この記事は前回Go言語でニューラルネットワークのスクラッチ実装の続きです。
前回、Go言語でニューラルネットワークを行列計算から作ってXORの非線形分類をやってみました。ただこれだと正直人間でも重みをイイ感じに設定すれば簡単にできてしまうのでどうにもニューラルネットワーク感がないなあと思いました。そこで、機械学習を使わないとコンピュータに処理させれなさそうで、かつすでに手法が存在して必ず成功するものはないかなと思ったところ、MNISTの手書き文字の分類をやればいいじゃないか!と思ったのでそれをやってみることにしました。
データの用意
機械学習と言ってもまずはデータがないと何もできません。今回は上にも書いたようにMNIST手書き文字のデータを使います。
データのダウンロード
THE MNIST DATABASE
of handwritten digits
このサイトからダウンロードできます。

こんな感じの所があるのでポチポチダウンロードしてきます。上から学習用画像、学習用教師データ、テスト用画像、テスト用教師データです。
ダウンロードしてきたら解凍して適当なフォルダに入れてください。ここで、ダウンロードのページの下の方に行くとこのような記述があります。
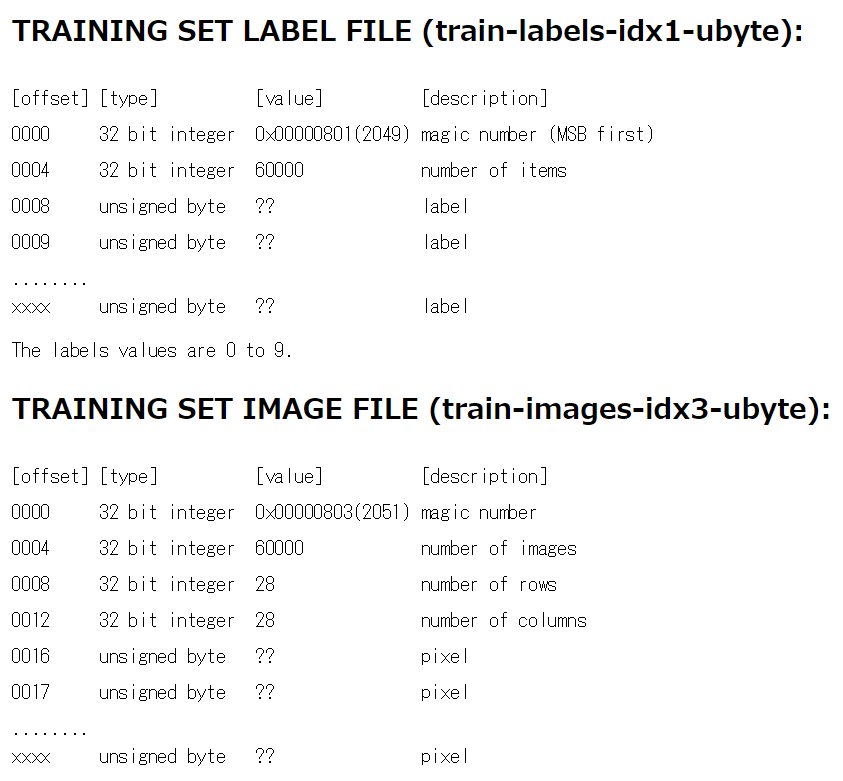
これは、先ほどダウンロードしてきたデータがどのような構造で保存されているかがかかれています。上はラベルファイル、つまり教師データです。これは最初の64bitには教師データではない情報が含まれていることがわかります。下はトレーニングデータです。これは最初の128bitは機械学習には必要のないデータが含まれています。
データの読み込み
ここで用意したデータを読み込みます。まずはトレーニングデータの画像の読み込みをします。画像のサイズは28×28なので最終的に[60000][28][28]のスライスを返すように実装します。
func GetTrainImg() [][][]int{
// ファイルをOpenする
f, err := os.Open("C:\\hoge\\hoge\\train-images-idx3-ubyte")
// 読み取り時の例外処理
if err != nil{
fmt.Println("error")
}
// 関数が終了した際に確実に閉じるようにする
defer f.Close()
// バイト型スライスの作成
buf := make([]byte, 60000 * 28 * 28 + 16)
// nはバイト数を示す
n, err := f.Read(buf)
// バイト数が0になることは、読み取り終了を示す
if n == 0{
os.Exit(1)
}
if err != nil{
os.Exit(1)
}
imgs := make([][][]int,60000)
counter := 16
for i:=0;i<60000;i++{
imgs[i] = make([][]int,28)
for j:=0;j<28;j++{
imgs[i][j] = make([]int,28)
for k:=0;k<28;k++{
imgs[i][j][k] = int(buf[counter])
counter ++
}
}
}
return imgs
}
次にトレーニングデータの教師データを読み込みます。
func GetTrainLabel() []int{
// ファイルをOpenする
f, err := os.Open("C:\\hoge\\hoge\\train-labels-idx1-ubyte")
// 読み取り時の例外処理
if err != nil{
fmt.Println("error")
}
// 関数が終了した際に確実に閉じるようにする
defer f.Close()
// バイト型スライスの作成
buf := make([]byte, 60008)
// nはバイト数を示す
n, err := f.Read(buf)
// バイト数が0になることは、読み取り終了を示す
if n == 0{
os.Exit(1)
}
if err != nil{
os.Exit(1)
}
//データを格納するスライス
label := make([]int,60000)
// バイト型を数字に変換してスライスに入れる
for i:=8;i<len(buf);i++{
label[i-8] = int(buf[i])
}
return label
}
テストデータに関しては読み込み用のバッファを10008に、データを格納するスライスを10000にしてそれ用の関数を作ります。
//テストデータの画像を読み込む
func GetTestImg() [][][]int{
//上の感じで実装してください
}
//テストデータの教師データを読み込む
func GetTestLabel() []int{
//上の感じで実装してください
}
データの整形
画像データは二次元です。ですが機械学習にぶち込むときは一次元にしなければなりません。ですので、28×28の画像を784のベクトルに変換します。
//データ数*28*28のスライスをデータ数*784にする
func ReduceDimention(data [][][]int) [][]float64{
