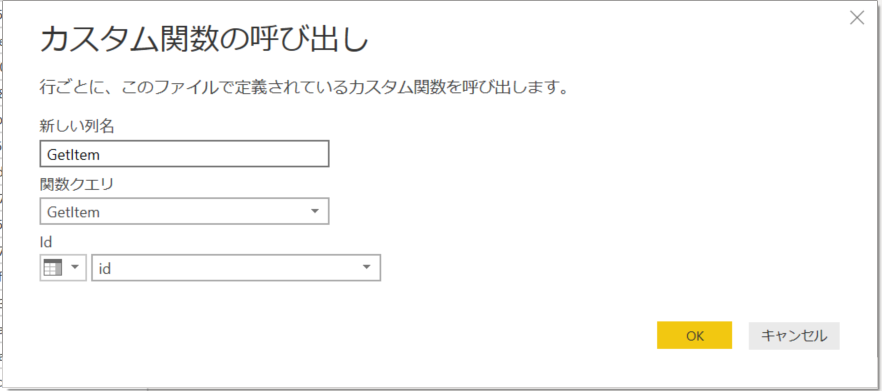
2. GetItem 関数に対して、id 列をパラメーターとして指定。
3. レコードが取得できたら、必要な列を展開。
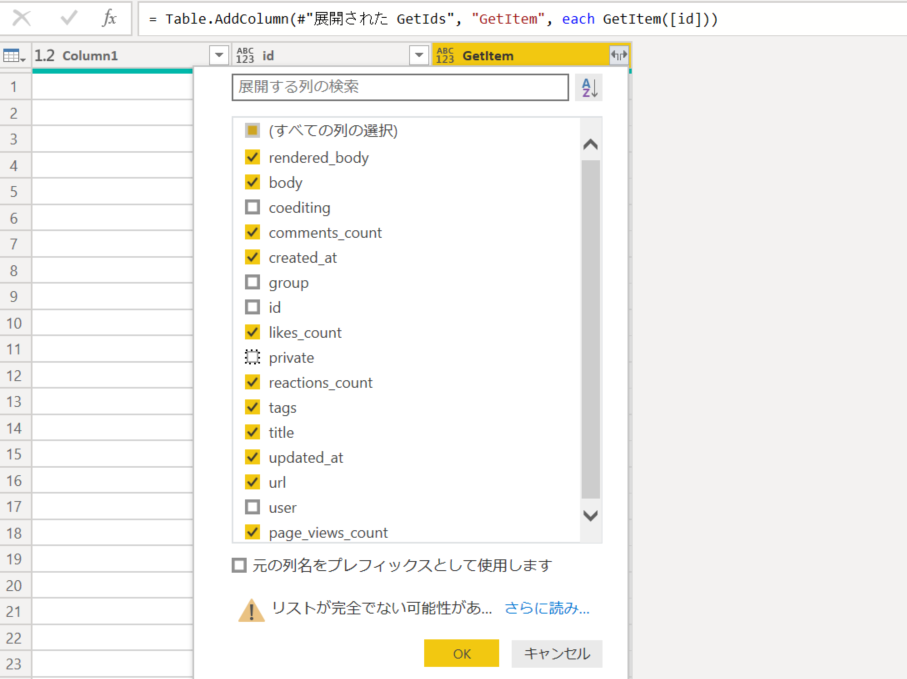
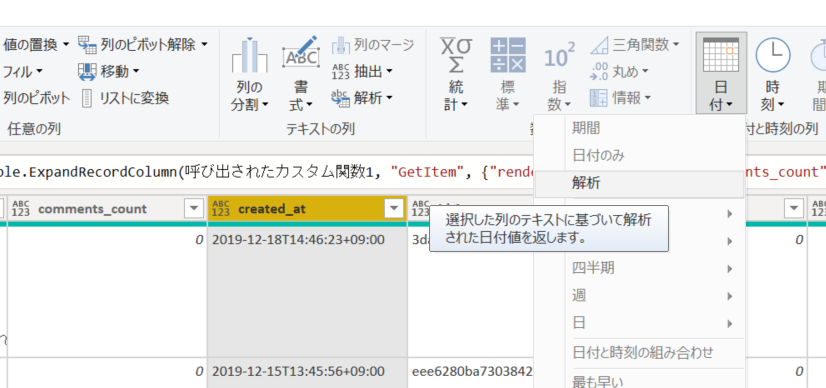
4. created_at と updated_at 列に対して、日付の解析を実行。
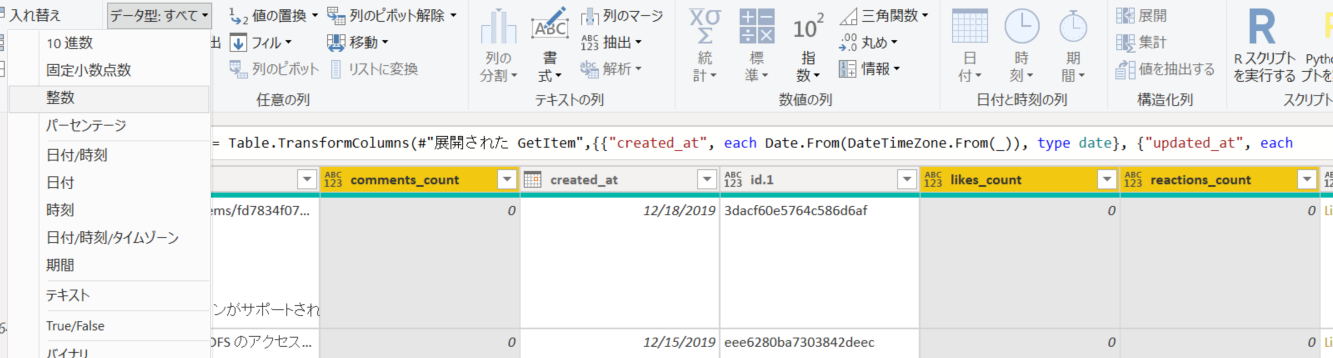
5. comments_count、likes_count、reactions_count、page_views_count を整数型に変換。
タグ一覧の追加
各記事には複数のタグが付いているため、そちらも別途準備。
1. PagingInfo クエリを複製。Tags に名前を変更。
2.「展開された GetItem」以降のステップをすべて削除し、「展開された GetItem」で Tags のみ選択。
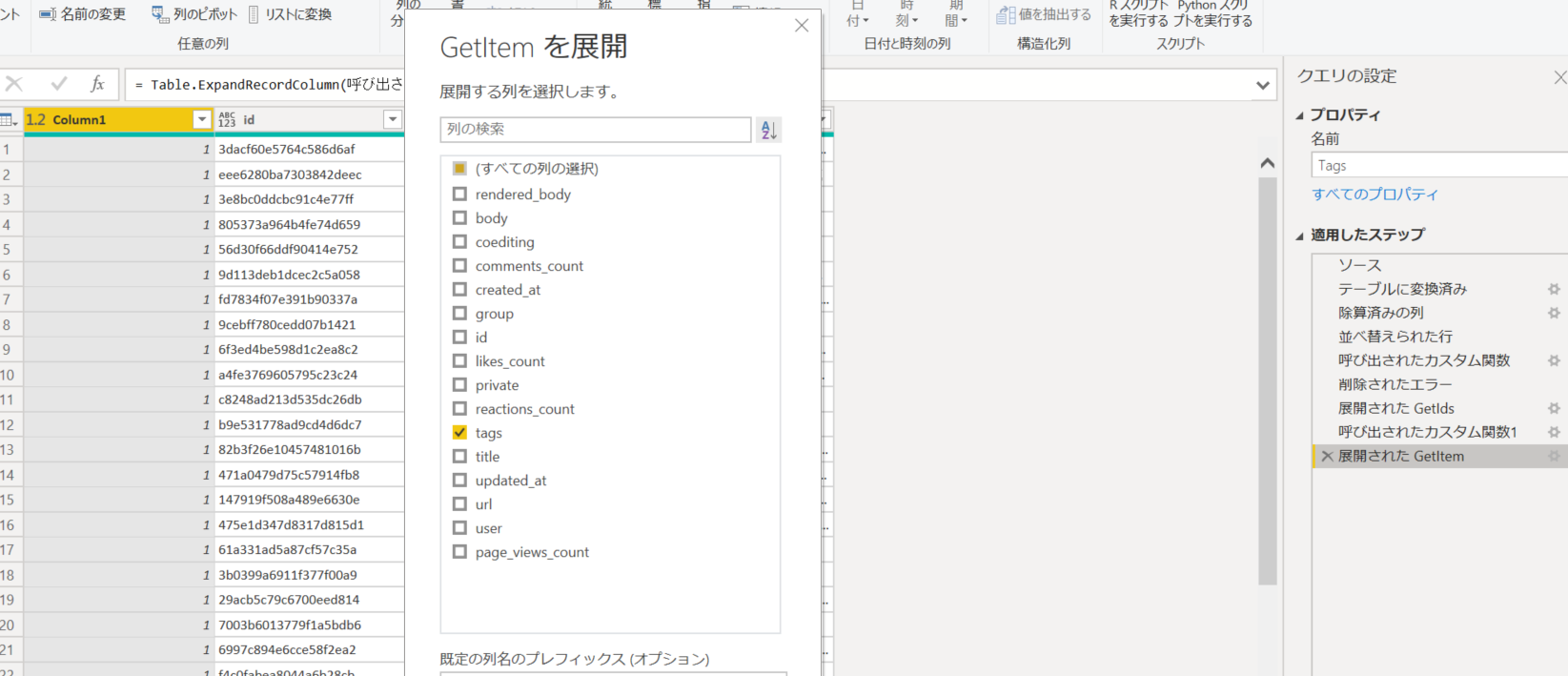
3.「新しい行に展開する」を選択。
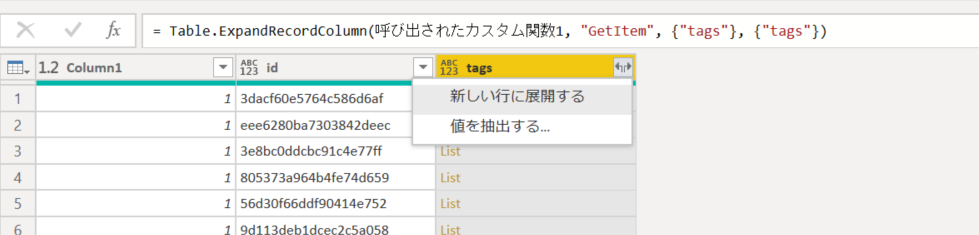
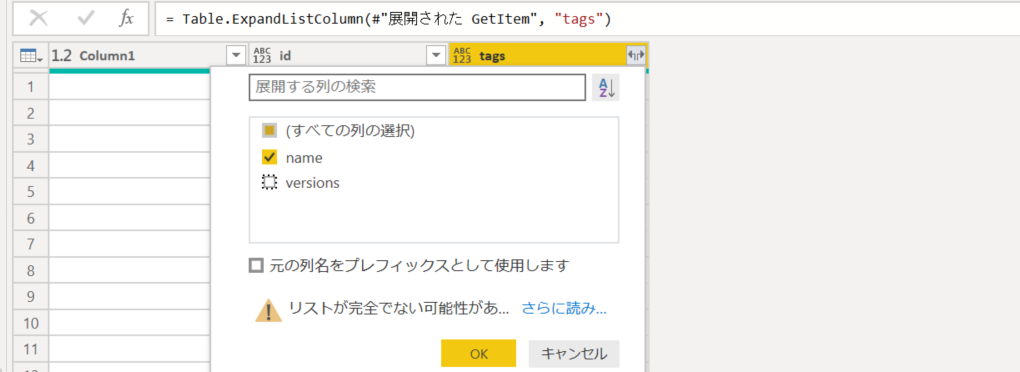
4. name 列だけ展開。
不要なクエリの削除と名前の変更
1. カスタム関数のもとになった、items と itemsId クエリを削除。
