はじめに
こんにちは!今回は、インデックスについて取り上げます。インデックスは、データベース内のテーブルを検索・参照するときに高速化をもたらす重要な仕組みです。その反面、更新コストやストレージ使用量などのトレードオフがあるため、正しい知識と設計が欠かせません。
本文
1. インデックスとは?
インデックス(索引) は、テーブルとは別の領域に用意された「検索用の構造」を指します。
- キー列の値 + その行を特定するポインタ
- 検索時にまずインデックスを参照し、目的の行が格納されている場所を特定してから、テーブル本体へアクセスするため、データ取得が高速になります
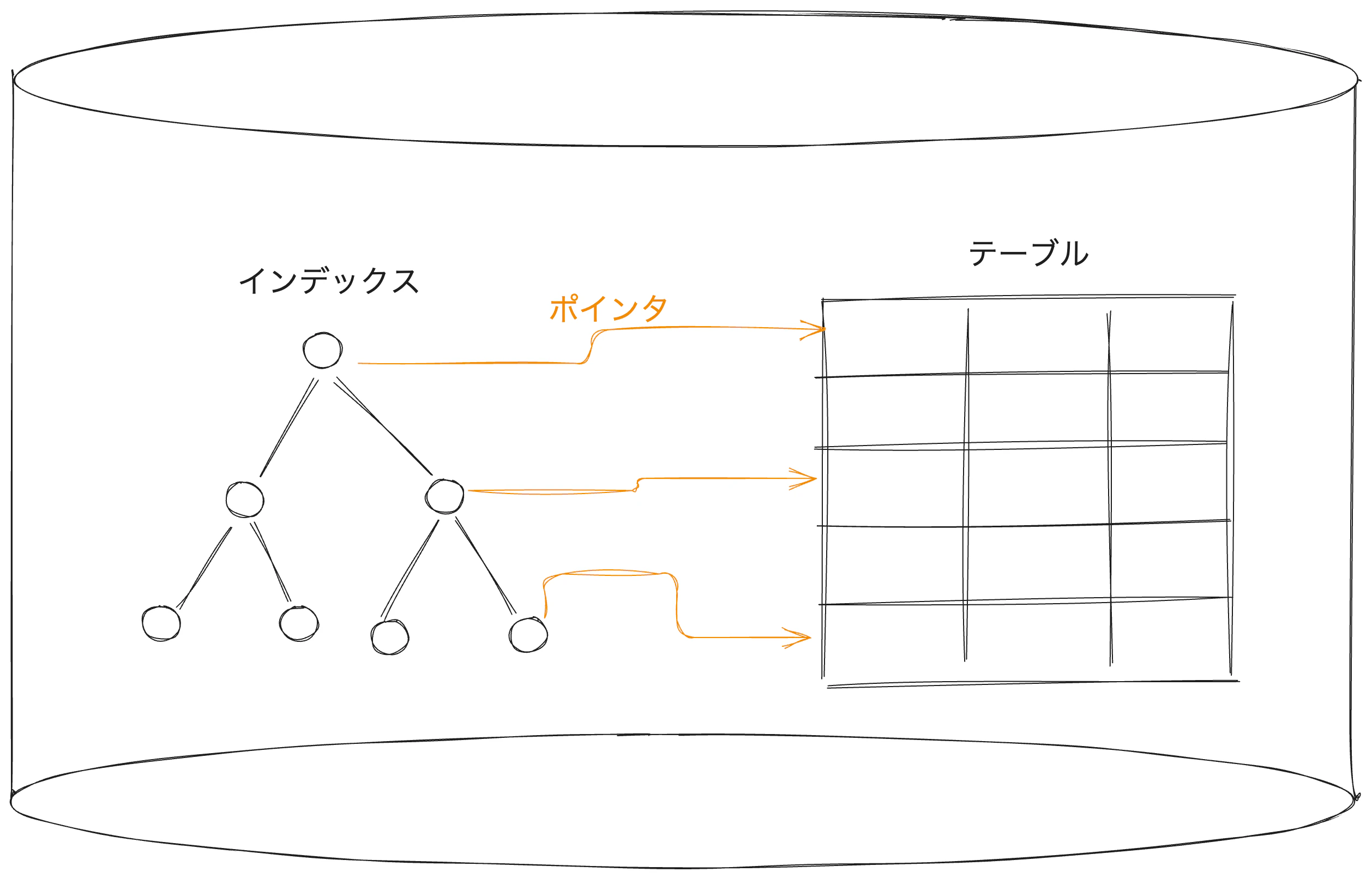
ただし、データの挿入・更新・削除時にはインデックス内容の更新も必要になるため、書き込み頻度が高いテーブルに過剰なインデックスを設定するとパフォーマンスが低下することがあります。
2. インデックスの主なデータ構造
-
B木インデックス
- 最も一般的で、木構造を用いてデータをソートしながら管理します
- バランスを保ち、木の高さが低い状態を維持することで高速検索を実現します
- 2分探索木と同じように、データの大きさを比較することで、該当するデータを探索していきます。次のようにデータを繋げることで探索を高速化します

- 2分探索木と同じように、データの大きさを比較することで、該当するデータを探索していきます。次のようにデータを繋げることで探索を高速化します
- B+木やB*木などの派生形が使われることも多く、RDBMSによっては「Clustered Index」や「Non-clustered Index」などの用語が対応している場合もあります
- B木をB+木にすると次の図のようなイメージになります
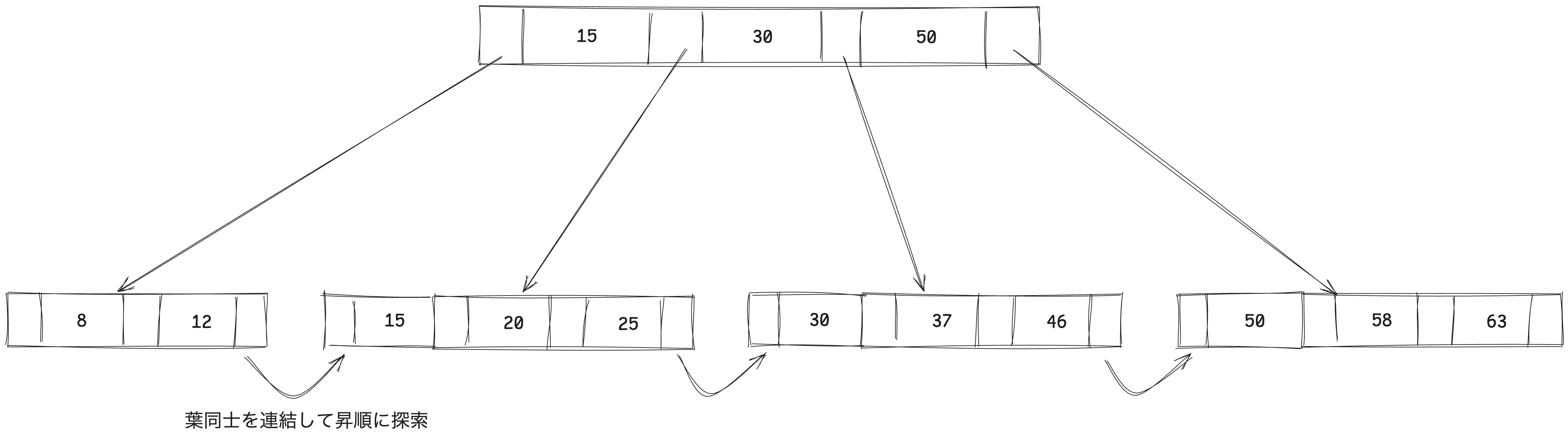
- B木をB+木にすると次の図のようなイメージになります
-
範囲検索や順序づけにも強い
- 値の大小が比較しやすいので、範囲検索やB木の派生形は特定の1つのデータを探すのに向いているので主キーなどによく設定されます
- ただし、木を探索してデータにアクセスするため、検索条件は1つしか指定できず、ANDやORの条件指定などで複数のインデックスを同時に使うことはできません
-
ビットマップインデックス
- 値の種類が少ない列(性別、真偽フラグなど)に有効
- 0/1のビットでデータの存在を示し、AND/OR演算などが高速に行える
- 例えば、ユーザを管理するデータベースがあり、「男性」「女性」「それ以外」のそれぞれについて次のようなビットマップを用意します