ans := matrix.MakeMatrix(len(data),28*28)
for i:=0;i<len(data);i++{
for j:=0;j<28;j++{
for k:=0;k<28;k++{
ans[i][j*28+k] = float64(data[i][j][k]) / 255.0
}
}
}
return ans
}
次に、教師データは0~9までの数字が入っていますが、これもニューラルネットワークの関係上onehotencodeingというものを施してあげて10この要素の中で一つだけ1が入っているベクトルにします。
func Onehotencoding(data []int) [][]float64{
ans := matrix.MakeMatrix(len(data),10)
for i:=0;i<len(data);i++{
ans[i][data[i]] = 1.0
}
return ans
}
今回は確率的勾配法というのを用います。なにぶん訓練データが6万もあるのですべてでいっぺんに学習していると時間がかかってしまいます。ですのでいくつかの塊にランダムに分割してそれを学習するということをすることをします。インデックスを並び替えるのはFisher-Yatesアルゴリズムなるものを使いました。
//0からn-1までの数字をランダムに並べる
//Fisher-Yatesアルゴリズム(たぶん)
func Shuffle(n int) []int{
rand.Seed(time.Now().UnixNano())
ls := make([]int,n)
for i:=0;i<n;i++{
ls[i] = i
}
for i := len(ls)-1;i>=0;i--{
j := rand.Intn(i + 1)
ls[i], ls[j] = ls[j], ls[i]
}
return ls
}
//バッチサイズで分割 nはデータ数を割り切れる数にしてほしい
func SplitData(n int,data [][]float64,label [][]float64) ([][][]float64 ,[][][]float64){
ans := make([][][]float64,len(data)/n)
anslabel := make([][][]float64,len(data)/n)
for i:=0;i<len(ans);i++{
ans[i] = make([][]float64,n)
anslabel[i] = make([][]float64,n)
for j:=0;j<len(ans[0]);j++{
ans[i][j] = make([]float64,len(data[0]))
anslabel[i][j] = make([]float64,len(label[0]))
}
}
indexes := Shuffle(len(data))
count := 0
for i:=0;i<len(ans);i++{
for j:=0;j<len(ans[0]);j++{
for k:=0;k<len(data[0]);k++{
ans[i][j][k] = data[indexes[count]][k]
//fmt.Print(data[indexes[count]][k])
if i == 0 && j == 0 {
//fmt.Print(data[indexes[count]][k], " ")
}
}
for k:=0;k<len(anslabel[0][0]);k++{
anslabel[i][j][k] = label[indexes[count]][k]
}
count ++
}
}
return ans,anslabel
}
行列計算の実装
行列計算の実装は...しません!前回の記事で使ったものを流用します。ただ、プログラムがすごく長くなってしまったので別のファイルに移しました。
package matrix
import
(
"os"
"math"
"math/rand"
"time"
)
//大きい値を出力
func Max(a float64,b float64) float64{
if a > b{return a} else{return b}
}
//行列を生成
func MakeMatrix(i int,j int) [][]float64{
}
//行列を合計
func Add(a [][]float64,b [][]float64) [][]float64{
}
//アダマール積
func AdaMul(a [][]float64,b [][]float64) [][]float64{
}
//行列の積
func Multi(a [][]float64,b [][]float64) [][]float64{
}
//行列に定数を加算
func ConstAdd(n float64,mat [][]float64) [][]float64{
}
//行列を定数倍
func ConstMult(n float64,matrix [][]float64) [][]float64{
}
//行列の転置
func Trans(a [][]float64) [][]float64{
}
//行列にベクトルを足し算
/*
[[1,2,3], [[1+1,1+2,1+3],