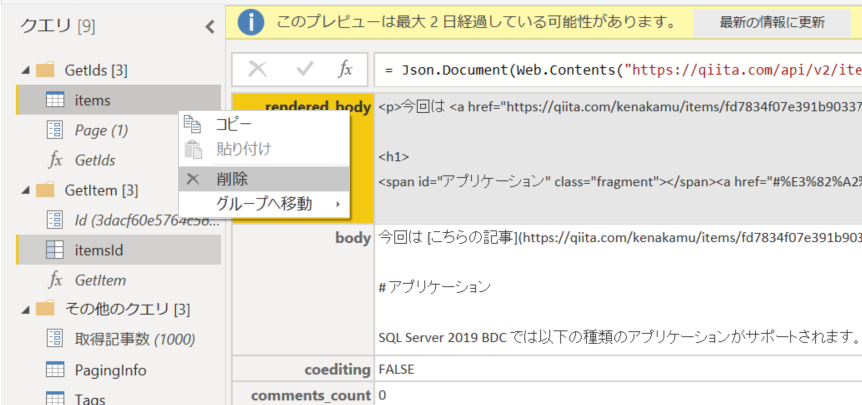
2. PagingInfo クエリを Items と名前を変更。
3.「閉じて適用」をクリック。
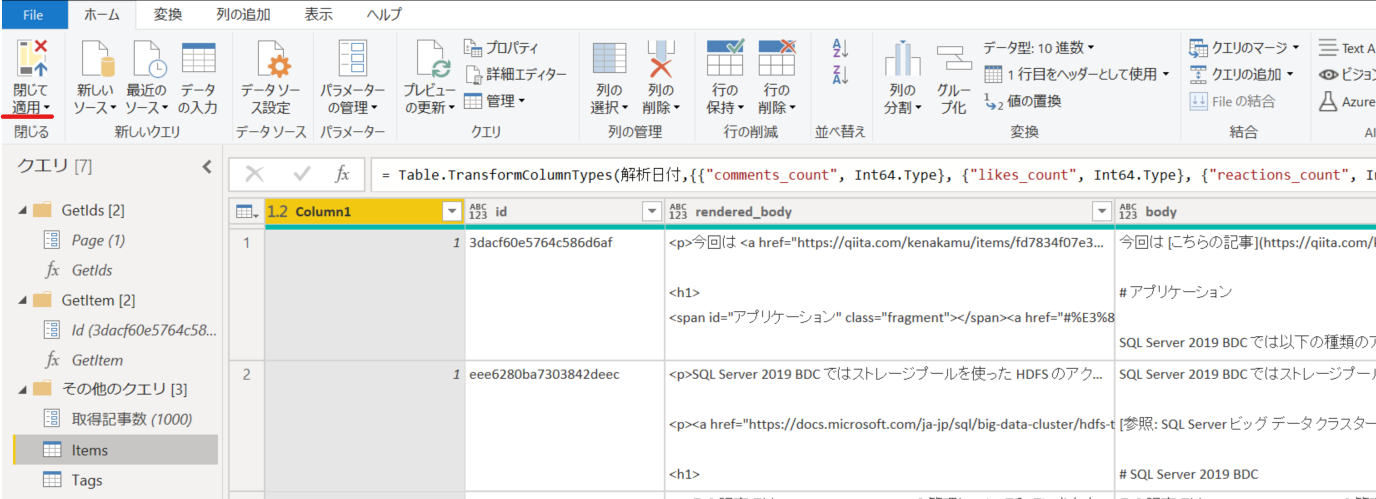
最終的に Items クエリは以下のようになりました。
let
ソース = List.Generate(()=>取得記事数, each _> 0, each _-100),
テーブルに変換済み = Table.FromList(ソース, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
除算済みの列 = Table.TransformColumns(テーブルに変換済み, {{"Column1", each _ / 100, type number}}),
並べ替えられた行 = Table.Sort(除算済みの列,{{"Column1", Order.Ascending}}),
呼び出されたカスタム関数 = Table.AddColumn(並べ替えられた行, "GetIds", each GetIds([Column1])),
削除されたエラー = Table.RemoveRowsWithErrors(呼び出されたカスタム関数, {"GetIds"}),
#"展開された GetIds" = Table.ExpandTableColumn(削除されたエラー, "GetIds", {"id"}, {"id"}),
呼び出されたカスタム関数1 = Table.AddColumn(#"展開された GetIds", "GetItem", each GetItem([id])),
