はじめに
こんにちは!今回は、SQLの機能でできることを幅広く紹介します。普段よく使うCRUD(SELECT/INSERT/UPDATE/DELETE)以外にも、ビューやカーソル、ストアドプロシージャ、トリガーなど、SQLには便利な機能が多数存在します。これらを上手に活用することで、パフォーマンスやセキュリティを高められたり、開発者の負担を軽減できる場合が多いです。
本文
1. ビュー(View)
1.1 ビューとは
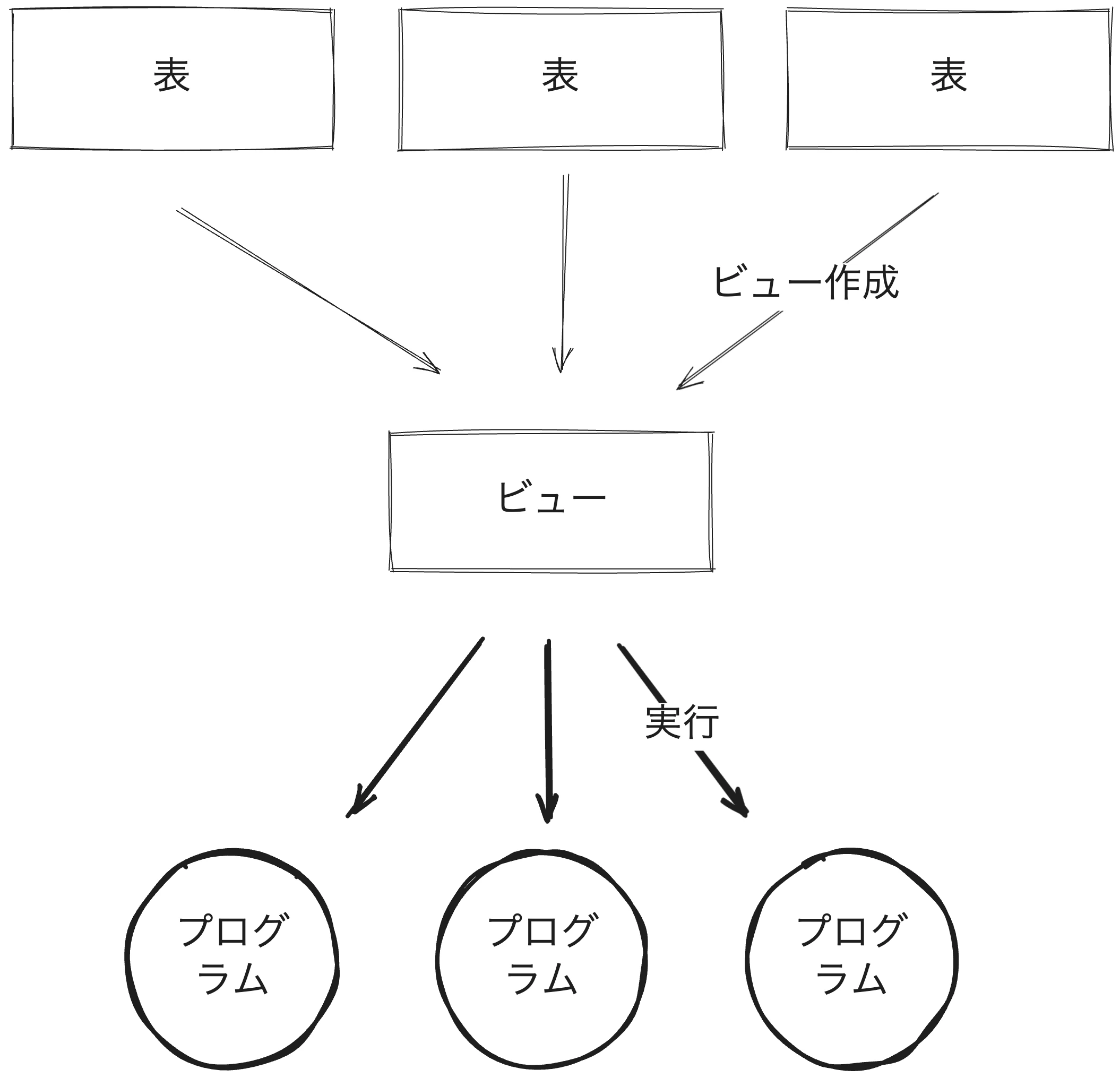
ビュー(仮想表, 導出表)は、実際のテーブル(実表)に問い合わせを行った結果を仮想的なテーブルとして扱う仕組みです。毎回定義されたSELECT文が実行されるため、常に最新のデータを参照できます。
-- 例
CREATE VIEW 営業部社員 (社員番号, 氏名) AS
SELECT 社員番号, 氏名
FROM 社員
WHERE 部署 = '営業部';
1.2 ビューの目的
-
複雑なSQLを簡易化
- 複数テーブルの結合や集約など、よく使うSELECT文をビューとして登録しておけば、利用者は単純なSELECT文で呼び出せます
-
セキュリティの確保
- 公開したくない列や行を隠すことが可能。必要最小限の情報だけをビューとして切り出し、ユーザにはビューへのアクセス権のみ付与する
1.3 更新可能なビュー
ビューに対してINSERT/UPDATE/DELETEができる場合を更新可能ビューと言います。しかし、以下の機能を使うと元の行が特定できなくなり、更新不可となる場合が多いです。
- GROUP BY句、HAVING句
- 集計関数(SUM, AVGなど)
- DISTINCT句
- 計算列(演算で求められた列)
- 結合条件によっては更新が難しいものも
また、ビューに含まれない列はNULLやデフォルト値で補える必要があります。
1.4 体現ビュー(マテリアライズドビュー)
通常のビューは参照のたびに実表へ問い合わせを行うため、頻繁に参照されると処理が遅くなる可能性があります。そこで体現ビュー(マテリアライズドビュー) を使い、問い合わせ結果をあらかじめキャッシュとして格納する方法があります。
- メリット: ビューへのアクセスが高速になる
- デメリット: 実データとの不整合リスク、メンテナンスコスト増、追加のストレージが必要
更新のタイミングや同期の仕組みを設計することが重要です。
2. カーソル(Cursor)
2.1 カーソルの目的