[4,5,6], + [[1,1,4]] = [4+1,5+1,6+3],
[7,8,9]] [7+1,8+1,9+3]]
*/
func AddVector(mat [][]float64,vec [][]float64) [][]float64{
}
//要素1、大きさ1行n列のベクトルとの内積つまり、列方向の合計
func VecMul(mat [][]float64) [][]float64{
}
//シグモイド関数
func Sigmoid(x [][]float64) [][]float64{
}
//シグモイド関数の微分(出力された値を引数に入れる)
func DiffSigmoid(x [][]float64) [][]float64{
}
//ソフトマックス関数
func Softmax(x [][]float64) [][]float64{
}
//二乗誤差
func Square(y [][]float64,t [][]float64) float64 {
}
//乱数を発生
func random(min, max float64,seed int) float64 {
}
//i*jの中身0~1の乱数の行列を生成
func MakeWight(i int,j int) [][]float64{
}
これだけの関数をmatrix.goに移します。
ニューラルネットワークを実装
ここからニューラルネットワークを実装していきたいと思います。まず、今回と前回との違いは、入力層の数が違うことです。前回は入力層は2でしたが、今回は28×28=784層の入力層を使います。さらに、データ数が6万もあるので少し複雑にしてよいかなとおもって、中間層を二層にしてそれぞれ64層のネットワークを構成しました。
順伝搬の変更
//変数を四層分用意
var w1_1,w1_0,w2_1,w2_0,w3_1,w3_0,layer_z1,layer_a1,layer_z2,layer_a2,layer_z3,layer_a3,dw1,db1,dw2,db2,dw3,db3 [][]float64
var costList []float64
//重みの初期化
func initValue(){
//データの次元数
dim := 28*28
//中間層1のノードの数
midNode := 64
//中間層2のノード数
midNode2:= 64
//出力層のノード数
finNode := 10
//入力層から中間層1への重み
w1_1 = matrix.MakeWight(dim,midNode)
//入力層から中間層1へのかけ合わせないやつ
w1_0 = matrix.MakeWight(1,midNode)
//中間層1から中間層2への重み
w2_1 = matrix.MakeWight(midNode,midNode2)
//中間層1から中間層2へのかけ合わせないやつ
w2_0 = matrix.MakeWight(1,midNode2)
//中間層から出力層への重み
w3_1 = matrix.MakeWight(midNode2,finNode)
//中間層から出力層へのかけ合わせないやつ
w3_0 = matrix.MakeWight(1,finNode)
}
//順伝搬
func forward(data [][]float64) [][]float64{
//入力から中間層1
layer_z1 = matrix.AddVector(matrix.Multi(data,w1_1),w1_0)
layer_a1 = matrix.Sigmoid(layer_z1)
//中間層1から中間層2
layer_z2 = matrix.AddVector(matrix.Multi(layer_a1,w2_1), w2_0)
layer_a2 = matrix.Sigmoid(layer_z2)
//中間層2から出力層
layer_z3 = matrix.AddVector(matrix.Multi(layer_a2,w3_1), w3_0)
layer_a3 = matrix.Softmax(layer_z3)
return layer_a3
}
逆伝搬
前回、出力層ー中間層間の微分が謎な関数が大量につながっていたんですけど、それやっぱ間違ってたっぽくて、交差エントロピー誤差の微分にしました。交差エントロピー誤差とソフトマックス関数の微分、引き算だけでできるの本当に世の中うまくできてるなと思いました。
func back(x [][]float64,y [][]float64){
//中間層2-出力層の重みでの微分を求める
output_delta := matrix.Add(layer_a3,matrix.ConstMult(-1,y))
dw3 = matrix.Multi(matrix.Trans(layer_a2),output_delta)
db3 = matrix.VecMul(output_delta)
//中間層1-中間層2の重みで微分を求める
mid2_delta := matrix.AdaMul(matrix.Multi(output_delta,matrix.Trans(w3_1)),matrix.DiffSigmoid(layer_a2))
dw2 = matrix.Multi(matrix.Trans(layer_a1),mid2_delta)
