こんにちは。SRAの三島です。個人的に興味があるテーマの一つは画像解析です。画像解析ツールやクラウドサービス、ライブラリ、色々あるのですが、その中で AWS Rekognition を使ってみて分かったこと、感じたこと、などを書こうかと思います。
Amazon Rekognitionは、AWSが提供する画像および動画分析サービスです。このサービスは、機械学習を利用して画像や動画から情報を抽出し、以下のような用途に利用できます。
・顔認識と分析: 顔の検出、比較、属性の認識(例: 性別、年齢、感情など)。
・オブジェクトとシーンの検出: 画像や動画内のオブジェクト、シーン、アクティビティの識別。
・テキスト検出: 画像や動画内の印刷されたテキストや手書きテキストの認識。
・コンテンツモデレーション: 不適切なコンテンツの検出とフィルタリング。
・有名人の認識: 画像や動画内の有名人の識別。
既に学習済みのモデルを使って上記を行うだけではつまらないと思いまして、「カスタムラベル」という機能を使うと文字通りカスタマイズすることが出来ます。つまり、自分の定義したラベルを学習して、テスト画像からそのラベルを見つけ出す、という事ができるようになります。本記事では、廃基盤(使わなくなった基盤)から金属を再利用するためにコンデンサの数を数えるという例をやってみたいと思います。学習に使う画像は以下のようなものです。