- 例えば、ユーザを管理するデータベースがあり、「男性」「女性」「それ以外」のそれぞれについて次のようなビットマップを用意します
- データウェアハウスやOLAP処理など、更新が少なく集計が多い環境で威力を発揮
-
ハッシュインデックス
- キーに対してハッシュ関数を使って格納場所を一意に決定する
- 例えば、ハッシュ関数として、"キー値%5"(5で割った余り)を用意し、その結果で求められた値の番地にデータを格納します

- 例えば、ハッシュ関数として、"キー値%5"(5で割った余り)を用意し、その結果で求められた値の番地にデータを格納します
- ハッシュ関数を利用するため、データが増えても検索を高速に行うことができる
- ただし、ハッシュ衝突が増えると効率低下しやすい
- 等価検索(
=)に強いが、範囲検索には適さない
- キーに対してハッシュ関数を使って格納場所を一意に決定する
3. ユニーク/非ユニークインデックス
- ユニークインデックス: インデックス列の値が一意である(主キーやユニークキーなど)。同じキー値を持つ複数行が存在しない
- 非ユニークインデックス: 重複を許容する列(外部キーや検索頻度の高い列など)で利用される場合。1つのキー値に複数の行が対応する
4. クラスタ化/非クラスタ化インデックス
-
クラスタ化インデックス
- テーブル上のデータがインデックスの順序に合わせて物理的に並んでいる
- 範囲検索が高速(順番にデータが格納されるため、一度読み込んだページに連続したデータが存在しやすい)
- テーブル1つにつき原則1つしか設定できない(物理的な並び替えを伴うため)
-
非クラスタ化インデックス
- 通常のインデックス。テーブル本体は独自の並びで存在し、インデックスはあくまでポインタを持つ
- 複数個の非クラスタ化インデックスを設定可能
5. インデックス設計と性能
5.1 インデックスの利点
- SELECTが高速化: 検索キーに合致する行へ直接ジャンプできるため、テーブル全走査(フルスキャン)を避けられる
- 範囲検索が簡単: クラスタ化インデックスやB木インデックスの場合、連続したキーを効率的に走査できる
5.2 インデックスのデメリット
-
更新コスト増:
INSERT/UPDATE/DELETEのたびにインデックスの再構成が必要。更新頻度が高い列にインデックスを付けすぎると逆効果 - ストレージ消費: インデックス用に追加のディスク領域が必要。テーブルが大きいとインデックスも膨大になる場合がある
5.3 設計のポイント
-
過剰なインデックスは避ける
- 1つのテーブルに大量のインデックスを作ると更新が遅くなる
- 統計情報や実行計画を見ながら、本当に必要な列だけを対象に設定する
-
データ量が少ない場合は不要
- レコード数が数百件程度のテーブルなら、フルスキャンのほうが速いことも多い