db2 = matrix.VecMul(mid2_delta)
//入力層-中間層の重みでの微分を求める
mid_delta := matrix.AdaMul(matrix.Multi(mid2_delta,matrix.Trans(w2_1)),matrix.DiffSigmoid(layer_a1))
dw1 = matrix.Multi(matrix.Trans(x),mid_delta)
db1 = matrix.VecMul(mid_delta)
}
変数が増えたので重みの更新もたくさん書いてあげます。
func update(alpha float64){
w1_1 = matrix.Add(w1_1,matrix.ConstMult(-alpha,dw1))
w1_0 = matrix.Add(w1_0,matrix.ConstMult(-alpha,db1))
w2_1 = matrix.Add(w2_1,matrix.ConstMult(-alpha,dw2))
w2_0 = matrix.Add(w2_0,matrix.ConstMult(-alpha,db2))
w3_1 = matrix.Add(w3_1,matrix.ConstMult(-alpha,dw3))
w3_0 = matrix.Add(w3_0,matrix.ConstMult(-alpha,db3))
}
精度測定用の関数
出力された予測の何パーセントが正しい出力かを計算する関数を実装します。出力される値はそれぞれの数字の確率なので一番大きな確率の数字と教師データと比較します。
func accuracy(data [][]float64,label []int) float64{
acc := 0
for i:=0;i<len(data);i++{
max := 0.0
num := 0
for j:=0;j<10;j++{
if data[i][j] > max{
max = data[i][j]
num = j
}
}
if label[i] == num{
acc ++
}
}
return float64(acc)/float64(len(label))
}
main関数の実装
func main(){
//変数の初期化
initValue()
//トレーニングデータの画像を読み込み
data := dataclean.ReduceDimention(getmnist.GetTrainImg())
//トレーニングデータの教師データを読み込み
label := dataclean.Onehotencoding(getmnist.GetTrainLabel())
//エポック
epoc := 10
//確率的勾配法
for i:=0;i<epoc;i++{
//データを100個ずつに分割
t,l := dataclean.SplitData(100,data,label)
count := 0
costsum := 0.0
for j:=0;j<len(t);j++{
x := t[j]
y := l[j]
//学習
train(x,y,0.1,1)
count ++
a := cost(layer_a3,y)
costsum += a
if a == math.NaN(){
i = epoc
break
}
//コストを記録
if count % 10 == 0{
costList = append(costList,costsum)
//fmt.Println(costList[len(costList)-1])
costsum = 0.0
count = 0
}
}
}
//テストデータでを予測
output := forward(dataclean.ReduceDimention(getmnist.GetTestImg()))
//テストデータの教師データを読み込み
la := getmnist.GetTestLabel()
//精度を出力
fmt.Println(accuracy(output,la))
//以下、コスト関数の推移をテキストファイルに記録する処理
file, _ := os.Create(`C:\\hoge\\grade.txt`)
defer file.Close()
for i:=0;i<len(costList);i++{
output := []byte(strconv.FormatFloat(costList[i], 'f', 15, 64) + " ")
file.Write(([]byte)(output))
}
}
結果
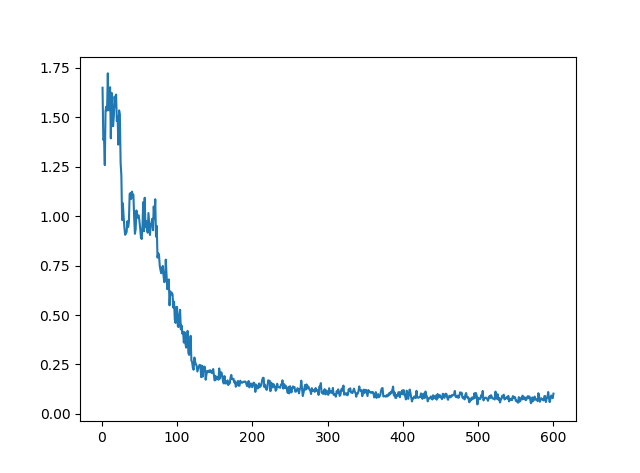
最も精度が良かったepoc数は10程度でした。それ以上いくと過学習を起こしました。
| epoc | accuracy |
|---|---|
| 8 | 0.9389 |
| 10 | 0.9459 |
| 15 | 0.9173 |
| 20 | 0.9293 |
epoc=10の誤差の推移
最後に
こうやってちょっと複雑なモデルを作ってると前回のように単純なものでは気づけなかった間違いに気づくことができました。ここまで来たら、CNNを実装してみたいので次はCNN作ります。この記事での間違いとか指摘などあったら教えてください。お願いします。(実はテスト期間真っただ中なのでそろそろ勉強しなくては)