Introduction to Heuristics Contestに参加しました。こういったマラソンマッチと呼ばれるコンテストへの参加は初めてでしたがビギナーズラックで42位となかなかいい順位だったので記念に書き残しておきたいと思います。
参加にあたって
参加するにあたってマラソンマッチについて知識がほとんど存在しなかったので@tsukammoさんのqiitaの記事をとりあえず一通り読みました。すべてが理解できたわけではないですが、tsukammoさんの記事の中では分布が可視化されていたり考え方が段階を踏んで書かれていたりとわかりやすかったです。ただ、ビームサーチやchokudaiサーチといった知らないアルゴリズムが出てきたので一応調べたりして雰囲気は把握したのですが結局自分でプログラムが書けたのは焼きなましだけでした。その後、プログラムの改善について参考になりそうな誰でもできる焼きなまし法という記事も読んでおきました。
本番
本番ではA,B,C問題がありB,C問題はさらっと眺めた感じ出力形式と貪欲で解くヒントみたいな感じだったのでまあいいやと思って飛ばしました。
A問題
最初にとりあえず出力形式が自分の認識と合っているかを確認するために1,2,3...25,26,1,2,...という風に順番に出力するだけのプログラムを書きました。次に山登り方を実装しました。これは適当に答えを変化させて改善されていたら更新するという単純なものです。この時の評価関数はとりあえず一から計算するものにしました。解の変化のさせ方は一か所をランダムに別の値に変えるという単純なものです。別の日のものと交換する、ランダムではなく1だけ動かすというのも考えたんですが別の日のと交換すると個数が変わらなくなってしまう、1だけ動かすとすべてが均一に動いてしまい局所解に陥りそうだなと直観的に思ったのでランダムに変更することにしました。
次に山登り法を焼きなまし法に改変しました。これは改善していなくてもある確率で遷移をし、その確率を徐々に小さくするというものです。この時点での全体像はこれです。
uniform_real_distribution<> dist(0.0, 1.0);
float judge(float p, mt19937& engine) {
float f = dist(engine);
return p >= f;
}
float prob(float delta, float tmp) {
return exp(delta / tmp);
}
int cost(vector<vector<int>>& s, vector<int>& c, vector<int>& ls) {
int result = 0;
vector<int> prev(26,-1);
rep(i, 0, ls.size()) {
prev[ls[i]] = i;
result += s[i][ls[i]];
rep(j, 0, 26) {
result -= c[j] * (i - prev[j]);
}
}
return result;
}
int main() {
// ↓この2行が追加部分
std::ios::sync_with_stdio(false);
std::cin.tie(0);
random_device seed_gen;
mt19937 engine(seed_gen());
int d;
cin >> d;
int con = 0;
vector<int> c(26);
vector<vector<int>> s(d, vector<int>(26));
rep(i, 0, 26) {
cin >> c[i];
}
rep(i, 0, d) {
rep(j, 0, 26) {
cin >> s[i][j];
}
}
// 初期化
vector<int> ls(d);
rep(i, 0, d) {
ls[i] = con;
++con;
con %= 26;
}
int now_cost = cost(s,c,ls);
for (int tmp = 20000; tmp > 10; tmp -= 100) {
rep(j, 0, d) {
int ra = rand() % 24 + 1,val = ls[j];
ls[j] = (ls[j] + ra) % 26;
int cos = cost(s, c, ls);
float p = prob(cos - now_cost, tmp);
if (judge(p,engine)) {
now_cost = cos;
}
else {
ls[j] = val;
}
}
}
rep(i, 0, d) {
printf("%d\n", ls[i] + 1);
}
}
ここで、評価関数の計算量を落とすことを考えました。ボトルネックである評価関数の計算量が落ちれば計算できる回数が増えるので探索できる範囲が増えて良い解にたどり着きやすくなります。今までの評価関数はすべてを最初から計算していましたが、変更するコンテストと変更されるコンテスト以外は今までと同じ値を使用しても差し支えないと考えたので以下のように変更しました。
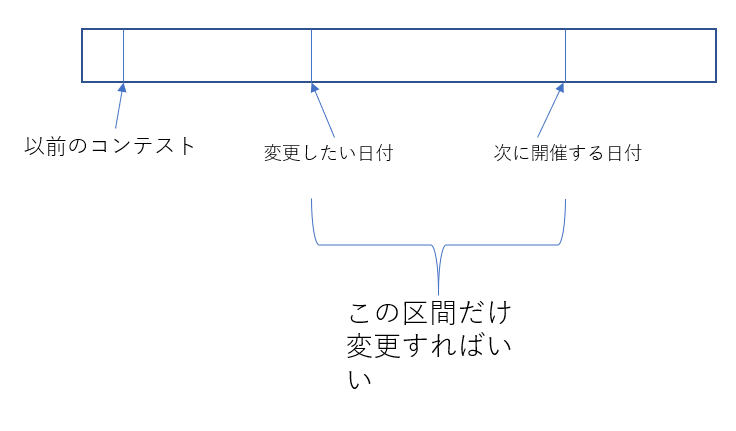
/*
prevLs <- 変更前の解
prev_cost <- 変更前のコスト
day <- 変更する日付
new_val <- 更新したい値
*/
int cost2(vector<vector<int>>& s, vector<int>& c,vector<int> &prevLs, int prev_cost,int day,int new_val) {
int result = prev_cost;
vector<int> prev(26, -1);
result -= s[day][prevLs[day]];
int mae = -1; // 以前コンテストが行われた日付
for (int i = day - 1; i >= 0; --i) {
if (prevLs[i] == prevLs[day]) {
mae = i;
break;
}
}
result -= c[prevLs[day]] * (day - mae);
for (int i = day+1; i < prevLs.size(); ++i) {
// 次にコンテストが開かれるまでの区間を変更
if (prevLs[day] != prevLs[i]) {
result += c[prevLs[day]] * (i - day);
result -= c[prevLs[day]] * (i - mae);
}
else {
break;
}
}
result += s[day][new_val];
mae = -1;
for (int i = day - 1; i >= 0; --i) {
if (prevLs[i] == new_val) {
mae = i;
break;
}
}
result += c[new_val] * (day - mae);
for (int i = day + 1; i < prevLs.size(); ++i) {
if (new_val != prevLs[i]) {
result -= c[new_val] * (i - day);
result += c[new_val] * (i - mae);
}
else {
break;
}
}
return result;
}
自分がそれっぽい工夫ができなのはここまでになります。その後はパラメータの調整をただただやりました。ただ、自動的に入力を生成して評価するという感じのプログラムが組めなかったので上がりそうな感じに変更してsubmitをただただやりました。
反省点
まず、評価関数の計算量をもっと減らせたようです。また、手元の環境で入力サンプルを生成して検証するといったこともできませんでした。次のコンテストまでに環境を構築しておきたいです。それ以外にもいろいろありますが公式解説がとても丁寧で知らないことがたくさん載っているので勉強していきたいと思います。