1枚目の画像には、黒いコンデンサ(円柱の金属)が二つあります。また、2枚目の画像にも、オレンジのコンデンサが二つあります。これらの画像にはラベルを”2”と付けて学習したいです。3枚目の画像は黒いコンデンサが一つとオレンジのコンデンサが二つで合計三つなので、ラベルを"3"と付けて学習しようと思います。
Rekognitionを利用するためにはGUIで操作する方法とpythonのプログラムの中からAPIを叩く方法があります。本記事ではまずはGUIで実行する方法を説明します(別の記事ではAPIを叩く方法を解説したいと考えています。)。下の写真はRekognitionのトップ画面です。左側のメニューの「カスタムラベル」の下の「カスタムラベルを使用」をクリックします。
次にプロジェクトの画面を表示します。下の写真は私のプロジェクトの画面です。既に作成済みのプロジェクトが表示されます。(初めて使う人は何も表示されません。)
ここで、右側のオレンジ色のボタンの「プロジェクトを作成」のボタンを押します。
プロジェクトの名前を書き入れて、「プロジェクトを作成」ボタンを押します。ここでは「escrap-test1」と入れてみます。

4つのステップが表示されました。つまり、1.データセットを作成する、2.画像にラベルを付ける、3.モデルをトレーニングする、4.パフォーマンスメトリックスを確認する、です。この順番に実行していけば良いのです。まずは、「データセットを作成」ボタンを押します。
