はじめに
こんにちは。@ken101と申します。
最近Sakana AIが話題ですね。
LLMを触ってみたくなりましたが、どうも自分のPCでは処理速度に問題があったため、
日本語に対応且つ軽そうなLLMを探しておりました。
LLM(Youri 7B Instruction GPTQ)というモデルを見つけたのでこちらで試してみます。
目的
昔OpenAI Apiを利用したvoice to voice のchatbotを作成し満足していたが、
応答テキスト作成の時間がボトルネックになっており、もっと高速化できないかと考えていた。
ローカル環境内ですべて完結させれば早いのではないかと考え実行。
環境
OS: WSL Ubuntu22.04LTS
GPU: RTX 4060Ti
メモリ 32GB
model: Youri 7B Instruction GPTQ
まずは開発してみる
下記サンプルから適当に編集
https://huggingface.co/rinna/youri-7b
import torch
import logging
import warnings
import time
import os
from auto_gptq import AutoGPTQForCausalLM
from transformers import AutoTokenizer
# スクリプト全体の開始時間を記録
start_time = time.time()
# 特定の警告を無視
warnings.filterwarnings("ignore", category=FutureWarning, message="`resume_download` is deprecated")
logging.getLogger("transformers").setLevel(logging.CRITICAL)
logging.getLogger("auto_gptq").setLevel(logging.CRITICAL)
logging.getLogger("huggingface_hub").setLevel(logging.CRITICAL)
logging.getLogger("auto_gptq.modeling._base").setLevel(logging.CRITICAL)
os.environ['TRANSFORMERS_CACHE'] = os.path.expanduser('~/.cache/huggingface/hub')
# GPUデバイスの確認
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# AutoTokenizerを使用してトークナイザーを読み込む
tokenizer = AutoTokenizer.from_pretrained("rinna/youri-7b-instruction-gptq")
# AutoGPTQForCausalLMを使用してモデルを読み込む
model = AutoGPTQForCausalLM.from_quantized("rinna/youri-7b-instruction-gptq",
use_safetensors=True,
checkpoint_format='gptq')
# モデルをGPUに移動
model.to(device)
# プロンプトを作成する
prompt = "コロンビアってどんな国?"
# トークン化し、特別なトークンを追加しないようにする
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
# トークンをGPUに移動
token_ids = token_ids.to(device)
# デバイスに合わせて入力データをモデルに渡して生成する
with torch.no_grad():
output_ids = model.generate(
input_ids=token_ids,
max_length=200,
do_sample=True,
temperature=0.5,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 生成された応答をデコードして出力する
output = tokenizer.decode(output_ids.tolist()[0])
print(output)
# スクリプト全体の終了時間を記録
end_time = time.time()
# スクリプト全体の経過時間を表示
print(f"スクリプト全体の実行にかかった時間: {end_time - start_time:.2f}秒")
実行してみるとこんな感じ。
コロンビアってどんな国?</s>
スクリプト全体の実行にかかった時間: 10.71秒
あれ?復唱しているだけで質問に答えてない。。。
と思ったのですが、どうやら入力されたテキストの続きを考える推論が得意らしい。
ので、プロンプトを工夫してみる。
# プロンプトを作成する
prompt = "コロンビアってどんな国?"