-
クラスタ化インデックスは一意性の高い列に
- 範囲検索が多い、主キーでソートしたいなどの場合に有効
- 一意性の低い列をクラスタ化すると逆に無駄が大きい可能性あり
-
更新頻度と利用頻度のバランス
- 参照回数が非常に多い列であればインデックスをつける価値が高いが、更新が多い列だとデメリットも大きい
6. パーティション化との関係
パーティション化(パーティショニング) は、大きなテーブルを複数の物理パーティションに分割し、検索や保守を効率化する手法です。特定の範囲(例: 日付区分)だけを読み込むことで、全体のスキャンを減らします
- インデックスもパーティション単位で作成できるDBMSが多い
- パーティションプルーニングとインデックスを組み合わせることで、データ量が莫大な場合に検索性能を向上可能
7. 性能評価とディスク容量
-
実行計画の確認
- DBMSの機能(EXPLAIN, EXPLAIN PLANなど)で、インデックスが使われているか、フルスキャンなのかを確かめる
-
ログの書き込み時間も考慮
- 更新系処理では、データ更新と同時にトランザクションログも更新される。大規模なインデックス再構築が頻繁に走ると処理時間が増大する可能性がある
-
ディスク容量の計算
- テーブル本体だけでなく、インデックスやログファイル、マテリアライズドビューなどの領域が必要
- B木などの木構造は、深さやページサイズに応じてストレージを消費するため、容量見積り時には忘れずに考慮する
- テーブルの表領域の容量は、一般的に1行あたりの平均行長(バイト)× 見積行数で求められます
- データページの1ブロックは通常1024バイト、8192バイトなどのような1024の正数倍の値を指定します。テーブルの1行を複数のブロックに分けて格納することはないので、ブロックごとに格納できる行数は、ブロックサイズ ÷ 平均行長(小数点以下切り捨て) で求められます
まとめ
インデックスは、データベース検索を効率化するために欠かせない仕組みです。一方で、データの更新コストやストレージ使用量も増大するため、設計・運用には次の点を意識する必要があります。
- データ構造に合わせたインデックスの種類選定: B木、ビットマップ、ハッシュなど
- クラスタ化や非クラスタ化のメリット・デメリット
- 更新頻度やアクセス頻度を踏まえたインデックス設計
- パーティション化との組み合わせ
- ディスク容量・ログ処理のコスト試算
これらを踏まえた上で、テーブルや利用シナリオごとに最適なインデックスを設定すれば、データベースの検索性能を大きく向上させられます。システムの実行計画や統計情報をよく確認しながら、インデックスを効果的に使っていきましょう。