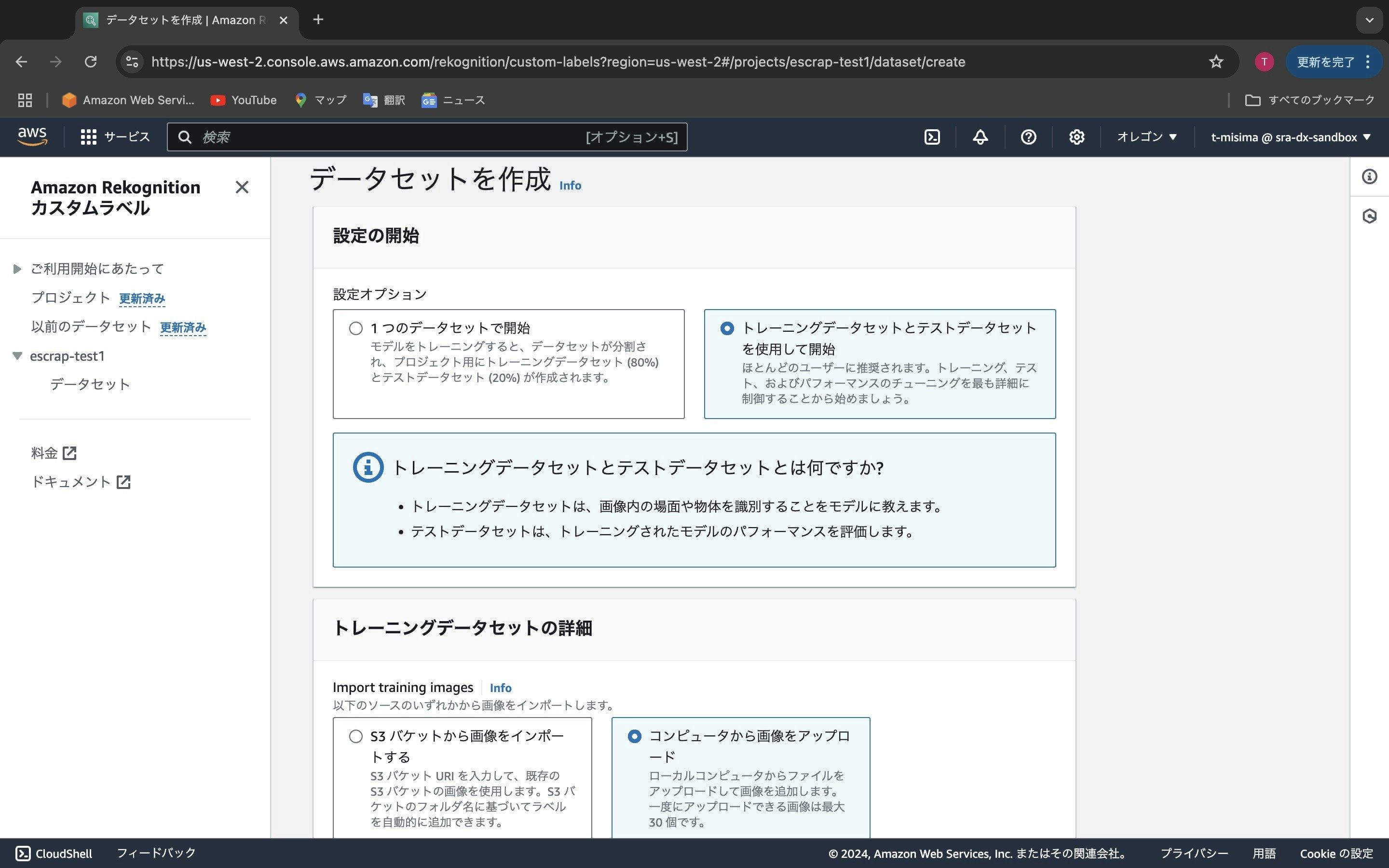
データはトレーニングデータセットとテストデータセットの2セットを用意する必要があります。なぜならば、トレーニングデータでモデルの学習を行い、テストデータでどれくらいの精度が達成するかを検証する必要があるからです。「1つのデータセットで開始」を選んでデータをアップロードすると、アップロードした画像のうち80%をトレーニングデータ、20%をテストデータに自動的に分割します。「トレーニングデータセットとテストデータセットを使用して開始」を選ぶと、トレーニングデータとテストデータのアップロードは別々に行います。ここでは後者の別々にアップロードする方を選びます。データをRekognitionにアップロードする方法は、「S3バケットから画像をインポートする」を選ぶと、S3に蓄積されているデータからデータをアップロードします。ということは、あらかじめS3にテストデータを蓄積しておく必要があります。「コンピュータから画像をアップロードする」を選ぶと、自身のローカルコンピュータから直接Rekognitionにデータをアップロードできます。ここでは後者の直接アップロードする方法を選択してみます(S3を使う方法は別の記事で説明する予定です。)。「データセットを作成」ボタンを押すと次の画面に移ります。