prompt +="応答:"
こうしてあげると応答:の続きを推論してくれるので
コロンビアってどんな国?応答: 南北アメリカ大陸の北西部に位置する</s>
スクリプト全体の実行にかかった時間: 10.84秒
適切な回答をしていただきました。
問題点
ここで問題点が2点
- レスポンスまでの時間が遅い。
- レスポンス内容は質問に対しての返答のみでよい。
ということでこれら2点を下記方法で解決します。
①モデル起動の時間がボトルネックになっているため、一度のモデル起動のみで後はリクエストを投げるだけという方針にする。(Python Flask)
②プロンプトの部分の文字数を判断し、レスポンスに含めないようにする。
改善結果
修正したソース↓
from flask import Flask, request, jsonify
import torch
import logging
import warnings
import time
import os
from auto_gptq import AutoGPTQForCausalLM
from transformers import AutoTokenizer
app = Flask(__name__)
# グローバル変数でモデルとトークナイザーを管理
model = None
tokenizer = None
def load_model():
global model, tokenizer
start_time = time.time()
# 特定の警告を無視
warnings.filterwarnings("ignore", category=FutureWarning, message="resume_download is deprecated")
logging.getLogger("transformers").setLevel(logging.CRITICAL)
logging.getLogger("auto_gptq").setLevel(logging.CRITICAL)
logging.getLogger("huggingface_hub").setLevel(logging.CRITICAL)
logging.getLogger("auto_gptq.modeling._base").setLevel(logging.CRITICAL)
os.environ['TRANSFORMERS_CACHE'] = os.path.expanduser('~/.cache/huggingface/hub')
# GPUデバイスの確認
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# AutoTokenizerを使用してトークナイザーを読み込む
tokenizer = AutoTokenizer.from_pretrained("rinna/youri-7b-instruction-gptq")
# AutoGPTQForCausalLMを使用してモデルを読み込む
model = AutoGPTQForCausalLM.from_quantized("rinna/youri-7b-instruction-gptq",
use_safetensors=True,
checkpoint_format='gptq')
# モデルをGPUに移動
model.to(device)
end_time = time.time()
print(f"モデルの事前読み込みにかかった時間: {end_time - start_time:.2f}秒")
# アプリケーションが起動する際にモデルを読み込む
load_model()
@app.route('/generate', methods=['POST'])
def generate():
global model, tokenizer
data = request.json
input_text = data.get("input_text", "")
# プロンプトを作成する
prompt = input_text
prompt +="応答:"
# トークン化し、特別なトークンを追加しないようにする
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt",truncation=True)
# デバイスに合わせて入力データをモデルに渡して生成する
with torch.no_grad():
output_ids = model.generate(
input_ids=token_ids.to(model.device),
max_length=200,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
# トークン化された応答をデコードし、プロンプトの長さを除去する
prompt_length = token_ids.size(1) # プロンプトのトークン数を取得
output = tokenizer.decode(output_ids[0][prompt_length:], skip_special_tokens=True)
return jsonify({"response": output})
if __name__ == '__main__':
app.run(debug=False)
これでhttpリクエストを投げると、
{
"input_text": "コロンビアってどんな国?"
}
{
"response": "ベネズエラとブラジルに国境を接している。 コロンビアの北部は、かつてのメキシコの一部であり、1810年にスペインから独立した。コロンビアは、1849年にニューヨーカーと激しい戦いに勝利し、米国から最初の「米国人移民」を追い出した。コロンビアは、1948年に米国との間に不和を生じるまで、50年間ほぼ無血で政権を樹立した。"
}
適切なresponseを返してくれました。
処理速度も以下の通り1秒かからない程度です。
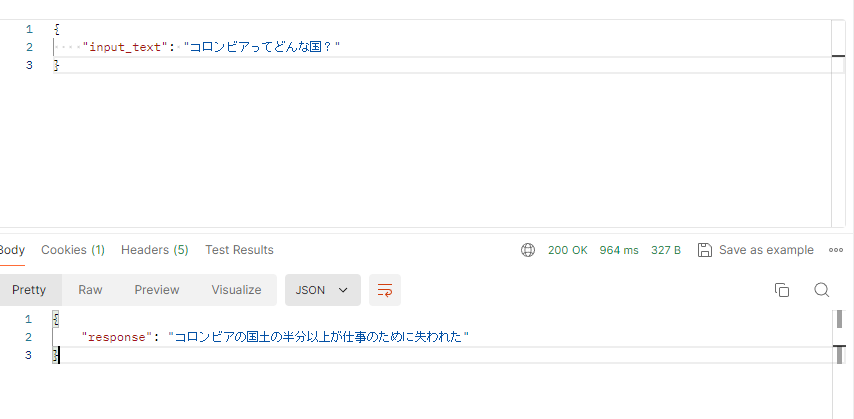
response内容も度々変わるのでとてもおもしろいです。
パラメータをいじるとさらに返答内容が変化するので、是非試してみてください。
では。