#"展開された GetItem" = Table.ExpandRecordColumn(呼び出されたカスタム関数1, "GetItem", {"rendered_body", "body", "comments_count", "created_at", "likes_count", "reactions_count", "tags", "title", "updated_at", "url", "page_views_count"}, {"rendered_body", "body", "comments_count", "created_at", "likes_count", "reactions_count", "tags", "title", "updated_at", "url", "page_views_count"}),
解析日付 = Table.TransformColumns(#"展開された GetItem",{{"created_at", each Date.From(DateTimeZone.From(_)), type date}, {"updated_at", each Date.From(DateTimeZone.From(_)), type date}}),
変更された型 = Table.TransformColumnTypes(解析日付,{{"comments_count", Int64.Type}, {"likes_count", Int64.Type}, {"reactions_count", Int64.Type}, {"page_views_count", Int64.Type}})
in
変更された型
レポートの作成
データの準備ができたので適当にレポートを作ります。
1.「折れ線グラフおよび積み上げ縦棒グラフ」を選択。
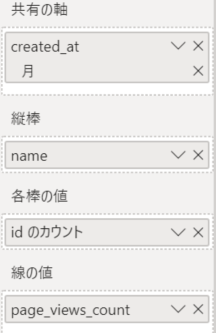
2. 各種プロパティを設定。
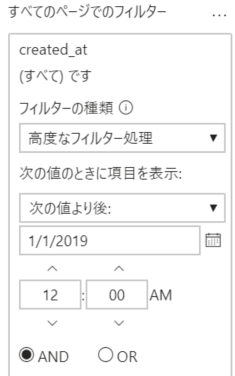
3. すべてのページでのフィルターに created_at を追加して、2019/1/1 以降を指定。
4. ビジュアルを見ながらプロパティを適当に調整。
ここから後は好きにどうぞ。
M 言語だけで書くと簡単?
やり方はいくつかありますが、もともとやっていた方法だと Id 取得までは以下のような感じで、この後、レコード詳細を取得するなどの処理が続きます。
let
Options = [Headers=[Authorization="Bearer <Access_Token>"]],
GetItem = (id as text) =>
let
data = Json.Document(Web.Contents("https://qiita.com/api/v2/items/"& id, Options))
in
data,
GetItemsWithPage = (page as number) =>
let