「トレーニング(0個)」と「テスト(0個)」と書いてあります。現段階ではトレーニングデータもテストデータも0個の状態です。画面をスクロールしてもらって「画像を追加」ボタンを押します。

この画面で、「upload_images_form.choose_files」ボタンを押します。
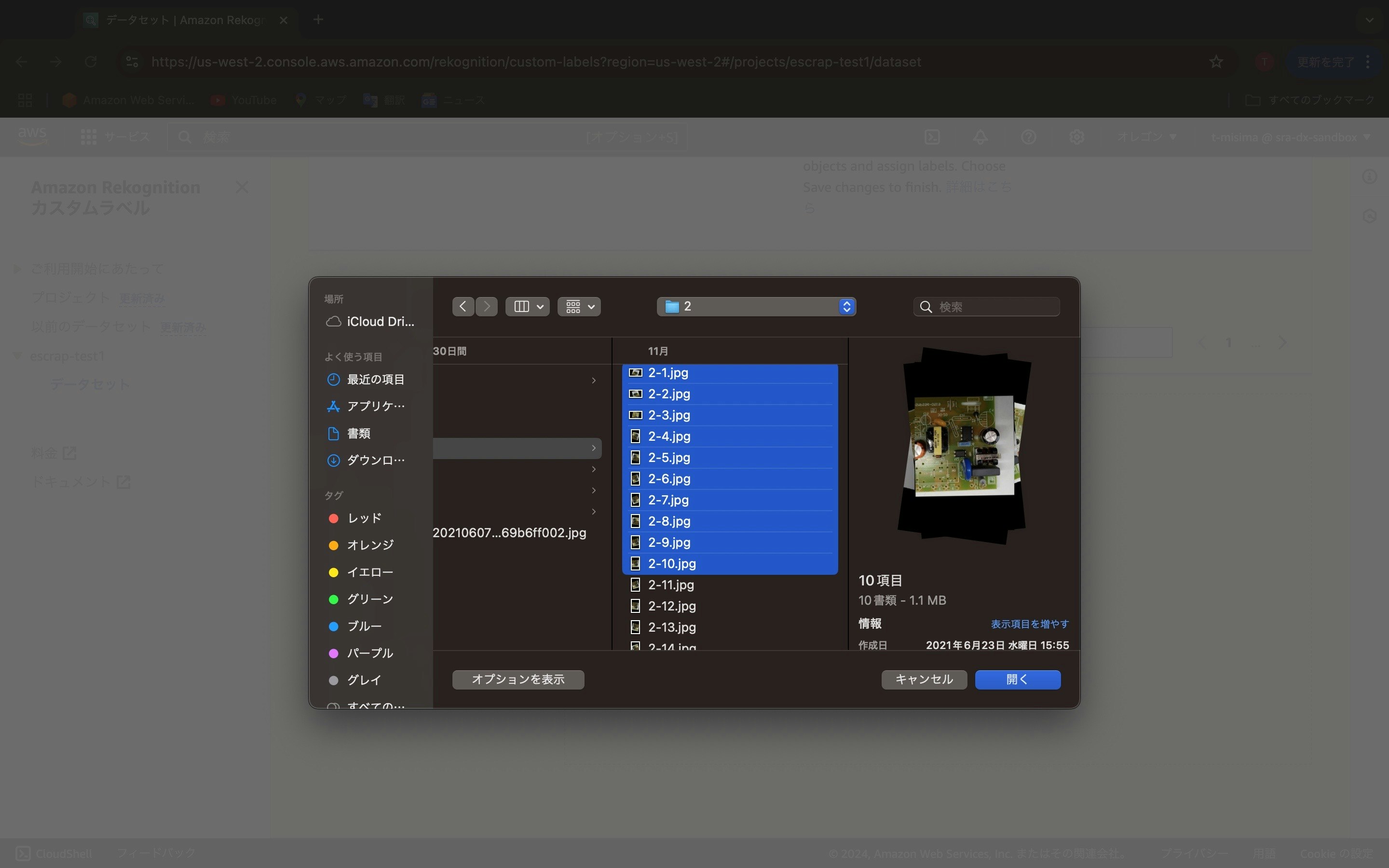
自分のローカルなパソコンのフォルダが表示されますので、アップロードしたいデータを選びます。この例では、2-1.jpg から2-10.jpg までの10枚の画像データを選んでいます。最大30個のデータを一度にアップロードできます。「開く」ボタンを押します。
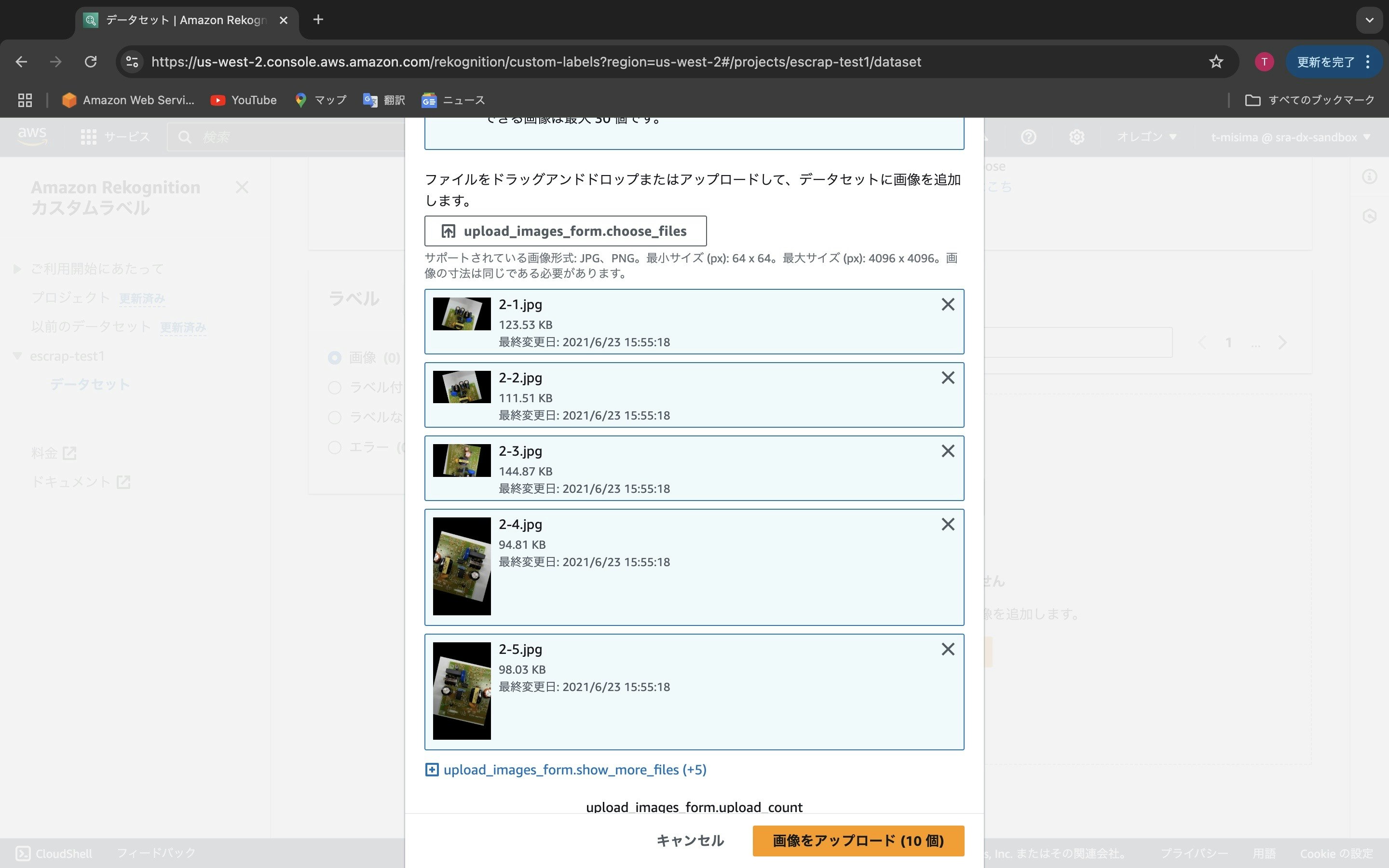
これらのデータをアップロードします、という確認画面が出ます。ここで「画像をアップロード」ボタンを押します。
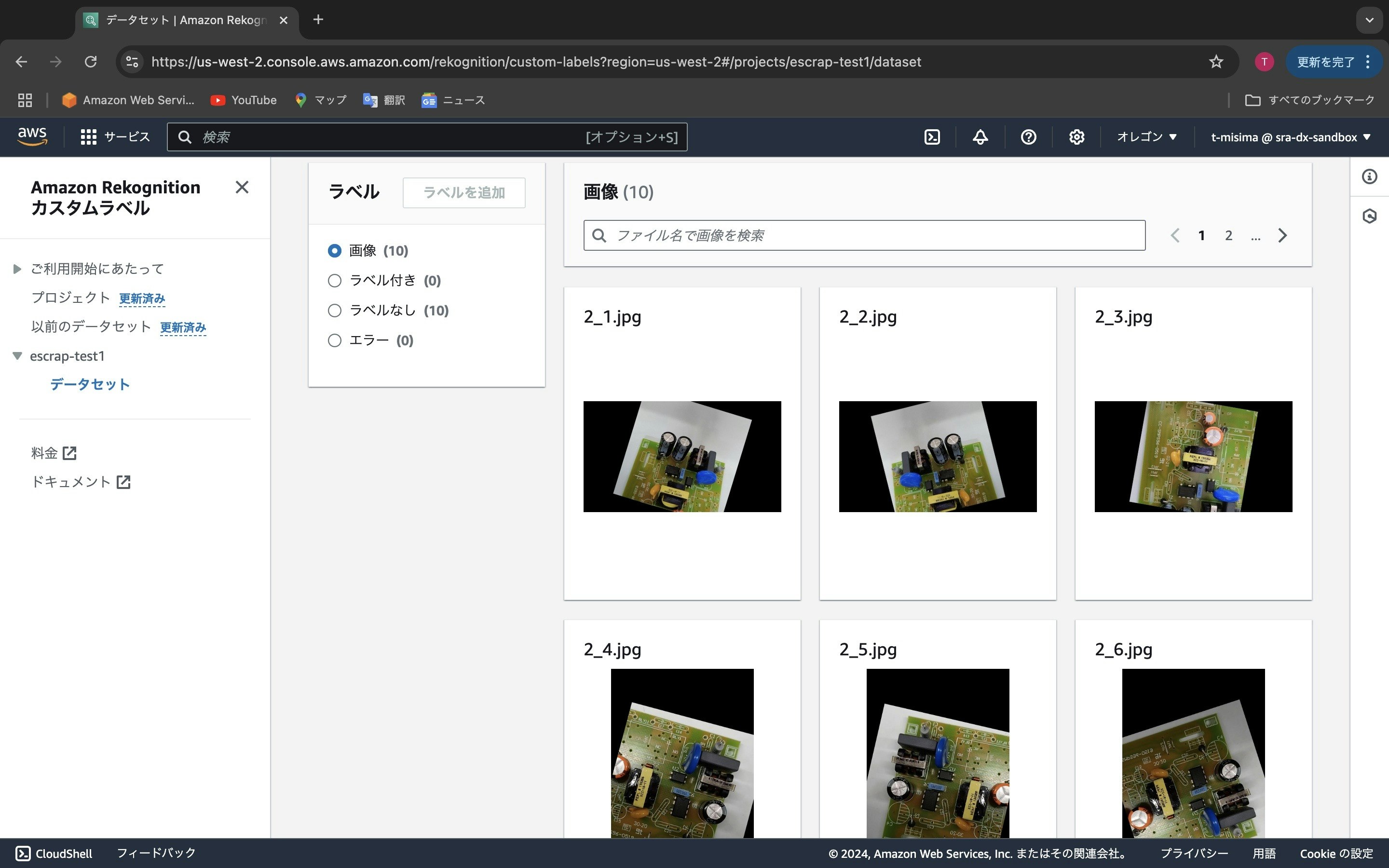
アップロードした画像が表示されます。ここで左側の「ラベル」を見ると、「ラベルなし」が10個あることを示しています。画面の上部にスクロースすると「ラベル付けを開始」というボタンがありますのでこれをクリックします。

「ラベルを追加」というボタンがアクティブになります。これをクリックします。