カーソルは、プログラム(手続き型言語)からデータベースを1行ずつ処理するときに使います。かつてCOBOLやCなどで1レコードごとに処理したい場合、複数行を一括で扱えなかったために導入されました。
現在でもストアドプロシージャや特定のロジックで、1行ずつ細かい処理を行いたい場合に利用されますが、大規模処理ではパフォーマンス面に注意が必要です。
2.2 カーソルの使用例
-- カーソルの宣言
DECLARE @FName NVARCHAR(50), @LName NVARCHAR(50);
DECLARE EmpCur CURSOR FOR
SELECT FName, LName
FROM Employee;
-- カーソルを開く
OPEN EmpCur;
-- データを取得して変数に格納
FETCH NEXT FROM EmpCur INTO @FName, @LName;
WHILE @@FETCH_STATUS = 0
BEGIN
PRINT @FName + ' ' + @LName;
FETCH NEXT FROM EmpCur INTO @FName, @LName;
END
-- カーソルを閉じる
CLOSE EmpCur;
- DECLARE : カーソルの宣言
- OPEN : カーソルを開いて結果セットを用意
- FETCH : 1行ずつデータを変数に格納
- CLOSE : カーソルを閉じ、リソース解放
2.3 カーソルの問題点
- DBMSごとの実装差が大きく、移植やバージョンアップで不都合が起こりやすい
- 行を1つずつ扱うため、通常のセット処理に比べパフォーマンスが劣る場合がある
- 多用すると複雑性が増し、保守コストも高まる
どうしても1行単位で処理が必要な場合に限定してカーソルを使うのがベストです。
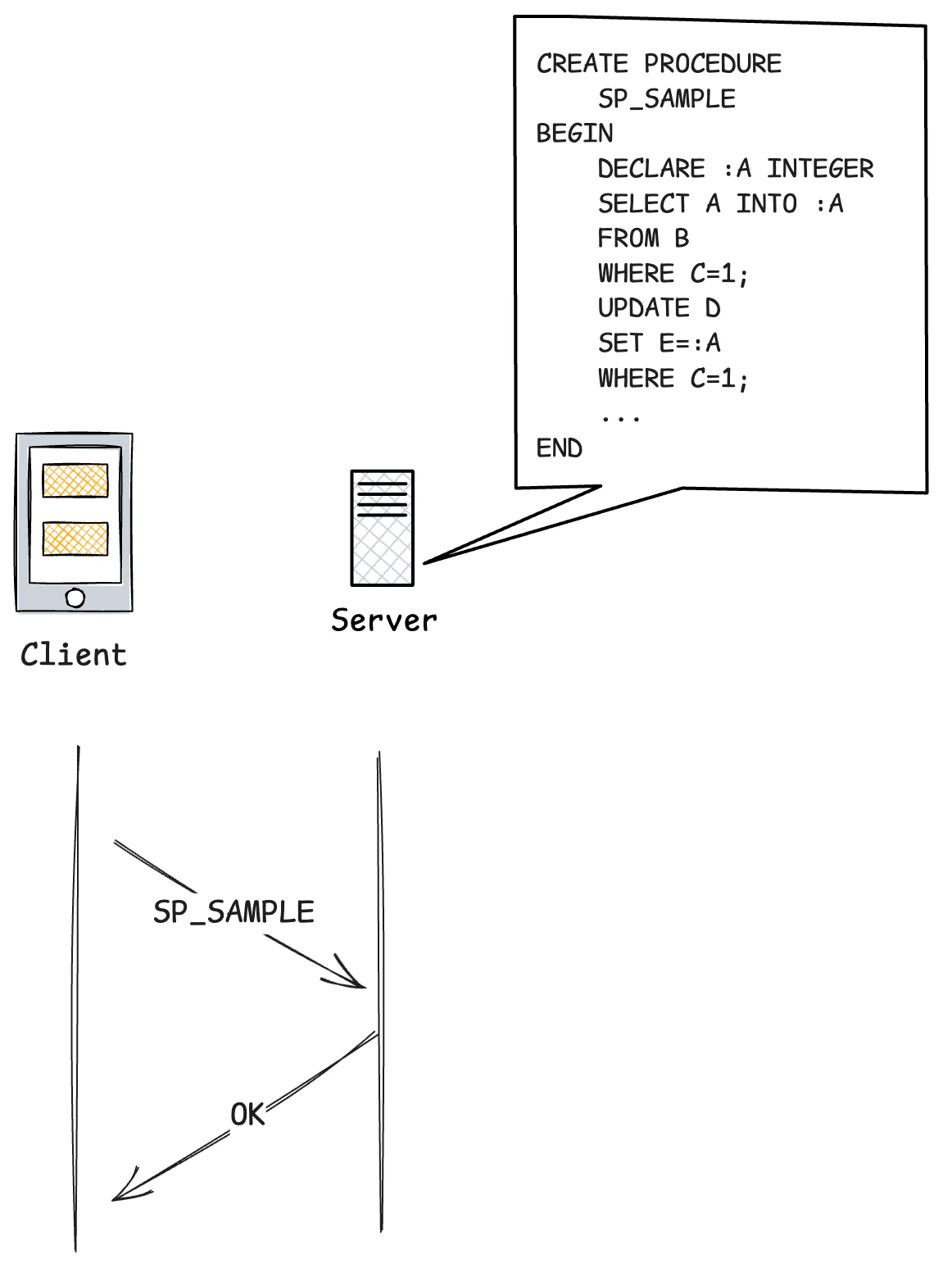
3. ストアドプロシージャ(Stored Procedure)
ストアドプロシージャは、データベースサーバ内にあらかじめ保存されたプログラムです。複数のSQL文をまとめ、引数を受け取って実行できます。
3.1 利用目的
-
処理の高速化
- ストアドプロシージャはサーバ上で事前にコンパイルされるため、SQLを都度送るより早いケースが多い
- 通信量が削減できる
-
ロジックの一元化
- アプリケーション側に複雑な処理を書かず、DBサーバに任せることで開発負担を減らせる
-
セキュリティ向上
- データ操作ロジックをサーバ側に集約し、ユーザにはプロシージャ実行権限のみ付与すれば直接テーブルを触られない