data = Web.Contents("https://qiita.com/api/v2/authenticated_user/items?per_page=100&page=" & Number.ToText(page), Options),
result =
if Json.Document(data) = null
then error "no records"
else data
in
result,
ItemLlist = List.Generate(
()=>[Page=2, Func = GetItemsWithPage(1)],
each (try [Func])[HasError] = false,
each [Page = [Page] + 1, Func=GetItemsWithPage([Page])],
each [Func]
),
ItemLlists = List.Transform(ItemLlist, (_) => Json.Document(_)),
AllItems = Table.FromList(List.Combine(ItemLlists), Splitter.SplitByNothing(), null, null, ExtraValues.Error),
Ids = Table.ExpandRecordColumn(AllItems, "Column1", {"id"}, {"id"}),
Details = Table.AddColumn(Ids, "GetItem", each GetItem([id])),
ExpandColumns = Table.ExpandRecordColumn(Details, "GetItem", {"rendered_body", "body", "comments_count", "created_at", "likes_count", "reactions_count", "tags", "title", "updated_at", "url", "page_views_count"}, {"rendered_body", "body", "comments_count", "created_at", "likes_count", "reactions_count", "tags", "title", "updated_at", "url", "page_views_count"})
in
ExpandColumns
上記のクエリでレコード詳細まではとれます。
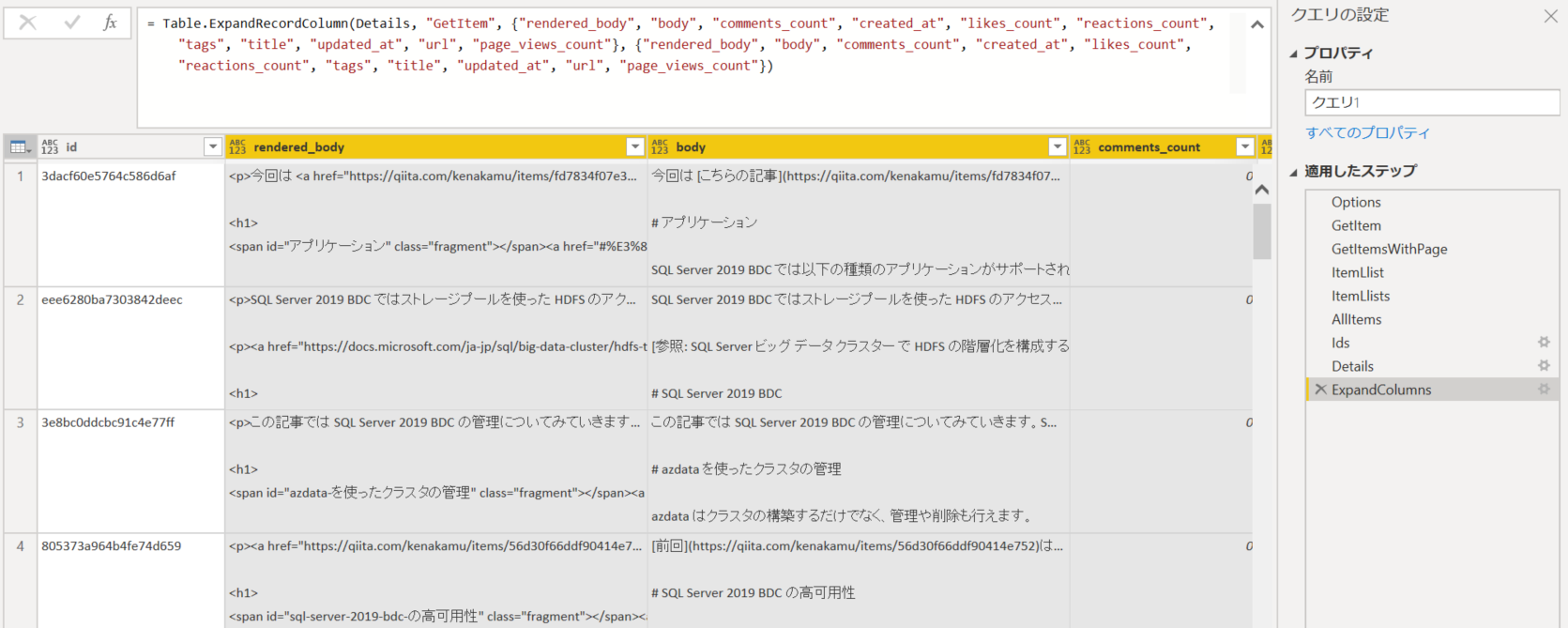
少しだけ List.Generate の使い方や変数の意味など理解する必要はありますが、コードをよく見ればできると思います。尚、呼び出す API 側の仕様によって、処理継続の判定なども変わってきますので、そのあたりは工夫が必要です。
まとめ
Qiita のコネクタあればそれでいいんですが、今回はあえていくつかの機能も紹介する体で記事を書いてみました。
- Web コネクタとヘッダーの指定
- List.Generate 関数
- パラメーターの利用
- カスタム関数の作成
- 列の追加でのカスタム関数の利用
- データ変換
まだ無駄はあるので、是非最適化してください。あと「いいね」が少なくて寂しいのでよろしくお願いします。