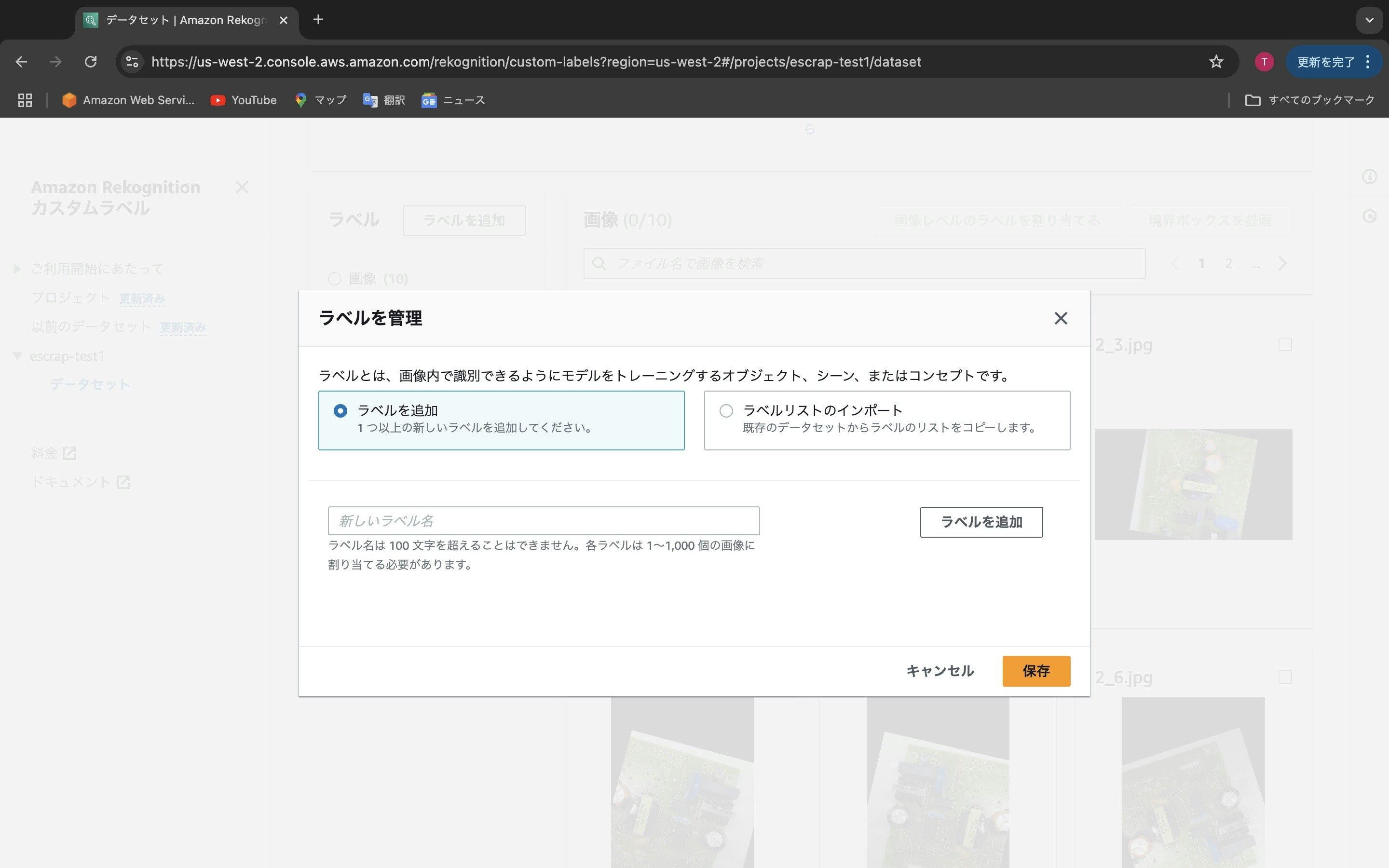
コンデンサが2個、3個、4個の場合を区別したいので、ここでは「2」「3」「4」という三つのラベルを追加します。
左側の「ラベル」の欄に「2」「3」「4」というラベルが出来上がっていることを確認できます。それぞれのラベルに紐づけられた画像ファイルはまだ一枚も無いため、全て「(0)」と表示されています。

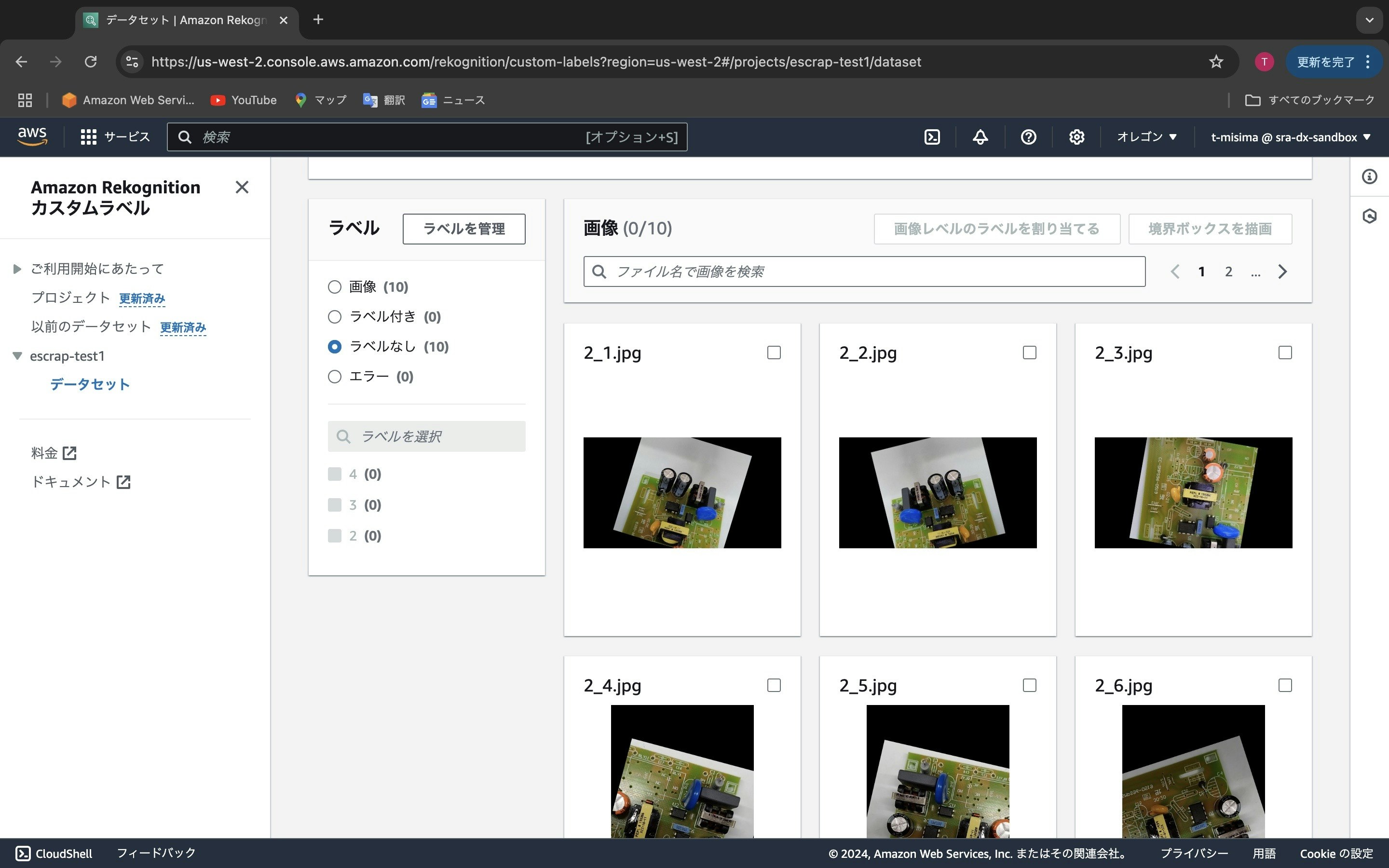
次にラベルを付けるのですが、一度に複数枚(最大9枚)の画像に一つのラベルを付けることが出来ます。ここでは先ほどアップロードした画像は全てコンデンサの数が2個であるので、チェックボックスにチェックを入れて「画像レベルのラベルを割り当てる」をクリックします。
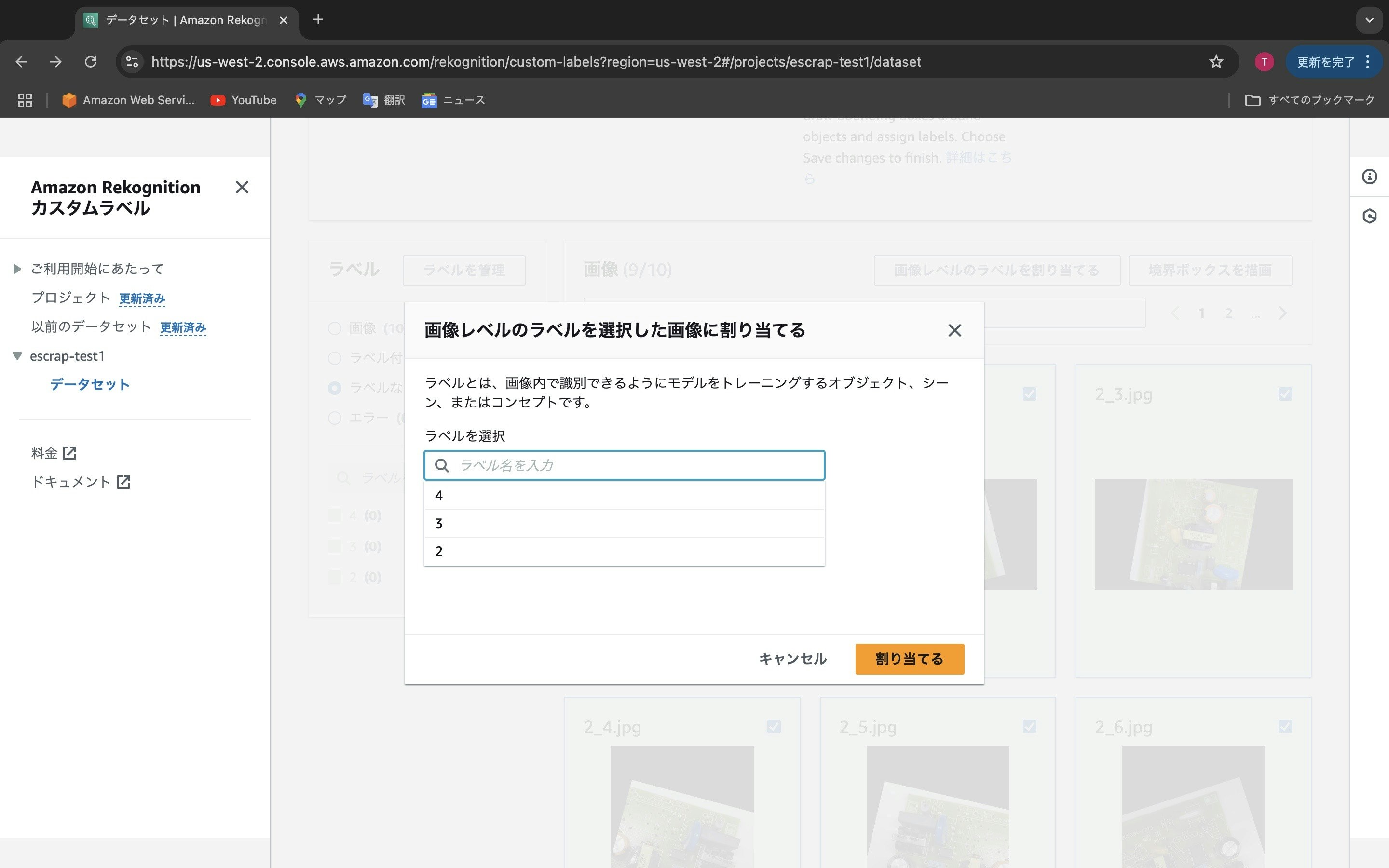
先ほど自分で作成したラベル「2」「3」「4」が表示されます。ここでは「2」を選択し「割り当てる」ボタンを押します。
「変更を保存」ボタンを押します。
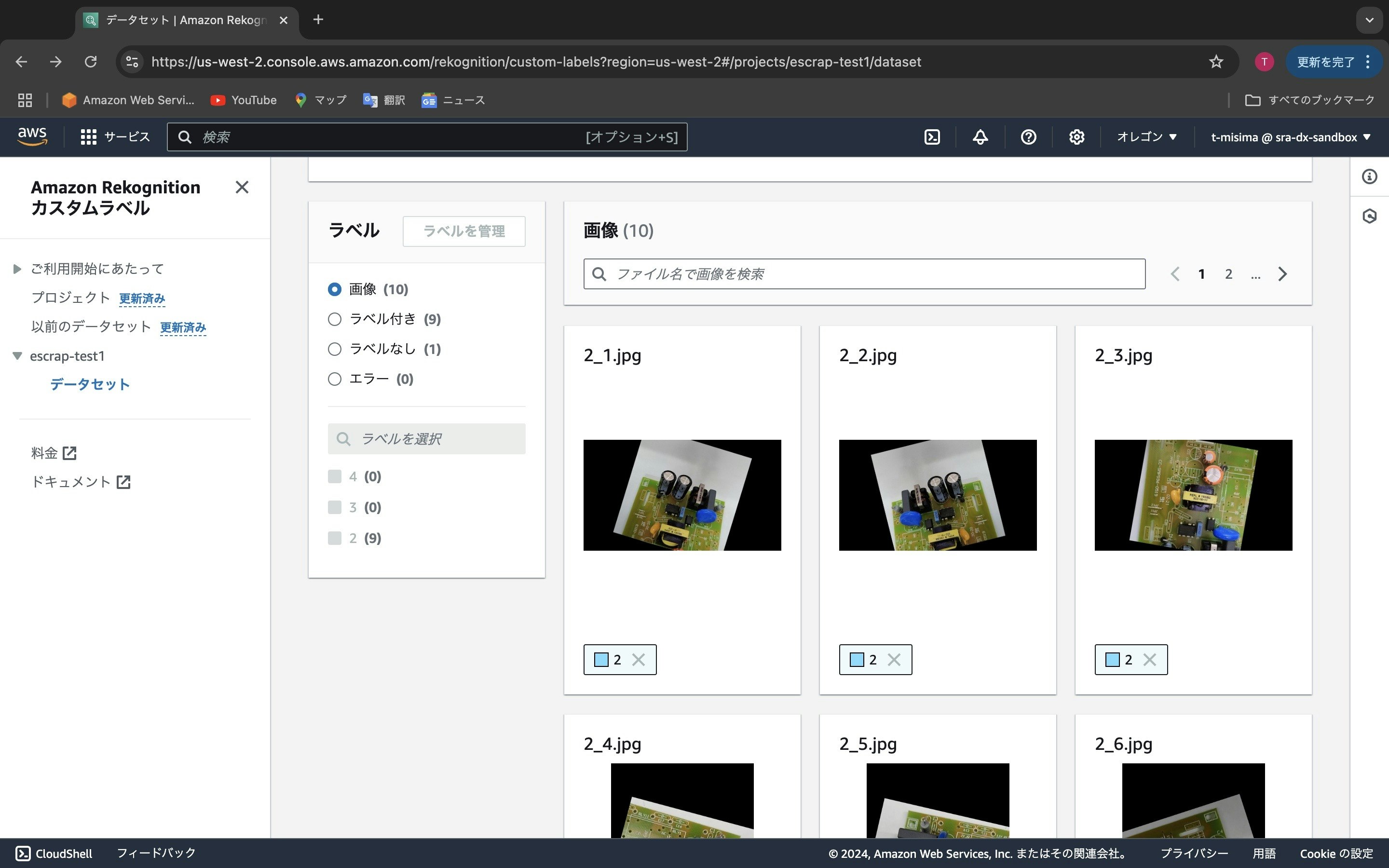
9枚の画像にラベル「2」が付与されました。この操作を繰り返します。
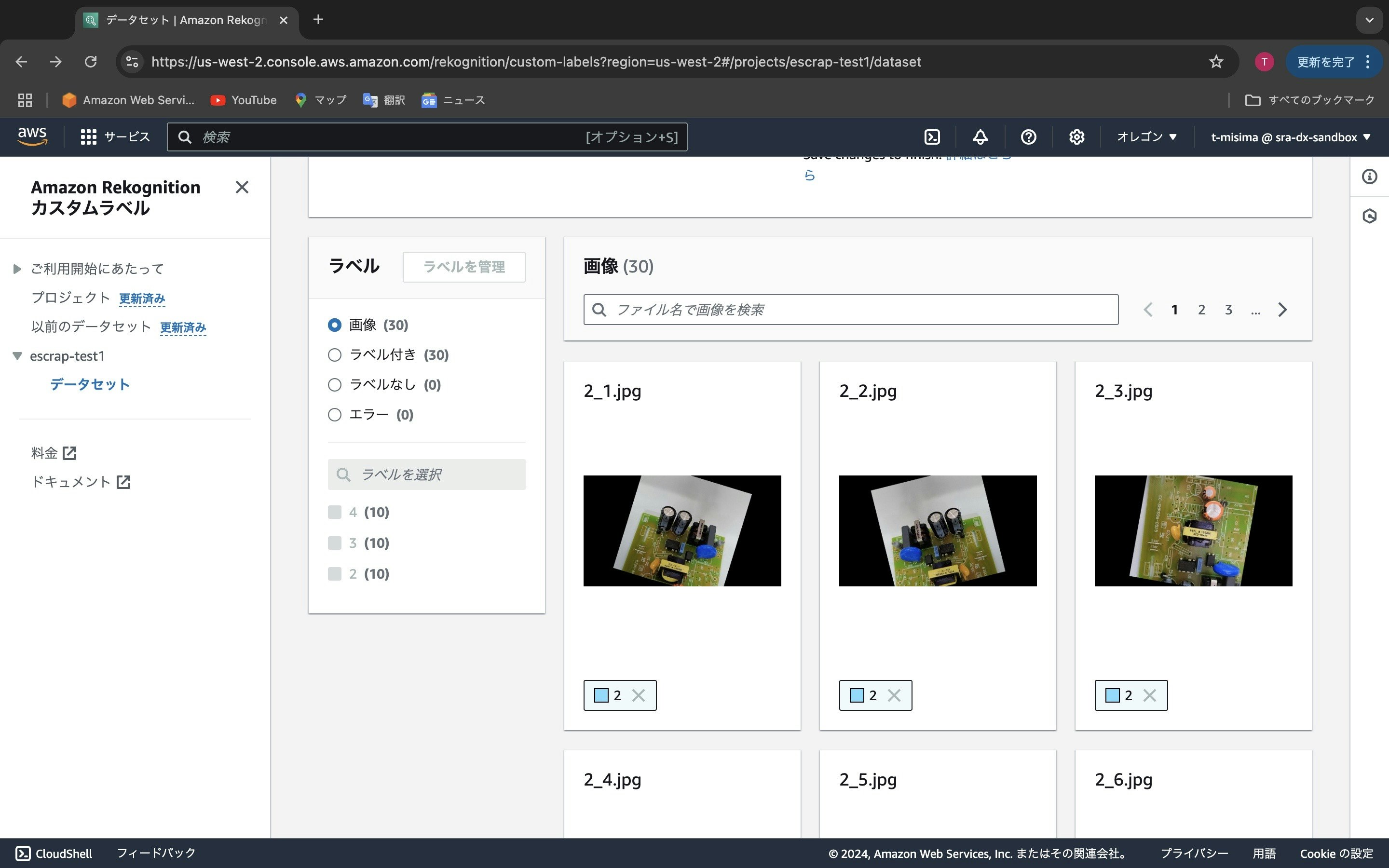