-- 例
CREATE PROCEDURE sp_updateStock
@ProdID INT,
@Delta INT
AS
BEGIN
UPDATE 在庫
SET 数量 = 数量 + @Delta
WHERE 商品番号 = @ProdID;
END;
4. トリガー(Trigger)
トリガーは、テーブルやビューに対してINSERT/UPDATE/DELETEなどの操作が行われた際、自動的に呼び出される仕組みです。
4.1 利用目的
-
関連データの連動更新
- 在庫が減ったら別のテーブルに履歴を書き込む、など
-
制約を超えた高度な整合性維持
- 条件付きでエラーを発生させたり、特殊な業務ルールを実装できる
-
監査ログの記録
- いつ誰がデータを更新したのか、変更前の値や変更後の値を記録する
-- 例
CREATE TRIGGER trgStockCheck
AFTER UPDATE OF 在庫数量 ON 在庫
REFERENCING NEW ROW AS newRow
FOR EACH ROW
WHEN (newRow.在庫数量 < 0)
BEGIN ATOMIC
-- 在庫不足時の処理を行う(発注処理を呼び出す等)
CALL ReorderProc(newRow.商品番号);
END;
4.2 トリガーの注意点
- トリガーの実行回数が増えるとオーバーヘッドが大きくなり、パフォーマンスが低下しやすいです
- 処理順序が複雑になるとバグやデッドロックの原因にもなります
- テスト・運用時に「いつ、どこで、何が動いているか」が見えにくいです
使い方を誤ると可読性や保守性が低下するため、シンプルな設計が大切です。
まとめ
SQLは単にSELECTやINSERTなどで終わらず、ビューによるデータ抽象化やセキュリティ強化、 カーソルでの1行単位処理、 ストアドプロシージャによるサーバサイドのビジネスロジック、 トリガーによる自動処理など、多彩な機能を備えています。
- ビュー: 複雑なクエリを簡略化&セキュリティ対策
- カーソル: 1行ずつ処理が必要な場合に便利(ただし性能に注意)
- ストアドプロシージャ: サーバ上でSQL文を一括実行し、高速化と通信量削減
- トリガー: テーブル更新時に自動処理を行い、整合性や業務ルールを担保
これらを効果的に組み合わせると、アプリケーション開発やデータ管理で大きなメリットがあります。ただし、無闇に機能を多用するとパフォーマンスや保守性が下がることもあるため、要件や運用状況に応じて慎重に設計する必要があります。