ラベルのところを見ると、4(10), 3(10), 2(10) とあります。これはラベルが「4」「3」「2」の画像がそれぞれ10枚ずつセットされたことを表します。
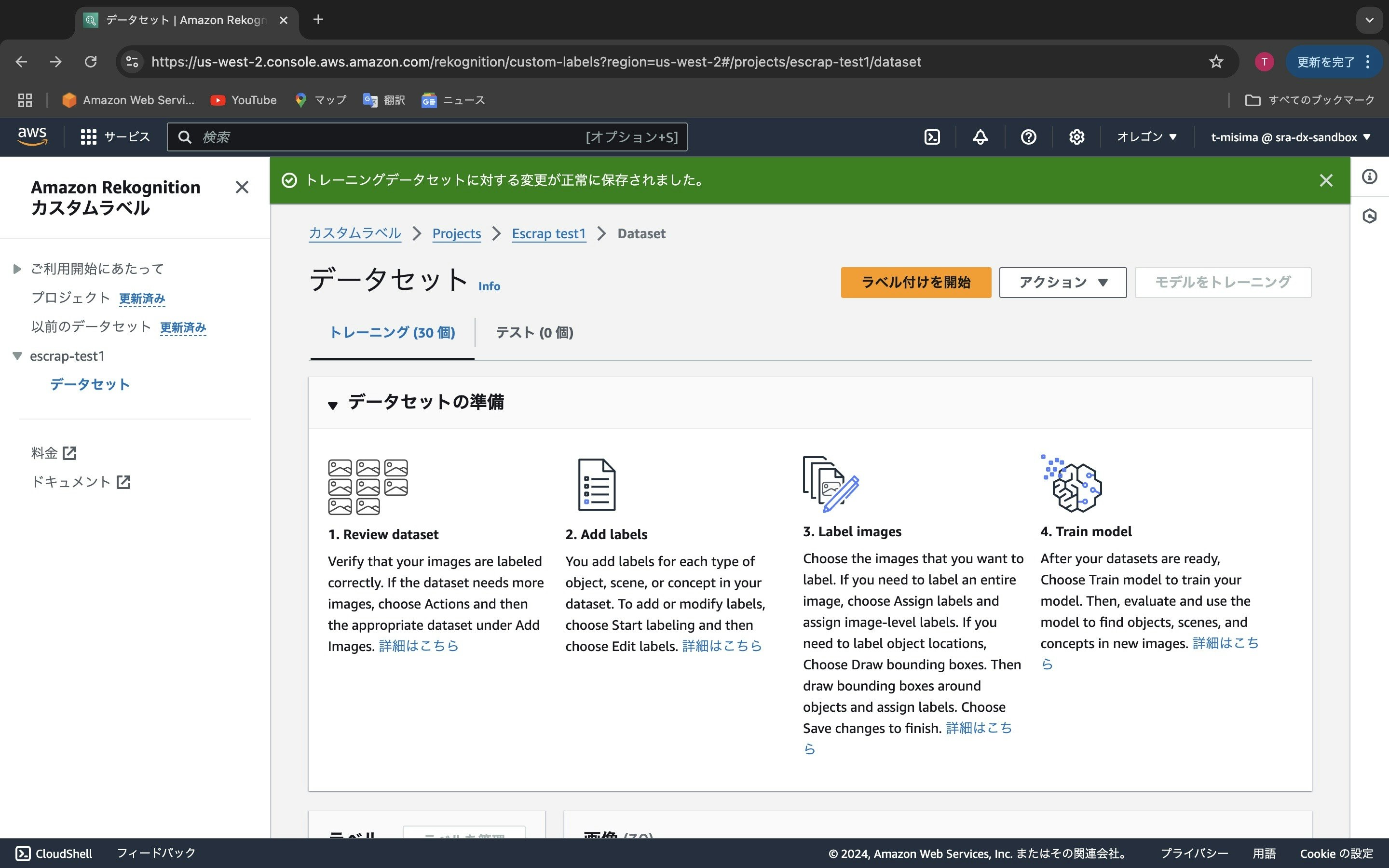
スクロールして上の画面を見ると、「トレーニング(30個)」「テスト(0個)」とあります。これはトレーニングデータが30個セットされたことを表します。しかし、テストデータまだセットしてないので0個です。「テスト(0個)」をクリックすると、テストデータのアップロードとラベルを付ける画面に切り替わります。上記のトレーニングデータを同じようにして、テストデータもアップロードどラベル付けを行います。

テストデータのラベルの状況を見てみますと、4(5), 3(5), 2(5) とあります。これはラベルが「4」、「3」、「2」の画像がそれぞれ5枚ずつセットされたことを表します。

画面の上部にスクロースすると、「トレーニング(30個)」「テスト(15個)」と表示されました。これはトレーニングデータが30個、テストデータが15個準備されている状態を表します。トレーニングデータとテストデータが揃ったのでモデルのトレーニングができる最低限の状態になりました。「最低限」と書いた理由は、精度を上げるためにはもっとたくさんのトレーニングデータがあったほうが望ましいのです。ここではこれでトレーニングを実行してみます。「モデルをトレーニング」をクリックします。
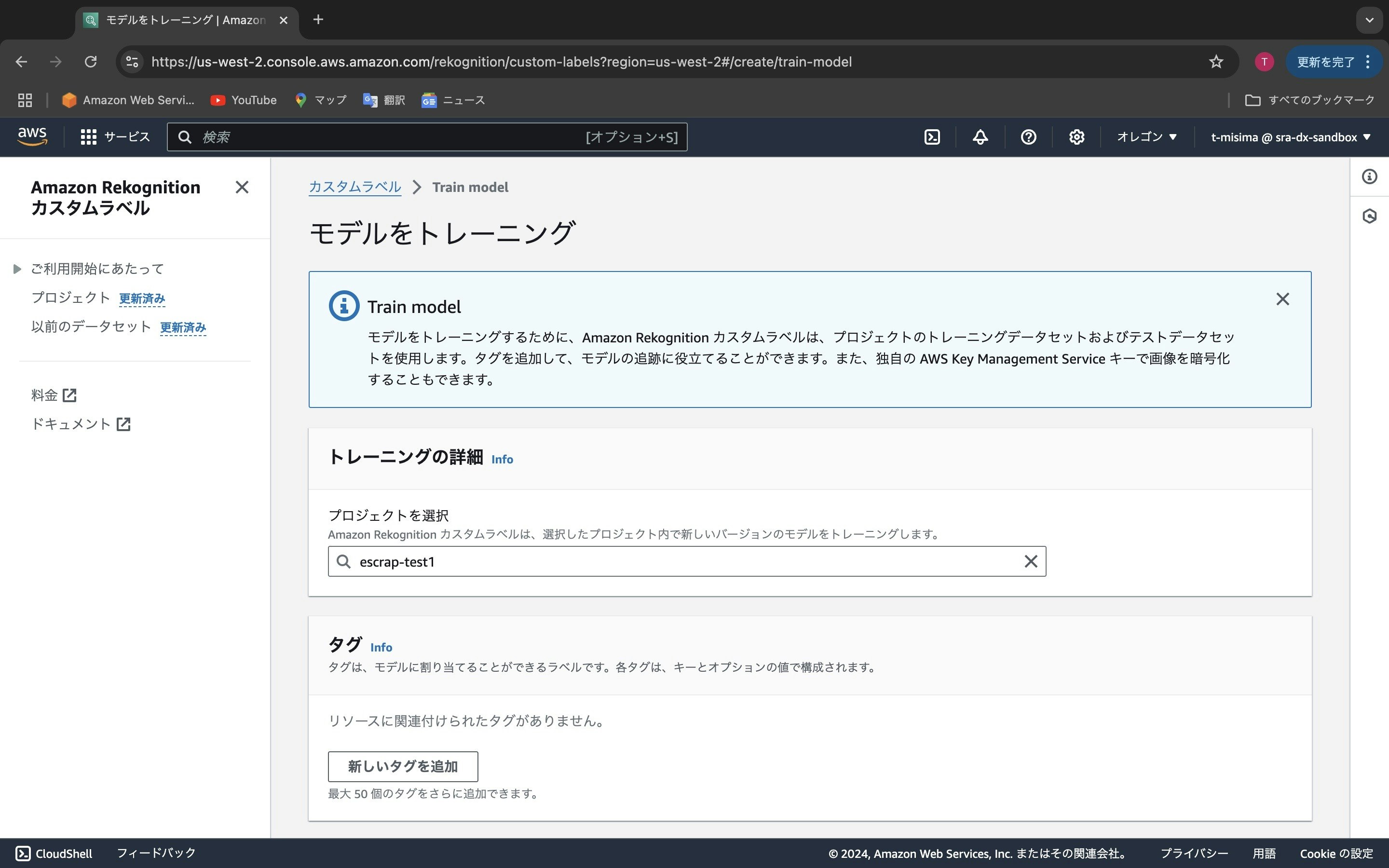
上記でセットした画像データを使ってどのモデルをトレーニングするかを選択する画面です。今回、「escrap-test1」というモデルを作りましたので、これを選択します。画面をスクロールして、「モデルをトレーニング」ボタンを押します。
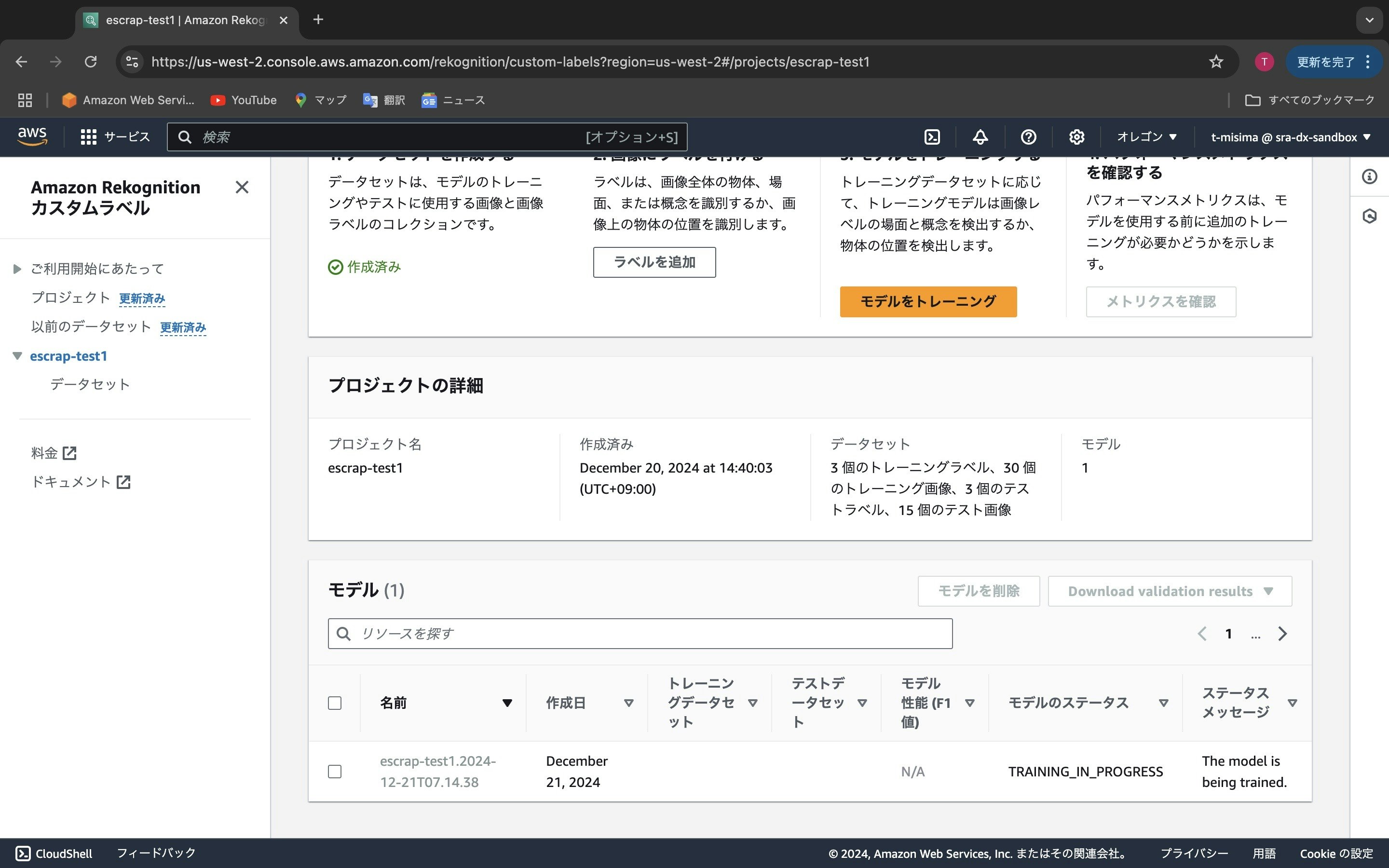
「モデルのステータス」が「TRAINING_IN_PROGRESS」、「ステータスメッセージ」が「The model is being trained」とあります。現在、トレーニングデータを使ってモデルの学習が実行されています。しばらく待ちます。

「モデルのステータス」が「TRAINING_COMPLETED」、「ステータスメッセージ」が「The model is ready to run」と変わりました。正常に学習が完了したことを表します(エラーがある場合はエラーメッセージが表示されます)。「メトリクスを確認」ボタンを押します。
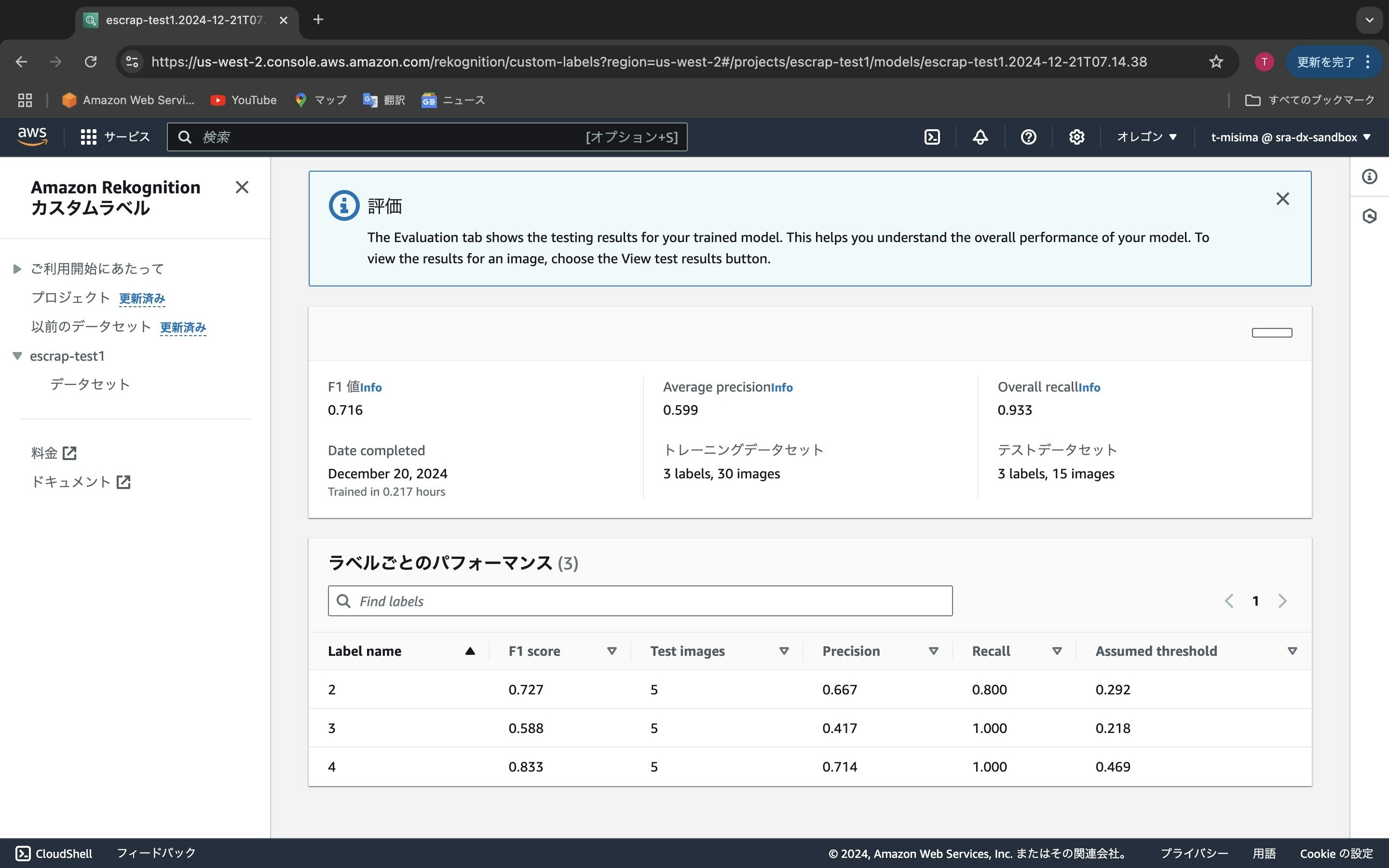
この画面はトレーニングデータで学習したモデルを使ってテストデータのラベルを判定した結果を表示しています。「F1 score」、「Precision」、「Recall」などの評価データがあります。F1 scoreはPrecisionとRecallから計算されて効率よくバランスの取れたモデルの度合いを0から1で表します。1に近いほど、良いモデルであることを表します。ラベルが「2」、「3」、「4」の時のF1 scoreの他に左上には全体のF1 scoreが表示されます。0.716という値です。悪くは無いですが、とても良い値では有りません。その原因の一つは、トレーニングデータが少ないことだと思います。精度を上げるためにはトレーニングデータを追加して再度学習を行う必要があります。
RekognitionをGUIを使って操作する方法は以上です。メリットは一切プログラミングなど必要無く、AIの知識もほとんど無くても操作できることです。ディメリットはデータをアップロードするためには上限が30であること、ラベルを一度に付けられる上限が9であること、などから、操作を何度も繰り返す事が必要であり、上記の例はデータ数が少ないのですがデータ数が多いとなかなかストレスです。また、もう少し複雑なことをやりたい場合や他のサービスと組み合わせたい場合などはGUI操作だけではやりにくく、pythonでプログラムを書いてその中からAPIを叩いた方が便利だと思います。APIを使う方法は別の記事にしようと思います。
終わり。